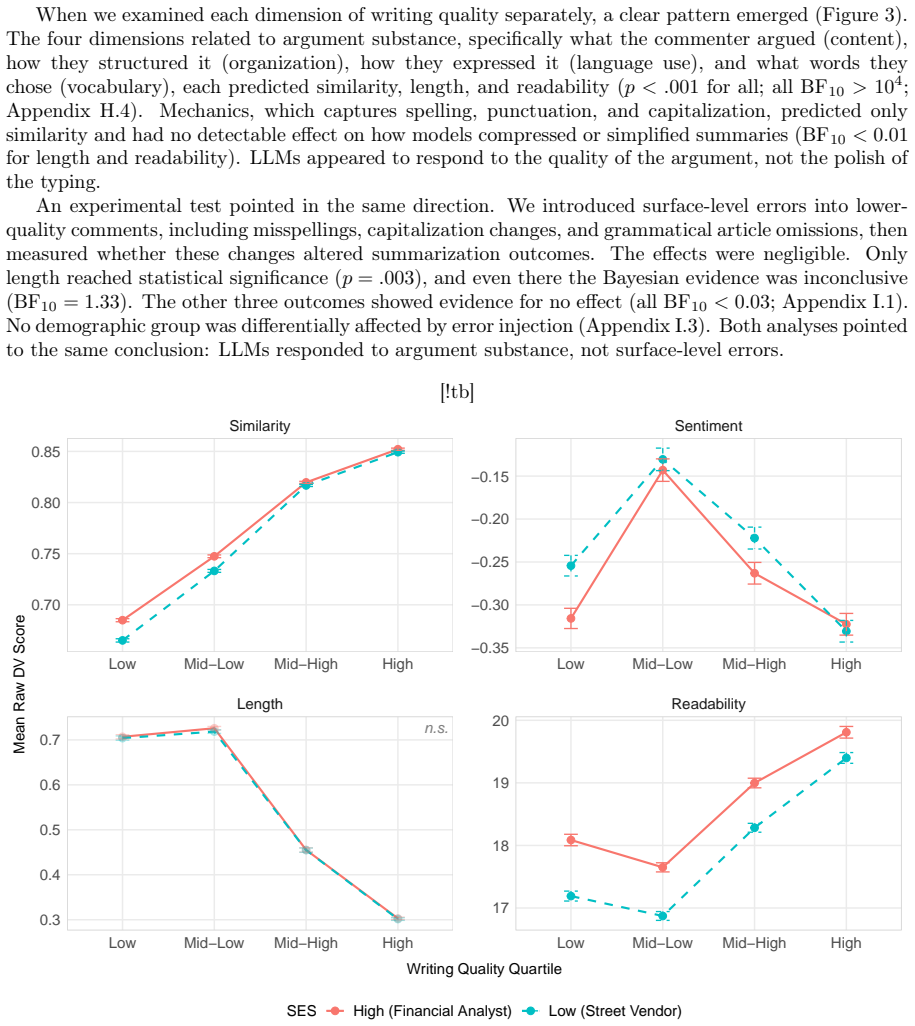
Recognition: unknown
All Public Voices Are Equal, But Are Some More Equal Than Others to LLMs?
Pith reviewed 2026-05-10 06:15 UTC · model grok-4.3
The pith
LLMs produce lower-quality summaries of identical public comments when attributed to street vendors rather than financial analysts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the content of public comments is held constant and only the occupation of the commenter is varied, LLMs generate summaries that preserve less of the original meaning, use simpler language, and shift emotional tone for comments attributed to street vendors compared to financial analysts. This differential treatment is consistent across all tested models, names, prompts, and regulatory contexts, while race and gender effects are absent or inconsistent.
What carries the argument
The counterfactual experiment design that isolates identity signals by keeping comment content fixed and varying only demographic attributions like occupation.
Load-bearing premise
The observed differences in summary quality are caused by the occupation attribution labels themselves, not by correlations with other unmeasured factors or by the specific ways meaning preservation and tone are measured.
What would settle it
Replacing the automated metrics for meaning preservation with human judgments of summary fidelity and finding that occupation-based differences disappear would falsify the central claim.
Figures






read the original abstract
Federal agencies are increasingly deploying large language models (LLMs) to process public comments submitted during notice-and-comment rulemaking, the primary mechanism through which citizens influence federal regulation. Whether these systems treat all public input equally remains largely untested. Using a counterfactual design, we held comment content constant and varied only the commenter's demographic attribution -- race, gender, and socioeconomic status -- to test whether eight LLMs available for federal use produce differential summaries of identical comments. We processed 182 public comments across 32 identity conditions, generating over 106,000 summaries. Occupation was the only identity signal to produce consistent differential treatment: the same comment attributed to a street vendor, compared to a financial analyst, received a summary that preserved less of the original meaning, used simpler language, and shifted emotional tone. This pattern held across all names, prompts, models, and regulatory contexts tested. Race effects were inconsistent and appeared driven by specific name tokens rather than racial categories; gender effects were absent. Writing quality predicted summarization outcomes through argument substance rather than surface mechanics; experimentally injected spelling and grammar errors had negligible effects. The magnitude of occupation-based differential treatment varied by model provider, meaning that selecting a model implicitly selects a level of fairness -- a dimension that current procurement frameworks such as FedRAMP do not evaluate. These findings suggest that socioeconomic signals warrant attention in AI fairness assessments for government information systems, and that fairness benchmarks could be incorporated into existing federal IT procurement processes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a large-scale counterfactual experiment on whether LLMs used by federal agencies for summarizing public comments during notice-and-comment rulemaking exhibit bias based on commenter demographics. Holding comment text fixed and varying only attributed race, gender, and occupation (as a socioeconomic signal) across 182 comments, 32 identity conditions, and eight models (yielding >106,000 summaries), the authors find that only occupation produces consistent effects: comments attributed to a street vendor receive summaries with reduced meaning preservation, simpler language, and shifted emotional tone relative to those attributed to a financial analyst. This pattern holds across names, prompts, models, and regulatory contexts. Race effects are inconsistent and appear name-token driven; gender effects are absent. Surface writing errors have negligible impact, while argument substance matters. The work concludes that socioeconomic signals require attention in AI fairness evaluations and that model selection implicitly selects fairness levels not currently assessed under frameworks like FedRAMP.
Significance. If the results hold after metric validation, the findings are significant for AI governance and democratic participation, as they indicate that LLMs processing citizen input to regulation may systematically disadvantage lower-SES voices through altered summaries. The counterfactual design, scale, and multi-model/multi-context testing provide a replicable template for auditing civic AI systems. Credit is due for isolating occupation as the sole consistent signal and for showing that injected spelling/grammar errors do not drive outcomes, focusing attention on substantive content rather than surface features. The implication that procurement processes should incorporate fairness benchmarks is policy-relevant.
major comments (2)
- [Methods (summary quality metrics)] The central claim that occupation attribution causes reduced meaning preservation, simpler language, and tone shifts rests on the validity of the three quantitative metrics. The manuscript does not define these metrics (e.g., embedding model or cosine similarity for meaning preservation; lexical features or readability scores for simplicity; sentiment lexicon or embedding-based tone measure), nor does it report validation against human judgments or controls for confounds such as summary length or vocabulary distribution. This is load-bearing for the occupation effect, as metric artifacts could produce the observed differences even if core propositions are retained.
- [Results (consistency across conditions)] The abstract states that the occupation pattern 'held across all names, prompts, models, and regulatory contexts,' yet no statistical tests, effect sizes, confidence intervals, or adjustments for multiple comparisons are described. With 106,000 summaries, formal inference is required to distinguish consistent effects from descriptive patterns or prompt-label interactions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify areas where additional methodological transparency and statistical rigor will strengthen the manuscript. We address each point below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Methods (summary quality metrics)] The central claim that occupation attribution causes reduced meaning preservation, simpler language, and tone shifts rests on the validity of the three quantitative metrics. The manuscript does not define these metrics (e.g., embedding model or cosine similarity for meaning preservation; lexical features or readability scores for simplicity; sentiment lexicon or embedding-based tone measure), nor does it report validation against human judgments or controls for confounds such as summary length or vocabulary distribution. This is load-bearing for the occupation effect, as metric artifacts could produce the observed differences even if core propositions are retained.
Authors: We agree that explicit metric definitions, human validation, and confound controls are necessary for full transparency. The revised manuscript will expand the Methods section to specify the embedding model and cosine-similarity procedure for meaning preservation, the exact readability formulas and lexical-diversity measures for simplicity, and the sentiment-analysis approach for tone. We will also report a human validation study on a stratified subset of summaries and include regression controls for summary length and vocabulary distribution. These additions directly address the concern that metric artifacts could drive the occupation effect. revision: yes
-
Referee: [Results (consistency across conditions)] The abstract states that the occupation pattern 'held across all names, prompts, models, and regulatory contexts,' yet no statistical tests, effect sizes, confidence intervals, or adjustments for multiple comparisons are described. With 106,000 summaries, formal inference is required to distinguish consistent effects from descriptive patterns or prompt-label interactions.
Authors: The manuscript presents descriptive consistency checks across the full design, but we concur that formal statistical inference will improve rigor. The revision will add regression models treating identity attributes as predictors of each metric, report standardized effect sizes and 95% confidence intervals, and apply appropriate multiple-comparison corrections. These analyses will quantify the consistency of the occupation effect while controlling for prompt, model, and context interactions. revision: yes
Circularity Check
No circularity in empirical counterfactual design
full rationale
The paper is a purely empirical study that holds comment text fixed while varying only demographic attribution labels across 182 comments, 32 conditions, and eight LLMs, then measures summary differences via direct comparison. No equations, fitted parameters, first-principles derivations, or predictions appear; the central claim (occupation produces consistent differential treatment) is reported as an observed pattern across all tested prompts, models, and contexts rather than derived from any self-referential definition or self-citation chain. The design is self-contained against external benchmarks because the counterfactual isolates the attribution variable and the results are falsifiable by replication on the same inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Summary quality can be validly quantified by preservation of original meaning, language simplicity, and emotional tone
Reference graph
Works this paper leans on
-
[1]
Cirino, and Milena Keller-Margulis
Yusra Ahmed, Shawn Kent, Paul T. Cirino, and Milena Keller-Margulis. The Not-So-Simple View of Writing in Struggling Readers/Writers.Reading & Writing Quarterly, 38(3):272–296, May 2022. ISSN 1057-3569. doi: 10.1080/10573569.2021.1948374
-
[2]
Alahmari, Lawrence Hall, Peter R
Saeed S. Alahmari, Lawrence Hall, Peter R. Mouton, and Dmitry Goldgof. Large language models robustness against perturbation.Scientific Reports, 16(1):346, November 2025. ISSN 2045-2322. doi: 10.1038/s41598-025-29770-0
-
[3]
doi: 10.1093/pnasnexus/pgaf089
Jiafu An, Difang Huang, Chen Lin, and Mingzhu Tai. Measuring gender and racial biases in large language models: Intersectional evidence from automated resume evaluation.PNAS Nexus, 4(3), February 2025. doi: 10.1093/pnasnexus/pgaf089
-
[4]
Understanding Intrinsic Socioeconomic Biases in Large Language Models
Mina Arzaghi, Florian Carichon, and Golnoosh Farnadi. Understanding Intrinsic Socioeconomic Biases in Large Language Models. InProceedings of the 2024 AAAI/ACM Conference on AI, Ethics, and Society, pages 49–60. AAAI Press, February 2025
2024
-
[5]
API Endpoints
Ask Sage. API Endpoints. https://docs.asksage.ai/docs/api-documentation/api-endpoints.html, January 2026
2026
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Barr, Roger Levy, Christoph Scheepers, and Harry J
Dale J. Barr, Roger Levy, Christoph Scheepers, and Harry J. Tily. Random effects structure for confirmatory hypothesis testing: Keep it maximal.Journal of Memory and Language, 68(3): 255–278, April 2013. ISSN 0749-596X. doi: 10.1016/j.jml.2012.11.001
-
[8]
Jessie S. Barrot and Joan Y. Agdeppa. Complexity, accuracy, and fluency as indices of college- level L2 writers’ proficiency.Assessing Writing, 47:100510, January 2021. ISSN 1075-2935. doi: 10.1016/j.asw.2020.100510
-
[9]
Jill A. Bennett. The Consolidated Standards of Reporting Trials (CONSORT): Guidelines for Reporting Randomized Trials.Nursing Research, 54(2):128, March 2005. ISSN 0029-6562
2005
-
[10]
MarianneBertrandandSendhilMullainathan. AreEmilyandGregMoreEmployableThanLakisha and Jamal? A Field Experiment on Labor Market Discrimination.American Economic Review, 94(4):991–1013, September 2004. ISSN 0002-8282. doi: 10.1257/0002828042002561
-
[11]
Douglas Biber, Bethany Gray, and Kornwipa Poonpon. Should We Use Characteristics of Conver- sation to Measure Grammatical Complexity in L2 Writing Development?TESOL Quarterly, 45 (1):5–35, March 2011. ISSN 0039-8322, 1545-7249. doi: 10.5054/tq.2011.244483
-
[12]
Paul D. Bliese. Group Size, ICC Values, and Group-Level Correlations: A Simulation.Organiza- tional Research Methods, 1998. doi: 10.1177/109442819814001
-
[13]
SafeforDemocracy
ReeveT.Bull. MakingtheAdministrativeState"SafeforDemocracy": ATheoreticalandPractical Analysis of Citizen Participation in Agency Decisionmaking.Administrative Law Review, 65(3): 611–664, 2013. ISSN 0001-8368
2013
-
[14]
Bram Bulté and Alex Housen. Conceptualizing and measuring short-term changes in L2 writing complexity.Journal of Second Language Writing, 26:42–65, December 2014. ISSN 1060-3743. doi: 10.1016/j.jslw.2014.09.005. 21
-
[15]
Isabel Cachola, Daniel Khashabi, and Mark Dredze. Evaluating the Evaluators: Are readability metrics good measures of readability? In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24011–24027, Suzhou, China, November 2025...
-
[16]
Adrian G. Carpusor and William E. Loges. Rental Discrimination and Ethnicity in Names.Journal of Applied Social Psychology, 36(4):934–952, 2006. ISSN 1559-1816. doi: 10.1111/j.0021-9029.2006. 00050.x
-
[17]
Path-Specific Counterfactual Fairness
Silvia Chiappa. Path-Specific Counterfactual Fairness. InProceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7801–7808, July 2019. doi: 10.1609/aaai.v33i01.33017801
-
[18]
Transparency and Public Participation in the Rulemaking Process: Recommendations for the New Administration.George Washington Law Review, June 2009
Cary Coglianese, Heather Kilmartin, and Evan Mendelson. Transparency and Public Participation in the Rulemaking Process: Recommendations for the New Administration.George Washington Law Review, June 2009
2009
-
[19]
2013.Statistical power analysis for the behavioral sciences
Jacob Cohen.Statistical Power Analysis for the Behavioral Sciences. Routledge, New York, 2 edition, May 2013. ISBN 978-0-203-77158-7. doi: 10.4324/9780203771587
-
[20]
Kimberle Crenshaw. Demarginalizing the Intersection of Race and Sex: A Black Feminist Critique of Antidiscrimination Doctrine, Feminist Theory and Antiracist Politics.University of Chicago Legal Forum, 1989(8), 1989
1989
-
[21]
Scott A. Crossley. Linguistic features in writing quality and development: An overview.Journal of Writing Research, 11(3):415–443, February 2020. ISSN 2294-3307. doi: 10.17239/jowr-2020.11. 03.01
-
[22]
Crossley, Franklin Bradfield, and Analynn Bustamante
Scott A. Crossley, Franklin Bradfield, and Analynn Bustamante. Using human judgments to examine the validity of automated grammar, syntax, and mechanical errors in writing.Journal of Writing Research, 11(2):251–270, October2019. ISSN2294-3307. doi: 10.17239/jowr-2019.11.02.01
-
[23]
de Figueiredo
John M. de Figueiredo. E-Rulemaking: Bringing Data to Theory at the Federal Communications Commission.Duke Law Journal, 55(5):969–993, 2006. ISSN 0012-7086
2006
-
[24]
Deliberating Like a State: Locating Public Administration Within the Delibera- tive System.Political Studies, 72(3):924–943, August 2024
Rikki Dean. Deliberating Like a State: Locating Public Administration Within the Delibera- tive System.Political Studies, 72(3):924–943, August 2024. ISSN 0032-3217. doi: 10.1177/ 00323217231166285
2024
-
[25]
Ali Derakhshan and Roghayeh Karimian Shirejini. An Investigation of the Iranian EFL Learners’ Perceptions Towards the Most Common Writing Problems.Sage Open, 10(2):2158244020919523, April 2020. ISSN 2158-2440. doi: 10.1177/2158244020919523
-
[26]
The impact of artificial intelligence (AI) on the public comments process
DocketScope. The impact of artificial intelligence (AI) on the public comments process. White paper, DocketScope, Inc., 2023. https://www.docketscope.com/ai-and-public-comments-process- ebook
2023
-
[27]
Cheryl A. Engber. The relationship of lexical proficiency to the quality of ESL compositions. Journal of Second Language Writing, 4(2):139–155, May 1995. ISSN 1060-3743. doi: 10.1016/ 1060-3743(95)90004-7
1995
-
[28]
Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev
Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. SummEval: Re-evaluating Summarization Evaluation.Transactions of the Association for Computational Linguistics, 9:391–409, April 2021. ISSN 2307-387X. doi: 10.1162/tacl_a_00373. https://doi.org/10.1162/tacl_a_00373
-
[29]
Xiao Fang, Shangkun Che, Minjia Mao, Hongzhe Zhang, Ming Zhao, and Xiaohang Zhao. Bias of AI-generated content: An examination of news produced by large language models.Scientific Reports, 14, September 2023. doi: 10.1038/s41598-024-55686-2
-
[30]
Federal Agencies are Publishing Fewer but Larger Regulations
Mark Febrizio. Federal Agencies are Publishing Fewer but Larger Regulations. Technical report, Regulatory Studies Center, George Washington University, 2021. 22
2021
-
[31]
FedRAMP Marketplace
Federal Risk and Authorization Management Program (FedRAMP). FedRAMP Marketplace. https://marketplace.fedramp.gov/products, January 2026
2026
-
[32]
Gaebler, Sharad Goel, Aziz Huq, and Prasanna Tambe
Johann D. Gaebler, Sharad Goel, Aziz Huq, and Prasanna Tambe. Auditing large language models for race & gender disparities: Implications for artificial intelligence-based hiring.Behavioral Science & Policy, 10(2):46–55, October 2024. ISSN 2379-4607. doi: 10.1177/23794607251320229
-
[33]
Chi, and Alex Beutel
Sahaj Garg, Vincent Perot, Nicole Limtiaco, Ankur Taly, Ed H. Chi, and Alex Beutel. Counterfac- tual Fairness in Text Classification through Robustness. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’19, pages 219–226, New York, NY, USA, January
2019
-
[34]
Association for Computing Machinery. ISBN 978-1-4503-6324-2. doi: 10.1145/3306618. 3317950
-
[35]
Thomas Mesnard Gemma Team, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, Léonard Hussenot, and et al. Gemma. 2024. doi: 10.34740/KAGGLE/M/3301. https://www.kaggle.com/m/3301
-
[36]
Danebeth Tristeza Glomo-Narzoles and Donna Tristeza Glomo-Palermo. Workplace English Lan- guage Needs and their Pedagogical Implications in ESP.International Journal of English Language and Literature Studies, 10(3):202–212, June 2021. ISSN 2306-0646. doi: 10.18488/journal.23.2021. 103.202.212
-
[37]
Yanilda González and Lindsay Mayka. Policing, Democratic Participation, and the Reproduction of Asymmetric Citizenship.American Political Science Review, 117(1):263–279, February 2023. ISSN 0003-0554, 1537-5943. doi: 10.1017/S0003055422000636
-
[38]
Thompson.Why Deliberative Democracy?Princeton University Press, December 2016
Amy Gutmann and Dennis F. Thompson.Why Deliberative Democracy?Princeton University Press, December 2016. ISBN 978-1-4008-2633-9. doi: 10.1515/9781400826339
-
[39]
Who’s Asking? Investigating Bias Through the Lens of Disability-Framed Queries in LLMs
Vishnu Hari, Kalpana Panda, Srikant Panda, Amit Agarwal, and Hitesh Laxmichand Patel. Who’s Asking? Investigating Bias Through the Lens of Disability-Framed Queries in LLMs. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6644–6655, 2025
2025
-
[40]
More than a Feeling: Accuracy and Application of Sentiment Analysis , journal =
Jochen Hartmann, Mark Heitmann, Christian Siebert, and Christina Schamp. More than a Feeling: Accuracy and Application of Sentiment Analysis.International Journal of Research in Marketing, 40(1):75–87, March 2023. ISSN 0167-8116. doi: 10.1016/j.ijresmar.2022.05.005
-
[41]
Yu Huang and Lawrence Jun Zhang. Does a Process-Genre Approach Help Improve Students’ Argumentative Writing in English as a Foreign Language? Findings From an Intervention Study. Reading & Writing Quarterly, 36(4):339–364, July 2020. ISSN 1057-3569. doi: 10.1080/10573569. 2019.1649223
-
[42]
Occupational Prestige, December 2019
Bradley Hughes, David Condon, and Sanjay Srivastava. Occupational Prestige, December 2019. URLhttps://osf.io/ngk2t
2019
-
[43]
Hughes, Sanjay Srivastava, Magdalena Leszko, and David M
Bradley T. Hughes, Sanjay Srivastava, Magdalena Leszko, and David M. Condon. Occupational Prestige: The Status Component of Socioeconomic Status.Collabra: Psychology, 10(1), January
-
[44]
doi: 10.1525/collabra.92882
-
[45]
Gpt-4o system card, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card, 2024
2024
-
[46]
The Public Trust: Administrative Legitimacy and Democratic Lawmaking
Katharine Jackson. The Public Trust: Administrative Legitimacy and Democratic Lawmaking. Connecticut Law Review, 56(1):1–86, 2023–2024
2023
-
[47]
Johnson, Joseph H
Carla J. Johnson, Joseph H. Beitchman, and E. B. Brownlie. Twenty-Year Follow-Up of Chil- dren With and Without Speech-Language Impairments: Family, Educational, Occupational, and Quality of Life Outcomes.American Journal of Speech-Language Pathology, 19(1):51–65, February
-
[48]
doi: 10.1044/1058-0360(2009/08-0083)
-
[49]
Robustly Improving LLM Fairness in Realistic Settings via Interpretability, June 2025
Adam Karvonen and Samuel Marks. Robustly Improving LLM Fairness in Realistic Settings via Interpretability, June 2025. 23
2025
-
[50]
Haymarket Books, Chicago, Illinois, 2017
Keeanga-Yamahtta Taylor, editor.How We Get Free: Black Feminism and the Combahee River Collective. Haymarket Books, Chicago, Illinois, 2017. ISBN 978-1-60846-855-3
2017
-
[51]
Understanding Gen- der Bias in AI-Generated Product Descriptions
Markelle Kelly, Mohammad Tahaei, Padhraic Smyth, and Lauren Wilcox. Understanding Gen- der Bias in AI-Generated Product Descriptions. InProceedings of the 2025 ACM Confer- ence on Fairness, Accountability, and Transparency, FAccT ’25, pages 2587–2615, New York, NY, USA, June 2025. Association for Computing Machinery. ISBN 979-8-4007-1482-5. doi: 10.1145/3...
-
[52]
All Public Voices Are Equal, But Are Some More Equal Than Others to LLMs?, February 2026
Sola Kim, Marco Janssen, Jieshu Wang, Ame Min-Venditti, Neha Karanjia, and Marty Anderies. All Public Voices Are Equal, But Are Some More Equal Than Others to LLMs?, February 2026
2026
-
[53]
Folsom, Luana Greulich, and Cynthia Puranik
Young-Suk Kim, Stephanie Al Otaiba, Jessica S. Folsom, Luana Greulich, and Cynthia Puranik. Evaluating the dimensionality of first grade written composition.Journal of speech, language, and hearing research, 57(1):199–211, February 2014. ISSN 1092-4388. doi: 10.1044/1092-4388
-
[54]
J. P. Kincaid, Jr. Fishburne, Richard L. Rogers, and Brad S. Chissom. Derivation of New Read- ability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel:. Technical report, Defense Technical Information Center, Fort Belvoir, VA, January 1975
1975
-
[55]
Neural Text Summarization: A Critical Evaluation
Wojciech Kryscinski, Nitish Shirish Keskar, Bryan McCann, Caiming Xiong, and Richard Socher. Neural Text Summarization: A Critical Evaluation. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Languag...
-
[56]
Evaluating the Factual Consistency of Abstractive Text Summarization
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the Factual Consistency of Abstractive Text Summarization. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9332–9346, Online, November 2020. Association for Co...
-
[57]
Kumar, Saurav Sahay, Sahisnu Mazumder, Eda Okur, Ramesh Manuvinakurike, Nicole Marie Beckage, Hsuan Su, Hung-yi Lee, and Lama Nachman
Shachi H. Kumar, Saurav Sahay, Sahisnu Mazumder, Eda Okur, Ramesh Manuvinakurike, Nicole Marie Beckage, Hsuan Su, Hung-yi Lee, and Lama Nachman. Decoding Biases: An Analysis of Automated Methods and Metrics for Gender Bias Detection in Language Models. InNeurIPS 2024 Workshop Red Teaming GenAI, January 2025
2024
-
[58]
Counterfactual fairness
Matt Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. Counterfactual fairness. InPro- ceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pages 4069–4079, Red Hook, NY, USA, December 2017. Curran Associates Inc. ISBN 978-1-5108- 6096-4
2017
-
[59]
Kristopher Kyle and Scott A. Crossley. Automatically Assessing Lexical Sophistication: Indices, Tools, Findings, and Application.TESOL Quarterly, 49(4):757–786, 2015. ISSN 1545-7249. doi: 10.1002/tesq.194
-
[60]
Kristopher Kyle and Scott A. Crossley. Measuring Syntactic Complexity in L2 Writing Using Fine-Grained Clausal and Phrasal Indices.The Modern Language Journal, 102(2):333–349, 2018. ISSN 1540-4781. doi: 10.1111/modl.12468
-
[61]
Batia Laufer and Paul Nation. Vocabulary Size and Use: Lexical Richness in L2 Writ- ten Production.Applied Linguistics - APPL LINGUIST, 16:307–322, September 1995. doi: 10.1093/applin/16.3.307
-
[62]
James M. LeBreton and Jenell L. Senter. Answers to 20 Questions About Interrater Reliability and Interrater Agreement.Organizational Research Methods, 11(4):815–852, October 2008. ISSN 1094-4281. doi: 10.1177/1094428106296642
-
[63]
Reference-free Summarization Evaluation via Semantic Correlation and Compression Ratio
Yizhu Liu, Qi Jia, and Kenny Zhu. Reference-free Summarization Evaluation via Semantic Correlation and Compression Ratio. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz, editors,Proceedings of the 2022 Conference of the North American 24 Chapter of the Association for Computational Linguistics: Human Language Technologies, pag...
-
[64]
Xiaofei Lu. A Corpus-Based Evaluation of Syntactic Complexity Measures as Indices of College- Level ESL Writers’ Language Development.TESOL Quarterly, 45(1):36–62, March 2011. ISSN 0039-8322, 1545-7249. doi: 10.5054/tq.2011.240859
-
[65]
Steven G. Luke. Evaluating significance in linear mixed-effects models in R.Behavior Research Methods, 49(4):1494–1502, August 2017. ISSN 1554-3528. doi: 10.3758/s13428-016-0809-y
-
[66]
Milkman, Modupe Akinola, and Dolly Chugh
Katherine L. Milkman, Modupe Akinola, and Dolly Chugh. What happens before? A field ex- periment exploring how pay and representation differentially shape bias on the pathway into or- ganizations.Journal of Applied Psychology, 100(6):1678–1712, November 2015. ISSN 1939-1854, 0021-9010. doi: 10.1037/apl0000022
-
[67]
Dan Nally, Mike Parker, Matthew Aumeier, Kevin Murphy, Michelle Rau, James McWalter, Jack Titus, Lauren Schramm, Reilly Raab, Anurag Acharya, Sarthak Chaturvedi, Anastasia Bernat, Sai Munikoti, and Sameera Horawalavithana. Workshop summary report on using AI tools to improve the efficiency and outcomes of the NEPA process: AI for permitting workshop at th...
2025
-
[68]
Courtney Napoles, Maria Nădejde, and Joel Tetreault. Enabling Robust Grammatical Er- ror Correction in New Domains: Data Sets, Metrics, and Analyses.Transactions of the As- sociation for Computational Linguistics, 7:551–566, September 2019. ISSN 2307-387X. doi: 10.1162/tacl_a_00282
-
[69]
Huy Nghiem, Phuong-Anh Nguyen-Le, John Prindle, Rachel Rudinger, and Hal Daumé III. ‘Rich Dad, Poor Lad’: How do Large Language Models Contextualize Socioeconomic Factors in College Admission ? In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Langu...
-
[70]
2024 Federal AI Use Case Inventory
Office of Management and Budget and Federal Chief Information Officers Council. 2024 Federal AI Use Case Inventory. Technical report, Office of Management and Budget (OMB); CIO.gov, Washington, DC, December 2024
2024
-
[71]
Office of Management and Budget and Shalanda D. Young. Modernizing the Federal Risk and Authorization Management Program (FedRAMP). Technical Report M-24-15, Executive Office of the President, Office of Management and Budget, Washington, D.C., July 2024
2024
-
[72]
Ollama. Ollama. https://github.com/ollama/ollama, January 2026
2026
-
[73]
MahmudOmar, ShellySoffer, ReemAgbareia, NicolaLuigiBragazzi, DonaldU.Apakama, CarolR. Horowitz, Alexander W. Charney, Robert Freeman, Benjamin Kummer, Benjamin S. Glicksberg, Girish N. Nadkarni, and Eyal Klang. Sociodemographic biases in medical decision making by large language models.Nature Medicine, 31(6):1873–1881, June 2025. ISSN 1546-170X. doi: 10.1...
-
[74]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
2022
-
[75]
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thomp- son, Phu Mon Htut, and Samuel Bowman. BBQ: A hand-built bias benchmark for question answering. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Findings of 25 the Association for Computational Linguistics: ACL 2022, pages 2086–2105, Dublin, Irela...
-
[76]
Active Learning for e-Rulemaking: Public Comment Categorization
Stephen Purpura, Claire Cardie, and Jesse Simons. Active Learning for e-Rulemaking: Public Comment Categorization. InThe Proceedings of the 9th Annual International Digital Government Research Conference, May 2008
2008
-
[77]
Lincoln Quillian, Devah Pager, Ole Hexel, and Arnfinn H. Midtbøen. Meta-analysis of field exper- iments shows no change in racial discrimination in hiring over time.Proceedings of the National Academy of Sciences, 114(41):10870–10875, October 2017. doi: 10.1073/pnas.1706255114
-
[78]
In: Inui, K., Jiang, J., Ng, V., Wan, X
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT- Networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th In- ternational Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982– 39...
-
[79]
Sara Rinfret, Robert Duffy, Jeffrey Cook, and Shane St. Onge. Bots, fake comments, and E- rulemaking: The impact on federal regulations.International Journal of Public Administration, 45(11):859–867, August 2022. ISSN 0190-0692. doi: 10.1080/01900692.2021.1931314
-
[80]
Robert, Nicolas Chopin, and Judith Rousseau
Christian P. Robert, Nicolas Chopin, and Judith Rousseau. Harold Jeffreys’s Theory of Probability Revisited.Statistical Science, 24(2):141–172, 2009. ISSN 0883-4237
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.