Recognition: unknown
Beyond Overlap Metrics: Rewarding Reasoning and Preferences for Faithful Multi-Role Dialogue Summarization
Pith reviewed 2026-05-10 06:42 UTC · model grok-4.3
The pith
Distilling reasoning traces and blending metric signals with human-aligned criteria in a GRPO reward produces more factually faithful multi-role dialogue summaries than optimizing overlap metrics alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A framework that first distills structured reasoning traces such as step-by-step inferences and reflections from a large teacher model for staged supervised fine-tuning, then optimizes via GRPO under a dual-principle reward blending metric-based signals with human-aligned criteria for key information coverage, implicit inference, factual faithfulness, and conciseness, yields multi-role dialogue summaries that preserve semantic consistency and achieve superior factual faithfulness and preference alignment compared with baselines trained solely on overlap metrics.
What carries the argument
The dual-principle reward applied during GRPO optimization, which integrates automatic metric signals with targeted human-aligned criteria for coverage, inference, faithfulness, and conciseness after initialization on distilled reasoning traces from a teacher model.
Load-bearing premise
That blending metric-based signals with human-aligned criteria for coverage, inference, faithfulness, and conciseness in the reward will drive genuine improvements in faithfulness rather than reward hacking or overfitting to the chosen preference model.
What would settle it
Human evaluation of factual accuracy on a held-out set of multi-role dialogues, comparing summaries from the proposed method against standard baselines to test whether reported gains in model-based preference alignment correspond to actual human judgments of faithfulness.
Figures


read the original abstract
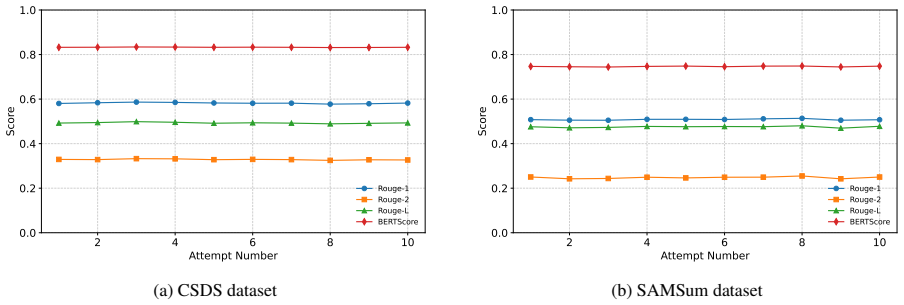
Multi-role dialogue summarization requires modeling complex interactions among multiple speakers while preserving role-specific information and factual consistency. However, most existing methods optimize for automatic metrics such as ROUGE and BERTScore, which favor surface-level imitation of references rather than genuine gains in faithfulness or alignment with human preferences. We propose a novel framework that couples explicit cognitive-style reasoning with reward-based optimization for multi-role dialogue summarization. Our method first distills structured reasoning traces (e.g., step-by-step inferences and intermediate reflections) from a large teacher model and uses them as auxiliary supervision to initialize a reasoning-aware summarizer via staged supervised fine-tuning. It then applies GRPO with a dual-principle reward that blends metric-based signals with human-aligned criteria targeting key information coverage, implicit inference, factual faithfulness, and conciseness. Experiments on multilingual multi-role dialogue benchmarks show that our method matches strong baselines on ROUGE and BERTScore. Specifically, results on CSDS confirm the framework's stability in semantic consistency, while in-depth analysis on SAMSum demonstrates clear gains in factual faithfulness and model-based preference alignment. These findings underscore the value of reasoning-aware and preference-aware training for reliable dialogue summarization. Checkpoints and datasets are available at https://huggingface.co/collections/NebulaPixel/summorchestra-multirole-summary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for multi-role dialogue summarization that first performs staged supervised fine-tuning using structured reasoning traces distilled from a large teacher model, followed by GRPO optimization with a dual-principle reward that combines metric-based signals with human-aligned criteria for coverage, implicit inference, factual faithfulness, and conciseness. The authors claim that this approach matches strong baselines on ROUGE and BERTScore on multilingual benchmarks such as CSDS, while showing gains in factual faithfulness and model-based preference alignment on SAMSum.
Significance. If the reported gains in faithfulness hold under independent verification, the work would be significant as it attempts to address the limitations of standard overlap metrics in dialogue summarization by incorporating explicit reasoning and preference alignment. The public release of checkpoints and datasets supports reproducibility and further research in the area.
major comments (2)
- [Abstract] Abstract: The claim of 'clear gains in factual faithfulness' on SAMSum lacks supporting details on evaluation protocol, error bars, statistical tests, or ablation studies; this undermines assessment of whether improvements are robust, as the abstract provides no quantitative breakdown or verification method beyond model-based preference alignment.
- [Abstract and Experiments section] Abstract and Experiments section: The dual-principle reward blends metric signals with human-aligned criteria including model-based preference alignment for faithfulness, yet the reported gains are also measured via model-based preference alignment; this creates a circularity risk where improvements may reflect optimization to the training reward rather than independent factual consistency, with no mention of human annotations or cross-model evaluations to break the dependency.
minor comments (2)
- [Abstract] The abstract refers to 'in-depth analysis on SAMSum' without specifying the exact metrics, human evaluation details, or how post-hoc analysis was performed.
- No description of how the preference model was trained or validated independently of the evaluation metrics is provided, which would clarify the separation between training and test signals.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and indicate planned revisions to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'clear gains in factual faithfulness' on SAMSum lacks supporting details on evaluation protocol, error bars, statistical tests, or ablation studies; this undermines assessment of whether improvements are robust, as the abstract provides no quantitative breakdown or verification method beyond model-based preference alignment.
Authors: We agree that the abstract would benefit from more context to support the claim of gains. In the revised manuscript, we will expand the abstract to include a brief quantitative breakdown of the faithfulness improvements (e.g., specific percentage gains) and explicitly reference the evaluation protocol, ablation studies on reasoning distillation and dual-reward components, and multiple-run results detailed in the Experiments section. We will also add error bars and a note on statistical significance testing to demonstrate robustness. These changes will make the abstract more self-contained while maintaining its summary nature. revision: yes
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: The dual-principle reward blends metric signals with human-aligned criteria including model-based preference alignment for faithfulness, yet the reported gains are also measured via model-based preference alignment; this creates a circularity risk where improvements may reflect optimization to the training reward rather than independent factual consistency, with no mention of human annotations or cross-model evaluations to break the dependency.
Authors: We acknowledge the potential circularity concern. The dual-principle reward integrates multiple signals during GRPO training, but we will revise the manuscript to clarify that the evaluation of factual faithfulness uses a distinct model-based judge with fixed, non-training-tied criteria. We will add cross-model evaluations employing an alternative LLM preference scorer not involved in optimization to verify independence. While the paper does not include human annotations (as the focus was on scalable automated methods aligned with existing benchmarks), we will explicitly discuss this as a limitation and highlight corroborating gains on non-preference metrics such as ROUGE on CSDS. These clarifications and additions will appear in the revised Experiments and Discussion sections. revision: partial
- We cannot provide human annotations for factual faithfulness on SAMSum, as no such annotations were collected in this study.
Circularity Check
No significant circularity detected
full rationale
The paper outlines a staged training pipeline—distilling reasoning traces from a teacher model for SFT initialization, followed by GRPO using a dual-principle reward that combines standard metrics with human-aligned criteria for coverage, inference, faithfulness, and conciseness—then reports experimental results on ROUGE, BERTScore, and additional SAMSum analysis for faithfulness and preference alignment. No equations, self-citations, or load-bearing steps in the abstract or described method reduce the claimed improvements directly to the training inputs or reward model by construction. The evaluation relies on external benchmarks and does not rename or refit the same quantities as predictions; the derivation chain remains independent of its own fitted signals.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Structured reasoning traces distilled from a large teacher model provide useful auxiliary supervision for initializing a reasoning-aware summarizer.
- domain assumption A dual-principle reward blending metric signals with human-aligned criteria for coverage, inference, faithfulness, and conciseness will improve factual consistency.
Reference graph
Works this paper leans on
-
[1]
From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan. From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge. Proceedings of the 2025 Conference on Empirical Methods ...
-
[2]
Yu, Tian and Zhang, Shaolei and Feng, Yang. Truth-Aware Context Selection: Mitigating Hallucinations of Large Language Models Being Misled by Untruthful Contexts. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.645
-
[3]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[4]
Findings of the association for computational linguistics: ACL 2023 , pages=
RHO: Reducing hallucination in open-domain dialogues with knowledge grounding , author=. Findings of the association for computational linguistics: ACL 2023 , pages=
2023
-
[5]
Computational Linguistics , volume=
Punctuation as implicit annotations for Chinese word segmentation , author=. Computational Linguistics , volume=. 2009 , publisher=
2009
-
[6]
BERTScore: Evaluating Text Generation with BERT
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
work page internal anchor Pith review arXiv 1904
-
[7]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[8]
doi:10.57967/HF/3240 , urldate =
Miaoran Li and Rogger Luo and Ofer Mendelevitch , title =. doi:10.57967/hf/3240 , publisher =
-
[9]
Worldpm: Scaling human preference modeling.arXiv preprint arXiv:2505.10527, 2025
WorldPM: Scaling Human Preference Modeling , author=. arXiv preprint arXiv:2505.10527 , year=
-
[10]
Chen, Jiaao and Yang, Diyi. Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.336
-
[11]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,
A Survey on Dialogue Summarization: Recent Advances and New Frontiers , author =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,. 2022 , month =. doi:10.24963/ijcai.2022/764 , url =
-
[12]
TWEETSUMM - A Dialog Summarization Dataset for Customer Service
Feigenblat, Guy and Gunasekara, Chulaka and Sznajder, Benjamin and Joshi, Sachindra and Konopnicki, David and Aharonov, Ranit. TWEETSUMM - A Dialog Summarization Dataset for Customer Service. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.24
-
[13]
Lulu Zhao and Fujia Zheng and Keqing He and Weihao Zeng and Yuejie Lei and Huixing Jiang and Wei Wu and Weiran Xu and Jun Guo and Fanyu Meng , title =. CoRR , volume =. 2021 , url =. 2110.12680 , timestamp =
-
[14]
Wang, Yiming and Zhang, Zhuosheng and Wang, Rui. Element-aware Summarization with Large Language Models: Expert-aligned Evaluation and Chain-of-Thought Method. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.482
-
[15]
Dialogue Summarization with Mixture of Experts based on Large Language Models
Tian, Yuanhe and Xia, Fei and Song, Yan. Dialogue Summarization with Mixture of Experts based on Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.385
-
[16]
Zhang, Shengyu and Dong, Linfeng and Li, Xiaoya and Zhang, Sen and Sun, Xiaofei and Wang, Shuhe and Li, Jiwei and Hu, Runyi and Zhang, Tianwei and Wang, Guoyin and Wu, Fei , title =. ACM Comput. Surv. , month = nov, keywords =. 2025 , publisher =. doi:10.1145/3777411 , abstract =
-
[17]
Ramprasad, Sanjana and Ferracane, Elisa and Lipton, Zachary. Analyzing LLM Behavior in Dialogue Summarization: Unveiling Circumstantial Hallucination Trends. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.677
-
[18]
Lewis, Mike and Liu, Yinhan and Goyal, Naman and Ghazvininejad, Marjan and Mohamed, Abdelrahman and Levy, Omer and Stoyanov, Veselin and Zettlemoyer, Luke. BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguisti...
-
[19]
, title =
Zhang, Jingqing and Zhao, Yao and Saleh, Mohammad and Liu, Peter J. , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[20]
Ming Zhong and Yang Liu and Yichong Xu and Chenguang Zhu and Michael Zeng , title =. Thirty-Sixth. 2022 , url =. doi:10.1609/AAAI.V36I10.21432 , timestamp =
-
[21]
Keyan Jin and Yapeng Wang and Leonel Santos and Tao Fang and Xu Yang and Sio Kei Im and Hugo Gon. Reasoning or not?. Expert Syst. Appl. , volume =. 2026 , url =. doi:10.1016/J.ESWA.2025.129831 , timestamp =
-
[22]
Hierarchical Attention Adapter for Abstractive Dialogue Summarization
Li, Raymond and Li, Chuyuan and Murray, Gabriel and Carenini, Giuseppe. Hierarchical Attention Adapter for Abstractive Dialogue Summarization. Proceedings of The 5th New Frontiers in Summarization Workshop. 2025. doi:10.18653/v1/2025.newsum-main.2
-
[23]
Lu, Yen-Ju and Hu, Ting-Yao and Koppula, Hema Swetha and Pouransari, Hadi and Chang, Jen-Hao Rick and Xia, Yin and Kong, Xiang and Zhu, Qi and Wang, Xiaoming Simon and Tuzel, Oncel and Vemulapalli, Raviteja. Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization. Findings of the Association for Co...
-
[24]
CPO : Addressing Reward Ambiguity in Role-playing Dialogue via Comparative Policy Optimization
Ye, Jing and Wang, Rui and Wu, Yuchuan and Ma, Victor and Fang, Feiteng and Huang, Fei and Li, Yongbin. CPO : Addressing Reward Ambiguity in Role-playing Dialogue via Comparative Policy Optimization. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.18
-
[25]
Zhuohao Yu and Jiali Zeng and Weizheng Gu and Yidong Wang and Jindong Wang and Fandong Meng and Jie Zhou and Yue Zhang and Shikun Zhang and Wei Ye , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.03637 , eprinttype =. 2506.03637 , timestamp =
-
[26]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.03300 , eprinttype =. 2402.03300 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[27]
Gabriel Murray and Steve Renals and Jean Carletta , title =. 9th European Conference on Speech Communication and Technology, INTERSPEECH-Eurospeech 2005, Lisbon, Portugal, September 4-8, 2005 , pages =. 2005 , url =. doi:10.21437/INTERSPEECH.2005-59 , timestamp =
-
[28]
A keyphrase based approach to interactive meeting summarization , booktitle =
Korbinian Riedhammer and Beno. A keyphrase based approach to interactive meeting summarization , booktitle =. 2008 , url =. doi:10.1109/SLT.2008.4777863 , timestamp =
-
[29]
Combining Graph Degeneracy and Submodularity for Unsupervised Extractive Summarization
Tixier, Antoine and Meladianos, Polykarpos and Vazirgiannis, Michalis. Combining Graph Degeneracy and Submodularity for Unsupervised Extractive Summarization. Proceedings of the Workshop on New Frontiers in Summarization. 2017. doi:10.18653/v1/W17-4507
-
[30]
Keep Meeting Summaries on Topic: Abstractive Multi-Modal Meeting Summarization
Li, Manling and Zhang, Lingyu and Ji, Heng and Radke, Richard J. Keep Meeting Summaries on Topic: Abstractive Multi-Modal Meeting Summarization. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1210
-
[31]
A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining
Zhu, Chenguang and Xu, Ruochen and Zeng, Michael and Huang, Xuedong. A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.19
-
[32]
Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence,
Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting Summarization , author =. Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence,. 2021 , month =. doi:10.24963/ijcai.2021/524 , url =
-
[33]
S umm ^N : A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
Zhang, Yusen and Ni, Ansong and Mao, Ziming and Wu, Chen Henry and Zhu, Chenguang and Deb, Budhaditya and Awadallah, Ahmed and Radev, Dragomir and Zhang, Rui. S umm ^N : A Multi-Stage Summarization Framework for Long Input Dialogues and Documents. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
-
[34]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Re-FRAME the Meeting Summarization SCOPE: Fact-Based Summarization and Personalization via Questions , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[35]
Abstractive Meeting Summarization: A Survey
Rennard, Virgile and Shang, Guokan and Hunter, Julie and Vazirgiannis, Michalis. Abstractive Meeting Summarization: A Survey. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00578
-
[36]
Improving Factual Consistency of News Summarization by Contrastive Preference Optimization
Feng, Huawen and Fan, Yan and Liu, Xiong and Lin, Ting-En and Yao, Zekun and Wu, Yuchuan and Huang, Fei and Li, Yongbin and Ma, Qianli. Improving Factual Consistency of News Summarization by Contrastive Preference Optimization. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.648
-
[37]
Eunice Akani and Beno. Increasing faithfulness in human-human dialog summarization with Spoken Language Understanding tasks , journal =. 2024 , url =. doi:10.48550/ARXIV.2409.10070 , eprinttype =. 2409.10070 , timestamp =
-
[38]
doi: 10.18653/v1/2024.emnlp-main.3
Joonho Yang and Seunghyun Yoon and Byeongjeong Kim and Hwanhee Lee , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.3 , timestamp =
-
[39]
Discourse-Driven Evaluation: Unveiling Factual Inconsistency in Long Document Summarization
Zhong, Yang and Litman, Diane. Discourse-Driven Evaluation: Unveiling Factual Inconsistency in Long Document Summarization. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.103
-
[40]
Disentangling Length from Quality in Direct Preference Optimization
Park, Ryan and Rafailov, Rafael and Ermon, Stefano and Finn, Chelsea. Disentangling Length from Quality in Direct Preference Optimization. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.297
-
[41]
Direct Preference Optimization with an Offset
Amini, Afra and Vieira, Tim and Cotterell, Ryan. Direct Preference Optimization with an Offset. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.592
-
[42]
Tajiri, Manato and Inaba, Michimasa. Refining Text Generation for Realistic Conversational Recommendation via Direct Preference Optimization. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1456
-
[43]
Learning to Summarize from LLM -generated Feedback
Song, Hwanjun and Yun, Taewon and Lee, Yuho and Oh, Jihwan and Lee, Gihun and Cai, Jason and Su, Hang. Learning to Summarize from LLM -generated Feedback. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/202...
-
[44]
Ye, Yuxuan and Santos-Rodriguez, Raul and Simpson, Edwin. Optimising Factual Consistency in Summarisation via Preference Learning from Multiple Imperfect Metrics. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.940
-
[45]
Bansal, Hritik and Suvarna, Ashima and Bhatt, Gantavya and Peng, Nanyun and Chang, Kai-Wei and Grover, Aditya. Comparing Bad Apples to Good Oranges Aligning Large Language Models via Joint Preference Optimization. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.39
-
[46]
CSDS : A Fine-Grained C hinese Dataset for Customer Service Dialogue Summarization
Lin, Haitao and Ma, Liqun and Zhu, Junnan and Xiang, Lu and Zhou, Yu and Zhang, Jiajun and Zong, Chengqing. CSDS : A Fine-Grained C hinese Dataset for Customer Service Dialogue Summarization. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.365
-
[47]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
SAMS um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization
Gliwa, Bogdan and Mochol, Iwona and Biesek, Maciej and Wawer, Aleksander. SAMS um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization. Proceedings of the 2nd Workshop on New Frontiers in Summarization. 2019. doi:10.18653/v1/D19-5409
-
[49]
North American Chapter of the Association for Computational Linguistics , year=
Guideline Compliance in Task-Oriented Dialogue: The Chained Prior Approach , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[50]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[51]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[52]
ArXiv , year=
Reasoning Scaffolding: Distilling the Flow of Thought from LLMs , author=. ArXiv , year=
-
[53]
ArXiv , year=
Distilling the Knowledge in a Neural Network , author=. ArXiv , year=
-
[54]
Artificial Intelligence Review , year=
Knowledge distillation and dataset distillation of large language models: emerging trends, challenges, and future directions , author=. Artificial Intelligence Review , year=
-
[55]
Transactions of the Association for Computational Linguistics , year=
SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization , author=. Transactions of the Association for Computational Linguistics , year=
-
[56]
Conference on Empirical Methods in Natural Language Processing , year=
Evaluating the Factual Consistency of Abstractive Text Summarization , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[57]
ArXiv , year=
RewardDance: Reward Scaling in Visual Generation , author=. ArXiv , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.