Recognition: unknown
DORA Explorer: Improving the Exploration Ability of LLMs Without Training
Pith reviewed 2026-05-10 06:24 UTC · model grok-4.3
The pith
DORA Explorer improves LLM exploration in sequential decision tasks without training by generating action candidates, scoring them on token log-probabilities, and selecting with a tunable parameter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
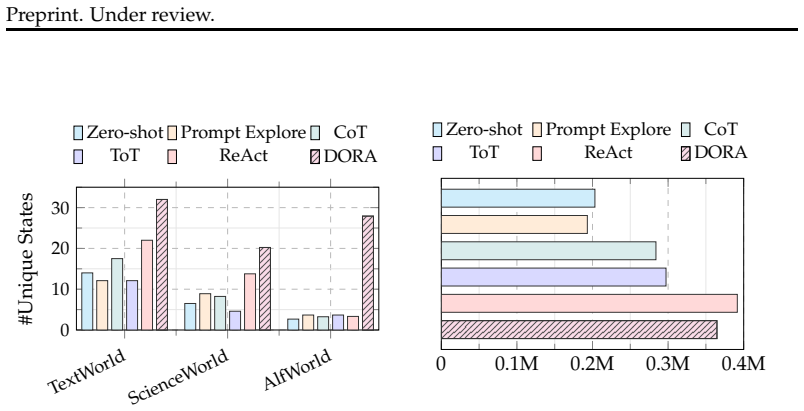
DORA Explorer generates diverse action candidates, scores them using the base LLM's token log-probabilities, and selects the next action with a tunable exploration parameter. In the Multi-Armed Bandit setting this yields results competitive with Upper Confidence Bound methods. Across the Text Adventure Learning Environment Suite it produces consistent gains, such as improving Qwen2.5-7B from 29.2% to 45.5% success in TextWorld.
What carries the argument
DORA ranking procedure that generates candidates, scores them by token log-probabilities, and balances them with a tunable exploration parameter.
If this is right
- LLM agents reach UCB-competitive exploration in multi-armed bandit problems without any training.
- Success rates rise consistently across multiple base models in text adventure environments.
- Token log-probabilities supply enough signal to guide action choice in exploratory settings.
- Standard decoding and prompting techniques remain insufficient for sequence-level diversity.
- The tunable parameter lets users control the exploration-exploitation trade-off at inference time.
Where Pith is reading between the lines
- The same candidate-scoring logic could be tested on other sequential domains such as web navigation or tool-use agents.
- Relying on the base model's probabilities suggests that exploration can be improved without external reward models or reinforcement learning.
- Checking whether the exploration parameter needs per-environment tuning or can be fixed generically would clarify practical deployment.
- If the gains persist on longer-horizon tasks, the method could reduce the cost of deploying capable LLM agents in information-gathering scenarios.
Load-bearing premise
That an LLM's token log-probabilities serve as a reliable proxy for both the quality and the exploratory value of candidate actions.
What would settle it
If DORA-selected actions produce lower cumulative reward than standard sampling or UCB across repeated trials on the same bandit instances or adventure games, the performance advantage would not hold.
Figures


read the original abstract
Despite the rapid progress, LLMs for sequential decision-making (i.e., LLM agents) still struggle to produce diverse outputs. This leads to insufficient exploration, convergence to sub-optimal solutions, and becoming stuck in loops. Such limitations can be problematic in environments that require active exploration to gather information and make decisions. Sampling methods such as temperature scaling introduce token-level randomness but fail to produce enough diversity at the sequence level. We analyze LLM exploration in the classic Multi-Armed Bandit (MAB) setting and the Text Adventure Learning Environment Suite (TALES). We find that current decoding strategies and prompting methods like Chain-of-Thought and Tree-of-Thought are insufficient for robust exploration. To address this, we introduce DORA Explorer (Diversity-Oriented Ranking of Actions), a training-free framework for improving exploration in LLM agents. DORA generates diverse action candidates, scores them using token log-probabilities, and selects actions using a tunable exploration parameter. DORA achieves UCB-competitive performance on MAB and consistent gains across TALES, e.g., improving Qwen2.5-7B's performance from 29.2% to 45.5% in TextWorld. Our project is available at: https://dora-explore.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DORA Explorer, a training-free framework to improve exploration in LLM agents for sequential decision-making tasks. It generates diverse action candidates, scores them using the base LLM's token log-probabilities, and selects the next action via a tunable exploration parameter. Evaluations are presented in the classic Multi-Armed Bandit (MAB) setting, where DORA is claimed to achieve UCB-competitive performance, and in the Text Adventure Learning Environment Suite (TALES), where it reports consistent gains over baselines such as temperature sampling, Chain-of-Thought, and Tree-of-Thought (e.g., raising Qwen2.5-7B success from 29.2% to 45.5% in TextWorld). The authors conclude that existing decoding and prompting strategies are insufficient for robust exploration.
Significance. If the gains prove robust and independent of per-task parameter fitting, DORA would supply a simple, training-free mechanism for increasing sequence-level diversity in LLM agents, addressing a practical bottleneck in environments that reward information-gathering. The explicit project page and code release are positive for reproducibility.
major comments (3)
- [Abstract and §3] Abstract and §3 (method): The central claim of 'consistent gains' and 'UCB-competitive performance' rests on a single tunable exploration parameter whose selection procedure is not described. If this parameter is grid-searched or optimized on the same episodes used for final reporting, the comparison to fixed-hyperparameter baselines (UCB, temperature) becomes circular and the training-free claim is weakened.
- [§4] §4 (experiments): No error bars, number of independent runs, or statistical significance tests are reported for the percentage improvements (e.g., 29.2% → 45.5%). Without these, it is impossible to determine whether the observed deltas exceed run-to-run variance or depend on favorable random seeds.
- [§4.2] §4.2 (TALES results): The manuscript provides no ablation on the exploration parameter across tasks or models, nor does it state whether a single fixed value was used for all reported TALES numbers. This detail is load-bearing for the 'consistent gains across TALES' assertion.
minor comments (2)
- [Abstract] The abstract states 'DORA achieves UCB-competitive performance' but does not specify the exact UCB variant or its exploration constant; a brief comparison table would clarify the baseline.
- [§3] Notation for the scoring function (token log-probabilities) and the selection rule should be formalized with an equation in §3 to avoid ambiguity when readers attempt to re-implement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity on the exploration parameter, add statistical reporting, and include ablations. These changes strengthen the paper without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The central claim of 'consistent gains' and 'UCB-competitive performance' rests on a single tunable exploration parameter whose selection procedure is not described. If this parameter is grid-searched or optimized on the same episodes used for final reporting, the comparison to fixed-hyperparameter baselines (UCB, temperature) becomes circular and the training-free claim is weakened.
Authors: We agree the selection procedure for the exploration parameter requires explicit description to avoid any ambiguity. In the revised manuscript we will add a dedicated paragraph in §3 explaining that a single fixed value (λ = 0.5) was used for all TALES results; this value was selected via a small grid search on a separate validation split of episodes that is disjoint from the test episodes used for final reporting. For the MAB experiments we will similarly document the grid and confirm no test-episode leakage occurred. This preserves the training-free nature of DORA while making the experimental protocol fully reproducible. revision: yes
-
Referee: [§4] §4 (experiments): No error bars, number of independent runs, or statistical significance tests are reported for the percentage improvements (e.g., 29.2% → 45.5%). Without these, it is impossible to determine whether the observed deltas exceed run-to-run variance or depend on favorable random seeds.
Authors: We acknowledge that the absence of error bars and statistical tests limits interpretability. In the revision we will re-run all TALES experiments with five independent random seeds, report means and standard deviations for every method, and include paired t-tests (or Wilcoxon tests where appropriate) comparing DORA against each baseline. The updated tables and text will make clear that the reported gains remain statistically significant under these controls. revision: yes
-
Referee: [§4.2] §4.2 (TALES results): The manuscript provides no ablation on the exploration parameter across tasks or models, nor does it state whether a single fixed value was used for all reported TALES numbers. This detail is load-bearing for the 'consistent gains across TALES' assertion.
Authors: We will add a new subsection (or appendix) containing an ablation of the exploration parameter λ over the range {0.1, 0.3, 0.5, 0.7, 0.9} for both Qwen2.5-7B and Llama-3-8B across the three TALES environments. The ablation will confirm that a single fixed λ = 0.5 yields the strongest average performance and that DORA remains superior to baselines for a broad interval around this value, thereby supporting the claim of consistent gains. revision: yes
Circularity Check
No significant circularity detected in the derivation chain
full rationale
The paper introduces DORA as a training-free method that generates action candidates, scores them via base-LLM token log-probabilities, and selects via a tunable exploration parameter. No equations, self-citations, or load-bearing steps are presented that reduce the reported performance gains (e.g., UCB-competitive MAB results or TALES improvements) to a fitted parameter or input by construction. The tunable parameter is part of the proposed framework rather than a post-hoc fit on evaluation data that would force the gains; empirical results are reported without evidence of the specific reduction required for circularity flags. The derivation chain remains self-contained as an empirical proposal.
Axiom & Free-Parameter Ledger
free parameters (1)
- exploration parameter
invented entities (1)
-
DORA Explorer framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Towards scientific intelligence: A survey of llm-based scientific agents , author=. arXiv preprint arXiv:2503.24047 , year=
-
[2]
Gamebench: Evaluating strategic reasoning abilities of llm agents, 2024
Gamebench: Evaluating strategic reasoning abilities of llm agents , author=. arXiv preprint arXiv:2406.06613 , year=
-
[3]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open-source vision-language-action model , author=. arXiv preprint arXiv:2406.09246 , year=
work page internal anchor Pith review arXiv
-
[4]
2024 12th International Symposium on Digital Forensics and Security (ISDFS) , pages=
Llm-based framework for administrative task automation in healthcare , author=. 2024 12th International Symposium on Digital Forensics and Security (ISDFS) , pages=. 2024 , organization=
2024
-
[5]
A Thorough Examination of Decoding Methods in the Era of LLM s
Shi, Chufan and Yang, Haoran and Cai, Deng and Zhang, Zhisong and Wang, Yifan and Yang, Yujiu and Lam, Wai. A Thorough Examination of Decoding Methods in the Era of LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.489
-
[6]
Foundations and Trends
Recommender systems meet large language model agents: A survey , author=. Foundations and Trends. 2025 , publisher=
2025
-
[7]
Chi and Quoc V Le and Minmin Chen , year=
Allen Nie and Yi Su and Bo Chang and Jonathan Lee and Ed H. Chi and Quoc V Le and Minmin Chen , year=. Evolve: Evaluating and Optimizing
-
[8]
Tales: Text-adventure learning environment suite
Tales: Text adventure learning environment suite , author=. arXiv preprint arXiv:2504.14128 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Can large language models explore in-context? , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Expanding LLM agent boundaries with strategy-guided exploration.arXiv preprint arXiv:2603.02045,
Expanding LLM Agent Boundaries with Strategy-Guided Exploration , author=. arXiv preprint arXiv:2603.02045 , year=
-
[11]
Is temperature the creativity parameter of large language models? , author=. arXiv preprint arXiv:2405.00492 , year=
-
[12]
Control the Temperature: Selective Sampling for Diverse and High-Quality
Sergey Troshin and Wafaa Mohammed and Yan Meng and Christof Monz and Antske Fokkens and Vlad Niculae , booktitle=. Control the Temperature: Selective Sampling for Diverse and High-Quality. 2025 , url=
2025
-
[13]
International conference on machine learning , pages=
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[14]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[15]
The Curious Case of Neural Text Degeneration
The curious case of neural text degeneration , author=. arXiv preprint arXiv:1904.09751 , year=
work page internal anchor Pith review arXiv 1904
-
[16]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
A thorough examination of decoding methods in the era of llms , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[17]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[18]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[19]
Findings of the association for computational linguistics: EMNLP 2024 , pages=
The effect of sampling temperature on problem solving in large language models , author=. Findings of the association for computational linguistics: EMNLP 2024 , pages=
2024
-
[20]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hierarchical neural story generation , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
Turning up the heat: Min-p sampling for creative and coherent llm outputs , author=. arXiv preprint arXiv:2407.01082 , year=
-
[22]
International Conference on Learning Representations , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations , year=
-
[23]
2025 , eprint=
TALES: Text Adventure Learning Environment Suite , author=. 2025 , eprint=
2025
-
[24]
Workshop on Computer Games , pages=
Textworld: A learning environment for text-based games , author=. Workshop on Computer Games , pages=. 2018 , organization=
2018
-
[25]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations , pages=
Textworldexpress: Simulating text games at one million steps per second , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations , pages=
-
[26]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Alfworld: Aligning text and embodied environments for interactive learning , author=. arXiv preprint arXiv:2010.03768 , year=
work page internal anchor Pith review arXiv 2010
-
[27]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Scienceworld: Is your agent smarter than a 5th grader? , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Interactive fiction games: A colossal adventure , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
, author=
Unpacking the exploration--exploitation tradeoff: a synthesis of human and animal literatures. , author=. Decision , volume=. 2015 , publisher=
2015
-
[30]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[31]
Machine Learning , year=
Finite-time Analysis of the Multiarmed Bandit Problem , author=. Machine Learning , year=
-
[32]
COLT , year=
Analysis of Thompson Sampling for the Multi-armed Bandit Problem , author=. COLT , year=
-
[33]
Forty-second International Conference on Machine Learning , year=
Training a Generally Curious Agent , author=. Forty-second International Conference on Machine Learning , year=
-
[34]
Verbalized sampling: How to mitigate mode collapse and unlock llm diversity , author=. arXiv preprint arXiv:2510.01171 , year=
-
[35]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Sentence-wise smooth regularisation for sequence to sequence learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[36]
Factual Confidence of LLM s: on Reliability and Robustness of Current Estimators
Mahaut, Mat. Factual Confidence of LLM s: on Reliability and Robustness of Current Estimators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.250
-
[37]
Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Log probabilities are a reliable estimate of semantic plausibility in base and instruction-tuned language models , author=. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[38]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Factual confidence of LLMs: on reliability and robustness of current estimators , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.