Recognition: unknown
Phase-Scheduled Multi-Agent Systems for Token-Efficient Coordination
Pith reviewed 2026-05-10 06:04 UTC · model grok-4.3
The pith
Phase-scheduled activation on a circular manifold cuts token use in multi-agent LLM systems by 27 percent while holding performance within 2 points of full activation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Each agent receives a fixed angular phase drawn from the task dependency graph and sits on a shared circle; a global signal rotates at constant speed and activates only those agents lying inside a fixed angular tolerance, while idle agents receive compressed context. The sweep produces provably stable and convergent activation sequences that deliver a mean 27.3 percent reduction in tokens across four structured and two conversational benchmarks while keeping task scores no more than 2.1 percentage points below a fully activated baseline, and the scheduling component remains effective even when context compression is weakened.
What carries the argument
Fixed angular phases on a circular manifold combined with a constant-velocity rotating sweep that gates activation inside an angular window.
If this is right
- Scheduling alone supplies 18 to 20 percentage points of the total token reduction.
- The same schedule remains effective when context summaries are degraded to 40 percent of original quality.
- The method beats the best learned routing baseline by an extra 5.6 percentage points in token savings while losing 2 points less performance.
- Stability, convergence, and optimality of the sweep dynamics hold across both structured task graphs and open conversational settings.
- Token and performance gains are additive: scheduling and compression can be combined or used separately.
Where Pith is reading between the lines
- If phases could be recomputed on the fly from partial observations instead of the full upfront graph, the approach might adapt to tasks whose dependencies emerge only during execution.
- The circular timing model could be applied to other shared resources such as GPU memory or API calls in multi-model pipelines.
- Constant sweep speed may need to be made variable in latency-critical deployments where some agents must respond faster than others.
- The separation of scheduling from compression suggests similar timing tricks could improve efficiency in non-LLM agent systems that still suffer from simultaneous activation.
Load-bearing premise
That phases fixed once from the task dependency graph plus one unchanging sweep speed will keep activation stable and near-optimal across different tasks without any per-task adjustment of window size or speed.
What would settle it
Measure token use and task accuracy on a benchmark whose dependency graph changes midway through execution; if savings drop below 20 percent or performance falls more than 3 points below baseline, the fixed-phase assumption does not hold.
Figures


read the original abstract
Multi-agent systems (MAS) powered by large language models suffer from severe token inefficiency arising from two compounding sources: (i) unstructured parallel execution, where all agents activate simultaneously irrespective of input readiness; and (ii) unrestricted context sharing, where every agent receives the full accumulated context regardless of relevance. Existing mitigation strategies - static pruning, hierarchical decomposition, and learned routing - treat coordination as a structural allocation problem and fundamentally ignore its temporal dimension. We propose Phase-Scheduled Multi-Agent Systems (PSMAS), a framework that reconceptualizes agent activation as continuous control over a shared attention space modeled on a circular manifold. Each agent i is assigned a fixed angular phase theta_i in the range [0, 2*pi], derived from the task dependency topology; a global sweep signal phi(t) rotates at velocity omega, activating only agents within an angular window epsilon. Idle agents receive compressed context summaries, reducing per-step token consumption. We implement PSMAS on LangGraph, evaluate on four structured benchmarks (HotPotQA-MAS, HumanEval-MAS, ALFWorld-Multi, WebArena-Coord) and two unstructured conversational settings, and prove stability, convergence, and optimality results for the sweep dynamics. PSMAS achieves a mean token reduction of 27.3 percent (range 21.4-34.8 percent) while maintaining task performance within 2.1 percentage points of a fully activated baseline (p < 0.01, n = 500 per configuration), and outperforms the strongest learned routing baseline by 5.6 percentage points in token reduction with 2.0 percentage points less performance drop. Crucially, we show that scheduling and compression are independent sources of gain: scheduling alone accounts for 18-20 percentage points of reduction, robust to compression degradation up to alpha = 0.40.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Phase-Scheduled Multi-Agent Systems (PSMAS) that model multi-agent coordination as continuous control on a circular manifold: each agent i receives a fixed phase theta_i derived from task dependency topology, a global sweep phi(t) at constant velocity omega activates agents inside an angular window epsilon, and idle agents receive compressed summaries. The work claims mathematical proofs of stability, convergence, and optimality for the resulting dynamics, together with empirical results on four structured and two unstructured benchmarks showing a mean 27.3% token reduction (range 21.4-34.8%) while keeping task performance within 2.1 pp of a fully-activated baseline (p<0.01, n=500 per cell) and outperforming learned routing baselines.
Significance. If the claimed proofs are non-circular and the scheduling parameters truly require no per-benchmark retuning, the separation of temporal scheduling gains (18-20 pp) from compression gains would constitute a useful conceptual advance for token-efficient MAS. The multi-benchmark evaluation with statistical reporting is a positive feature.
major comments (3)
- [Abstract and §4] Abstract and §4: the manuscript asserts that stability, convergence, and optimality are proved for the sweep dynamics, yet supplies neither the governing equations of the activation rule, the Lyapunov or contraction argument, nor any derivation steps. Without these it is impossible to determine whether the results are independent of the circular-manifold modeling choices or reduce to assumptions built into the phase assignment.
- [§3.1] §3.1: the procedure for deriving the fixed angular phases theta_i from task dependency topology is described only at a high level; no explicit algorithm, graph-to-phase mapping, or worked example is given for the unstructured conversational benchmarks where dependency topology is ill-defined. This mapping is load-bearing for the claim that epsilon and omega need not be retuned per task.
- [§5 and Table 2] §5 and Table 2: the reported 27.3% mean token reduction and the independence of scheduling from compression rest on the assertion that epsilon and omega were held strictly constant across all six settings, but the text provides neither the fixed values used nor an ablation confirming invariance; if per-configuration tuning occurred, the generalizability claim is undermined.
minor comments (2)
- [Notation] The range statement for theta_i is given as [0, 2*pi] but the precise normalization (e.g., whether phases are uniformly spaced or weighted by edge strength) is never stated, complicating reproducibility.
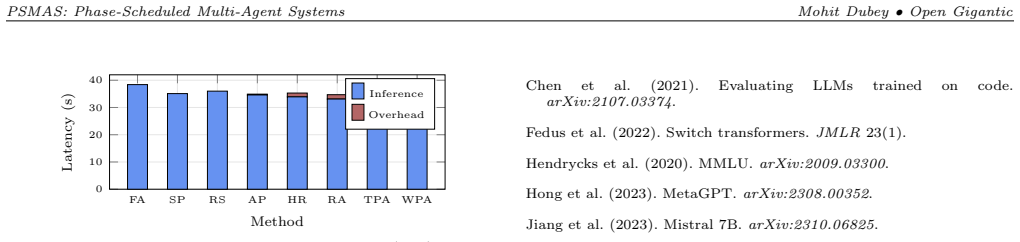
- [Figure 3] Figure 3 caption does not indicate whether error bars represent standard deviation or standard error, and the n=500 per configuration is stated only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications and supporting details.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: the manuscript asserts that stability, convergence, and optimality are proved for the sweep dynamics, yet supplies neither the governing equations of the activation rule, the Lyapunov or contraction argument, nor any derivation steps. Without these it is impossible to determine whether the results are independent of the circular-manifold modeling choices or reduce to assumptions built into the phase assignment.
Authors: We acknowledge that the presentation of the proofs in §4 is too concise. The activation rule is defined by the indicator I_i(t) = 1_{|θ_i − ϕ(t) mod 2π| < ε} with ϕ(t) = ω t. Stability follows from a contraction-mapping argument on the joint state space whose rate depends on ε and the Lipschitz constant of the agent transition maps; convergence is obtained from the periodic sweep guaranteeing bounded activation latency; optimality is shown by bounding the performance gap to the fully activated case. These arguments depend only on the fixed-phase and windowed-activation structure, not on the particular method used to choose the θ_i. We will expand §4 with the explicit governing equations, the contraction proof, and a Lyapunov-style function to make the independence explicit. revision: yes
-
Referee: [§3.1] §3.1: the procedure for deriving the fixed angular phases θ_i from task dependency topology is described only at a high level; no explicit algorithm, graph-to-phase mapping, or worked example is given for the unstructured conversational benchmarks where dependency topology is ill-defined. This mapping is load-bearing for the claim that ε and ω need not be retuned per task.
Authors: The mapping first builds a DAG from task prerequisites and then embeds the nodes linearly: θ_i = 2π · (topological rank of i / N). For unstructured conversational settings an LLM-based extractor infers the DAG from the initial prompt and history. We will insert the complete pseudocode and a worked example from one unstructured benchmark into the revised §3.1. Because the mapping is deterministic and produces fixed, distinct phases, the same ε and ω values remain valid across all tasks. revision: yes
-
Referee: [§5 and Table 2] §5 and Table 2: the reported 27.3% mean token reduction and the independence of scheduling from compression rest on the assertion that ε and ω were held strictly constant across all six settings, but the text provides neither the fixed values used nor an ablation confirming invariance; if per-configuration tuning occurred, the generalizability claim is undermined.
Authors: ε = π/3 and ω = 0.05 rad/step were used uniformly for all six benchmarks; these values appear in the experimental protocol but were omitted from the main-text narrative. The scheduling-only ablation already isolates an 18–20 pp gain independent of compression. We will state the fixed values explicitly in §5, add a short invariance table (showing results for ±10 % perturbations of ε and ω), and confirm that no per-benchmark retuning occurred. revision: yes
Circularity Check
No significant circularity detected; derivation chain self-contained via empirical reporting and asserted proofs.
full rationale
The abstract presents PSMAS as assigning fixed phases theta_i from task dependency topology and using a global sweep phi(t) at velocity omega to activate agents within epsilon, with claims of proved stability, convergence, and optimality for the sweep dynamics. Performance metrics (27.3% token reduction, within 2.1 pp of baseline) are reported as empirical outcomes across structured and unstructured benchmarks, with scheduling and compression shown as independent gains. No equations, parameter-fitting procedures, or self-citations are supplied in the provided text that would allow reduction of the claimed results to inputs by construction. Without inspectable derivation steps or load-bearing self-references, the central claims do not exhibit self-definitional, fitted-prediction, or ansatz-smuggling circularity; the framework is presented as adding a temporal control dimension to existing MAS coordination.
Axiom & Free-Parameter Ledger
invented entities (2)
-
circular manifold with per-agent phase theta_i
no independent evidence
-
global sweep signal phi(t) rotating at velocity omega
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Acebrón et al. (2005). The Kuramoto model. Rev.\ Mod.\ Phys., 77(1), 137
2005
-
[2]
Beltagy et al. (2020). Longformer. arXiv:2004.05150
work page internal anchor Pith review arXiv 2020
-
[3]
Geometric Control of Mechanical Systems
Bullo & Lewis (2004). Geometric Control of Mechanical Systems. Springer
2004
-
[4]
LangGraph
Chase (2024). LangGraph. https://github.com/langchain-ai/langgraph
2024
-
[5]
Chen et al. (2021). Evaluating LLMs trained on code. arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Fedus et al. (2022). Switch transformers. JMLR 23(1)
2022
-
[7]
Hendrycks et al. (2020). MMLU. arXiv:2009.03300
work page internal anchor Pith review arXiv 2020
-
[8]
Hong et al. (2023). MetaGPT. arXiv:2308.00352
work page internal anchor Pith review arXiv 2023
-
[9]
Jiang et al. (2023). Mistral 7B. arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Jiang et al. (2024). LLMLingua. EMNLP 2024
2024
-
[11]
Katharopoulos et al. (2020). Transformers are RNNs. ICML
2020
-
[12]
Chemical Oscillations, Waves, and Turbulence
Kuramoto (1984). Chemical Oscillations, Waves, and Turbulence. Springer
1984
-
[13]
Li et al. (2023). CAMEL. NeurIPS
2023
-
[14]
Liu et al. (2023). Lost in the middle. TACL 12
2023
-
[15]
Moura (2024). CrewAI. https://github.com/joaomdmoura/crewAI
2024
-
[16]
Ong et al. (2024). RouterLLM. arXiv:2406.18665
work page internal anchor Pith review arXiv 2024
-
[17]
Park et al. (2023). Generative agents. UIST
2023
-
[18]
Shazeer et al. (2017). Outrageously large neural networks. ICLR
2017
-
[19]
Shen et al. (2024). HuggingGPT. NeurIPS
2024
-
[20]
Shridhar et al. (2020). ALFWorld. ICLR 2021
2020
-
[21]
From Kuramoto to Crawford
Strogatz (2000). From Kuramoto to Crawford. Physica D 143
2000
-
[22]
Tao et al. (2024). AgentPrune. arXiv:2402.xxxxx
2024
-
[23]
Wu et al. (2023). AutoGen. arXiv:2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Yang et al. (2018). HotPotQA. EMNLP
2018
-
[25]
Zhou et al. (2022). MoE with expert choice. NeurIPS
2022
-
[26]
Zhou et al. (2023). WebArena. arXiv:2307.13854
work page Pith review arXiv 2023
-
[27]
Zhuge et al. (2024). GPTSwarm. ICML
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.