Recognition: unknown
SkillFlow:Benchmarking Lifelong Skill Discovery and Evolution for Autonomous Agents
Pith reviewed 2026-05-10 06:09 UTC · model grok-4.3
The pith
Agents can modestly raise task success by discovering and patching skills across sequential problems, yet many models gain little or nothing from the skills they accumulate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
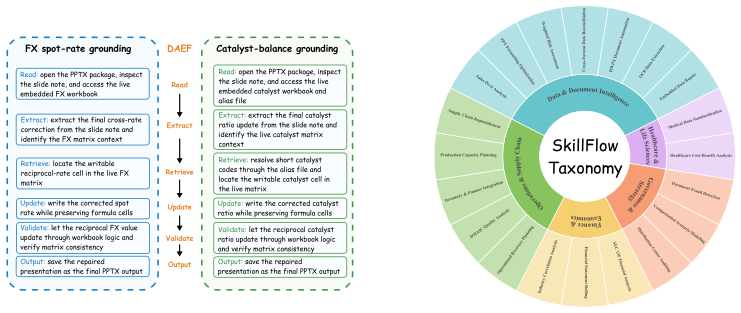
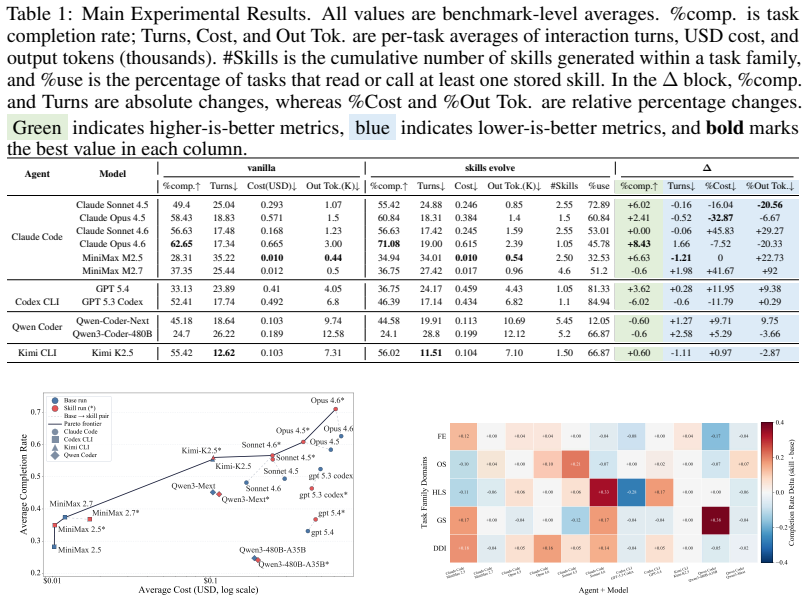
SkillFlow is a benchmark of 166 tasks across 20 families built with a Domain-Agnostic Execution Flow that enforces consistent workflows within each family. Agents operate under an Agentic Lifelong Learning protocol: they begin with an empty skill library, attempt tasks sequentially, generate patches based on execution trajectories and rubric feedback, and carry the updated library into subsequent tasks. This process yields a performance increase for capable models, such as an 8.43-point rise in task success for one frontier model, while revealing that high rates of skill invocation frequently fail to translate into proportional utility and can even produce regression in other models.
What carries the argument
The Agentic Lifelong Learning protocol, which drives sequential task solving followed by trajectory- and rubric-based skill patching and library carry-forward within families defined by Domain-Agnostic Execution Flow.
If this is right
- Agents that reliably patch and retain skills could handle longer sequences of related tasks with progressively less external guidance.
- Benchmarks must separately track skill usage and skill utility, because high invocation rates alone do not predict performance gains.
- The identified regression cases after patching indicate that agents require mechanisms to validate or prune low-value skills before adding them to the library.
- Consistent workflow structures across task families enable measurable skill transfer that may extend to open-ended agent deployments.
Where Pith is reading between the lines
- The same protocol could be applied to task families drawn from entirely separate domains to test whether skill libraries remain coherent when workflows diverge.
- Models that invoke skills heavily yet gain little may lack an internal way to judge skill quality apart from immediate task outcome, suggesting a need for explicit utility estimation.
- If task families were expanded while preserving the execution-flow constraint, the benchmark could reveal whether skill evolution generalizes beyond the initial 20 families.
Load-bearing premise
The 166 tasks and the sequential patching protocol measure genuine skill discovery, repair, and transfer without being distorted by the way the tasks were constructed or by model-specific prompting effects.
What would settle it
An experiment in which the same models are given a fixed, high-quality skill library at the outset and achieve success rates that match or exceed those reached through the full lifelong patching process would show that the discovery and evolution steps add no unique benefit.
Figures






read the original abstract
As the capability frontier of autonomous agents continues to expand, they are increasingly able to complete specialized tasks through plug-and-play external skills. Yet current benchmarks mostly test whether models can use provided skills, leaving open whether they can discover skills from experience, repair them after failure, and maintain a coherent library over time. We introduce SkillFlow, a benchmark of 166 tasks across 20 families in which task construction within each family follows a Domain-Agnostic Execution Flow (DAEF) that defines an agent workflow framework, allowing these tasks to share a consistent workflow. Agents are evaluated under an Agentic Lifelong Learning protocol in which they begin without skills, solve tasks sequentially within each family, externalize lessons through trajectory- and rubric-driven skill patches, and carry the updated library forward. Experiments reveal a substantial capability gap. For Claude Opus 4.6, lifelong skill evolution improves task success from 62.65% to 71.08% (+8.43 points). However, high skill usage does not necessarily imply high utility: Kimi K2.5 gains only +0.60 points despite 66.87% skill usage, while Qwen-Coder-Next reaches only a 44.58% task completion rate and still regresses relative to the vanilla setting. SkillFlow contributes a structured testbed for this direction and an in-depth empirical analysis of skill discovery, patching, transfer, and their failure modes under lifelong evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillFlow, a benchmark of 166 tasks across 20 families constructed via Domain-Agnostic Execution Flow (DAEF) to enforce consistent agent workflows within families. Agents are evaluated under an Agentic Lifelong Learning protocol: starting with no skills, solving tasks sequentially, externalizing lessons via trajectory- and rubric-driven patches, and carrying the skill library forward across tasks. Experiments report concrete deltas, e.g., Claude Opus 4.6 task success rising from 62.65% to 71.08% (+8.43 points) under lifelong evolution, while highlighting that high skill usage does not guarantee utility (Kimi K2.5: +0.60 points at 66.87% usage; Qwen-Coder-Next regresses to 44.58%). The work positions SkillFlow as a testbed for skill discovery, repair, transfer, and failure modes.
Significance. If the benchmark and protocol validly isolate emergent skill evolution rather than workflow familiarity or rubric quality, the contribution would be meaningful: it fills a gap left by benchmarks that only test plug-and-play skill usage. The empirical breakdown of usage-vs-utility cases and model-specific failure modes offers concrete data points for future agent research. The structured DAEF construction and lifelong carry-over protocol are clear strengths that could support reproducible follow-up work.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the headline claim of a 'substantial capability gap' and the specific deltas (Claude +8.43 points, Kimi +0.60 at 66.87% usage) are presented without reported controls, number of runs, variance, statistical significance tests, or exclusion criteria for task outcomes. This makes it impossible to determine whether the numbers support the central claim of genuine skill evolution.
- [Task Construction / Agentic Lifelong Learning Protocol] Task construction and protocol description (likely §3–4): DAEF supplies a shared workflow skeleton within each family and rubric-driven patching encodes human-derived success criteria. No ablation (rubric detail level, cross-family transfer, or workflow-ablated baseline) is described to rule out the alternative that gains arise from repeated scaffold exposure or instruction-following rather than discovered skill libraries. This directly affects whether the +8.43-point improvement isolates the intended phenomenon.
- [Results / Analysis] Results analysis of skill usage vs. utility (Kimi and Qwen cases): the observation that high usage need not produce high utility is noted but lacks quantitative breakdown of patch quality, skill retention across families, or model-specific patching failure modes. Without this, the claim that the benchmark reveals distinct discovery/repair/transfer behaviors remains under-supported.
minor comments (2)
- [Abstract] Abstract: 'Domain-Agnostic Execution Flow' and 'Agentic Lifelong Learning protocol' are introduced without a one-sentence operational definition, which would aid readers before the detailed sections.
- [Figures / Tables] Figure and table captions (throughout): ensure all report exact task counts per family, number of models evaluated, and whether success rates are macro- or micro-averaged.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments. We address each major point below and commit to revisions that will strengthen the empirical rigor and clarity of the claims regarding skill evolution.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline claim of a 'substantial capability gap' and the specific deltas (Claude +8.43 points, Kimi +0.60 at 66.87% usage) are presented without reported controls, number of runs, variance, statistical significance tests, or exclusion criteria for task outcomes. This makes it impossible to determine whether the numbers support the central claim of genuine skill evolution.
Authors: We agree that the reported deltas require statistical support to substantiate the central claims. In the revised manuscript we will add results from multiple independent runs (minimum of three per model, subject to computational constraints), report means and standard deviations, apply appropriate significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests), and explicitly state exclusion criteria for task outcomes. These details will be incorporated into the Experiments section and the abstract will be updated accordingly. revision: yes
-
Referee: [Task Construction / Agentic Lifelong Learning Protocol] Task construction and protocol description (likely §3–4): DAEF supplies a shared workflow skeleton within each family and rubric-driven patching encodes human-derived success criteria. No ablation (rubric detail level, cross-family transfer, or workflow-ablated baseline) is described to rule out the alternative that gains arise from repeated scaffold exposure or instruction-following rather than discovered skill libraries. This directly affects whether the +8.43-point improvement isolates the intended phenomenon.
Authors: The referee correctly notes the lack of ablations to isolate skill evolution from workflow familiarity. We will add a workflow-ablated baseline that removes the shared DAEF skeleton within families and an ablation varying rubric detail levels. We will also quantify cross-family transfer by reporting skill retention and success rates when skills move between families. These experiments will be included in the revised Experiments section to better demonstrate that gains arise from the skill library rather than scaffold exposure. revision: yes
-
Referee: [Results / Analysis] Results analysis of skill usage vs. utility (Kimi and Qwen cases): the observation that high usage need not produce high utility is noted but lacks quantitative breakdown of patch quality, skill retention across families, or model-specific patching failure modes. Without this, the claim that the benchmark reveals distinct discovery/repair/transfer behaviors remains under-supported.
Authors: We acknowledge that the current analysis would be strengthened by quantitative breakdowns. The revised Results section will include metrics on patch quality (fraction of patches that improve subsequent task performance), skill retention rates across families, and a categorized taxonomy of model-specific patching failure modes. These will be presented in additional tables and figures to provide firmer support for the observed differences in discovery, repair, and transfer behaviors. revision: yes
Circularity Check
No circularity: empirical benchmark with direct performance measurements
full rationale
The paper introduces the SkillFlow benchmark consisting of 166 tasks across 20 families constructed via Domain-Agnostic Execution Flow (DAEF) and evaluates agents under an Agentic Lifelong Learning protocol. Reported results (e.g., Claude Opus 4.6 success rising from 62.65% to 71.08%) are direct empirical measurements of task completion rates before and after skill library updates. No equations, first-principles derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or described structure. The central claims rest on observable outcomes under explicitly defined task families and patching rules rather than any reduction of outputs to inputs by construction. Potential confounding from task design or rubrics is a validity concern but does not constitute circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task construction within each family follows a Domain-Agnostic Execution Flow (DAEF) that defines an agent workflow framework allowing tasks to share a consistent workflow.
Reference graph
Works this paper leans on
-
[1]
Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766,
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766, 2026
-
[2]
Claude Code: an agentic coding tool
Anthropic. Claude Code: an agentic coding tool. https://github.com/anthropics/ claude-code, 2025
2025
-
[3]
anthropics/skills: Public repository for agent skills
Anthropic. anthropics/skills: Public repository for agent skills. https://github.com/ anthropics/skills, 2026. GitHub repository. Accessed: 2026-04-13
2026
-
[4]
Cursor: Ai code editor.https://cursor.sh, 2024
Anysphere. Cursor: Ai code editor.https://cursor.sh, 2024
2024
-
[5]
Coding agents are effective long-context processors
Weili Cao, Xunjian Yin, Bhuwan Dhingra, and Shuyan Zhou. Coding agents are effective long-context processors.arXiv preprint arXiv:2603.20432, 2026
-
[6]
arXiv preprint arXiv:2603.00718 , year=
Shiqi Chen, Jingze Gai, Ruochen Zhou, Jinghan Zhang, Tongyao Zhu, Junlong Li, Kangrui Wang, Zihan Wang, Zhengyu Chen, Klara Kaleb, et al. Skillcraft: Can llm agents learn to use tools skillfully?arXiv preprint arXiv:2603.00718, 2026
-
[7]
Jason Chou, Ao Liu, Yuchi Deng, Zhiying Zeng, Tao Zhang, Haotian Zhu, Jianwei Cai, Yue Mao, Chenchen Zhang, Lingyun Tan, et al. Autocodebench: Large language models are automatic code benchmark generators.arXiv preprint arXiv:2508.09101, 2025
-
[8]
awesome-claude-skills: A curated list of awesome claude skills, resources, and tools
ComposioHQ. awesome-claude-skills: A curated list of awesome claude skills, resources, and tools. https://github.com/ComposioHQ/awesome-claude-skills, 2026. GitHub reposi- tory. Accessed: 2026-04-13
2026
-
[9]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Zhen Fang, Zhuoyang Liu, Jiaming Liu, Hao Chen, Yu Zeng, Shiting Huang, Zehui Chen, Lin Chen, Shanghang Zhang, and Feng Zhao. Dualvla: Building a generalizable embodied agent via partial decoupling of reasoning and action.arXiv preprint arXiv:2511.22134, 2025
-
[11]
Gemini CLI: An open-source AI agent that brings the power of Gemini directly into your terminal.https://github.com/google-gemini/gemini-cli, 2025
Google. Gemini CLI: An open-source AI agent that brings the power of Gemini directly into your terminal.https://github.com/google-gemini/gemini-cli, 2025
2025
-
[12]
Ruiyan Han, Zhen Fang, XinYu Sun, Yuchen Ma, Ziheng Wang, Yu Zeng, Zehui Chen, Lin Chen, Wenxuan Huang, Wei-Jie Xu, et al. Unicorn: Towards self-improving unified multimodal models through self-generated supervision.arXiv preprint arXiv:2601.03193, 2026
-
[13]
Tingxu Han, Yi Zhang, Wei Song, Chunrong Fang, Zhenyu Chen, Youcheng Sun, and Lijie Hu. Swe-skills-bench: Do agent skills actually help in real-world software engineering?arXiv preprint arXiv:2603.15401, 2026
-
[14]
Harbor: A framework for evaluating and optimizing agents and models in container environments
Harbor Framework Team. Harbor: A framework for evaluating and optimizing agents and models in container environments. https://github.com/harbor-framework/harbor, 2026. GitHub repository. Accessed: 2026-04-16
2026
-
[15]
Shiting Huang, Zhen Fang, Zehui Chen, Siyu Yuan, Junjie Ye, Yu Zeng, Lin Chen, Qi Mao, and Feng Zhao. CRITICTOOL: Evaluating self-critique capabilities of large language models in tool-calling error scenarios. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods ...
-
[16]
Shiting Huang, Zecheng Li, Yu Zeng, Qingnan Ren, Zhen Fang, Qisheng Su, Kou Shi, Lin Chen, Zehui Chen, and Feng Zhao. Internalizing meta-experience into memory for guided reinforcement learning in large language models.arXiv preprint arXiv:2602.10224, 2026
-
[17]
Wenxuan Huang, Yu Zeng, Qiuchen Wang, Zhen Fang, Shaosheng Cao, Zheng Chu, Qingyu Yin, Shuang Chen, Zhenfei Yin, Lin Chen, et al. Vision-deepresearch: Incentivizing deepresearch capability in multimodal large language models.arXiv preprint arXiv:2601.22060, 2026
-
[18]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023. 10
work page internal anchor Pith review arXiv 2023
-
[19]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review arXiv 2026
-
[20]
SkillNet: Create, evaluate, and connect AI skills,
Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, et al. Skillnet: Create, evaluate, and connect ai skills. arXiv preprint arXiv:2603.04448, 2026
-
[21]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review arXiv 2026
-
[23]
Kimi cli
Moonshot AI. Kimi cli. https://github.com/MoonshotAI/kimi-cli, 2024. GitHub reposi- tory, commit abc123, Accessed: 2026-04-02
2024
-
[24]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Codex CLI: Lightweight coding agent that runs in your terminal
OpenAI. Codex CLI: Lightweight coding agent that runs in your terminal. https://github. com/openai/codex, 2025
2025
-
[26]
Introducing gpt-5.3-codex
OpenAI. Introducing gpt-5.3-codex. https://openai.com/index/ introducing-gpt-5-3-codex/, 2026
2026
-
[27]
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[28]
Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Simón Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, et al. Gdpval: Evaluating ai model performance on real-world economically valuable tasks.arXiv preprint arXiv:2510.04374, 2025
-
[29]
Pinchbench: Skill-based benchmark for llm agents
PinchBench Team. Pinchbench: Skill-based benchmark for llm agents. https://github.com/ pinchbench, 2026
2026
-
[30]
Qwen-code
Qwen Team. Qwen-code. https://github.com/QwenLM/qwen-code, 2025. GitHub reposi- tory, Accessed: 2026-04-02
2025
-
[31]
Skillsmp: Skills marketplace
SkillsMP. Skillsmp: Skills marketplace. https://skillsmp.com/, 2026. Website. Accessed: 2026-04-13
2026
-
[32]
Beyond Accuracy: Unveiling Inefficiency Patterns in Tool-Integrated Reasoning
Qisheng Su, Shiting Huang, Zhen Fang, Ziyan Chen, Zehui Chen, and Feng Zhao. Beyond accuracy: Unveiling inefficiency patterns in tool-integrated reasoning, 2026. URL https: //arxiv.org/abs/2604.05404
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
2024
-
[34]
awesome-openclaw-skills: The awesome collection of openclaw skills
V oltAgent. awesome-openclaw-skills: The awesome collection of openclaw skills. https: //github.com/VoltAgent/awesome-openclaw-skills, 2026. GitHub repository. Accessed: 2026-04-13
2026
-
[35]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Chunqiu Steven Xia, Yinlin Deng, and Lingming Zhang. Top leaderboard ranking= top coding proficiency, always? evoeval: Evolving coding benchmarks via llm.arXiv preprint arXiv:2403.19114, 2024. 11
-
[37]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
work page internal anchor Pith review arXiv 2026
-
[38]
Xskill: Cross embodiment skill discovery
Mengda Xu, Zhenjia Xu, Cheng Chi, Manuela Veloso, and Shuran Song. Xskill: Cross embodiment skill discovery. InConference on robot learning, pages 3536–3555. PMLR, 2023
2023
-
[39]
arXiv preprint arXiv:2603.01145 , year=
Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yuxuan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, et al. Autoskill: Experience-driven lifelong learning via skill self-evolution. arXiv preprint arXiv:2603.01145, 2026
-
[40]
Yu Zeng, Wenxuan Huang, Zhen Fang, Shuang Chen, Yufan Shen, Yishuo Cai, Xiaoman Wang, Zhenfei Yin, Lin Chen, Zehui Chen, et al. Vision-deepresearch benchmark: Rethinking visual and textual search for multimodal large language models.arXiv preprint arXiv:2602.02185, 2026
-
[41]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents.arXiv preprint arXiv:2602.02474, 2026
work page internal anchor Pith review arXiv 2026
-
[42]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review arXiv 2025
-
[43]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng, Michael Y Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, et al. Skillweaver: Web agents can self-improve by discovering and honing skills.arXiv preprint arXiv:2504.07079, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
Memento-skills: Let agents design agents
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents. arXiv preprint arXiv:2603.18743, 2026. 12 A Benchmark Details A.1 Comparison Table 2: Comparison between SKILLFLOWand representative benchmarks from the perspective of skill lifecyc...
-
[45]
Derive the reusable capability from this trace
-
[46]
Explicitly identify any wrong assumptions , brittle choices , or dead - end strategies
Compare the agent's apparent plan against verifier outcomes , failed tests , and concrete tool results . Explicitly identify any wrong assumptions , brittle choices , or dead - end strategies
-
[47]
Identify the strongest trigger phrases or task types this skill should support
-
[48]
Extract the minimal reusable workflow , validation steps , failure - prevention guidance , and anti - patterns to avoid
-
[49]
If the current approach failed or was brittle , infer the next - best direction , fallback , or escalation path that a future agent should try earlier , even if that exact fix was not fully executed in the trace
-
[50]
Convert those lessons into reusable decision rules , such as when to switch tools , inspect lower - level formats , add verification earlier , or abandon a high - level API
-
[51]
md`, a new skill directory ,`references /`,`scripts /`, or`assets /`
Decide whether the knowledge belongs in an existing`SKILL . md`, a new skill directory ,`references /`,`scripts /`, or`assets /`
-
[52]
when to use
Keep the patch small , high - signal , and generalized . ## Skill authoring checklist - Do not encode task - specific filled values , IDs , or one - off outputs unless they belong in a reusable template . - Prefer one skill directory per capability . - If creating a new skill , create`skill - name / SKILL . md`instead of writing a bare `SKILL . md`at the ...
-
[53]
py`to compute values in Python and inject them into the XLSX XML
** XML - level patching ** ( most reliable , no external deps ) : Write formulas with openpyxl , then use`scripts / p a t c h _ c a c h e d _ v a l u e s . py`to compute values in Python and inject them into the XLSX XML . ** Do this in a single pass ** --- multiple XML patches can corrupt formula cells
-
[54]
** LibreOffice recalc **: If available , use`scripts / l i b re o f fi c e _r e c al c . sh`. Check with`which libreoffice`
-
[55]
n "`) and string values (`t =
**`formulas`library **:`pip install formulas -- break - system - packages`. Note : often fails to produce openpyxl - readable cached values . ** Do not rely on this as primary approach .** ### XML Patching Workflow ```bash # After saving workbook with openpyxl : python3 scripts / p a t c h _ c a c h e d _ v a l u e s . py / root / output / result . xlsx `...
-
[56]
** Read test file ** to understand verification method
-
[57]
** Examine workbook structure ** --- both sheets , all rows / columns , identify : - Yellow / highlighted cells ( targets ) --- check fill colors - Header rows with labels / years - Source data ranges - Series code columns for lookups - Pre - existing formulas ( e . g . ,`= B12`in label cells )
-
[58]
** Map the layout precisely ** --- off - by - one row / column errors are common
-
[59]
** Write formulas ** with correct absolute / relative references : -`$D12`--- absolute column , relative row -`H$10`--- relative column , absolute row -`$H$21 : $L$38`--- fully absolute range
-
[60]
** Save with openpyxl ** ( preserves formatting )
-
[61]
** Patch cached values ** using XML - level approach ( single pass )
-
[62]
py`to confirm all formula cells have cached values
** Verify output ** --- run`scripts / verify_formulas . py`to confirm all formula cells have cached values
-
[63]
excel-formula-tasks/scripts/patch_cached_values.py
** Run the test suite ** before declaring done : ```bash cd / root && python -m pytest test_output . py -v 2 >&1 | head -80 ``` ## Common Formula Patterns ### INDEX / MATCH Lookup ```python formula = f'= INDEX ( Data ! $H$21 : $L$38 , MATCH ( $D { row } , Data ! $D$21 : $D$38 ,0) , MATCH ({ col } $10 , Data ! $H$4 : $L$4 ,0) )' ``` ### Net Gap / Derived P...
-
[64]
Reads the workbook to find all formula cells
-
[65]
Computes expected values using Python ( simulating INDEX / MATCH , arithmetic , stats )
-
[66]
"" Convert column letter ( s ) to 0 - based index
Patches the <v > elements in the worksheet XML so data_only = True returns values IMPORTANT : Run this ONCE after saving with openpyxl . Multiple runs may corrupt formulas . """ import sys import re import zipfile import xml . etree . ElementTree as ET import shutil import os import openpyxl import statistics NS ='http :// schemas . openxmlformats . org /...
2006
-
[67]
Multiple patches can corrupt formula cells by losing`<f >`elements
** Single pass only .** Each patch reopens the ZIP . Multiple patches can corrupt formula cells by losing`<f >`elements
-
[68]
** Compute ALL values in Python first ** , then patch all at once
-
[69]
str "`. Numeric results should not have`t =
** Handle string vs numeric types .** String formula results ( e . g . ,`= B12` referencing text ) need`t =" str "`. Numeric results should not have`t =" s "`
-
[70]
xml`--- it may not exist
** List ZIP contents first ** if you need`sharedStrings . xml`--- it may not exist
-
[71]
excel-formula-tasks
** Sheet filename :** Usually`xl / worksheets / sheet1 . xml`for the first sheet . Check the workbook's`xl / _rels / workbook . xml . rels`if unsure . ## Computing Formula Values in Python For INDEX / MATCH lookups , build a lookup dict from the Data sheet : ```python # Build lookup : ( series_code , year ) -> value lookup = {} for row in range ( data_sta...
2020
-
[72]
The agent correctly inferred that workbook inspection and verifier inspection must happen before editing
-
[73]
The agent identified the spreadsheet-specific failure mode that formulas can exist without cached values, which breaks downstream checking underdata_only=True
-
[74]
Unknown option -- recalculate
The agent encountered a self-induced corruption caused by XML patching, explicitly diagnosed it, restarted from the original workbook, and produced a clean final artifact. 39 D.3 FAILURE TAXONOMY EXAMPLES D.3.1 Verifier Toolchain Mismatch Failure Mode:Verifier / toolchain incompatibility Task:api-sla-at-risk-calc Other Failure Modes:Missing recalculation ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.