Recognition: unknown
BranchBench: Aligning Database Branching with Agentic Demands
Pith reviewed 2026-05-10 06:08 UTC · model grok-4.3
The pith
Current branchable databases cannot support agentic workloads at scale due to performance trade-offs between branching speed and read operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BranchBench demonstrates a fundamental tension in branchable relational DBMSes: systems optimized for fast branching suffer up to 5-4000x slower reads as branches deepen, while systems optimized for fast data operations incur 25-1500x higher branch creation and switching latency, and no current system supports the representative agentic workloads at scale.
What carries the argument
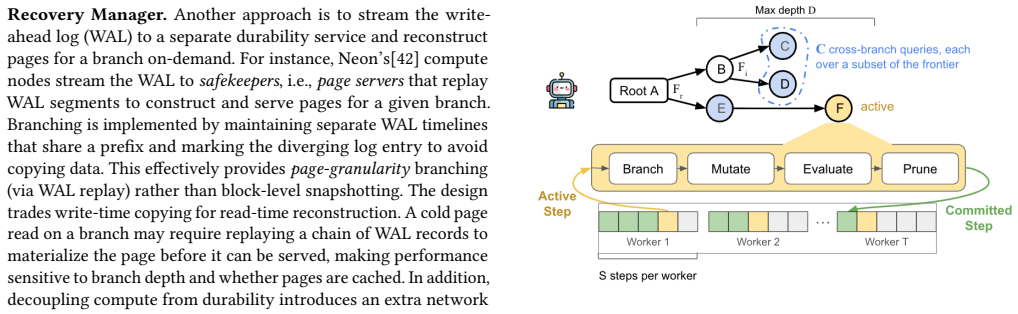
Parameterized macrobenchmarks that execute repeated branch-mutate-evaluate loops to isolate branch lifecycle costs while reflecting the structure of agentic exploration.
If this is right
- Agentic applications built on branching databases will encounter unacceptable latency once exploration depth increases beyond shallow levels.
- Database development must shift from adapting existing transaction or copy-on-write mechanisms toward architectures that treat branching as a first-class primitive.
- Workloads involving repeated speculative state changes, such as failure reproduction or data curation by agents, remain impractical on today's branchable systems.
- Performance results from BranchBench can serve as targets for measuring progress in future branch-native database implementations.
Where Pith is reading between the lines
- Agent frameworks may need to adopt lightweight in-memory versioning layers instead of depending on persistent database branches for exploration.
- The observed trade-off suggests that new storage formats combining fast snapshotting with efficient query indexing could close the gap without full redesign.
- Extending the benchmark to include concurrent agent interactions across shared branches would test whether isolation mechanisms also need rethinking.
- Similar branching demands in other domains, such as scientific simulation or automated testing, could reuse the same macrobenchmark structure to quantify costs.
Load-bearing premise
The five chosen workloads and the evaluated systems accurately represent the space of real agentic database demands and the current state of the art.
What would settle it
Demonstration of any single system that keeps both branch creation and read latency low and stable across increasing branch depths when running the BranchBench macrobenchmarks would falsify the reported tension and the conclusion that redesign is required.
Figures






read the original abstract
Branchable databases are evolving from developer tools to infrastructure for agentic workloads characterized by speculative mutations and non-linear state exploration. Traditional RDBMS mechanisms such as nested transactions do not provide the persistent isolation and concurrent branch management required by autonomous agents, and recent "zero-copy" designs make different trade-offs whose impact on agentic workloads remains unclear. To clarify this space, we present BranchBench, a benchmark for evaluating branchable relational DBMSes under agentic exploration. We characterize five representative workloads-agentic software engineering, failure reproduction, data curation, MCTS, and simulation-and design parameterized macrobenchmarks that execute branch-mutate-evaluate loops to reflect these workloads, along with microbenchmarks that isolate branch lifecycle costs. We evaluate state of the art systems including Neon, DoltgreSQL, Tiger Data, Xata, and PostgreSQL baselines, and find a fundamental tension: systems optimized for fast branching suffer up to 5-4000x slower reads as branches deepen, while systems optimized for fast data operations incur 25-1500x higher branch creation and switching latency. Further, no current system supports the representative workloads at scale. These results highlight the need for branch-native DBMSes designed specifically for agentic exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce BranchBench, a benchmark for evaluating branchable relational DBMSes under agentic workloads. It characterizes five workloads (agentic software engineering, failure reproduction, data curation, MCTS, and simulation) via parameterized macrobenchmarks that execute branch-mutate-evaluate loops plus microbenchmarks isolating branch lifecycle costs. Evaluation of Neon, DoltgreSQL, Tiger Data, Xata, and PostgreSQL baselines reveals a fundamental tension: fast-branching systems suffer 5-4000x slower reads as branches deepen while fast-data systems incur 25-1500x higher branch creation/switching latency, with no current system supporting the workloads at scale.
Significance. If the benchmark workloads and measurements are representative, the work is significant for identifying concrete performance trade-offs in current branching DBMS designs and motivating branch-native systems for speculative agentic exploration. The empirical contribution is strengthened by the provision of specific quantitative ranges across multiple systems and the focus on persistent isolation and concurrent branch management not addressed by traditional nested transactions.
major comments (2)
- [§4] §4 (Workload Characterization): The five workloads are asserted to reflect agentic demands, but the macrobenchmark parameterization (branch depths, mutation patterns, read/write ratios, and loop frequencies) is presented without validation against real agent traces, sensitivity analysis, or external data. This directly affects the load-bearing claim that the observed 5-4000x read slowdowns and 25-1500x branch latencies are fundamental rather than artifacts of the chosen parameters.
- [§5] §5 (Evaluation Methodology): The reported performance factors lack accompanying details on benchmark implementation, exact workload parameterization, measurement methodology (e.g., how reads are timed as branches deepen), error handling, number of runs, or statistical reporting. Without these, it is not possible to assess whether the data supports the conclusion that no current system supports the representative workloads at scale.
minor comments (2)
- The abstract refers to 'zero-copy' designs without defining the term or citing the specific mechanisms used in the evaluated systems (Neon, DoltgreSQL, etc.).
- Consider adding a summary table of workload parameters (e.g., typical branch depth, mutation rate) to improve clarity of the macrobenchmark design.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve the transparency and rigor of BranchBench. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Workload Characterization): The five workloads are asserted to reflect agentic demands, but the macrobenchmark parameterization (branch depths, mutation patterns, read/write ratios, and loop frequencies) is presented without validation against real agent traces, sensitivity analysis, or external data. This directly affects the load-bearing claim that the observed 5-4000x read slowdowns and 25-1500x branch latencies are fundamental rather than artifacts of the chosen parameters.
Authors: We agree that explicit validation against real agent traces would be ideal. No public, large-scale traces of agentic database interactions currently exist, as this is an emerging workload class. The five workloads were synthesized from documented agent behaviors in the literature (e.g., SWE-agent-style software engineering loops, MCTS planning, and simulation rollouts). In revision we will: (1) add a dedicated subsection justifying each parameter range with citations to the source agent papers, (2) include sensitivity analysis sweeping branch depth, mutation rate, and read/write ratio, and (3) explicitly discuss the synthetic nature of the workloads and the resulting limitations on generalizability. These changes will show that the reported trade-offs persist across a range of plausible parameters rather than a single arbitrary point. revision: yes
-
Referee: [§5] §5 (Evaluation Methodology): The reported performance factors lack accompanying details on benchmark implementation, exact workload parameterization, measurement methodology (e.g., how reads are timed as branches deepen), error handling, number of runs, or statistical reporting. Without these, it is not possible to assess whether the data supports the conclusion that no current system supports the representative workloads at scale.
Authors: We accept that the current description of the evaluation is insufficient for full reproducibility and assessment. In the revised manuscript we will expand §5 with: (1) complete benchmark implementation details and a link to the open-source repository, (2) exact macrobenchmark parameter tables for each workload, (3) precise timing methodology for reads at increasing branch depths, (4) error-handling and outlier policies, and (5) full statistical reporting (number of runs, means, standard deviations, and confidence intervals). These additions will allow readers to verify that the performance gaps are measured consistently and support the scalability conclusions. revision: yes
Circularity Check
No circularity: empirical benchmark paper with direct measurements only
full rationale
This is an empirical benchmark and evaluation paper. It characterizes five workloads, designs parameterized macrobenchmarks that execute branch-mutate-evaluate loops, runs them on existing systems (Neon, DoltgreSQL, etc.), and reports observed latency and scalability differences. No equations, derivations, fitted parameters, or predictions are present that could reduce to the inputs by construction. The central claims rest on measured results from the defined benchmarks rather than any self-referential logic or self-citation chain. Workload representativeness is an assumption about external validity, not a circularity in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Antoine Amend. 2020. Modernizing Risk Management Part 1: Streaming Data Ingestion, Rapid Model Development and Monte Carlo Simulations at Scale. https://www.databricks.com/blog/2020/05/27/modernizing-risk-management- part-1-streaming-data-ingestion-rapid-model-development-and-monte- carlo-simulations-at-scale.html. Published May 27, 2020
2020
-
[2]
Elaine Ang. 2025. psycopg2 support. https://github.com/dolthub/doltgresql/ issues/2143
2025
-
[3]
Apache Software Foundation. 2024. Apache Iceberg. https://iceberg.apache.org/. Accessed: 2026-03-01
2024
-
[4]
James Arthur. 2025. Vibe coding with a database in the sandbox. https://electric- sql.com/blog/2025/06/05/database-in-the-sandbox. Published June 5, 2025
2025
-
[5]
Bauplan Labs. 2024. Bauplan. https://www.bauplanlabs.com/. Accessed: 2026- 03-01
2024
-
[6]
Browne, Edward Powley, Daniel Whitehouse, Simon M
Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Peter I. Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. 2012. A Survey of Monte Carlo Tree Search Methods.IEEE Transactions on Computational Intelligence and AI in Games4, 1 (2012), 1–43. https://doi.org/10.1109/TCIAIG.2012.2186810
-
[7]
Haas, and Chris Jermaine
Zhuhua Cai, Zografoula Vagena, Luis Leopoldo Perez, Subramanian Arumugam, Peter J. Haas, and Chris Jermaine. 2013. Simulation of database-valued markov chains using SimSQL. InACM SIGMOD Conference. https://api.semanticscholar. org/CorpusID:18300835
2013
-
[8]
Raouf Chebri. 2022. ketteQ uses Neon branching for scenario analysis. https: //neon.com/blog/database-branching-for-postgres-with-neon. Published Dec 06, 2022
2022
-
[9]
Panayiotis K Chrysanthis and Krithi Ramamritham. 1990. ACTA: A framework for specifying and reasoning about transaction structure and behavior. InPro- ceedings of the 1990 ACM SIGMOD international conference on Management of data. 194–203
1990
-
[10]
Richard Cole, Florian Funke, Leo Giakoumakis, Wey Guy, Alfons Kemper, Stefan Krompass, Harumi Kuno, Raghunath Nambiar, Thomas Neumann, Anisoara Patel, Meikel Poess, Kai-Uwe Sattler, Bernhard Seeger, Jan Takahashi, and Marek Wolski. 2011. Mixed Workload CH-benCHmark. InProceedings of the Fourth International Workshop on Testing Database Systems (DBTest). h...
-
[11]
Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears
Brian F. Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. 2010. Benchmarking cloud serving systems with YCSB. InACM Symposium on Cloud Computing. https://api.semanticscholar.org/CorpusID:2589691
2010
-
[12]
Delta Lake Project. 2024. Delta Lake. https://delta.io/. Accessed: 2026-03-01
2024
-
[13]
Djellel Eddine Difallah, Andrew Pavlo, Carlo Curino, and Philippe Cudré- Mauroux. 2013. OLTP-Bench: An Extensible Testbed for Benchmarking Relational Databases.Proc. VLDB Endow.7 (2013), 277–288. https://api. semanticscholar.org/CorpusID:2612270
2013
-
[14]
Mike Freedman. 2025. Fluid Storage: Forkable, Ephemeral, and Durable Infras- tructure for the Age of Agents. https://www.tigerdata.com/blog/fluid-storage- forkable-ephemeral-durable-infrastructure-age-of-agents
2025
-
[15]
Hector Garcia-Molina and Kenneth Salem. 1987. Sagas.ACM Sigmod Record16, 3 (1987), 249–259
1987
-
[16]
Jim Gray et al. 1981. The transaction concept: Virtues and limitations. InVLDB, Vol. 81. 144–154
1981
-
[17]
Sam Harrison. 2024. Looking at How Replit Agent Handles Databases. https: //neon.com/blog/looking-at-how-replit-agent-handles-databases. Published Nov 08, 2024
2024
-
[18]
Levente Kocsis and Csaba Szepesvári. 2006. Bandit based monte-carlo planning. InEuropean conference on machine learning. Springer, 282–293
2006
- [19]
-
[20]
Kroese, Tim J
Dirk P. Kroese, Tim J. Brereton, Thomas Taimre, and Zdravko I. Botev. 2014. Why the Monte Carlo method is so important today.Wiley Interdisciplinary Reviews: Computational Statistics6 (2014). https://api.semanticscholar.org/CorpusID: 18521840
2014
-
[21]
Peng Li, Xi Rao, Jennifer Blase, Yue Zhang, Xu Chu, and Ce Zhang. 2021. Cleanml: A study for evaluating the impact of data cleaning on ml classification tasks. In 2021 IEEE 37th international conference on data engineering (ICDE). IEEE, 13–24
2021
-
[22]
Qian Li, Peter Kraft, Michael Cafarella, Çağatay Demiralp, Goetz Graefe, Christos Kozyrakis, Michael Stonebraker, Lalith Suresh, Xiangyao Yu, and Matei Zaharia
-
[23]
R3: Record-replay-retroaction for database-backed applications.Proceedings 12 of the VLDB Endowment16, 11 (2023), 3085–3097
2023
- [24]
-
[25]
Wilson Lin. 2026. Scaling Long-Running Autonomous Coding. https://www. cursor.com/blog/scaling-agents. Published January 14, 2026
2026
-
[26]
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, et al
-
[27]
Supporting Our AI Overlords: Redesign- ing Data Systems to be Agent-First
Supporting our ai overlords: Redesigning data systems to be agent-first. arXiv preprint arXiv:2509.00997(2025)
-
[28]
Michael Maddox, David Goehring, Aaron J Elmore, Samuel Madden, Aditya Parameswaran, and Amol Deshpande. 2016. Decibel: The relational dataset branching system. InProceedings of the VLDB Endowment. International Confer- ence on Very Large Data Bases, Vol. 9. 624
2016
-
[29]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Mari- anna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, ...
work page internal anchor Pith review arXiv 2026
-
[30]
JP Morgan et al. 1997. Creditmetrics-technical document.JP Morgan, New York 1 (1997), 102–127
1997
-
[31]
MotherDuck. 2024. MotherDuck. https://motherduck.com/. Accessed: 2026-03- 01
2024
-
[32]
Richard E Murray, Patrick B Ryan, and Stephanie J Reisinger. 2011. Design and validation of a data simulation model for longitudinal healthcare data. InAMIA Annual Symposium Proceedings, Vol. 2011. 1176
2011
-
[33]
Felix Neutatz, Binger Chen, Ziawasch Abedjan, and Eugene Wu. 2021. From Cleaning before ML to Cleaning for ML.IEEE Data Eng. Bull.44, 1 (2021), 24–41
2021
-
[34]
Deniz Preil and Michael Krapp. 2022. Artificial intelligence-based inventory management: a Monte Carlo tree search approach.Annals of Operations Research 308, 1 (2022), 415–439
2022
-
[35]
Erhard Rahm, Hong Hai Do, et al. 2000. Data cleaning: Problems and current approaches.IEEE Data Eng. Bull.23, 4 (2000), 3–13
2000
-
[36]
Sebastian Schelter, Dustin Lange, Philipp Schmidt, Meltem Celikel, and Felix Biessmann. 2018. Automating large-scale data quality verification.pVLDB(2018)
2018
-
[37]
Shafaq Siddiqi, Roman Kern, and Matthias Boehm. 2023. SAGA: A scalable frame- work for optimizing data cleaning pipelines for machine learning applications. Proceedings of the ACM on Management of Data1, 3 (2023), 1–26
2023
-
[38]
Carlota Soto. 2024. Database Branching Workflows: A Guide for Devel- opers. https://neon.com/blog/database-branching-workflows-a-guide-for- developers. Published May 9, 2024
2024
- [39]
-
[40]
Michael Stonebraker, Jim Frew, Kenn Gardels, and Jeff Meredith. 1993. The SEQUOIA 2000 storage benchmark. , 10 pages. https://doi.org/10.1145/170036. 170038
-
[41]
Anomalo team. 2024. Continuous Monitoring for Data Quality: Solutions for Reliable Data. https://www.anomalo.com/blog/continuous-monitoring-for-data- quality-solutions-for-reliable-data
2024
-
[42]
Dolt Team. 2025. Dolt - Using Branches. https://docs.dolthub.com/sql-reference/ version-control/branches
2025
-
[43]
Kimi Team. 2026. Kimi K2.5: Visual Agentic Intelligence. arXiv:2602.02276 [cs.CL] https://arxiv.org/abs/2602.02276
work page internal anchor Pith review arXiv 2026
-
[44]
Neon Team. 2026. Neon Branching - Branch your data the same way you branch your code. https://neon.com/docs/introduction/branching
2026
-
[45]
Xata Team. 2025. Xata Instant Branching: Copy-on-Write branching system for PostgreSQL databases. https://xata.io/documentation/core-concepts/branching
2025
-
[46]
Bob Ternosky. 2026. Instant Per-Branch Databases with PostgreSQL 18’s clone file copy and Copy-on-Write Filesystems. https://medium.com/axial- engineering/instant-per-branch-databases-with-postgresql-18s-clone-file- copy-and-copy-on-write-filesystems-1b1930bddbaa
2026
-
[47]
Joe Thom. 2025. Building Production-Ready Apps with Automated Database Migrations on Replit. https://blog.replit.com/production-databases-automated- migrations. Published December 12, 2025
2025
-
[48]
Treeverse. 2024. lakeFS. https://lakefs.io/. Accessed: 2026-03-01
2024
-
[49]
Edoardo Vittori, Amarildo Likmeta, and Marcello Restelli. 2021. Monte carlo tree search for trading and hedging. InProceedings of the Second ACM International Conference on AI in Finance. 1–9
2021
-
[50]
Gerhard Weikum and Hans-Jörg Schek. 1992. Concepts and applications of multilevel transactions and open nested transactions
1992
-
[51]
Jiakai Xu, Tianle Zhou, Eugene Wu, and Kostis Kaffes. 2025. Toward Systems Foundations for Agentic Exploration.SOSP SSA Workshop(2025)
2025
- [52]
- [53]
-
[54]
Xuanhe Zhou, Guoliang Li, Chengliang Chai, and Jianhua Feng. 2022. A Learned Query Rewrite System using Monte Carlo Tree Search.Proceedings of the VLDB Endowment15, 1 (2022). https://doi.org/10.14778/3485450.3485456
-
[55]
Kexin Zhu, Michael Whittaker, Srdjan Petrovic, Robert Grandl, and Sanjay Ghe- mawat. 2025. Vive la Différence: Practical Diff Testing of Stateful Applica- tions.Proc. VLDB Endow.18 (2025), 2018–2030. https://api.semanticscholar.org/ CorpusID:280693134 13 A MACROBENCHMARK QUERIES This section provides examples of the queries used in the mac- robenchmark. A...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.