Recognition: unknown
Fringe Projection Based Vision Pipeline for Autonomous Hard Drive Disassembly
Pith reviewed 2026-05-10 06:53 UTC · model grok-4.3
The pith
A single fringe projection camera-projector pair supplies pixel-aligned depth maps and instance masks for robotic hard drive disassembly without separate registration steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that fringe projection profilometry can serve simultaneously as the primary depth sensor and as the imaging source for a real-time instance segmentation network. Selective triggering of a learned depth-completion model (Depth Anything V2 Base) fills gaps only when the fringe pattern fails, and the entire stack is optimized for deployment. On the evaluation data this yields box mAP@50 of 0.960 and mask mAP@50 of 0.957 for segmentation, depth RMSE of 2.317 mm, and a combined latency of 12.86 ms (77.7 FPS) for the platter-facing inference path. The approach avoids the registration overhead of typical RGB-D pipelines and is augmented by sim-to-real transfer learning.
What carries the argument
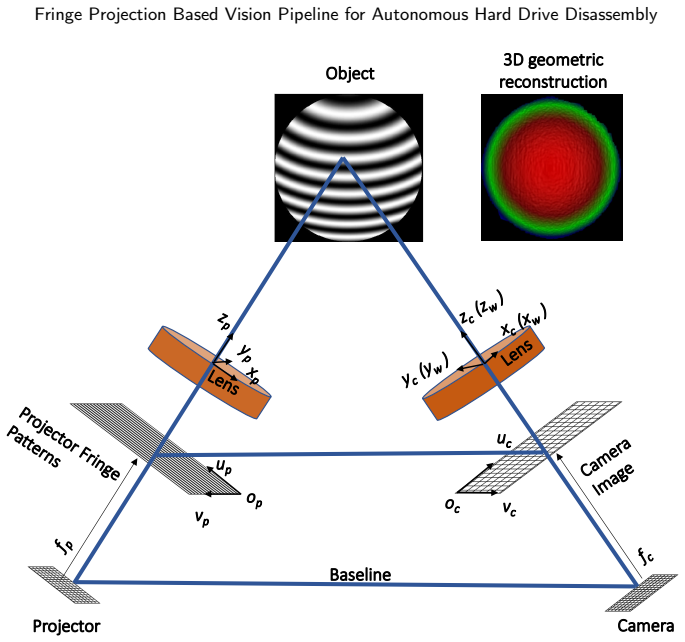
Fringe Projection Profilometry (FPP) module that re-uses the same camera-projector hardware for both depth sensing and instance segmentation, with selective depth completion triggered only on FPP failure regions.
If this is right
- Pixel-wise alignment between depth and segmentation masks removes the need for extrinsic calibration between separate sensors.
- Real-time performance at 77.7 FPS supports closed-loop control of robotic arms during disassembly.
- High segmentation accuracy (0.96 mAP) enables precise localization of small fasteners and platters.
- The public synthetic HDD dataset can reduce data-collection costs for similar recycling tasks.
- Selective triggering limits the computational cost of depth completion to only the regions where FPP fails.
Where Pith is reading between the lines
- The same optical architecture could be adapted to other small electronic devices if the fringe pattern density and segmentation classes are re-tuned.
- Robustness testing on drives with reflective coatings or heavy wear would be a direct next measurement to confirm the weakest assumption.
- End-to-end integration with force-controlled grippers could be tested by feeding the aligned 3D masks directly into motion planning.
Load-bearing premise
That selective depth completion can be triggered reliably across real-world variations in drive models, lighting, and surface conditions without introducing systematic geometric errors.
What would settle it
Deploy the pipeline on a fresh collection of hard drives never seen in training or simulation, under changed ambient lighting and surface finishes, and check whether segmentation mAP@50 falls below 0.90 or depth RMSE exceeds 5 mm.
Figures









read the original abstract
Unrecovered e-waste represents a significant economic loss. Hard disk drives (HDDs) comprise a valuable e-waste stream necessitating robotic disassembly. Automating the disassembly of HDDs requires holistic 3D sensing, scene understanding, and fastener localization, however current methods are fragmented, lack robust 3D sensing, and lack fastener localization. We propose an autonomous vision pipeline which performs 3D sensing using a Fringe Projection Profilometry (FPP) module, with selective triggering of a depth completion module where FPP fails, and integrates this module with a lightweight, real-time instance segmentation network for scene understanding and critical component localization. By utilizing the same FPP camera-projector system for both our depth sensing and component localization modules, our depth maps and derived 3D geometry are inherently pixel-wise aligned with the segmentation masks without registration, providing an advantage over RGB-D perception systems common in industrial sensing. We optimize both our trained depth completion and instance segmentation networks for deployment-oriented inference. The proposed system achieves a box mAP@50 of 0.960 and mask mAP@50 of 0.957 for instance segmentation, while the selected depth completion configuration with the Depth Anything V2 Base backbone achieves an RMSE of 2.317 mm and MAE of 1.836 mm; the Platter Facing learned inference stack achieved a combined latency of 12.86 ms and a throughput of 77.7 Frames Per Second (FPS) on the evaluation workstation. Finally, we adopt a sim-to-real transfer learning approach to augment our physical dataset. The proposed perception pipeline provides both high-fidelity semantic and spatial data which can be valuable for downstream robotic disassembly. The synthetic dataset developed for HDD instance segmentation will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a vision pipeline for autonomous hard disk drive (HDD) disassembly that integrates Fringe Projection Profilometry (FPP) for primary 3D sensing, with selective triggering of monocular depth completion (Depth Anything V2 Base) on FPP failure, and a lightweight real-time instance segmentation network for scene understanding and fastener/component localization. The approach exploits the shared camera-projector hardware to achieve inherent pixel-wise alignment between depth maps and segmentation masks without registration. It reports box mAP@50 of 0.960 and mask mAP@50 of 0.957 for segmentation, depth RMSE of 2.317 mm and MAE of 1.836 mm, combined latency of 12.86 ms and 77.7 FPS for the platter-facing stack, and employs sim-to-real transfer to augment the physical dataset, with plans to release the synthetic data publicly.
Significance. If the hybrid pipeline and reported metrics hold, the work offers a practical contribution to robotic e-waste recycling by delivering an integrated, aligned semantic-spatial perception system optimized for real-time deployment. The explicit quantitative results on segmentation accuracy, depth precision, and inference throughput, combined with the public dataset release, provide concrete value for downstream robotics tasks. The emphasis on hardware-level alignment and inference optimization are notable strengths.
major comments (2)
- [Method section (hybrid depth pipeline description)] The selective triggering of depth completion is load-bearing for the hybrid 3D sensing claims and the reported RMSE/MAE values, yet the manuscript provides no explicit decision rule, threshold value, false-positive/negative rates, or validation experiments quantifying depth errors introduced on real HDDs under varying reflectivity, lighting, surface wear, or model diversity. Without this, the end-to-end accuracy and robustness of the pipeline remain unsubstantiated.
- [Experiments (sim-to-real and dataset)] The sim-to-real transfer approach for instance segmentation is central to the generalization and dataset augmentation claims, but no domain-gap metrics, cross-model hold-out results on physical data from different HDD models, or quantitative comparison of synthetic vs. real performance are reported. This leaves the effectiveness of the transfer unquantified and risks overstatement of the mAP figures.
minor comments (3)
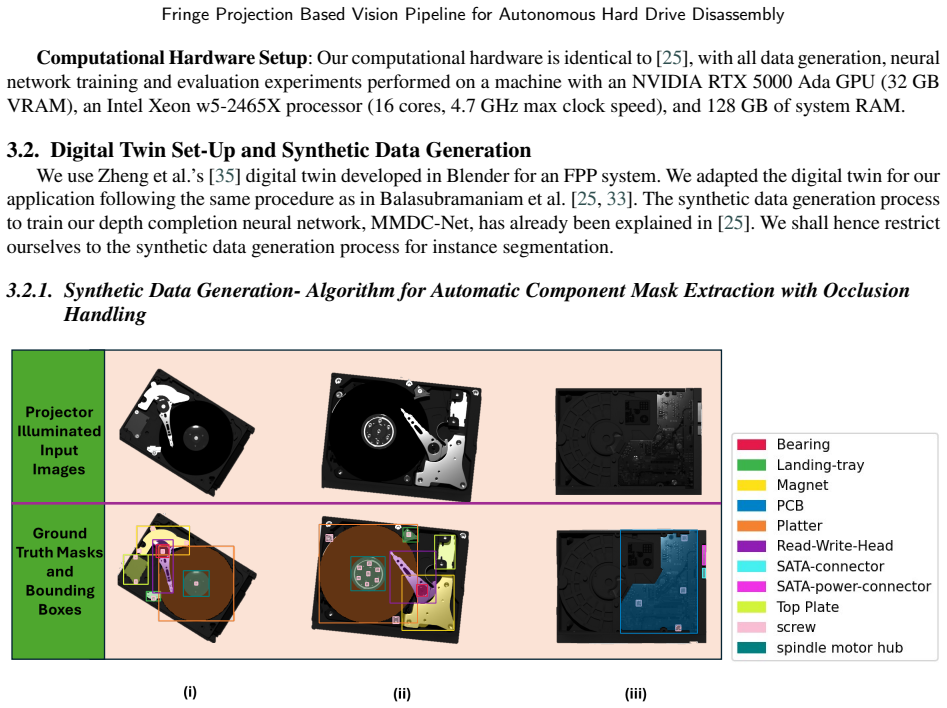
- [Abstract and Experiments] Dataset size, number of HDD models, diversity of conditions, and train/test split details are not provided, which would better contextualize the mAP@50, RMSE, and FPS metrics.
- [Experiments] Baseline comparisons to alternative depth sensing (e.g., standard RGB-D or other completion methods) or segmentation networks are absent, limiting assessment of the advance over the fragmented methods noted in the introduction.
- [Experiments] Failure-case analysis for the full pipeline (e.g., when FPP fails and completion is triggered) would strengthen the practical claims.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas for improvement in the manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Method section (hybrid depth pipeline description)] The selective triggering of depth completion is load-bearing for the hybrid 3D sensing claims and the reported RMSE/MAE values, yet the manuscript provides no explicit decision rule, threshold value, false-positive/negative rates, or validation experiments quantifying depth errors introduced on real HDDs under varying reflectivity, lighting, surface wear, or model diversity. Without this, the end-to-end accuracy and robustness of the pipeline remain unsubstantiated.
Authors: We thank the referee for highlighting this important aspect. Upon review, we recognize that the manuscript lacks an explicit description of the decision rule for selective triggering of the depth completion module. The triggering is intended to activate when FPP fails, but specific thresholds and validation were omitted. To address this, we will update the Method section with a detailed explanation of the decision criteria, including threshold values and metrics used to detect FPP failure. Additionally, we will incorporate validation experiments on real HDDs under varied conditions (reflectivity, lighting, surface wear, model diversity) and report the associated false-positive and false-negative rates for the triggering logic. This will substantiate the end-to-end accuracy and robustness of the hybrid pipeline. revision: yes
-
Referee: [Experiments (sim-to-real and dataset)] The sim-to-real transfer approach for instance segmentation is central to the generalization and dataset augmentation claims, but no domain-gap metrics, cross-model hold-out results on physical data from different HDD models, or quantitative comparison of synthetic vs. real performance are reported. This leaves the effectiveness of the transfer unquantified and risks overstatement of the mAP figures.
Authors: We appreciate the referee's point regarding the sim-to-real transfer. The current manuscript reports performance on the augmented dataset but does not provide domain-gap metrics, cross-model hold-out results, or direct comparisons of synthetic versus real performance. We will revise the Experiments section to include these quantitative analyses, such as domain adaptation metrics, performance on hold-out physical data from different HDD models, and ablation studies comparing models trained with and without the synthetic data. This will better quantify the effectiveness of the transfer learning approach and support the reported mAP values. revision: yes
Circularity Check
No circularity: empirical pipeline with direct metric measurements
full rationale
The paper describes an integrated hardware-software vision system evaluated via standard held-out test metrics (box/mask mAP@50, RMSE/MAE in mm, latency/FPS). No equations, derivations, or 'predictions' are presented that reduce to fitted inputs by construction. Selective triggering and sim-to-real augmentation are described as engineering choices without self-referential definitions or load-bearing self-citations that close the loop on the reported numbers. All performance figures are direct empirical outcomes on test data, not re-expressions of training objectives or prior author results.
Axiom & Free-Parameter Ledger
free parameters (2)
- depth-completion triggering threshold
- network training hyperparameters
axioms (2)
- domain assumption FPP yields accurate depth maps when projected patterns are reliably captured by the camera
- domain assumption Sim-to-real transfer improves robustness of segmentation and depth models on physical HDDs
Reference graph
Works this paper leans on
-
[1]
C. P. Baldé, R. Kuehr, T. Yamamoto, R. McDonald, E. D’Angelo, S. Althaf, G. Bel, O. Deubzer, E. Fernandez-Cubillo, V. Forti, V. Gray, S. Herat, S. Honda, G. Iattoni, D. S. Khetriwal, V. Luda di Cortemiglia, Y. Lobuntsova, I. Nnorom, N. Pralat, M. Wagner, The global e-waste monitor 2024, Tech. rep., United Nations Institute for Training and Research (UNITA...
2024
-
[2]
M. Sabbaghi, W. Cade, W. Olson, S. Behdad, The Global Flow of Hard Disk Drives: Quantifying the Concept of Value Leakage in E-waste RecoverySystems,JournalofIndustrialEcology23(3)(2019)560–573,_eprint:https://onlinelibrary.wiley.com/doi/pdf/10.1111/jiec.12765. doi:10.1111/jiec.12765. URLhttps://onlinelibrary.wiley.com/doi/abs/10.1111/jiec.12765
-
[3]
URLhttps://doi.org/10.1021/acs.est.5b02264
K.Habib,K.Parajuly,H.Wenzel,TrackingtheFlowofResourcesinElectronicWaste-TheCaseofEnd-of-LifeComputerHardDiskDrives, Environmental Science & Technology 49 (20) (2015) 12441–12449.doi:10.1021/acs.est.5b02264. URLhttps://doi.org/10.1021/acs.est.5b02264
-
[4]
URLhttps://www.sciencedirect.com/science/article/pii/S0959652619342477
H.Tanvar,A.Barnwal,N.Dhawan,Characterizationandevaluationofdiscardedharddiscdrivesforrecoveryofcopperandrareearthvalues, Journal of Cleaner Production 249 (2020) 119377.doi:10.1016/j.jclepro.2019.119377. URLhttps://www.sciencedirect.com/science/article/pii/S0959652619342477
- [5]
-
[6]
T. Barman, S. Coleman, D. Kerr, S. Harrigan, J. Quinn, Optimizing Industrial E-Waste Recycling with Attention-Driven Deep Learning for PCB Segmentation Using Hyperspectral Imaging, in: 2025 IEEE Symposia on Computational Intelligence for Energy, Transport and Environmental Sustainability (CIETES), 2025, pp. 1–7.doi:10.1109/CIETES63869.2025.10995066. URLht...
-
[7]
A. F. Hussein, W. M. Hamanah, M. A. Abido, Harnessing hyperspectral imaging and deep learning for advanced e-waste classification using three spectral bands, Results in Engineering 27 (2025) 106110.doi:10.1016/j.rineng.2025.106110. URLhttps://www.sciencedirect.com/science/article/pii/S2590123025021826
-
[8]
A. Picon, P. Galan, A. Bereciartua-Perez, L. Benito-del Valle, On the analysis of adapting deep learning methods to hyperspectral imaging. Use case for WEEE recycling and dataset, Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy 330 (2025) 125665. doi:10.1016/j.saa.2024.125665. URLhttps://www.sciencedirect.com/science/article/pii/S13861...
-
[9]
M. Mohsin, S. Rovetta, F. Masulli, A. Cabri, Heatmap Visualization for Deep Learning Analysis of Waste Printed Circuit Boards, in: 2025 IEEE 2nd International Conference on Electronics, Communications and Intelligent Science (ECIS), 2025, pp. 1–5.doi:10.1109/ ECIS65594.2025.11086768. URLhttps://ieeexplore.ieee.org/document/11086768
-
[10]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, D. Batra, Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization, in: 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 618–626, iSSN: 2380-7504. doi:10.1109/ICCV.2017.74. URLhttps://ieeexplore.ieee.org/document/8237336
-
[11]
S. Ahmed, D. F. Sanam, Exploration of an E-waste Prediction Model for Collection System Optimization Using Deep Learning Models in E-waste Management Facilities, in: 2025 2nd International Conference on Next-Generation Computing, IoT and Machine Learning (NCIM), 2025, pp. 1–6.doi:10.1109/NCIM65934.2025.11160027. URLhttps://ieeexplore.ieee.org/abstract/doc...
-
[12]
Jahanian, Q
A. Jahanian, Q. H. Le, K. Youcef-Toumi, D. Tsetserukou, See the E-Waste! Training Visual Intelligence to See Dense Circuit Boards for Recycling, 2019, pp. 0–0. URLhttps://openaccess.thecvf.com/content_CVPRW_2019/html/cv4gc/Jahanian_See_the_E- Waste_Training_Visual_Intelligence_to_See_Dense_Circuit_CVPRW_2019_paper.html
2019
-
[13]
C. Liu, B. Balasubramaniam, N. A. Yancey, M. H. Severson, A. Shine, P. Bove, B. Li, X. Liang, M. Zheng, RAISE: A Robot-Assisted SelectIve Disassembly and Sorting System for End-of-Life Phones, Resources, Conservation and Recycling 225 (2026) 108609.doi: 10.1016/j.resconrec.2025.108609. URLhttps://www.sciencedirect.com/science/article/pii/S0921344925004860
-
[14]
G. Foo, S. Kara, M. Pagnucco, Screw detection for disassembly of electronic waste using reasoning and re-training of a deep learning model, Procedia CIRP 98 (2021) 666–671.doi:10.1016/j.procir.2021.01.172. URLhttps://www.sciencedirect.com/science/article/pii/S2212827121002031
-
[15]
B. Karbouj, G. A. Topalian-Rivas, J. Krüger, Comparative Performance Evaluation of One-Stage and Two-Stage Object Detectors for Screw Head Detection and Classification in Disassembly Processes, Procedia CIRP 122 (2024) 527–532.doi:10.1016/j.procir.2024.01.077. URLhttps://www.sciencedirect.com/science/article/pii/S2212827124001021
-
[16]
S. Puttero, A. Nassehi, E. Verna, G. Genta, M. Galetto, Automatic object detection for disassembly and recycling of electronic board components, Procedia CIRP 127 (2024) 206–211.doi:10.1016/j.procir.2024.07.036. URLhttps://www.sciencedirect.com/science/article/pii/S2212827124003457
-
[17]
D. P. Brogan, N. M. DiFilippo, M. K. Jouaneh, Deep learning computer vision for robotic disassembly and servicing applications, Array 12 (2021) 100094.doi:10.1016/j.array.2021.100094. URLhttps://www.sciencedirect.com/science/article/pii/S2590005621000394
-
[18]
H. Zhao, C. Liu, B. Balasubramaniam, J. Li, J. Song, X. Liang, M. Zheng, B. Li, Precision 3D profilometry of consumer-grade computer enclosures using high dynamic range fringe projection, Applied Optics 64 (30) (2025) 8986–8994.doi:10.1364/AO.575966. URLhttps://opg.optica.org/ao/abstract.cfm?uri=ao-64-30-8986
-
[19]
E. Yildiz, T. Brinker, E. Renaudo, J. Hollenstein, S. Haller-Seeber, J. Piater, F. Wörgötter, A Visual Intelligence Scheme for Hard Drive DisassemblyinAutomatedRecyclingRoutines:,in:ProceedingsoftheInternationalConferenceonRobotics,ComputerVisionandIntelligent Systems, SCITEPRESS - Science and Technology Publications, Budapest, Hungary, 2020, pp. 17–27.do...
-
[20]
E. Yildiz, E. Renaudo, J. Hollenstein, J. Piater, F. Wörgötter, An Extended Visual Intelligence Scheme for Disassembly in Automated RecyclingRoutines,in:P.Galambos,E.Kayacan,K.Madani(Eds.),Robotics,ComputerVisionandIntelligentSystems,SpringerInternational Publishing, Cham, 2022, pp. 25–50.doi:10.1007/978-3-031-19650-8_2
-
[21]
E. Yildiz, F. Wörgötter, DCNN-Based Screw Detection for Automated Disassembly Processes, in: 2019 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), 2019, pp. 187–192.doi:10.1109/SITIS.2019.00040. URLhttps://ieeexplore.ieee.org/document/9067965
-
[22]
C. Rojas, A. Rodríguez-Sánchez, E. Renaudo, Efficient Segmentation of E-Waste Devices With Deep Learning for Robotic Recycling, in: Emerging Topics in Pattern Recognition and Artificial Intelligence, Vol. Volume 9 of Series on Language Processing, Pattern Recognition, and Intelligent Systems, WORLD SCIENTIFIC, 2023, pp. 123–144.doi:10.1142/9789811289125_0...
-
[23]
C.Rojas,A.Rodríguez-Sánchez,E.Renaudo,DeepLearningforFastSegmentationofE-wasteDevices’InnerPartsinaRecyclingScenario, in: M. El Yacoubi, E. Granger, P. C. Yuen, U. Pal, N. Vincent (Eds.), Pattern Recognition and Artificial Intelligence, Springer International Publishing, Cham, 2022, pp. 161–172.doi:10.1007/978-3-031-09037-0_14
-
[24]
B. Li, High-speed 3D optical sensing for manufacturing research and industrial sensing applications, Transactions on Energy Systems and Engineering Applications 3 (2) (2022) 1–12.doi:10.32397/tesea.vol3.n2.490. URLhttps://revistas.utb.edu.co/tesea/article/view/490
-
[25]
B. Balasubramaniam, V. Suresh, Y. Cheng, J. Li, B. Li, Application-driven multi-modal depth completion in fringe projection profilometry, Optics and Lasers in Engineering 200 (2026) 109587.doi:10.1016/j.optlaseng.2025.109587. URLhttps://www.sciencedirect.com/science/article/pii/S0143816625007717
-
[26]
URLhttps://imagine-h2020.eu/hdd-taxonomy.php
IMAGINE. URLhttps://imagine-h2020.eu/hdd-taxonomy.php
-
[27]
YOLOv11: An Overview of the Key Architectural Enhancements
R. Khanam, M. Hussain, YOLOv11: An Overview of the Key Architectural Enhancements, arXiv:2410.17725 [cs] version: 1 (Oct. 2024). doi:10.48550/arXiv.2410.17725. URLhttp://arxiv.org/abs/2410.17725
work page internal anchor Pith review doi:10.48550/arxiv.2410.17725 2024
-
[28]
Q. Wang, X. Wei, K. Li, B. Cao, W. Zhang, Non-Contact Measurement of Sunflower Flowerhead Morphology Using Mobile- Boosted Lightweight Asymmetric (MBLA)-YOLO and Point Cloud Technology, Agriculture 15 (21) (2025) 2180.doi:10.3390/ agriculture15212180. URLhttps://www.mdpi.com/2077-0472/15/21/2180
2025
-
[29]
URLhttps://www.mdpi.com/2077-0472/15/15/1702
L.H.Naqvi,B.Balasubramaniam,J.Li,L.Liu,B.Li,Four-DimensionalHyperspectralImagingforFruitandVegetableGrading,Agriculture 15 (15) (2025) 1702.doi:10.3390/agriculture15151702. URLhttps://www.mdpi.com/2077-0472/15/15/1702
-
[30]
Zhang, High-Speed 3D Imaging with Digital Fringe Projection Techniques, CRC Press, 2018, google-Books-ID: p22mCwAAQBAJ
S. Zhang, High-Speed 3D Imaging with Digital Fringe Projection Techniques, CRC Press, 2018, google-Books-ID: p22mCwAAQBAJ
2018
-
[31]
B. Li, N. Karpinsky, S. Zhang, Novel calibration method for structured-light system with an out-of-focus projector, Applied Optics 53 (16) (2014) 3415–3426, publisher: Optica Publishing Group.doi:10.1364/AO.53.003415. URLhttps://opg.optica.org/ao/abstract.cfm?uri=ao-53-16-3415 Balasubramaniam et al.:Preprint submitted to ElsevierPage 19 of 20 Fringe Proje...
-
[32]
URLhttps://www.mdpi.com/2079-9292/12/4/859
B.Balasubramaniam,J.Li,L.Liu,B.Li,3DImagingwithFringeProjectionforFoodandAgriculturalApplications—ATutorial,Electronics 12 (4) (2023) 859, number: 4.doi:10.3390/electronics12040859. URLhttps://www.mdpi.com/2079-9292/12/4/859
-
[33]
B. Balasubramaniam, B. Li, Single Shot 3D Shape Measurement of Non-Volatile Data Storage Devices, Vol. Volume 2: Manufacturing EquipmentandAutomation;ManufacturingProcesses;ManufacturingSystems;Nano/Micro/MesoManufacturing;QualityandReliabilityof InternationalManufacturingScienceandEngineeringConference,2023,_eprint:https://asmedigitalcollection.asme.org/...
-
[34]
Dwyer, J
B. Dwyer, J. Nelson, T. Hansen, et al., Roboflow (Version 1.0) [Software], computer vision (2026). URLhttps://roboflow.com
2026
-
[35]
Y. Zheng, S. Wang, Q. Li, B. Li, Fringe projection profilometry by conducting deep learning from its digital twin, Optics Express 28 (24) (2020) 36568–36583.doi:10.1364/OE.410428. URLhttps://opg.optica.org/oe/abstract.cfm?uri=oe-28-24-36568
-
[36]
URLhttps://sketchfab.com
Sketchfab - The best 3D viewer on the web. URLhttps://sketchfab.com
-
[37]
URLhttps://grabcad.com/
GrabCAD Making Additive Manufacturing at Scale Possible. URLhttps://grabcad.com/
-
[38]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y.-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V. Alwala, H. Khedr, A. Huang, et al., Sam 3: Segment anything with concepts, arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
F. Lin, J. Yuan, S. Wu, F. Wang, Z. Wang, UniNeXt: Exploring A Unified Architecture for Vision Recognition, in: Proceedings of the 31st ACMInternationalConferenceonMultimedia,MM’23,AssociationforComputingMachinery,NewYork,NY,USA,2023,pp.3200–3208. doi:10.1145/3581783.3612260. URLhttps://dl.acm.org/doi/10.1145/3581783.3612260
-
[40]
G. P. B, R. Marion Lincy G, A. Rishekeeshan, Deekshitha, Accelerating Native Inference Model Performance in Edge Devices using TensorRT, in: 2024 IEEE Recent Advances in Intelligent Computational Systems (RAICS), 2024, pp. 1–7, iSSN: 2769-5565.doi: 10.1109/RAICS61201.2024.10690032. URLhttps://ieeexplore.ieee.org/abstract/document/10690032
-
[41]
URLhttps://onnx.ai/onnx/intro/
Introduction to ONNX - ONNX 1.21.0 documentation. URLhttps://onnx.ai/onnx/intro/
-
[42]
URLhttps://developer.nvidia.com/tensorrt
NVIDIA TensorRT. URLhttps://developer.nvidia.com/tensorrt
-
[43]
2011–2018.doi:10.1109/HPCC-DSS- SmartCity-DependSys57074.2022.00299
Y.Zhou,K.Yang,ExploringTensorRTtoImproveReal-TimeInferenceforDeepLearning,in:2022IEEE24thIntConfonHighPerformance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), 2022, pp. 2011–2018.doi:10.1109/HP...
-
[44]
Sumaiya, R. Jafarpourmarzouni, S. Lu, Z. Dong, Enhancing Real-time Inference Performance for Time-Critical Software-Defined Vehicles, in: 2024 IEEE International Conference on Mobility, Operations, Services and Technologies (MOST), 2024, pp. 101–113.doi:10.1109/ MOST60774.2024.00019. URLhttps://ieeexplore.ieee.org/abstract/document/10607059 Balasubramania...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.