Recognition: unknown
CASCADE: A Cascaded Hybrid Defense Architecture for Prompt Injection Detection in MCP-Based Systems
Pith reviewed 2026-05-10 06:03 UTC · model grok-4.3
The pith
A three-layer cascaded defense detects prompt injection attacks in MCP-based LLM applications with high precision while running entirely locally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
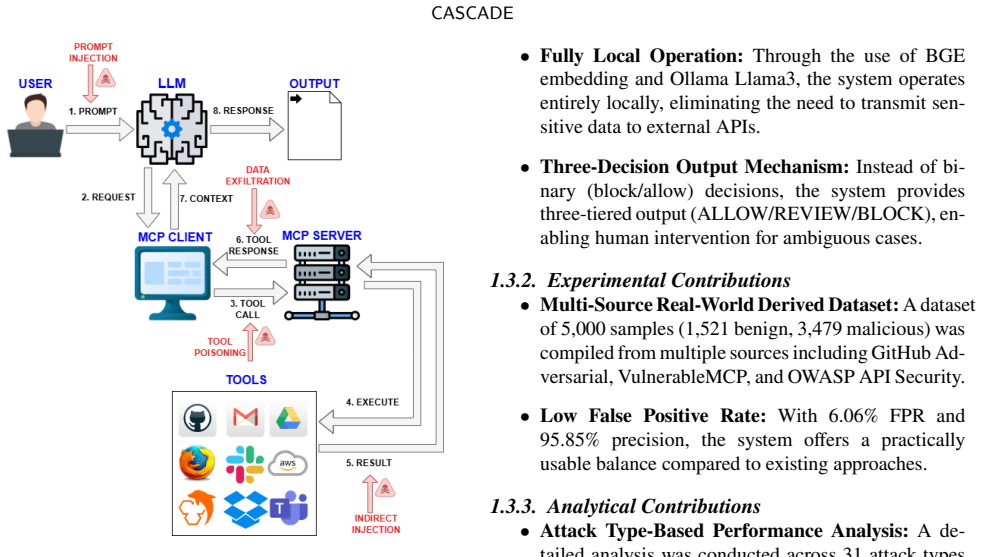
CASCADE is a cascaded hybrid defense architecture consisting of three layers for MCP-based systems. The first layer performs fast pre-filtering using regex, phrase weighting, and entropy analysis. The second layer conducts semantic analysis with BGE embeddings and an Ollama Llama3 fallback. The third layer applies pattern-based output filtering. On a 5,000-sample dataset, it achieves 95.85% precision, 6.06% false positive rate, 61.05% recall, and 74.59% F1-score, with high detection for data exfiltration and prompt injection attacks.
What carries the argument
The three-tiered cascaded architecture that progressively applies statistical pre-filters, semantic embeddings, and pattern matching to identify attacks.
If this is right
- Strong detection of data exfiltration attacks at 91.5% and prompt injection at 84.2% follows directly from the multi-layer checks.
- Fully local operation without external API calls distinguishes it from prior solutions and supports privacy-preserving use.
- Lower detection rates for semantic attacks at 52.5% and tool poisoning at 59.9% point to specific categories needing further development in the cascade.
- The overall metrics indicate a viable balance for practical deployment in MCP environments.
Where Pith is reading between the lines
- Adopting CASCADE could allow MCP tool developers to add defense as a standard component without depending on third-party services.
- Enhancing the semantic layer with additional local models might address the weaker performance on certain attack types.
- Applying the same cascaded approach to other LLM tool protocols could extend its utility beyond MCP.
- Validating performance on live traffic from MCP implementations would test if the results hold in practice.
Load-bearing premise
The 5,000 samples and 31 attack types in the evaluation dataset represent the real-world attacks that occur in deployed MCP-based systems.
What would settle it
Substantially lower precision or higher false positive rates when evaluated on a fresh dataset of MCP interactions or different attack implementations would disprove the effectiveness claim.
Figures


read the original abstract
Model Context Protocol (MCP) is a rapidly adopted standard for defining and invoking external tools in LLM applications. The multi-layered architecture of MCP introduces new attack surfaces such as tool poisoning, in addition to traditional prompt injection. Existing defense systems suffer from limitations including high false positive rates, API dependency, or white-box access requirements. In this study, we propose CASCADE, a three-tiered cascaded defense architecture for MCP-based systems: (i) Layer 1 performs fast pre-filtering using regex, phrase weighting, and entropy analysis; (ii) Layer 2 conducts semantic analysis via BGE embedding with an Ollama Llama3 fallback mechanism; (iii) Layer 3 applies pattern-based output filtering. Evaluation on a dataset of 5,000 samples yielded 95.85% precision, 6.06% false positive rate, 61.05% recall, and 74.59% F1-score. Analysis across 31 attack types categorized into 6 tiers revealed high detection rates for data exfiltration (91.5%) and prompt injection (84.2%), while semantic attack (52.5%) and tool poisoning (59.9%) categories showed potential for improvement. A key advantage of CASCADE over existing solutions is its fully local operation, requiring no external API calls
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CASCADE, a cascaded hybrid defense architecture consisting of three layers for detecting prompt injection and related attacks in systems using the Model Context Protocol (MCP). The first layer uses regex, phrase weighting, and entropy analysis for pre-filtering; the second employs BGE embeddings for semantic analysis with an Ollama Llama3 fallback; and the third applies pattern-based output filtering. The authors evaluate this on a dataset of 5,000 samples covering 31 attack types in 6 tiers, reporting 95.85% precision, 6.06% false positive rate, 61.05% recall, and 74.59% F1-score, with stronger performance on data exfiltration and prompt injection but weaker on semantic attacks and tool poisoning. The system is highlighted for its fully local operation without external API calls.
Significance. Assuming the evaluation is sound, this work contributes a practical defense mechanism for emerging MCP-based LLM applications, addressing both traditional prompt injection and new threats like tool poisoning through a hybrid local approach. The cascaded design promotes efficiency by handling simple cases quickly and escalating complex ones, which could be valuable for real-time systems. The per-category analysis provides useful diagnostic information on where the defense succeeds or needs enhancement.
major comments (3)
- [Abstract] The central performance claims rely on a 5,000-sample dataset, yet the manuscript provides no information on dataset construction, including benign sample sources, class balance, how the 31 attack types were generated or instantiated (particularly for semantic and tool poisoning categories), or any validation of coverage. This directly affects the reliability of the reported metrics such as the 61.05% recall and the tier-specific rates (e.g., 52.5% for semantic attacks).
- [Abstract] No baseline comparisons or statistical significance tests are mentioned in the evaluation summary. Without these, it is not possible to determine if the 74.59% F1-score represents a meaningful improvement over existing defenses or if the results are robust.
- [Abstract] The low recall (61.05%) and F1-score, combined with notably lower detection rates for tool poisoning (59.9%) and semantic attacks (52.5%), suggest that the cascaded architecture may not adequately cover all MCP-introduced attack surfaces. This challenges the claim of a comprehensive defense and indicates potential load-bearing weaknesses in Layers 2 and 3 for certain attack types.
minor comments (2)
- The abstract references '6 tiers' for the 31 attack types but does not define or list them; this should be clarified in the main text for reproducibility.
- Consider adding details on the specific regex patterns, entropy thresholds, and embedding similarity thresholds used in each layer to allow replication.
Simulated Author's Rebuttal
We are grateful to the referee for the insightful comments that will help improve the clarity and rigor of our work on the CASCADE defense architecture. We address each major comment below and commit to making the necessary revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] The central performance claims rely on a 5,000-sample dataset, yet the manuscript provides no information on dataset construction, including benign sample sources, class balance, how the 31 attack types were generated or instantiated (particularly for semantic and tool poisoning categories), or any validation of coverage. This directly affects the reliability of the reported metrics such as the 61.05% recall and the tier-specific rates (e.g., 52.5% for semantic attacks).
Authors: We agree that the manuscript would benefit from greater transparency on dataset construction. The current text references the 5,000 samples and 31 attack types across 6 tiers but omits the requested details. In the revision we will add an explicit 'Dataset Construction' subsection describing: benign samples drawn from public LLM interaction corpora; class balance (approximately 2,000 benign / 3,000 malicious); generation procedures (template-driven for prompt injection, LLM-assisted paraphrasing for semantic attacks, and manually crafted poisoned tool schemas for tool poisoning); and validation via expert review of a 500-sample subset. These additions will directly support interpretation of the 61.05% recall and tier-specific figures. revision: yes
-
Referee: [Abstract] No baseline comparisons or statistical significance tests are mentioned in the evaluation summary. Without these, it is not possible to determine if the 74.59% F1-score represents a meaningful improvement over existing defenses or if the results are robust.
Authors: We acknowledge the value of baselines and statistical tests. The revised manuscript will include side-by-side evaluation against two adapted baselines—a standalone BGE embedding detector and a regex-plus-entropy filter—run on the identical 5,000-sample set. We will also report McNemar’s test results for F1-score differences across tiers. These additions will demonstrate that the reported 74.59% F1 constitutes a meaningful gain, particularly under the constraint of fully local operation. We will note that MCP-specific attacks such as tool poisoning lack prior public baselines. revision: yes
-
Referee: [Abstract] The low recall (61.05%) and F1-score, combined with notably lower detection rates for tool poisoning (59.9%) and semantic attacks (52.5%), suggest that the cascaded architecture may not adequately cover all MCP-introduced attack surfaces. This challenges the claim of a comprehensive defense and indicates potential load-bearing weaknesses in Layers 2 and 3 for certain attack types.
Authors: The referee correctly highlights a genuine limitation. CASCADE is not presented as a fully comprehensive solution; the manuscript already notes weaker results on semantic and tool-poisoning categories and frames the work as a practical, low-FPR hybrid. The 6.06% false-positive rate is a deliberate design choice for real-time MCP usability. In revision we will temper abstract and conclusion language to avoid any implication of complete coverage, explicitly discuss the load on Layers 2 and 3 for these attack classes, and outline targeted future improvements such as embedding fine-tuning. This accurately reflects the contribution without overstating scope. revision: partial
Circularity Check
No significant circularity; purely empirical evaluation
full rationale
The paper describes a three-layer cascaded defense architecture (regex pre-filter, semantic embedding analysis, output filtering) and reports direct performance metrics from evaluating it on a fixed 5,000-sample dataset across 31 attack types. No equations, fitted parameters, predictions, or derivations are present that could reduce to the authors' own inputs or prior choices by construction. The reported precision, recall, and F1 values are presented as straightforward evaluation outcomes rather than self-referential results. Self-citations are absent from the provided text, and the central claims rest on external dataset testing rather than internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. Hou, Y. Zhao, S. Wang, H. Wang, Model context protocol (mcp): Landscape, security threats, and future research directions, ACM Transactions on Software Engineering and Methodology (2025)
2025
-
[2]
M. M. Hasan, H. Li, E. Fallahzadeh, G. K. Rajbahadur, B. Adams, A. E. Hassan, Model context protocol (mcp) at first glance: Study- ing the security and maintainability of mcp servers, arXiv preprint arXiv:2506.13538 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Gulyamov, S
S. Gulyamov, S. Gulyamov, A. Rodionov, R. Khursanov, K. Mekhmonov, D. Babaev, A. Rakhimjonov, Prompt injection attacks in large language models and ai agent systems: A comprehensive review of vulnerabilities, attack vectors, and defense mechanisms, Information 17 (1) (2026) 54
2026
-
[4]
OWASP,OWASPTop10forModelContextProtocol(MCP),https: //owasp.org/www-project-mcp-top-10/, accessed: 2026-04-18 (2025)
2026
- [5]
- [6]
-
[7]
Y. Hu, C. Fan, S. Samyoun, J. Du, Log-to-leak: Prompt injection attacks on tool-using llm agents via model context protocol (2025)
2025
-
[8]
Securing the Model Context Protocol: Defending LLMs against tool poisoning and adversarial attacks,
S. Jamshidi, K. W. Nafi, A. M. Dakhel, N. Shahabi, F. Khomh, N. Ezzati-Jivan, Securing the model context protocol: Defending llms against tool poisoning and adversarial attacks, arXiv preprint arXiv:2512.06556 (2025)
- [9]
-
[10]
Y. Liu, G. Deng, Y. Li, K. Wang, Z. Wang, X. Wang, T. Zhang, Y. Liu, H. Wang, Y. Zheng, et al., Prompt injection attack against llm-integratedapplications,arXivpreprintarXiv:2306.05499(2023)
work page internal anchor Pith review arXiv 2023
-
[11]
OWASP, OWASP Top 10 for Large Lan- guage Model Applications,https://owasp.org/ www-project-top-10-for-large-language-model-applications/, accessed: 2026-04-18 (2025)
2026
- [12]
-
[13]
J. Shi, Z. Yuan, Y. Liu, Y. Huang, P. Zhou, L. Sun, N. Z. Gong, Optimization-based prompt injection attack to llm-as-a-judge, in: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 660–674
2024
-
[14]
Debenedetti, J
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fis- cher, F. Tramèr, Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents, Advances in Neural Information Processing Systems 37 (2024) 82895–82920
2024
-
[15]
Suo, Signed-prompt: A new approach to prevent prompt injection attacks against llm-integrated applications, in: AIP Conference Pro- ceedings, Vol
X. Suo, Signed-prompt: A new approach to prevent prompt injection attacks against llm-integrated applications, in: AIP Conference Pro- ceedings, Vol. 3194, AIP Publishing LLC, 2024, p. 040013
2024
- [16]
-
[17]
N. Maloyan, D. Namiot, Breaking the protocol: Security analy- sis of the model context protocol specification and prompt injec- tion vulnerabilities in tool-integrated llm agents, arXiv preprint arXiv:2601.17549 (2026)
-
[18]
Mcp safety audit: Llms with the model context protocol allow major security exploits
B. Radosevich, J. Halloran, Mcp safety audit: Llms with the model context protocol allow major security exploits, 2025, URL https://arxiv. org/abs/2504.03767
- [19]
-
[20]
Siameh, A
T. Siameh, A. A. Addobea, C.-H. Liu, Context injection vulnera- bilities and resource exploitation attacks in model context protocol, Authorea Preprints (2025)
2025
- [21]
- [22]
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.