Recognition: unknown
Signal or Noise in Multi-Agent LLM-based Stock Recommendations?
Pith reviewed 2026-05-10 06:13 UTC · model grok-4.3
The pith
Multi-agent LLM equity recommendations generate significant outperformance on S&P 500 stocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
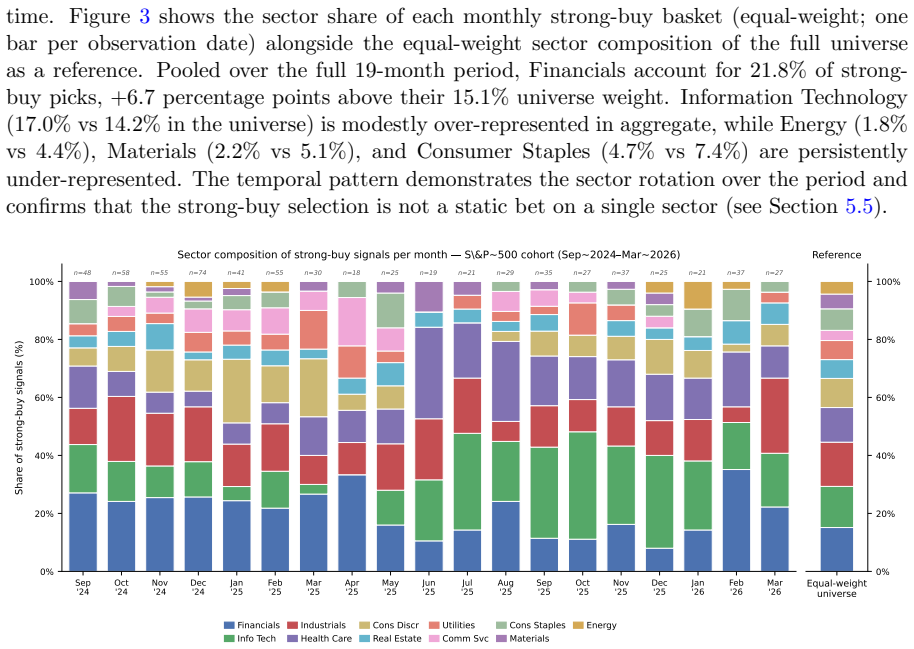
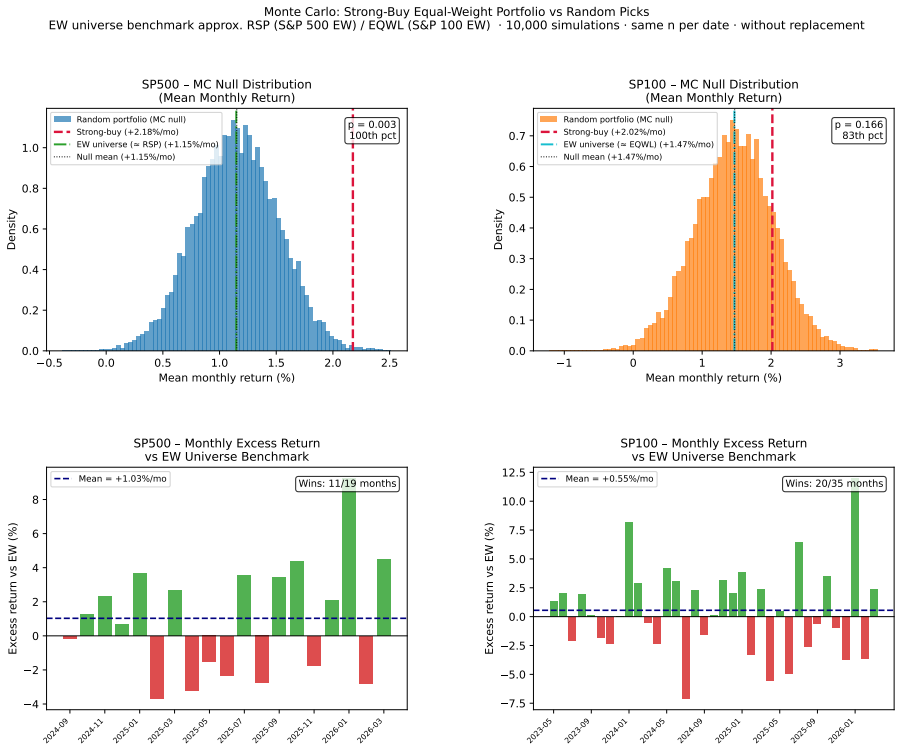
The MarketSenseAI system issues monthly equity theses and recommendations by routing inputs from four specialist agents—News, Fundamentals, Dynamics, and Macro—through a synthesis agent. On the S&P 500 cohort, the equal-weighted portfolio of strong-buy recommendations achieves +2.18%/month returns against +1.15% for the passive equal-weight benchmark, with +25.2% compound excess and p=0.003 against random portfolios. Agent contributions rotate with regimes, as shown by embedding projections, and the recommendation Information Coefficient is +0.489 with p=0.024.
What carries the argument
The adaptive-integration mechanism, where non-negative least-squares projection of thesis embeddings onto agent embeddings reveals rotating dominance among the four specialist agents in response to market conditions.
If this is right
- The buy signal serves as an effective universe-filter that can precede any portfolio construction process.
- Agent contributions adapt to market regimes, with Fundamentals leading on S&P 500 and Macro on S&P 100.
- Dynamics agent acts as an episodic momentum signal.
- The system identifies sources of alpha beyond classical factor models.
- Performance on S&P 100 shows consistent direction but lacks formal significance due to small average selection size.
Where Pith is reading between the lines
- If the regime-adaptive integration generalizes, multi-agent LLM systems could be deployed across varied market environments with dynamic weighting.
- These findings imply that LLM-based recommendations might complement rather than replace traditional quantitative strategies by providing a high-level filter.
- Extending the live validation to longer periods or additional indices would test the durability of the observed outperformance.
- Correlating the agent rotation with specific macro events suggests opportunities for incorporating calendar-based adjustments in similar systems.
Load-bearing premise
That all signals are generated live at each observation date with no look-ahead bias and that the Monte Carlo random portfolios accurately represent the null distribution of no skill under the same selection constraints and universe.
What would settle it
A follow-up live period in which the strong-buy equal-weight portfolio fails to outperform the passive benchmark or the observed agent contribution rotation no longer aligns with market regimes and macro events.
Figures








read the original abstract
We present the first portfolio-level validation of MarketSenseAI, a deployed multi-agent LLM equity system. All signals are generated live at each observation date, eliminating look-ahead bias. The system routes four specialist agents (News, Fundamentals, Dynamics, and Macro) through a synthesis agent that issues a monthly equity thesis and recommendation for each stock in its coverage universe, and we ask two questions: do its buy recommendations add value over both passive benchmarks and random selection, and what does the internal agent structure reveal about the source of the edge? On the S&P 500 cohort (19 months) the strong-buy equal-weight portfolio earns +2.18%/month against a passive equal-weight benchmark of +1.15% (approximating RSP), a +25.2% compound excess, and ranks at the 99.7th percentile of 10,000 Monte Carlo portfolios (p=0.003). The S&P 100 cohort (35 months) delivers a +30.5% compound excess over EQWL with consistent direction but formal significance not reached, limited by the small average selection of ~10 stocks per month. Non-negative least-squares projection of thesis embeddings onto agent embeddings reveals an adaptive-integration mechanism. Agent contributions rotate with market regime (Fundamentals leads on S&P 500, Macro on S&P 100, Dynamics acts as an episodic momentum signal) and this agent rotation moves in lockstep with both the sector composition of strong-buy selections and identifiable macro-calendar events, three independent views of the same underlying adaptation. The recommendation's cross-sectional Information Coefficient is statistically significant on S&P 500 (ICIR=+0.489, p=0.024). These results suggest that multi-agent LLM equity systems can identify sources of alpha beyond what classical factor models capture, and that the buy signal functions as an effective universe-filter that can sit upstream of any portfolio-construction process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first portfolio-level validation of MarketSenseAI, a deployed multi-agent LLM equity recommendation system. All signals are generated live without look-ahead bias. On the S&P 500 cohort over 19 months, the strong-buy equal-weighted portfolio returns +2.18%/month versus +1.15% for a passive equal-weight benchmark, delivering +25.2% compound excess and ranking at the 99.7th percentile of 10,000 Monte Carlo portfolios (p=0.003). The S&P 100 cohort (35 months) shows +30.5% compound excess but does not reach formal significance due to small selection size. Non-negative least-squares analysis of thesis embeddings onto agent embeddings reveals adaptive integration, with agent contributions rotating by market regime and aligning with sector composition and macro events. The cross-sectional ICIR is significant on S&P 500 (ICIR=+0.489, p=0.024). The authors conclude that multi-agent LLM systems can identify alpha beyond classical factors and serve as an effective universe filter.
Significance. If the performance and significance claims hold after verification of the Monte Carlo construction, this would constitute a notable contribution as the first live, portfolio-level test of a multi-agent LLM system in equity markets. Strengths include the explicit use of live signal generation to eliminate look-ahead bias, the multi-cohort design, and the triangulation of results via ICIR, agent-rotation analysis, and sector/macro alignment. These elements provide falsifiable, reproducible evidence that could inform both academic understanding of LLM adaptation and practical deployment of AI-driven signals upstream of portfolio construction.
major comments (1)
- [Monte Carlo simulation and results] The p=0.003 claim for the S&P 500 cohort rests on the strong-buy portfolio ranking at the 99.7th percentile of 10,000 Monte Carlo portfolios. The manuscript must specify (in the Monte Carlo methods subsection) whether each simulation month draws exactly the same number of stocks as the LLM actually selected that month, from the precise live universe at that date (including any liquidity or coverage constraints), and applies identical equal-weighted rebalancing. Any deviation in cardinality, static universe, or independent draws would produce an incorrect null distribution whose tails do not reflect the actual selection process, rendering the percentile and p-value uninterpretable.
minor comments (1)
- [Abstract] The abstract reports performance numbers and p-values but omits the exact average selection size for the S&P 500 cohort and any mention of transaction costs or turnover handling; adding these details would improve interpretability without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The single major comment concerns the documentation of the Monte Carlo null distribution; we address it directly below, confirm the construction used, and commit to expanding the methods section for full transparency and reproducibility.
read point-by-point responses
-
Referee: [Monte Carlo simulation and results] The p=0.003 claim for the S&P 500 cohort rests on the strong-buy portfolio ranking at the 99.7th percentile of 10,000 Monte Carlo portfolios. The manuscript must specify (in the Monte Carlo methods subsection) whether each simulation month draws exactly the same number of stocks as the LLM actually selected that month, from the precise live universe at that date (including any liquidity or coverage constraints), and applies identical equal-weighted rebalancing. Any deviation in cardinality, static universe, or independent draws would produce an incorrect null distribution whose tails do not reflect the actual selection process, rendering the percentile and p-value uninterpretable.
Authors: We agree that the precise construction of the Monte Carlo null must be documented to make the reported percentile and p-value interpretable. The simulations were executed exactly as the referee requires: for each month, we drew exactly the same number of stocks as the live LLM strong-buy selection for that month, sampling without replacement from the precise live universe available on the observation date (including all liquidity filters, coverage constraints, and data-availability restrictions present in the real-time feed). Each simulated portfolio was then equal-weighted and rebalanced on the identical schedule used for the actual strong-buy portfolio. No static universe or independent monthly draws were employed. We will revise the Monte Carlo methods subsection to include an explicit, step-by-step description of this procedure together with pseudocode, thereby eliminating any ambiguity and directly satisfying the referee's request. revision: yes
Circularity Check
No significant circularity; empirical claims rest on live signals and external benchmarks
full rationale
The paper's central results are empirical portfolio performance metrics (strong-buy returns vs. RSP/EQWL benchmarks) and statistical tests (Monte Carlo percentile ranking, ICIR) computed from live-generated signals at each date. These do not reduce by construction to any fitted parameter inside the paper's equations, nor to self-citations. The non-negative least-squares projection onto agent embeddings and the reported agent-rotation observations are independent computations on the same signals but do not tautologically reproduce the performance claim. No uniqueness theorem, ansatz smuggling, or renaming of known results is invoked as load-bearing. The Monte Carlo null is presented as an external randomization procedure; even if its exact cardinality/universe matching is debatable on validity grounds, that is a methodological concern rather than a circular reduction of the reported p-value to the input data by definition. The derivation chain is therefore self-contained against external benchmarks and standard statistical procedures.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Live generation at each observation date eliminates look-ahead bias
- domain assumption Monte Carlo random portfolios form a valid null distribution under identical universe and selection-size constraints
Forward citations
Cited by 1 Pith paper
-
CyberAId: AI-Driven Cybersecurity for Financial Service Providers
CyberAId is a proposed on-premise multi-agent system that coordinates LLM subagents with classical security tools to improve threat response and regulatory alignment in financial services.
Reference graph
Works this paper leans on
-
[1]
Saeed AlMarri, Mathieu Ravaut, Kristof Juhasz, Gautier Marti, Hamdan Al Ahbabi, and Ibrahim Elfadel. Measuring what llms think they do: Shap faithfulness and deployability on financial tabular classification.arXiv preprint arXiv:2512.00163, 2025
-
[2]
Quantum error thresholds for gauge-redundant digitiza- tions of lattice field theories
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Fl´ avio P. Calmon, and Himabindu Lakkaraju. Interpreting CLIP with sparse linear concept embeddings (SpLiCE). InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024. doi: 10.48550/arXiv.2402. 10376. URLhttps://arxiv.org/abs/2402.10376. arXiv:2402.10376
-
[3]
Eugene F. Fama and Kenneth R. French. Common risk factors in the returns on stocks and bonds.Journal of Financial Economics, 33(1):3–56, 1993. ISSN 0304-405X. doi: https://doi.org/10.1016/0304-405X(93)90023-5. URLhttps://www.sciencedirect.com/ science/article/pii/0304405X93900235
-
[4]
Marketsenseai 2.0: Enhancing stock analysis through llm agents
George Fatouros, Kostas Metaxas, John Soldatos, and Manos Karathanassis. Marketsenseai 2.0: Enhancing stock analysis through llm agents. In2025 IEEE International Conference on Data Mining Workshops (ICDMW), pages 883–892, 2025. doi: 10.1109/ICDMW69685. 2025.00105
-
[5]
Can large language models beat wall street? evaluating gpt-4’s impact on financial decision-making with marketsenseai.Neural Computing and Applications, 37(30):24893–24918, 2025
George Fatouros, Kostas Metaxas, John Soldatos, and Dimosthenis Kyriazis. Can large language models beat wall street? evaluating gpt-4’s impact on financial decision-making with marketsenseai.Neural Computing and Applications, 37(30):24893–24918, 2025
2025
-
[6]
Transforming sentiment analysis in the financial domain with chatgpt
Georgios Fatouros, John Soldatos, Kalliopi Kouroumali, Georgios Makridis, and Dimos- thenis Kyriazis. Transforming sentiment analysis in the financial domain with chatgpt. Machine Learning with Applications, 14:100508, 2023
2023
-
[7]
Wenxi Geng, Dingyuan Liu, Liya Li, and Yiqing Wang. Could large language models work as post-hoc explainability tools in credit risk models?arXiv preprint arXiv:2602.18895, 2026
-
[8]
Grinold and Ronald N
Richard C. Grinold and Ronald N. Kahn.Active Portfolio Management: A Quantitative Approach for Producing Superior Returns and Controlling Risk. McGraw-Hill, New York, NY, 2nd edition, 2000
2000
-
[9]
Enhancing investment analysis: Optimizing AI-agent collaboration in financial re- search
Xuewen Han, Neng Wang, Shangkun Che, Hongyang Yang, Kunpeng Zhang, and Sean Xin Xu. Enhancing investment analysis: Optimizing AI-agent collaboration in financial re- search. InProceedings of the ACM International Conference on AI in Finance (ICAIF), 19
-
[10]
URLhttps://arxiv.org/abs/2411.04788
doi: 10.48550/arXiv.2411.04788. URLhttps://arxiv.org/abs/2411.04788. arXiv:2411.04788
-
[11]
Artur Kulpa and Grzegorz Wojarnik. Review of prompt engineering techniques in fi- nance: An evaluation of chain-of-thought, tree-of-thought, and graph-of-thought ap- proaches.SSRN Working Paper 5339795, 2025. doi: 10.2139/ssrn.5339795. URL https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5339795
-
[12]
Xiangyu Li, Yawen Zeng, Xiaofen Xing, and Jin Xu. Profit mirage: Revisiting information leakage in LLM-based financial agents.arXiv preprint arXiv:2510.07920, 2025. doi: 10. 48550/arXiv.2510.07920. URLhttps://arxiv.org/abs/2510.07920
-
[13]
Alejandro Lopez-Lira and Yuehua Tang. Can ChatGPT forecast stock price movements? Return predictability and large language models.arXiv preprint arXiv:2304.07619, 2023. doi: 10.48550/arXiv.2304.07619. URLhttps://arxiv.org/abs/2304.07619
-
[14]
Orr, and Jun Wang
Jose Menchero, D.J. Orr, and Jun Wang. The Barra US equity model (USE4): Methodology notes. Technical report, MSCI Inc., August 2011. URLhttps://www.top1000funds.com/ wp-content/uploads/2011/09/USE4_Methodology_Notes_August_2011.pdf
2011
-
[15]
Kunihiro Miyazaki, Takanobu Kawahara, Stephen Roberts, and Stefan Zohren. Toward expert investment teams: A multi-agent LLM system with fine-grained trading tasks.arXiv preprint arXiv:2602.23330, 2026. doi: 10.48550/arXiv.2602.23330. URLhttps://arxiv. org/abs/2602.23330
-
[16]
Analysis of cross-sectional equity models
Northfield Information Services. Analysis of cross-sectional equity models. Technical re- port, Northfield Information Services, Inc., 2003. URLhttps://www.northinfo.com/ documents/151.pdf
2003
-
[17]
Charidimos Papadakis, Angeliki Dimitriou, Giorgos Filandrianos, Maria Lymperaiou, Kon- stantinos Thomas, and Giorgos Stamou. ATLAS: Adaptive trading with LLM AgentS through dynamic prompt optimization and multi-agent coordination.arXiv preprint arXiv:2510.15949, 2025. doi: 10.48550/arXiv.2510.15949. URLhttps://arxiv.org/abs/ 2510.15949. National Technical...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.15949 2025
-
[18]
Ai in investment analysis: Llms for equity stock ratings
Kassiani Papasotiriou, Srijan Sood, Shayleen Reynolds, and Tucker Balch. Ai in investment analysis: Llms for equity stock ratings. InProceedings of the 5th ACM International Conference on AI in Finance, pages 419–427, 2024
2024
-
[19]
From earnings calls to investment reports: Evaluating role-based multi-agent llm systems
Ranjan Satapathy, Raphael Liew, Joyjit Chattorj, Erik Cambria, and Rick Goh. From earnings calls to investment reports: Evaluating role-based multi-agent llm systems. In Proceedings of The 10th Workshop on Financial Technology and Natural Language Pro- cessing, pages 258–267, 2025
2025
-
[20]
Murtuza N Shergadwala. The stability trap: Evaluating the reliability of llm-based in- struction adherence auditing.arXiv preprint arXiv:2601.11783, 2026
-
[21]
Beyond the black box: Interpretability of LLMs in finance.arXiv preprint arXiv:2505.24650, 2025
Harish Tatsat and Ahmed Shater. Beyond the black box: Interpretability of LLMs in finance.arXiv preprint arXiv:2505.24650, 2025. doi: 10.48550/arXiv.2505.24650. URL https://arxiv.org/abs/2505.24650. Barclays Quantitative Analytics. Also available as SSRN Working Paper 5263803
-
[22]
Diego Vallarino. Adaptive market intelligence: A mixture of experts framework for volatility-sensitive stock forecasting.arXiv preprint arXiv:2508.02686, 2025. doi: 10. 48550/arXiv.2508.02686. URLhttps://arxiv.org/abs/2508.02686. 20
-
[23]
Prompt engineering in consistency and reliability with the evidence-based guideline for llms.NPJ digital medicine, 7(1):41, 2024
Li Wang, Xi Chen, XiangWen Deng, Hao Wen, MingKe You, WeiZhi Liu, Qi Li, and Jian Li. Prompt engineering in consistency and reliability with the evidence-based guideline for llms.NPJ digital medicine, 7(1):41, 2024
2024
-
[26]
Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. FinGPT: Open-source financial large language models. InFinLLM Workshop at IJCAI 2023, 2023. doi: 10.48550/arXiv. 2306.06031. URLhttps://arxiv.org/abs/2306.06031. arXiv:2306.06031
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[27]
Yiyao Zhang, Diksha Goel, Hussain Ahmad, and Claudia Szabo. RegimeFolio: A regime aware ML system for sectoral portfolio optimization in dynamic markets.arXiv preprint arXiv:2510.14986, 2025. doi: 10.48550/arXiv.2510.14986. URLhttps://arxiv.org/abs/ 2510.14986
-
[28]
AlphaAgents: Large language model based multi-agents for equity portfolio constructions,
Tianjiao Zhao, Jingrao Lyu, Stokes Jones, Harrison Garber, Stefano Pasquali, and Dha- gash Mehta. AlphaAgents: Large language model based multi-agents for equity portfolio constructions.arXiv preprint arXiv:2508.11152, 2025. doi: 10.48550/arXiv.2508.11152. URLhttps://arxiv.org/abs/2508.11152. BlackRock, Inc. 21 A Monte Carlo Results by Date Table 8 report...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.