Recognition: unknown
RemoteShield: Enable Robust Multimodal Large Language Models for Earth Observation
Pith reviewed 2026-05-10 06:43 UTC · model grok-4.3
The pith
RemoteShield trains Earth-observation multimodal models to keep consistent answers when images suffer cloud or fog and instructions turn vague or incomplete.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By forming semantic equivalence clusters from each clean sample and its image-text perturbed variants, then optimizing via preference learning that compares responses across clean and corrupted conditions within the same cluster, RemoteShield maintains consistent interpretation and reasoning under visual degradations such as cloud and fog cover together with textual variations such as colloquialisms or omitted instructions.
What carries the argument
Semantic equivalence clusters of clean and perturbed image-text pairs, optimized by preference learning that ranks stable responses higher than perturbation-induced failures.
If this is right
- RemoteShield outperforms representative baselines in robustness under cloud, fog, and other visual degradations.
- It achieves higher cross-condition consistency when instructions vary from precise to vague or colloquial.
- Performance gains appear across three distinct Earth observation tasks.
- The model learns to prioritize underlying task semantics over surface noise in both visual and textual inputs.
Where Pith is reading between the lines
- The cluster-and-preference approach could transfer to other multimodal domains that face similar real-world input noise, such as medical imaging or video surveillance.
- A direct test on perturbation types outside the hand-constructed set would show whether the learned stability generalizes or remains tied to the specific degradations used in training.
- Combining this alignment step with larger-scale foundation models might further reduce the gap between lab performance and field reliability in satellite data analysis.
Load-bearing premise
The hand-constructed visual and textual perturbations accurately capture the distribution of real-world degradations and preference learning on these clusters produces genuine generalization rather than overfitting to the chosen types.
What would settle it
Run RemoteShield on a fresh collection of real satellite images containing actual atmospheric conditions and naturally occurring vague or colloquial instructions that were never seen during training, then measure whether the robustness gap over baselines remains.
Figures



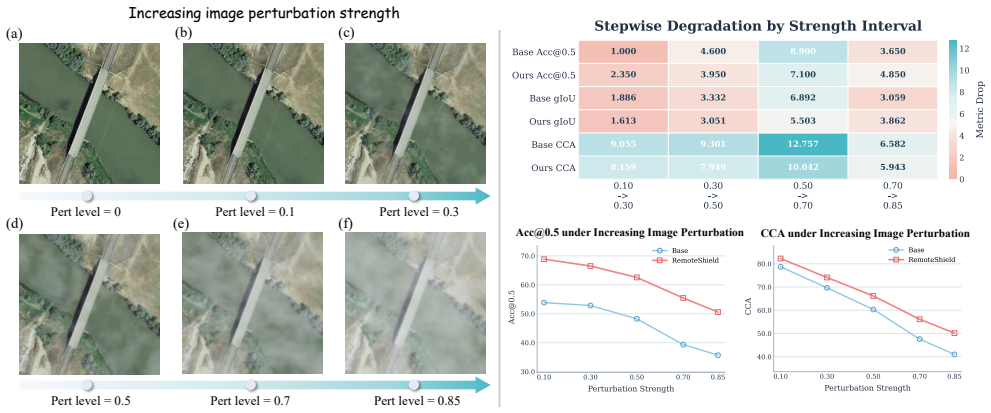

read the original abstract
A robust Multimodal Large Language Model (MLLM) for Earth Observation should maintain consistent interpretation and reasoning under realistic input variations. However, current Remote Sensing MLLMs fail to meet this requirement. Trained on carefully curated clean datasets, they learn brittle mappings that do not generalize to noisy conditions in operational Earth Observation. Consequently, their performance degrades when confronted with imperfect inputs in deployment. To quantify this vulnerability, we construct a realistic set of multimodal perturbations, including visual degradations such as cloud and fog cover, together with diverse human-centric textual variations ranging from colloquialisms to vague or omitted instructions. Empirical evaluations show that these perturbations significantly impair the visual-semantic reasoning capabilities of leading RS foundation models. To address this limitation, we introduce RemoteShield, a robust Remote Sensing MLLM trained to maintain consistent outputs across realistic input variations. During training, each clean sample is paired with its image-text perturbed variants to form a semantic equivalence cluster. Rather than directly fitting noisy samples, RemoteShield is optimized through preference learning over clean and perturbed conditions within the same cluster. By comparing model responses to clean and corrupted inputs, the model is encouraged to favor stable responses over perturbation-induced failures. This cross-condition alignment helps the model focus on underlying task semantics despite visual degradations and textual noise. Experiments on three Earth Observation tasks show that RemoteShield consistently delivers stronger robustness and cross-condition consistency than representative baselines under realistic multimodal perturbations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing remote sensing MLLMs are brittle to realistic multimodal perturbations (visual degradations such as cloud/fog and textual variations including colloquial, vague, or omitted instructions). It introduces RemoteShield, which constructs semantic equivalence clusters by pairing each clean sample with its perturbed variants and optimizes the model via preference learning to favor stable responses across clean and corrupted conditions within each cluster, thereby improving robustness and cross-condition consistency on three Earth Observation tasks.
Significance. If the empirical claims hold, the work would address a practically important gap in deploying MLLMs for operational Earth Observation, where inputs are frequently degraded. The preference-learning formulation on perturbation clusters offers a principled alternative to direct noisy-data fitting and could generalize to other multimodal robustness settings.
major comments (3)
- [Abstract] Abstract: the central claim that RemoteShield 'consistently delivers stronger robustness and cross-condition consistency than representative baselines' is stated without any quantitative metrics, tables, or specific results; the manuscript must supply concrete performance numbers, baseline comparisons, and statistical significance to support this assertion.
- [Method] Method (cluster construction and preference optimization): the description provides no details on how the visual (cloud/fog) and textual perturbations are generated, their sampling procedure, diversity, or whether evaluation uses held-out perturbation types; without this, it is impossible to determine whether the learned preference ordering reflects genuine semantic invariance or merely memorization of the specific training degradations.
- [Experiments] Experiments: no information is given on the three Earth Observation tasks, the chosen baselines, the exact perturbation protocol applied at test time, or any ablation studies isolating the contribution of preference learning versus cluster construction; these omissions make the robustness claims unverifiable.
minor comments (2)
- [Abstract] Abstract: the phrase 'human-centric textual variations' is imprecise; explicitly list the categories (colloquialisms, vagueness, omissions) and their generation method.
- [Method] Notation: the term 'semantic equivalence cluster' is introduced without a formal definition or example; provide one to clarify how clean and perturbed samples are grouped.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below and have revised the manuscript to incorporate the requested details and quantitative support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that RemoteShield 'consistently delivers stronger robustness and cross-condition consistency than representative baselines' is stated without any quantitative metrics, tables, or specific results; the manuscript must supply concrete performance numbers, baseline comparisons, and statistical significance to support this assertion.
Authors: We agree that the abstract should provide concrete support for the central claim. In the revised manuscript, we have updated the abstract to include key quantitative results from the experiments, such as average robustness gains (e.g., +X% on task A, +Y% on task B) and consistency improvements relative to baselines, along with a brief note on statistical significance. These additions are drawn directly from the results section while respecting abstract length constraints. revision: yes
-
Referee: [Method] Method (cluster construction and preference optimization): the description provides no details on how the visual (cloud/fog) and textual perturbations are generated, their sampling procedure, diversity, or whether evaluation uses held-out perturbation types; without this, it is impossible to determine whether the learned preference ordering reflects genuine semantic invariance or merely memorization of the specific training degradations.
Authors: We thank the referee for highlighting this gap in clarity. The revised Method section now provides explicit details: visual perturbations (cloud/fog) are generated via established remote-sensing simulation pipelines that overlay real cloud/fog masks sampled from operational datasets with parameter ranges reflecting realistic atmospheric conditions; textual perturbations are produced through a combination of rule-based paraphrasing, colloquial rewording, vagueness injection, and instruction omission, with diversity ensured by stratified sampling across categories. We have added a statement confirming that test-time perturbations include held-out types and intensities not seen during training, supporting that the preference optimization targets semantic invariance rather than memorization of specific degradations. revision: yes
-
Referee: [Experiments] Experiments: no information is given on the three Earth Observation tasks, the chosen baselines, the exact perturbation protocol applied at test time, or any ablation studies isolating the contribution of preference learning versus cluster construction; these omissions make the robustness claims unverifiable.
Authors: We acknowledge that the original submission omitted explicit specification of these elements. The revised Experiments section now names the three tasks (land-cover classification, object detection, and change detection on remote-sensing imagery), lists the representative baselines (including domain-specific MLLMs such as GeoChat and general-purpose models adapted to EO), and details the test-time perturbation protocol (identical generation process to training but with disjoint samples and held-out variants). We have also added ablation studies that isolate the contribution of preference learning (versus direct supervised fine-tuning on perturbed data) and of cluster construction (versus random pairing), with results showing their individual impacts on robustness and consistency metrics. revision: yes
Circularity Check
No significant circularity in the method or claims
full rationale
The paper describes an empirical procedure: hand-constructed multimodal perturbations are used to form semantic clusters, followed by preference optimization to favor consistent responses across clean and perturbed inputs within each cluster. The robustness claim is presented as the outcome of this training process evaluated on three Earth Observation tasks, with no mathematical derivation, equations, or self-referential definitions that reduce the result to its inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior work are invoked in the provided description. The approach is self-contained as a standard preference-learning pipeline grounded in externally defined perturbations, allowing independent falsification via held-out evaluations rather than tautological equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbed image-text variants share identical underlying task semantics with their clean counterparts
Reference graph
Works this paper leans on
-
[1]
Vision-language models do not understand nega- tion
Kumail Alhamoud, Shaden Alshammari, Yonglong Tian, Guohao Li, Philip HS Torr, Yoon Kim, and Marzyeh Ghas- semi. Vision-language models do not understand nega- tion. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29612–29622, 2025. 3
2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Earth observation and sustainable develop- ment: A systematic literature review and content analysis about the new space economy
Daniele Binci. Earth observation and sustainable develop- ment: A systematic literature review and content analysis about the new space economy. Environmental Innovation and Societal Transitions, 59:101088, 2026. 1
2026
-
[4]
Benchmarking robustness of adaptation methods on pre-trained vision-language models
Shuo Chen, Jindong Gu, Zhen Han, Yunpu Ma, Philip Torr, and V olker Tresp. Benchmarking robustness of adaptation methods on pre-trained vision-language models. Advances in Neural Information Processing Systems, 36: 51758–51777, 2023. 3
2023
-
[5]
Mm-r3: On (in-) consistency of vision-language mod- els (vlms)
Shih-Han Chou, Shivam Chandhok, Jim Little, and Leonid Sigal. Mm-r3: On (in-) consistency of vision-language mod- els (vlms). In Findings of the Association for Computational Linguistics: ACL 2025, pages 4762–4788, 2025. 1
2025
-
[6]
Test-time consistency in vision language mod- els
Shih-Han Chou, Shivam Chandhok, James J Little, and Leonid Sigal. Test-time consistency in vision language mod- els. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7789–7798, 2026. 1
2026
-
[7]
Earth observations for climate adaptation: track- ing progress towards the global goal on adaptation through satellite-derived indicators
Sarah Connors, Rochelle Schneider, Johanna Nalau, Michelle Hawkins, Sofia Ferdini, Ying Wang, Michael Rast, Kristin Aunan, Jean-Philippe Aurambout, Mark Dowell, et al. Earth observations for climate adaptation: track- ing progress towards the global goal on adaptation through satellite-derived indicators. npj Climate and Atmospheric Science, 8(1):359, 2025. 1
2025
-
[8]
Speckle noise reduction in sar images using rank residual constraint regularization
Mehmet Demır. Speckle noise reduction in sar images using rank residual constraint regularization. IEEE Access, 2025. 1
2025
-
[9]
Sug- arcrepe++ dataset: Vision-language model sensitivity to semantic and lexical alterations
Sri H Dumpala, Aman Jaiswal, Chandramouli Sastry, Evan- gelos Milios, Sageev Oore, and Hassan Sajjad. Sug- arcrepe++ dataset: Vision-language model sensitivity to semantic and lexical alterations. Advances in Neural Information Processing Systems, 37:17972–18018, 2024. 1
2024
-
[10]
Geovlm-r1: Reinforcement fine-tuning for improved remote sensing reasoning
Mustansar Fiaz, Hiyam Debary, Paolo Fraccaro, Danda Paudel, Luc Van Gool, Fahad Khan, and Salman Khan. Geovlm-r1: Reinforcement fine-tuning for improved remote sensing reasoning. arXiv preprint arXiv:2509.25026, 2025. 2
-
[11]
On the robustness of object detection models on aerial images
Haodong He, Jian Ding, Bowen Xu, and Gui-Song Xia. On the robustness of object detection models on aerial images. IEEE Transactions on Geoscience and Remote Sensing,
-
[12]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022. 7
2022
-
[13]
Rsgpt: A remote sensing vision language model and benchmark
Yuan Hu, Jianlong Yuan, Congcong Wen, Xiaonan Lu, Yu Liu, and Xiang Li. Rsgpt: A remote sensing vision language model and benchmark. ISPRS Journal of Photogrammetry and Remote Sensing, 224:272–286, 2025. 2
2025
-
[14]
Ziyue Huang, Hongxi Yan, Qiqi Zhan, Shuai Yang, Ming- ming Zhang, Chenkai Zhang, YiMing Lei, Zeming Liu, Qingjie Liu, and Yunhong Wang. A survey on remote sens- ing foundation models: From vision to multimodality. arXiv preprint arXiv:2503.22081, 2025. 1
-
[15]
Teochat: A large vision-language assistant for temporal earth observation data,
Jeremy Andrew Irvin, Emily Ruoyu Liu, Joyce Chuyi Chen, Ines Dormoy, Jinyoung Kim, Samar Khanna, Zhuo Zheng, and Stefano Ermon. Teochat: A large vision-language as- sistant for temporal earth observation data. arXiv preprint arXiv:2410.06234, 2024. 2
-
[16]
Survey of adversarial robustness in multimodal large language models
Chengze Jiang, Zhuangzhuang Wang, Minjing Dong, and Jie Gui. Survey of adversarial robustness in multimodal large language models. arXiv preprint arXiv:2503.13962, 2025. 3
-
[17]
Eaglevision: Object-level attribute multimodal llm for remote sensing
Hongxiang Jiang, Jihao Yin, Qixiong Wang, Jiaqi Feng, and Guo Chen. Eaglevision: Object-level attribute multimodal llm for remote sensing. arXiv preprint arXiv:2503.23330,
-
[18]
A review of appli- cations of satellite earth observation data for global societal benefit and stewardship of planet earth
Pratistha Kansakar and Faisal Hossain. A review of appli- cations of satellite earth observation data for global societal benefit and stewardship of planet earth. Space Policy, 36: 46–54, 2016. 1
2016
-
[19]
Self-attention-enhanced dual-branch network for cloud detection in panchromatic satellite imagery
Kinga Karwowska, Jolanta Siewert, and Aleksandra Sekrecka. Self-attention-enhanced dual-branch network for cloud detection in panchromatic satellite imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2026. 1 10
2026
-
[20]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. In CVPR, pages 27831–27840, 2024. 4, 6
2024
-
[21]
Ke Li, Fuyu Dong, Di Wang, Shaofeng Li, Quan Wang, Xinbo Gao, and Tat-Seng Chua. Show me what and where has changed? question answering and grounding for remote sensing change detection. arXiv preprint arXiv:2410.23828,
-
[22]
Language-guided progressive attention for visual grounding in remote sensing images
Ke Li, Di Wang, Haojie Xu, Haodi Zhong, and Cong Wang. Language-guided progressive attention for visual grounding in remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 62:1–13, 2024. 3
2024
-
[23]
Segearth-r1: Geospatial pixel reasoning via large language model
Kaiyu Li, Zepeng Xin, Li Pang, Chao Pang, Yupeng Deng, Jing Yao, Guisong Xia, Deyu Meng, Zhi Wang, and Xiangy- ong Cao. Segearth-r1: Geospatial pixel reasoning via large language model. arXiv preprint arXiv:2504.09644, 2025. 3
-
[24]
Rsvg-zeroov: Exploring a training-free framework for zero- shot open-vocabulary visual grounding in remote sensing im- ages
Ke Li, Di Wang, Ting Wang, Fuyu Dong, Yiming Zhang, Luyao Zhang, Xiangyu Wang, Shaofeng Li, and Quan Wang. Rsvg-zeroov: Exploring a training-free framework for zero- shot open-vocabulary visual grounding in remote sensing im- ages. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 6288–6296, 2026. 3
2026
-
[25]
Provg: Progressive visual ground- ing via language decoupling for remote sensing imagery
Ke Li, Ting Wang, Di Wang, Yongshan Zhu, Yiming Zhang, Tao Lei, and Quan Wang. Provg: Progressive visual ground- ing via language decoupling for remote sensing imagery. arXiv preprint arXiv:2604.01893, 2026. 3
-
[26]
Wenshuai Li, Xiantai Xiang, Zixiao Wen, Guangyao Zhou, Ben Niu, Feng Wang, Lijia Huang, Qiantong Wang, and Yuxin Hu. Georeason: Aligning thinking and answer- ing in remote sensing vision-language models via logi- cal consistency reinforcement learning. arXiv preprint arXiv:2601.04118, 2026. 2
-
[27]
Vrsbench: A versatile vision-language benchmark dataset for remote sens- ing image understanding
Xiang Li, Jian Ding, and Mohamed Elhoseiny. Vrsbench: A versatile vision-language benchmark dataset for remote sens- ing image understanding. Advances in Neural Information Processing Systems, 37:3229–3242, 2024. 2
2024
-
[28]
Xiang Li, Yong Tao, Siyuan Zhang, Siwei Liu, Zhitong Xiong, Chunbo Luo, Lu Liu, Mykola Pechenizkiy, Xiao Xi- ang Zhu, and Tianjin Huang. Reobench: Benchmarking robustness of earth observation foundation models. arXiv preprint arXiv:2505.16793, 2025. 1
-
[29]
Prompt-robust vision- language models via meta-finetuning
Haohui Liang, Runlin Huang, Yingjun Du, Yujia Hu, Weifeng Su, and Cees GM Snoek. Prompt-robust vision- language models via meta-finetuning. In The Fourteenth International Conference on Learning Representations,
-
[30]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 6
2024
-
[31]
Jiaqi Liu, Lang Sun, Ronghao Fu, and Bo Yang. To- wards faithful reasoning in remote sensing: A perceptually- grounded geospatial chain-of-thought for vision-language models. arXiv preprint arXiv:2509.22221, 2025. 3
-
[32]
Xu Liu and Zhouhui Lian. Rsunivlm: A unified vision language model for remote sensing via granularity-oriented mixture of experts. arXiv preprint arXiv:2412.05679, 2024. 2
-
[33]
Rsvqa: Visual question answering for remote sensing data
Sylvain Lobry, Diego Marcos, Jesse Murray, and Devis Tuia. Rsvqa: Visual question answering for remote sensing data. IEEE Transactions on Geoscience and Remote Sensing, 58 (12):8555–8566, 2020. 4
2020
-
[34]
Single remote sensing image dehazing
Jiao Long, Zhenwei Shi, Wei Tang, and Changshui Zhang. Single remote sensing image dehazing. IEEE Geoscience and Remote Sensing Letters, 11(1):59–63, 2013. 1
2013
-
[35]
Junwei Luo, Zhen Pang, Yongjun Zhang, Tingzhu Wang, Linlin Wang, Bo Dang, Jiangwei Lao, Jian Wang, Jingdong Chen, Yihua Tan, et al. Skysensegpt: A fine-grained in- struction tuning dataset and model for remote sensing vision- language understanding. arXiv preprint arXiv:2406.10100,
-
[36]
Geoevolve: Automating geospatial model discov- ery via multi-agent large language models
Peng Luo, Xiayin Lou, Yu Zheng, Zhuo Zheng, and Stefano Ermon. Geoevolve: Automating geospatial model discov- ery via multi-agent large language models. arXiv preprint arXiv:2509.21593, 2025. 2
-
[37]
Prompting directsam for semantic contour extraction in remote sensing images
Shiyu Miao, Delong Chen, Fan Liu, Chuanyi Zhang, Yan- hui Gu, Shengjie Guo, and Jun Zhou. Prompting directsam for semantic contour extraction in remote sensing images. In 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2025. 2
2025
-
[38]
Geopix: A multimodal large language model for pixel-level image understanding in remote sensing
Ruizhe Ou, Yuan Hu, Fan Zhang, Jiaxin Chen, and Yu Liu. Geopix: A multimodal large language model for pixel-level image understanding in remote sensing. IEEE Geoscience and Remote Sensing Magazine, 2025. 6
2025
-
[39]
Training lan- guage models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training lan- guage models to follow instructions with human feedback. Advances in neural information processing systems, 35: 27730–27744, 2022. 2
2022
-
[40]
Benchmarking multimodal large language models against image corruptions
Xinkuan Qiu, Meina Kan, Yongbin Zhou, and Shiguang Shan. Benchmarking multimodal large language models against image corruptions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9014– 9023, 2025. 3
2025
-
[41]
Towards a science of ai agent reliability, 2026
Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, and Arvind Narayanan. Towards a sci- ence of ai agent reliability.arXiv preprint arXiv:2602.16666,
-
[42]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023. 2, 5, 7
2023
-
[43]
Deepspeed: System optimizations enable train- ing deep learning models with over 100 billion parame- ters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable train- ing deep learning models with over 100 billion parame- ters. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506, 2020. 7
2020
-
[44]
Multitask Prompted Training Enables Zero-Shot Task Generalization
Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Ar- naud Stiegler, Teven Le Scao, Arun Raja, et al. Multi- 11 task prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207, 2021. 2
work page internal anchor Pith review arXiv 2021
-
[45]
Vlm-robustbench: A comprehensive benchmark for robustness of vision-language models
Rohit Saxena, Alessandro Suglia, and Pasquale Min- ervini. Vlm-robustbench: A comprehensive benchmark for robustness of vision-language models. arXiv preprint arXiv:2603.06148, 2026. 3
-
[46]
ThinkGeo: Evaluating tool-augmented agents for remote sensing tasks,
Akashah Shabbir, Muhammad Akhtar Munir, Akshay Dud- hane, Muhammad Umer Sheikh, Muhammad Haris Khan, Paolo Fraccaro, Juan Bernabe Moreno, Fahad Shahbaz Khan, and Salman Khan. Thinkgeo: Evaluating tool- augmented agents for remote sensing tasks. arXiv preprint arXiv:2505.23752, 2025. 2
-
[47]
Analyzing the sensitivity of vision language models in visual question answering
Monika Shah, Sudarshan Balaji, Somdeb Sarkhel, Sanorita Dey, and Deepak Venugopal. Analyzing the sensitivity of vision language models in visual question answering. In Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM2), pages 431–438, 2025. 1
2025
-
[48]
An effective thin cloud removal proce- dure for visible remote sensing images
Huanfeng Shen, Huifang Li, Yan Qian, Liangpei Zhang, and Qiangqiang Yuan. An effective thin cloud removal proce- dure for visible remote sensing images. ISPRS Journal of Photogrammetry and Remote Sensing, 96:224–235, 2014. 1
2014
-
[49]
Earthdial: Turning multi-sensory earth observations to interactive dialogues
Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fa- had Shahbaz Khan, et al. Earthdial: Turning multi-sensory earth observations to interactive dialogues. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14303–14313, 2025. 6
2025
-
[50]
Analysing the Robustness of Vision-Language-Models to Common Cor- ruptions, 2025
Muhammad Usama, Syeda Aishah Asim, Syed Bilal Ali, Syed Talal Wasim, and Umair Bin Mansoor. Analysing the robustness of vision-language-models to common cor- ruptions. arXiv preprint arXiv:2504.13690, 2025. 3
-
[51]
Geozero: Incentivizing rea- soning from scratch on geospatial scenes
Di Wang, Shunyu Liu, Wentao Jiang, Fengxiang Wang, Yi Liu, Xiaolei Qin, Zhiming Luo, Chaoyang Zhou, Hao- nan Guo, Jing Zhang, et al. Geozero: Incentivizing rea- soning from scratch on geospatial scenes. arXiv preprint arXiv:2511.22645, 2025. 2
-
[52]
Earthvqa: Towards queryable earth via re- lational reasoning-based remote sensing visual question an- swering
Junjue Wang, Zhuo Zheng, Zihang Chen, Ailong Ma, and Yanfei Zhong. Earthvqa: Towards queryable earth via re- lational reasoning-based remote sensing visual question an- swering. In AAAI, pages 5481–5489, 2024. 2
2024
-
[53]
Ringmogpt: A unified re- mote sensing foundation model for vision, language, and grounded tasks
Peijin Wang, Huiyang Hu, Boyuan Tong, Ziqi Zhang, Fan- glong Yao, Yingchao Feng, Zining Zhu, Hao Chang, Wen- hui Diao, Qixiang Ye, et al. Ringmogpt: A unified re- mote sensing foundation model for vision, language, and grounded tasks. IEEE Transactions on Geoscience and Remote Sensing, 63:1–20, 2024. 2
2024
-
[54]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 6
work page internal anchor Pith review arXiv 2025
-
[55]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023. 2
2023
-
[56]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learn- ers. arXiv preprint arXiv:2109.01652, 2021. 2
work page internal anchor Pith review arXiv 2021
-
[57]
Vision-language reasoning for geolocaliza- tion: A reinforcement learning approach
Biao Wu, Meng Fang, Ling Chen, Ke Xu, Tao Cheng, and Jun Wang. Vision-language reasoning for geolocaliza- tion: A reinforcement learning approach. arXiv preprint arXiv:2601.00388, 2026. 2
-
[58]
Aid: A benchmark data set for performance evaluation of aerial scene classification
Gui-Song Xia, Jingwen Hu, Fan Hu, Baoguang Shi, Xiang Bai, Yanfei Zhong, Liangpei Zhang, and Xiaoqiang Lu. Aid: A benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing, 55(7):3965–3981, 2017. 4
2017
-
[59]
Robustflow: Towards robust agentic workflow generation.arXiv preprint arXiv:2509.21834, 2025
Shengxiang Xu, Jiayi Zhang, Shimin Di, Yuyu Luo, Liang Yao, Hanmo Liu, Jia Zhu, Fan Liu, and Min-Ling Zhang. Robustflow: Towards robust agentic workflow generation. arXiv preprint arXiv:2509.21834, 2025. 3
-
[60]
Reo-vlm: Trans- forming vlm to meet regression challenges in earth observa- tion
Xizhe Xue, Guoting Wei, Hao Chen, Haokui Zhang, Feng Lin, Chunhua Shen, and Xiao Xiang Zhu. Reo-vlm: Trans- forming vlm to meet regression challenges in earth observa- tion. arXiv preprint arXiv:2412.16583, 2024. 2
-
[61]
Falcon: A remote sensing vision-language foundation model.arXiv preprint arXiv:2503.11070, 2025
Kelu Yao, Nuo Xu, Rong Yang, Yingying Xu, Zhuoyan Gao, Titinunt Kitrungrotsakul, Yi Ren, Pu Zhang, Jin Wang, Ning Wei, et al. Falcon: A remote sensing vision-language foun- dation model. arXiv preprint arXiv:2503.11070, 2025. 2
-
[62]
Remotesam: Towards segment anything for earth observation
Liang Yao, Fan Liu, Delong Chen, Chuanyi Zhang, Yi- jun Wang, Ziyun Chen, Wei Xu, Shimin Di, and Yuhui Zheng. Remotesam: Towards segment anything for earth observation. In Proceedings of the 33rd ACM International Conference on Multimedia, 2025. 2
2025
-
[63]
Remotereasoner: Towards unifying geospatial reasoning workflow.arXiv preprint arXiv:2507.19280, 2025
Liang Yao, Fan Liu, Hongbo Lu, Chuanyi Zhang, Rui Min, Shengxiang Xu, Shimin Di, and Pai Peng. Remotereasoner: Towards unifying geospatial reasoning workflow. arXiv preprint arXiv:2507.19280, 2025. 2, 6
-
[64]
RemoteAgent: Bridging Vague Human Intents and Earth Observation with RL-based Agentic MLLMs
Liang Yao, Shengxiang Xu, Fan Liu, Chuanyi Zhang, Bishun Yao, Rui Min, Yongjun Li, Chaoqian Ouyang, Shimin Di, and Min-Ling Zhang. Remoteagent: Bridging vague human intents and earth observation with rl-based agentic mllms. arXiv preprint arXiv:2604.07765, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Instruction tuning for large language models: A survey
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xi- aofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Guoyin Wang, et al. Instruction tuning for large language models: A survey. ACM Computing Surveys, 58(7):1–36,
-
[66]
Earthmarker: A visual prompting mul- timodal large language model for remote sensing
Wei Zhang, Miaoxin Cai, Tong Zhang, Yin Zhuang, Jun Li, and Xuerui Mao. Earthmarker: A visual prompting mul- timodal large language model for remote sensing. IEEE Transactions on Geoscience and Remote Sensing, 63:1–19,
-
[67]
Earthgpt: A universal multimodal large lan- guage model for multisensor image comprehension in re- mote sensing domain
Wei Zhang, Miaoxin Cai, Tong Zhang, Yin Zhuang, and Xuerui Mao. Earthgpt: A universal multimodal large lan- guage model for multisensor image comprehension in re- mote sensing domain. IEEE Transactions on Geoscience and Remote Sensing, 62:1–20, 2024. 2
2024
-
[68]
Zilun Zhang, Zian Guan, Tiancheng Zhao, Haozhan Shen, Tianyu Li, Yuxiang Cai, Zhonggen Su, Zhaojun Liu, Jianwei Yin, and Xiang Li. Geo-r1: Improving few-shot geospatial 12 referring expression understanding with reinforcement fine- tuning. arXiv preprint arXiv:2509.21976, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
On evalu- ating adversarial robustness of large vision-language mod- els
Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Chongx- uan Li, Ngai-Man Man Cheung, and Min Lin. On evalu- ating adversarial robustness of large vision-language mod- els. Advances in Neural Information Processing Systems, 36:54111–54138, 2023. 3
2023
-
[70]
Swift: a scalable lightweight infrastructure for fine-tuning
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yun- lin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, et al. Swift: a scalable lightweight infrastructure for fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 29733–29735, 2025. 7
2025
-
[71]
Advances on multimodal remote sensing foundation models for earth observation downstream tasks: A survey
Guoqing Zhou, Qian Lihuang, and Paolo Gamba. Advances on multimodal remote sensing foundation models for earth observation downstream tasks: A survey. Remote Sensing, 17(21):3532, 2025. 1
2025
-
[72]
Towards vision-language geo-foundation model: A survey. arxiv 2024,
Yue Zhou, Zhihang Zhong, and Xue Yang. Towards vision- language geo-foundation model: A survey. arXiv preprint arXiv:2406.09385, 2024
-
[73]
On the founda- tions of earth foundation models
Xiao Xiang Zhu, Zhitong Xiong, Yi Wang, Adam J Stewart, Konrad Heidler, Yuanyuan Wang, Zhenghang Yuan, Thomas Dujardin, Qingsong Xu, and Yilei Shi. On the founda- tions of earth foundation models. Communications Earth & Environment, 2026. 1 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.