Recognition: unknown
A Survey of Reinforcement Learning for Large Language Models under Data Scarcity: Challenges and Solutions
Pith reviewed 2026-05-10 06:34 UTC · model grok-4.3
The pith
A hierarchical framework organizes data-efficient reinforcement learning methods for large language models into data-centric, training-centric, and framework-centric perspectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
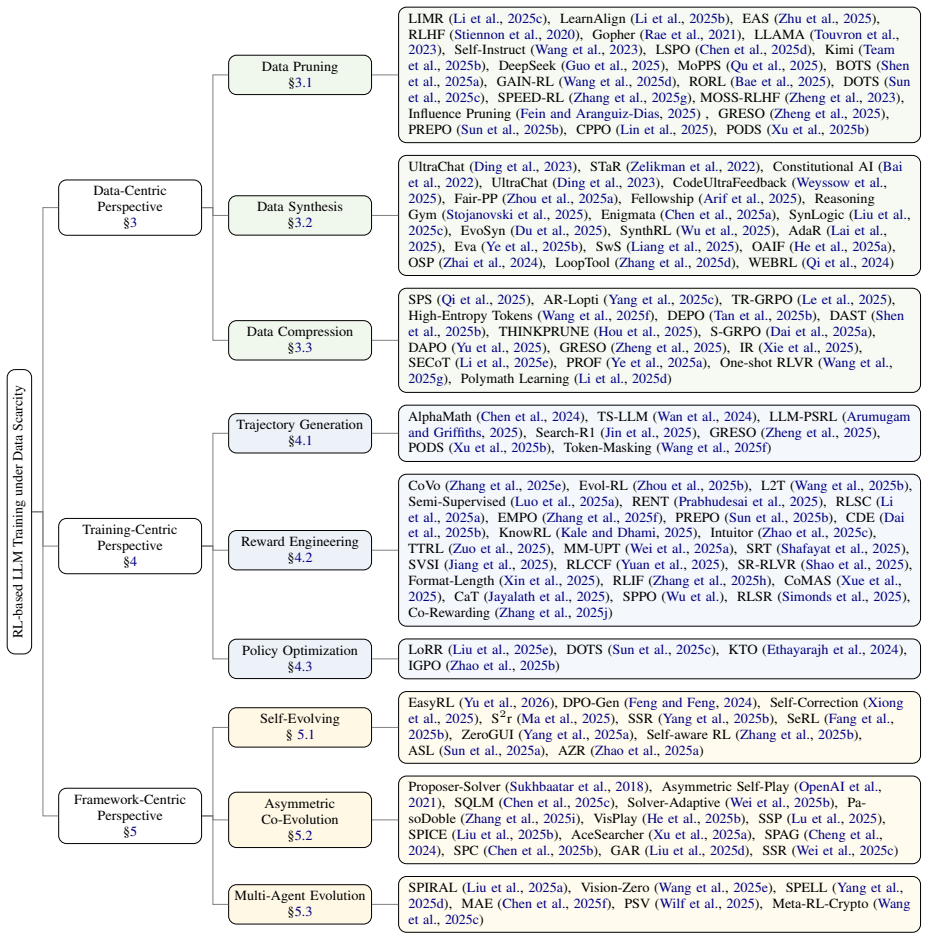
The authors propose a bottom-up hierarchical framework built around three complementary perspectives—the data-centric perspective, the training-centric perspective, and the framework-centric perspective—to structure the design space of data-efficient reinforcement learning for LLMs. Within this structure they develop a taxonomy of existing methods, summarize representative approaches in each category, and analyze their strengths and limitations, with the explicit goal of providing a clear conceptual foundation and a roadmap for future research.
What carries the argument
A bottom-up hierarchical framework that partitions data-efficient RL methods for LLMs into three complementary perspectives (data-centric, training-centric, framework-centric) and supplies a taxonomy inside each perspective.
If this is right
- The taxonomy supplies researchers with a structured way to locate gaps and avoid reinventing approaches already covered in one of the three perspectives.
- New methods can be evaluated by showing how they fit or extend the existing categories rather than being described in isolation.
- The framework directly supports the creation of a comprehensive roadmap for scalable RL post-training under data constraints.
Where Pith is reading between the lines
- Hybrid methods that deliberately cross the three perspectives may produce performance gains larger than any single category predicts.
- The same three-perspective lens could be tested on non-RL post-training regimes such as supervised fine-tuning or preference optimization to check whether similar data-scarcity patterns appear.
- Empirical benchmarks that measure data efficiency across the taxonomy categories would allow quantitative validation of which perspective yields the largest gains for given model sizes.
Load-bearing premise
The three perspectives form a complete and non-overlapping partition of all possible design choices for making reinforcement learning data-efficient when applied to large language models.
What would settle it
Identification of a concrete data-efficient RL technique for LLMs whose core mechanism cannot be placed in any one of the three perspectives without forcing substantial overlap or leaving important components unaccounted for.
Figures






read the original abstract
Reinforcement learning (RL) has emerged as a powerful post-training paradigm for enhancing the reasoning capabilities of large language models (LLMs). However, reinforcement learning for LLMs faces substantial data scarcity challenges, including the limited availability of high-quality external supervision and the constrained volume of model-generated experience. These limitations make data-efficient reinforcement learning a critical research direction. In this survey, we present the first systematic review of reinforcement learning for LLMs under data scarcity. We propose a bottom-up hierarchical framework built around three complementary perspectives: the data-centric perspective, the training-centric perspective, and the framework-centric perspective. We develop a taxonomy of existing methods, summarize representative approaches in each category, and analyze their strengths and limitations. Our taxonomy aims to provide a clear conceptual foundation for understanding the design space of data-efficient RL for LLMs and to guide researchers working in this emerging area. We hope this survey offers a comprehensive roadmap for future research and inspires new directions toward more efficient and scalable reinforcement learning post-training for LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey on reinforcement learning for large language models (LLMs) under data scarcity. It claims to deliver the first systematic review of the area and introduces a bottom-up hierarchical framework organized around three complementary perspectives (data-centric, training-centric, and framework-centric). The work develops a taxonomy of existing methods, summarizes representative approaches within each category, analyzes their strengths and limitations, and positions the taxonomy as a conceptual foundation to guide future research in data-efficient RL post-training for LLMs.
Significance. If the taxonomy accurately and usefully organizes the literature, this survey would provide a timely organizational contribution to a rapidly growing intersection of RL and LLMs. The explicit synthesis of challenges and solutions around data scarcity, together with the proposed multi-perspective structure, could help researchers navigate the design space and identify promising directions. The paper's value lies in its coverage and structuring rather than novel derivations or empirical results.
minor comments (2)
- The abstract and introduction should clarify whether the three perspectives are presented as a complete partition of the design space or as one useful (but not necessarily exhaustive) organizational lens; the current wording risks implying completeness without supporting argument or coverage statistics.
- The survey would benefit from an explicit statement of its literature search methodology (databases, keywords, time window, and inclusion criteria) to allow readers to assess the scope and potential omissions.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our survey and for recommending minor revision. The referee's summary correctly identifies the paper's core contribution as the first systematic taxonomy and hierarchical framework for data-efficient RL post-training of LLMs. No specific major comments were raised in the report.
Circularity Check
No significant circularity: survey taxonomy is organizational
full rationale
The paper is a literature review that proposes an organizational taxonomy around three perspectives (data-centric, training-centric, framework-centric) to structure existing RL-for-LLM methods under data scarcity. No mathematical derivations, fitted parameters, self-definitional reductions, or load-bearing self-citations appear; the framework is explicitly presented as a conceptual synthesis of prior work rather than a formally proven or input-derived partition. The central claims reduce to curation and summarization of external literature, which is self-contained against external benchmarks and does not collapse to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning has emerged as a powerful post-training paradigm for enhancing the reasoning capabilities of LLMs
- domain assumption Data scarcity challenges (limited external supervision and constrained model-generated experience) are substantial and make data-efficient RL a critical direction
Reference graph
Works this paper leans on
-
[1]
Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles
Alphamath almost zero: process supervision without process.Advances in Neural Information Processing Systems, 37:27689–27724. Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xuefeng Li, Jiaze Chen, Hao Zhou, and Mingxuan Wang. 2025a. Enigmata: Scaling logical reasoning in large language models with synthetic...
-
[2]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit re- wards.Preprint, arXiv:2502.01456. Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang
work page internal anchor Pith review arXiv
-
[3]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Safe rlhf: Safe reinforcement learning from human feedback.Preprint, arXiv:2310.12773. Muzhi Dai, Chenxu Yang, and Qingyi Si. 2025a. S-grpo: Early exit via reinforcement learning in reasoning models.arXiv preprint arXiv:2505.07686. Runpeng Dai, Linfeng Song, Haolin Liu, Zhenwen Liang, Dian Yu, Haitao Mi, Zhaopeng Tu, Rui Liu, Tong Zheng, Hongtu Zhu, and 1...
work page internal anchor Pith review arXiv 2023
-
[4]
He Du, Bowen Li, Aijun Yang, Siyang He, Qipeng Guo, and Dacheng Tao
Association for Computational Linguistics. He Du, Bowen Li, Aijun Yang, Siyang He, Qipeng Guo, and Dacheng Tao. 2025. Evosyn: Generalizable evolutionary data synthesis for verifiable learning. CoRR, abs/2510.17928. Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. Kto: Model alignment as prospect theoretic optimization....
-
[5]
arXiv preprint arXiv:2504.01296 , year=
Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning.arXiv preprint arXiv:2504.01296. Sam Houliston, Alizée Pace, Alexander Immer, and Gunnar Rätsch. 2024. Uncertainty-penalized direct preference optimization.Preprint, arXiv:2410.20187. Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xi- angyu Zhang, and Heung-Yeung Shum. 2025. Op...
-
[6]
InThe Thirteenth Interna- tional Conference on Learning Representations
Training language models to self-correct via reinforcement learning. InThe Thirteenth Interna- tional Conference on Learning Representations. Zhejian Lai, Xiang Geng, Zhijun Wang, Yang Bai, Ji- ahuan Li, Rongxiang Weng, Jingang Wang, Xuezhi Cao, Xunliang Cai, and Shujian Huang. 2025. Making mathematical reasoning adaptive.CoRR, abs/2510.04617. Tue Le, Ngh...
-
[7]
Spurious rewards: Rethinking training signals in rlvr.arXiv preprint arXiv:2506.10947,
Spurious rewards: Rethinking training signals in rlvr.arXiv preprint arXiv:2506.10947. Qianli Shen, Daoyuan Chen, Yilun Huang, Zhenqing Ling, Yaliang Li, Bolin Ding, and Jingren Zhou. 2025a. BOTS: A unified framework for bayesian online task selection in LLM reinforcement finetun- ing.CoRR, abs/2510.26374. Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, W...
-
[8]
Towards agentic self-learning llms in search environment.arXiv preprint arXiv:2510.14253, 2025
Intrinsic motivation and automatic curricula via asymmetric self-play. InInternational Confer- ence on Learning Representations. Wangtao Sun, Xiang Cheng, Jialin Fan, Yao Xu, Xing Yu, Shizhu He, Jun Zhao, and Kang Liu. 2025a. To- wards agentic self-learning llms in search environ- ment.Preprint, arXiv:2510.14253. Yan Sun, Jia Guo, Stanley Kok, Zihao Wang,...
-
[9]
InInter- national Conference on Machine Learning, pages 49890–49920
Alphazero-like tree-search can guide large language model decoding and training. InInter- national Conference on Machine Learning, pages 49890–49920. PMLR. Huanqian Wang, Yang Yue, Rui Lu, Jingxin Shi, An- drew Zhao, Shenzhi Wang, Shiji Song, and Gao Huang. 2025a. Model surgery: Modulating LLM’s behavior via simple parameter editing. InProceed- ings of th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.