Recognition: unknown
Where to Focus: Query-Modulated Multimodal Keyframe Selection for Long Video Understanding
Pith reviewed 2026-05-10 06:02 UTC · model grok-4.3
The pith
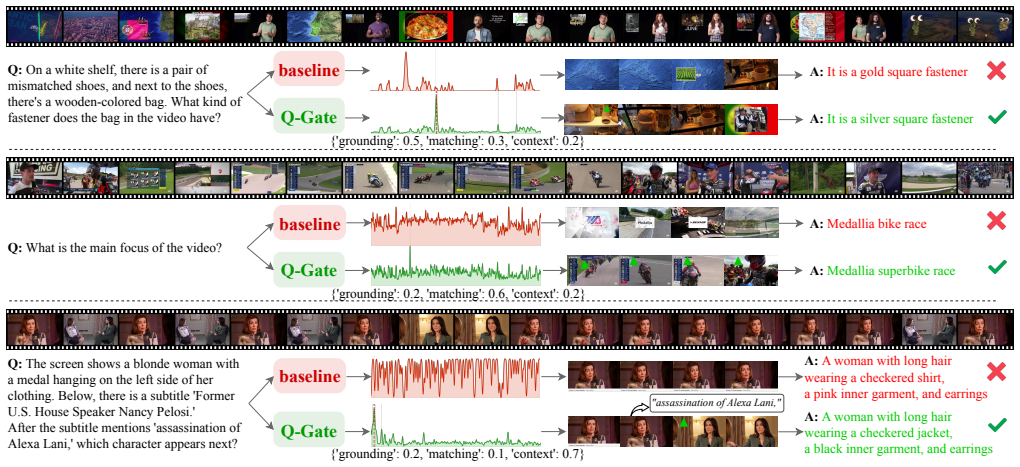
Q-Gate uses an LLM to dynamically weight visual and textual expert streams for selecting keyframes in long videos based on the query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Q-Gate treats keyframe selection as a dynamic modality routing problem by decoupling the retrieval into three lightweight expert streams—Visual Grounding for local details, Global Matching for scene semantics, and Contextual Alignment for subtitle-driven narratives—and introduces a Query-Modulated Gating Mechanism that leverages the in-context reasoning of an LLM to assess the query's intent and dynamically allocate attention weights across the experts, thereby suppressing modality-specific noise.
What carries the argument
The Query-Modulated Gating Mechanism, which uses LLM in-context reasoning to dynamically allocate attention weights to three expert streams: Visual Grounding, Global Matching, and Contextual Alignment.
If this is right
- Q-Gate outperforms state-of-the-art baselines on LongVideoBench and Video-MME across multiple MLLM backbones.
- The approach is training-free and plug-and-play for existing models.
- It suppresses modality-specific noise by muting irrelevant expert streams.
- Keyframe selection becomes adaptive to query type rather than using a single fixed metric.
Where Pith is reading between the lines
- Similar dynamic routing could reduce noise in other long-context multimodal tasks like audio or document understanding.
- The reliance on LLM reasoning for gating suggests potential speed gains if a smaller model or learned router replaces the full LLM call.
- This framing implies that query intent detection is a general lever for efficient multimodal compression.
Load-bearing premise
The in-context reasoning of an LLM can reliably assess the query's intent and dynamically allocate attention weights across the three expert streams without introducing errors or modal noise.
What would settle it
A set of purely visual queries where Q-Gate assigns high weight to the textual stream and underperforms a visual-only baseline on LongVideoBench.
Figures





read the original abstract
Long video understanding remains a formidable challenge for Multimodal Large Language Models (MLLMs) due to the prohibitive computational cost of processing dense frame sequences. Prevailing solutions, which select a keyframe subset, typically rely on either a single visual-centric metric (e.g., CLIP similarity) or a static fusion of heuristic scores. This ``one-size-fits-all'' paradigm frequently fails: visual-only metrics are ineffective for plot-driven narrative queries, while indiscriminately incorporating textual scores introduces severe ``modal noise'' for purely visual tasks. To break this bottleneck, we propose Q-Gate, a plug-and-play and training-free framework that treats keyframe selection as a dynamic modality routing problem. We decouple the retrieval process into three lightweight expert streams: Visual Grounding for local details, Global Matching for scene semantics, and Contextual Alignment for subtitle-driven narratives. Crucially, Q-Gate introduces a Query-Modulated Gating Mechanism that leverages the in-context reasoning of an LLM to assess the query's intent and dynamically allocate attention weights across the experts. This mechanism intelligently activates necessary modalities while ``muting'' irrelevant ones, thereby maximizing the signal-to-noise ratio. Extensive experiments on LongVideoBench and Video-MME across multiple MLLM backbones demonstrate that Q-Gate substantially outperforms state-of-the-art baselines. By effectively suppressing modality-specific noise, it provides a robust, highly interpretable solution for scalable video reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Q-Gate, a plug-and-play, training-free framework for keyframe selection in long-video understanding with MLLMs. It decomposes retrieval into three expert streams (Visual Grounding, Global Matching, Contextual Alignment) and introduces a Query-Modulated Gating Mechanism that uses an LLM's in-context reasoning to dynamically weight the streams according to query intent, with the goal of suppressing modality-specific noise. The central claim is that this approach substantially outperforms prior state-of-the-art keyframe selection methods on LongVideoBench and Video-MME across multiple MLLM backbones.
Significance. If the performance gains are shown to arise specifically from the dynamic, query-aware gating rather than from simply ensembling three parallel experts, the work would offer a practical, interpretable advance for scalable long-video reasoning. The training-free and plug-and-play design would make it immediately usable with existing MLLMs, addressing a clear efficiency bottleneck.
major comments (3)
- [Experiments] Experiments section: the manuscript asserts substantial outperformance on LongVideoBench and Video-MME but supplies no quantitative tables, per-query results, error bars, or statistical significance tests, preventing verification of the headline claim.
- [Method] Method section (Q-Gate description): the gating mechanism is presented only qualitatively with no equations for weight computation, no prompt templates for the LLM in-context reasoning, and no implementation details on how modality weights are normalized or applied, rendering the framework non-reproducible.
- [Ablations / Experiments] Ablation studies: no experiments replace the LLM gate with uniform averaging or static fusion of the three experts, so it is impossible to confirm that observed gains derive from modality-noise suppression rather than from the mere presence of multiple streams.
minor comments (2)
- [Introduction] The abstract and introduction repeatedly use the term 'modal noise' without a precise definition or quantitative measure of what constitutes noise versus signal in each expert stream.
- [Figures] Figure captions and method diagrams lack labels for the three expert streams and the gating module, reducing clarity for readers attempting to follow the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our submission. The comments identify key areas where additional rigor, clarity, and evidence are needed. We address each major comment point by point below and outline the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript asserts substantial outperformance on LongVideoBench and Video-MME but supplies no quantitative tables, per-query results, error bars, or statistical significance tests, preventing verification of the headline claim.
Authors: We acknowledge this shortcoming in the submitted version. Although the text describes the performance gains, the detailed quantitative tables, error bars, and significance tests were omitted during formatting. In the revised manuscript we will add comprehensive result tables for both LongVideoBench and Video-MME across all tested MLLM backbones, include standard-error bars from repeated runs, report paired statistical significance tests, and move per-query breakdowns to the supplementary material so that the headline claims can be fully verified. revision: yes
-
Referee: [Method] Method section (Q-Gate description): the gating mechanism is presented only qualitatively with no equations for weight computation, no prompt templates for the LLM in-context reasoning, and no implementation details on how modality weights are normalized or applied, rendering the framework non-reproducible.
Authors: The referee is correct that the current description lacks the necessary formalization and implementation details. We will revise the Method section to include (1) the exact equations for computing the query-modulated weights from the LLM's in-context output, (2) the full prompt templates used for intent assessment, and (3) the normalization procedure (softmax over the three expert scores) together with pseudocode for applying the weights. These additions will make the entire Q-Gate framework reproducible. revision: yes
-
Referee: [Ablations / Experiments] Ablation studies: no experiments replace the LLM gate with uniform averaging or static fusion of the three experts, so it is impossible to confirm that observed gains derive from modality-noise suppression rather than from the mere presence of multiple streams.
Authors: We agree that this ablation is essential to isolate the contribution of the dynamic, query-aware gating. In the revised paper we will add a dedicated ablation table that compares the full Q-Gate against two controlled variants: (a) uniform averaging of the three expert scores and (b) static (non-query-dependent) fusion weights. Performance differences on LongVideoBench and Video-MME will be reported to demonstrate that the observed improvements stem specifically from the LLM-driven modality routing rather than from ensembling alone. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces Q-Gate as a training-free, plug-and-play framework that decouples keyframe selection into three expert streams and uses LLM in-context reasoning for dynamic gating. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided text or abstract. The central claims rest on empirical results from external benchmarks (LongVideoBench, Video-MME) rather than any reduction to the method's own inputs by construction. The approach is self-contained and independent of the patterns that would trigger circularity flags.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM can assess query intent via in-context reasoning to allocate weights across visual, global, and contextual experts
invented entities (1)
-
Q-Gate framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evlampios Apostolidis, Eleni Adamantidou, Alexandros I Metsai, Vasileios Mezaris, and Ioannis Patras. 2021. Video summarization using deep neural networks: A survey.Proc. IEEE109, 11 (2021), 1838–1863
2021
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond2, 1 (2023), 1
2023
-
[3]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long- document transformer.arXiv preprint arXiv:2004.05150(2020)
work page internal anchor Pith review arXiv 2020
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Jieneng Chen, Luoxin Ye, Ju He, Zhao-Yang Wang, Daniel Khashabi, and Alan Yuille. 2024. Efficient large multi-modal models via visual context compression. Advances in neural information processing systems37 (2024), 73986–74007
2024
- [6]
-
[7]
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. 2024. Yolo-world: Real-time open-vocabulary object detection. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16901–16911
2024
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[9]
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. 2024. Videoagent: A memory-augmented multimodal agent for video understanding. InEuropean Conference on Computer Vision. Springer, 75–92
2024
-
[10]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2025. Video- mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24108–24118
2025
-
[11]
Boqing Gong, Wei-Lun Chao, Kristen Grauman, and Fei Sha. 2014. Diverse sequential subset selection for supervised video summarization.Advances in neural information processing systems27 (2014)
2014
- [12]
-
[13]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895(2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[16]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. 2024. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22195–22206
2024
-
[17]
Linjie Li, Yen-Chun Chen, Yu Cheng, Zhe Gan, Licheng Yu, and Jingjing Liu
-
[18]
InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Hero: Hierarchical encoder for video+ language omni-representation pre- training. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 2046–2065
2020
-
[19]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-llava: Learning united visual representation by alignment before pro- jection. InProceedings of the 2024 conference on empirical methods in natural language processing. 5971–5984
2024
-
[20]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[21]
Hao Liu, Matei Zaharia, and Pieter Abbeel. 2023. Ring attention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889(2023)
work page internal anchor Pith review arXiv 2023
- [22]
-
[23]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[24]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[25]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[26]
Dingjie Song, Wenjun Wang, Shunian Chen, Xidong Wang, Michael X Guan, and Benyou Wang. 2025. Less is more: A simple yet effective token reduction method for efficient multi-modal llms. InProceedings of the 31st International Conference on Computational Linguistics. 7614–7623
2025
-
[27]
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al . 2024. Moviechat: From dense token to sparse memory for long video understand- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18221–18232
2024
-
[28]
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. 2025. Adaptive keyframe sampling for long video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference. 29118–29128
2025
-
[29]
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. 2025. Video understanding with large language models: A survey.IEEE Transactions on Circuits and Systems for Video Technology(2025)
2025
-
[30]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv 2023.arXiv preprint arXiv:2302.1397110 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Shaoguang Wang, Weiyu Guo, Ziyang Chen, Yijie Xu, Xuming Hu, and Hui Xiong
-
[32]
Less is More: Token-Efficient Video-QA via Adaptive Frame-Pruning and Semantic Graph Integration.arXiv preprint arXiv:2508.03337(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Wenhai Wang, Zhe Chen, Yangzhou Liu, Yue Cao, Weiyun Wang, Xizhou Zhu, Lewei Lu, Tong Lu, Yu Qiao, and Jifeng Dai. 2025. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. InLarge Vision-Language Models: Pre-training, Prompting, and Applications. Springer, 23– 57
2025
-
[34]
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. 2024. Videoa- gent: Long-form video understanding with large language model as agent. In European Conference on Computer Vision. Springer, 58–76
2024
-
[35]
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. 2025. Videotree: Adaptive tree-based video representation for llm reasoning on long videos. InProceedings of the Computer Vision and Pattern Recognition Conference. 3272–3283
2025
-
[36]
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang
-
[37]
In European Conference on Computer Vision
Longvlm: Efficient long video understanding via large language models. In European Conference on Computer Vision. Springer, 453–470
-
[38]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. Longvideobench: A benchmark for long-context interleaved video-language understanding.Ad- vances in Neural Information Processing Systems37 (2024), 28828–28857
2024
-
[39]
Jiaqi Xu, Cuiling Lan, Wenxuan Xie, Xuejin Chen, and Yan Lu. 2023. Retrieval- based video language model for efficient long video question answering. (2023)
2023
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. 2025. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference. 10632–10643
2025
-
[42]
Jinhui Ye, Zihan Wang, Haosen Sun, Keshigeyan Chandrasegaran, Zane Du- rante, Cristobal Eyzaguirre, Yonatan Bisk, Juan Carlos Niebles, Ehsan Adeli, Li Fei-Fei, et al. 2025. Re-thinking temporal search for long-form video understand- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8579–8591
2025
- [43]
-
[44]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-llama: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations. 543–553
2023
-
[45]
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. 2025. Q- frame: Query-aware frame selection and multi-resolution adaptation for video- llms. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22056–22065
2025
-
[46]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. 2025. Mlvu: Benchmarking multi- task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13691–13701
2025
- [47]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.