Recognition: unknown
Attention Is not Everything: Efficient Alternatives for Vision
Pith reviewed 2026-05-10 05:43 UTC · model grok-4.3
The pith
Many non-Transformer methods remain direct competitors to attention-based models in computer vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
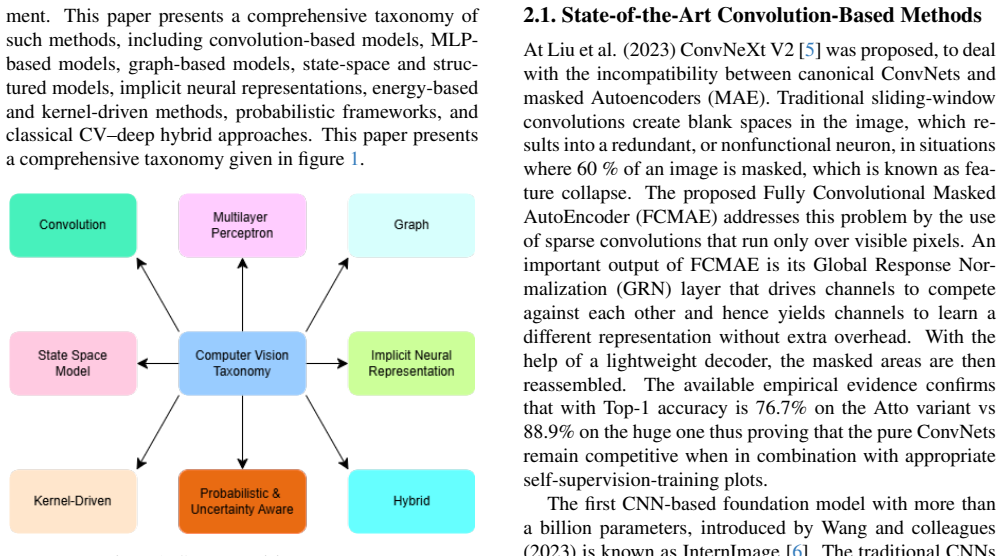
Organizing non-Transformer vision models into a taxonomy of convolution-based, MLP-based, state-space-based and related categories, then assessing 40 representative papers on efficiency, scalability, interpretability and robustness, shows that these alternatives function as viable direct competition to Transformer-based models while exposing specific challenges and opportunities for future computer vision research.
What carries the argument
A taxonomy that groups non-Transformer vision architectures by type and compares them systematically on efficiency, scaling, understandability, and robustness.
If this is right
- Developers can select non-Transformer models for tasks where lower compute or better interpretability matters without large performance loss.
- The taxonomy supplies a reference point for designing new models that target identified weaknesses in scaling or robustness.
- Research efforts can prioritize hybrid constructions that borrow strengths across the listed categories.
- Future comparisons can use the same four evaluation axes to track progress outside the Transformer paradigm.
Where Pith is reading between the lines
- Wider adoption of these methods could lower barriers for vision models on resource-constrained hardware.
- The taxonomy may help surface under-explored combinations that improve robustness without added attention layers.
- Extending the categories to include recent hybrid proposals would test whether the current grouping remains stable.
- Standardized reporting of all four metrics across new papers would make future updates to the taxonomy more reliable.
Load-bearing premise
The 40 chosen papers form a representative sample that supports a comprehensive taxonomy and fair comparisons across the four evaluation dimensions.
What would settle it
A new benchmark that tests all taxonomy categories against current Transformer models on standard vision datasets and finds consistent underperformance on every metric of efficiency, accuracy, scaling, and robustness would falsify the claim of direct competition.
Figures
read the original abstract
Recently computer vision has seen advancements mainly thanks to Transformer-based models. However many non-Transformer methods are still doing well being a direct competition of Transformer-based models. This review tries to present a comprehensive taxonomy of such methods and organize these methods into categories like convolution-based models, MLP-based models, state-space-based and more. These methods are looked at in terms of how efficient they are, how well they scale, how easy they are to understand and how robust they are. A total of 40 papers were chosen for this study. The goal is to give a view of non-Transformer methods and find out what challenges and opportunities exist for future computer vision research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that non-Transformer methods remain competitive with attention-based models in computer vision and presents a taxonomy organizing 40 selected papers into categories such as convolution-based, MLP-based, and state-space-based models. These are evaluated along axes of efficiency, scaling behavior, understandability, and robustness, with the goal of identifying challenges and opportunities for future research.
Significance. If the curation proves representative and the taxonomy is systematically constructed, the survey could serve as a useful reference for researchers seeking efficient vision architectures that avoid quadratic attention costs, potentially accelerating work on alternatives that match or exceed Transformer performance on specific metrics.
major comments (1)
- [Abstract] Abstract: the claim of a 'comprehensive taxonomy' of non-Transformer methods rests on the selection of exactly 40 papers, yet no search protocol, inclusion/exclusion criteria, or justification for representativeness is stated. Without this, the taxonomy cannot be assessed for coverage or bias, undermining the central contribution of organizing the field.
minor comments (1)
- The abstract states that methods are examined 'in terms of how efficient they are, how well they scale, how easy they are to understand and how robust they are,' but provides no indication of the specific quantitative metrics, benchmarks, or comparison tables used; this should be clarified with explicit references to later sections.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our survey. The concern about transparency in paper selection is valid and will be addressed directly to improve the manuscript's rigor and usefulness as a reference.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'comprehensive taxonomy' of non-Transformer methods rests on the selection of exactly 40 papers, yet no search protocol, inclusion/exclusion criteria, or justification for representativeness is stated. Without this, the taxonomy cannot be assessed for coverage or bias, undermining the central contribution of organizing the field.
Authors: We agree that the current abstract and introduction lack explicit details on the literature selection process, which weakens the claim of a comprehensive taxonomy. We will revise the manuscript by adding a dedicated 'Methodology' subsection (likely in Section 2 or as a new Section 3) that describes: (1) search strategy using keywords such as 'non-Transformer vision', 'efficient alternatives to attention', 'MLP vision models', 'state-space models for vision', and 'convolutional alternatives to Transformers' across arXiv, Google Scholar, and major venues (CVPR, ICCV, ECCV, NeurIPS, ICLR) from 2018 onward; (2) inclusion criteria focusing on papers proposing novel architectures with empirical results on standard vision benchmarks (ImageNet, COCO, etc.) that demonstrate competitive efficiency or performance; (3) exclusion criteria for purely theoretical works, incremental improvements without new architectural insights, or non-vision applications; and (4) a brief discussion of representativeness, acknowledging that the 40 papers prioritize influential and diverse examples across categories rather than exhaustive coverage. We will also note limitations such as potential recency bias and the subjective nature of 'key' contributions. This addition will allow readers to evaluate coverage and bias while preserving the taxonomy's organizational value. The abstract will be updated to reference this methodology instead of claiming comprehensiveness outright. revision: yes
Circularity Check
No significant circularity: literature survey with no derivations or fitted claims
full rationale
This manuscript is a review paper that curates and taxonomizes 40 existing non-Transformer vision models into categories (convolution-based, MLP-based, state-space, etc.) and discusses their efficiency, scaling, understandability, and robustness. No original equations, predictions, scaling laws, or parameter fits are asserted; every statement reduces to summaries or comparisons of prior published work. The taxonomy itself is an organizational construct supplied by the authors rather than a derived result that could loop back to the paper's own inputs. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing premises. The central contribution is therefore self-contained curation and does not reduce to any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 1
2017
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Training data-efficient image transformers & distillation through at- tention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv´e J´egou. Training data-efficient image transformers & distillation through at- tention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021. 1
2021
-
[4]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 1
2021
-
[5]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Fe- ichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976– 11986, 2022. 2, 3
2022
-
[6]
Internimage: Exploring large-scale vi- sion foundation models with deformable convolutions
Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, et al. Internimage: Exploring large-scale vi- sion foundation models with deformable convolutions. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14408–14419, 2023. 2, 3
2023
-
[7]
Unireplknet: A uni- versal perception large-kernel convnet for audio video point cloud time-series and image recognition
Xiaohan Ding, Yiyuan Zhang, Yixiao Ge, Sijie Zhao, Lin Song, Xiangyu Yue, and Ying Shan. Unireplknet: A uni- versal perception large-kernel convnet for audio video point cloud time-series and image recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5513–5524, 2024. 2, 3
2024
-
[8]
Inceptionnext: When inception meets convnext
Weihao Yu, Pan Zhou, Shuicheng Yan, and Xinchao Wang. Inceptionnext: When inception meets convnext. InPro- ceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 5672–5683, 2024. 3
2024
-
[9]
Repvit: Revisiting mobile cnn from vit perspective
Ao Wang, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Repvit: Revisiting mobile cnn from vit perspective. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15909–15920, 2024. 3
2024
-
[10]
Imagenet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical im- age database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 2, 5, 13
2009
-
[11]
Semantic un- derstanding of scenes through the ade20k dataset.Interna- tional journal of computer vision, 127(3):302–321, 2019
Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fi- dler, Adela Barriuso, and Antonio Torralba. Semantic un- derstanding of scenes through the ade20k dataset.Interna- tional journal of computer vision, 127(3):302–321, 2019. 2, 3
2019
-
[12]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Pete Warden. Speech commands: A dataset for limited-vocabulary speech recognition.arXiv preprint arXiv:1804.03209, 2018. 3
work page Pith review arXiv 2018
-
[13]
Aloft: A lightweight mlp-like architecture with dynamic low- frequency transform for domain generalization
Jintao Guo, Na Wang, Lei Qi, and Yinghuan Shi. Aloft: A lightweight mlp-like architecture with dynamic low- frequency transform for domain generalization. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24132–24141, 2023. 4
2023
-
[14]
Strip-mlp: Efficient token interaction for vision mlp
Guiping Cao, Shengda Luo, Wenjian Huang, Xiangyuan Lan, Dongmei Jiang, Yaowei Wang, and Jianguo Zhang. Strip-mlp: Efficient token interaction for vision mlp. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1494–1504, 2023. 4
2023
-
[15]
Dy- namic mlp for fine-grained image classification by leverag- ing geographical and temporal information
Lingfeng Yang, Xiang Li, Renjie Song, Borui Zhao, Jun- tian Tao, Shihao Zhou, Jiajun Liang, and Jian Yang. Dy- namic mlp for fine-grained image classification by leverag- ing geographical and temporal information. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 10945–10954, 2022. 4, 5
2022
-
[16]
Correlation-aware coarse-to-fine mlps for deformable med- ical image registration
Mingyuan Meng, Dagan Feng, Lei Bi, and Jinman Kim. Correlation-aware coarse-to-fine mlps for deformable med- ical image registration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9645–9654, 2024. 4, 5
2024
-
[17]
Rivuletmlp: An mlp-based architecture for efficient compressed video quality enhance- ment
Gang He, Weiran Wang, Guancheng Quan, Shihao Wang, Dajiang Zhou, and Yunsong Li. Rivuletmlp: An mlp-based architecture for efficient compressed video quality enhance- ment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7342–7352, 2025. 4, 5
2025
-
[18]
Deeper, broader and artier domain generaliza- tion
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. Deeper, broader and artier domain generaliza- tion. InProceedings of the IEEE international conference on computer vision, pages 5542–5550, 2017. 4
2017
-
[19]
One-shot learning of object categories.IEEE transactions on pattern analysis and machine intelligence, 28(4):594–611, 2006
Li Fei-Fei, Robert Fergus, and Pietro Perona. One-shot learning of object categories.IEEE transactions on pattern analysis and machine intelligence, 28(4):594–611, 2006. 5
2006
-
[20]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 5, 13
2009
-
[21]
Benchmarking rep- resentation learning for natural world image collections
Grant Van Horn, Elijah Cole, Sara Beery, Kimberly Wilber, Serge Belongie, and Oisin Mac Aodha. Benchmarking rep- resentation learning for natural world image collections. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 12884–12893, 2021. 5
2021
-
[22]
Mfqe 2.0: A new approach for multi- frame quality enhancement on compressed video.IEEE transactions on pattern analysis and machine intelligence, 43(3):949–963, 2019
Zhenyu Guan, Qunliang Xing, Mai Xu, Ren Yang, Tie Liu, and Zulin Wang. Mfqe 2.0: A new approach for multi- frame quality enhancement on compressed video.IEEE transactions on pattern analysis and machine intelligence, 43(3):949–963, 2019. 5
2019
-
[23]
Vision gnn: An image is worth graph of nodes.Ad- vances in neural information processing systems, 35:8291– 8303, 2022
Kai Han, Yunhe Wang, Jianyuan Guo, Yehui Tang, and En- hua Wu. Vision gnn: An image is worth graph of nodes.Ad- vances in neural information processing systems, 35:8291– 8303, 2022. 5
2022
-
[24]
Vision hgnn: An image is more than a graph of nodes
Yan Han, Peihao Wang, Souvik Kundu, Ying Ding, and Zhangyang Wang. Vision hgnn: An image is more than a graph of nodes. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 19878– 19888, 2023. 5, 6
2023
-
[25]
Greedyvig: Dynamic axial graph construction for efficient vision gnns
Mustafa Munir, William Avery, Md Mostafijur Rahman, and Radu Marculescu. Greedyvig: Dynamic axial graph construction for efficient vision gnns. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6118–6127, 2024. 5, 6
2024
-
[26]
Image processing gnn: Breaking rigidity in super- resolution
Yuchuan Tian, Hanting Chen, Chao Xu, and Yunhe Wang. Image processing gnn: Breaking rigidity in super- resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108– 24117, 2024. 6
2024
-
[27]
Improving graph representation for point cloud segmenta- tion via attentive filtering
Nan Zhang, Zhiyi Pan, Thomas H Li, Wei Gao, and Ge Li. Improving graph representation for point cloud segmenta- tion via attentive filtering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1244–1254, 2023. 6
2023
-
[28]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 5, 14
2014
-
[29]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 126–135, 2017. 6
2017
-
[30]
Single image super-resolution from transformed self- exemplars
Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self- exemplars. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5197–5206,
-
[31]
3d seman- tic parsing of large-scale indoor spaces
Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 3d seman- tic parsing of large-scale indoor spaces. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1534–1543, 2016. 7
2016
-
[32]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 7
2017
-
[33]
Toronto-3d: A large-scale mobile lidar dataset for semantic segmentation of urban roadways
Weikai Tan, Nannan Qin, Lingfei Ma, Ying Li, Jing Du, Guorong Cai, Ke Yang, and Jonathan Li. Toronto-3d: A large-scale mobile lidar dataset for semantic segmentation of urban roadways. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition work- shops, pages 202–203, 2020. 7
2020
-
[34]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015. 7
work page internal anchor Pith review arXiv 2015
-
[35]
Combining recur- rent, convolutional, and continuous-time models with linear state space layers.Advances in neural information process- ing systems, 34:572–585, 2021
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher R ´e. Combining recur- rent, convolutional, and continuous-time models with linear state space layers.Advances in neural information process- ing systems, 34:572–585, 2021. 7
2021
-
[36]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher R ´e. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2021. 7
work page internal anchor Pith review arXiv 2021
-
[37]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024. 7
2024
-
[38]
Selective structured state-spaces for long-form video understanding
Jue Wang, Wentao Zhu, Pichao Wang, Xiang Yu, Linda Liu, Mohamed Omar, and Raffay Hamid. Selective structured state-spaces for long-form video understanding. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6387–6397, 2023. 7, 9
2023
-
[39]
Towards long- form video understanding
Chao-Yuan Wu and Philipp Krahenbuhl. Towards long- form video understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1884–1894, 2021. 7
2021
-
[40]
Coin: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. Coin: A large-scale dataset for comprehensive instructional video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1207– 1216, 2019. 7
2019
-
[41]
The language of actions: Recovering the syntax and semantics of goal- directed human activities
Hilde Kuehne, Ali Arslan, and Thomas Serre. The language of actions: Recovering the syntax and semantics of goal- directed human activities. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 780–787, 2014. 7
2014
-
[42]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model.arXiv preprint arXiv:2401.09417, 2024. 7, 9
work page internal anchor Pith review arXiv 2024
-
[43]
Vmamba: Visual state space model.Advances in neu- ral information processing systems, 37:103031–103063,
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neu- ral information processing systems, 37:103031–103063,
-
[44]
U-mamba: Enhancing long-range dependency for biomedical image segmentation
Jun Ma, Feifei Li, and Bo Wang. U-mamba: Enhanc- ing long-range dependency for biomedical image segmen- tation.arXiv preprint arXiv:2401.04722, 2024. 8, 9
-
[45]
nnu-net: a self- configuring method for deep learning-based biomedical im- age segmentation.Nature methods, 18(2):203–211, 2021
Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Petersen, and Klaus H Maier-Hein. nnu-net: a self- configuring method for deep learning-based biomedical im- age segmentation.Nature methods, 18(2):203–211, 2021. 8
2021
-
[46]
Amos: A large-scale abdominal multi- organ benchmark for versatile medical image segmenta- tion.Advances in neural information processing systems, 35:36722–36732, 2022
Yuanfeng Ji, Haotian Bai, Chongjian Ge, Jie Yang, Ye Zhu, Ruimao Zhang, Zhen Li, Lingyan Zhanng, Wanling Ma, Xiang Wan, et al. Amos: A large-scale abdominal multi- organ benchmark for versatile medical image segmenta- tion.Advances in neural information processing systems, 35:36722–36732, 2022. 8
2022
-
[47]
2017 robotic instrument segmentation challenge.arXiv preprint arXiv:1902.06426, 2019
Max Allan, Alex Shvets, Thomas Kurmann, Zichen Zhang, Rahul Duggal, Yun-Hsuan Su, Nicola Rieke, Iro Laina, Niveditha Kalavakonda, Sebastian Bodenstedt, et al. 2017 robotic instrument segmentation challenge.arXiv preprint arXiv:1902.06426, 2019. 8
-
[48]
The multimodality cell segmenta- tion challenge: toward universal solutions.Nature methods, 21(6):1103–1113, 2024
Jun Ma, Ronald Xie, Shamini Ayyadhury, Cheng Ge, Anubha Gupta, Ritu Gupta, Song Gu, Yao Zhang, Gihun Lee, Joonkee Kim, et al. The multimodality cell segmenta- tion challenge: toward universal solutions.Nature methods, 21(6):1103–1113, 2024. 8
2024
-
[49]
Vm- unet: Vision mamba unet for medical image segmentation
Jiacheng Ruan, Jincheng Li, and Suncheng Xiang. Vm- unet: Vision mamba unet for medical image segmentation. ACM Transactions on Multimedia Computing, Communi- cations and Applications, 2024. 8, 9
2024
-
[50]
Noel CF Codella, David Gutman, M Emre Celebi, Brian Helba, Michael A Marchetti, Stephen W Dusza, Aadi Kalloo, Konstantinos Liopyris, Nabin Mishra, Harald Kit- tler, et al. Skin lesion analysis toward melanoma detec- tion: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (i...
2017
-
[51]
Noel Codella, Veronica Rotemberg, Philipp Tschandl, M Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris, Michael Marchetti, et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the interna- tional skin imaging collaboration (isic).arXiv preprint arXiv:1902.03368, 2019. 8
work page Pith review arXiv 2018
-
[52]
The ham10000 dataset, a large collection of multi-source der- matoscopic images of common pigmented skin lesions.Sci- entific data, 5(1):180161, 2018
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source der- matoscopic images of common pigmented skin lesions.Sci- entific data, 5(1):180161, 2018. 8
2018
-
[53]
Miccai multi- atlas labeling beyond the cranial vault–workshop and chal- lenge
Bennett Landman, Zhoubing Xu, Juan Igelsias, Martin Styner, Thomas Langerak, and Arno Klein. Miccai multi- atlas labeling beyond the cranial vault–workshop and chal- lenge. InProc. MICCAI multi-atlas labeling beyond cra- nial vault—workshop challenge, volume 5, page 12. Mu- nich, Germany, 2015. 8
2015
-
[54]
Vssd: Vision mamba with non-causal state space duality
Yuheng Shi, Mingjia Li, Minjing Dong, and Chang Xu. Vssd: Vision mamba with non-causal state space duality. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10819–10829, 2025. 8, 9
2025
-
[55]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 9
2021
-
[56]
Neuralangelo: High-fidelity neural surface reconstruction
Zhaoshuo Li, Thomas M ¨uller, Alex Evans, Russell H Tay- lor, Mathias Unberath, Ming-Yu Liu, and Chen-Hsuan Lin. Neuralangelo: High-fidelity neural surface reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8456–8465, 2023. 9, 10
2023
-
[57]
Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022. 9
2022
-
[58]
Large scale multi-view stereopsis evaluation
Rasmus Jensen, Anders Dahl, George V ogiatzis, Engin Tola, and Henrik Aanæs. Large scale multi-view stereopsis evaluation. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 406–413, 2014. 9
2014
-
[59]
Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017. 9
2017
-
[60]
arXiv preprint arXiv:2106.10689 , year=
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view recon- struction.arXiv preprint arXiv:2106.10689, 2021. 9
-
[61]
Zip-nerf: Anti-aliased grid-based neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Zip-nerf: Anti-aliased grid-based neural radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19697–19705, 2023. 10
2023
-
[62]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[63]
Deblur e-nerf: Nerf from motion-blurred events under high-speed or low-light condi- tions
Weng Fei Low and Gim Hee Lee. Deblur e-nerf: Nerf from motion-blurred events under high-speed or low-light condi- tions. InEuropean Conference on Computer Vision, pages 192–209. Springer, 2024. 10, 11
2024
-
[64]
Mobilenerf: Exploiting the polygon ras- terization pipeline for efficient neural field rendering on mobile architectures
Zhiqin Chen, Thomas Funkhouser, Peter Hedman, and An- drea Tagliasacchi. Mobilenerf: Exploiting the polygon ras- terization pipeline for efficient neural field rendering on mobile architectures. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 16569–16578, 2023. 10, 11
2023
-
[65]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, 2022. 10
2022
-
[66]
Baking neural ra- diance fields for real-time view synthesis
Peter Hedman, Pratul P Srinivasan, Ben Mildenhall, Jonathan T Barron, and Paul Debevec. Baking neural ra- diance fields for real-time view synthesis. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 5875–5884, 2021. 11
2021
-
[67]
Diffu- siondet: Diffusion model for object detection
Shoufa Chen, Peize Sun, Yibing Song, and Ping Luo. Diffu- siondet: Diffusion model for object detection. InProceed- ings of the IEEE/CVF international conference on com- puter vision, pages 19830–19843, 2023. 11, 12
2023
-
[68]
Crowdhuman: A benchmark for detecting human in a crowd,
Shuai Shao, Zijian Zhao, Boxun Li, Tete Xiao, Gang Yu, Xiangyu Zhang, and Jian Sun. Crowdhuman: A bench- mark for detecting human in a crowd.arXiv preprint arXiv:1805.00123, 2018. 11
-
[69]
Diffusiontrack: Point set diffusion model for visual object tracking
Fei Xie, Zhongdao Wang, and Chao Ma. Diffusiontrack: Point set diffusion model for visual object tracking. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19124, 2024. 11, 12
2024
-
[70]
Diff-retinex: Rethinking low-light image enhance- ment with a generative diffusion model
Xunpeng Yi, Han Xu, Hao Zhang, Linfeng Tang, and Ji- ayi Ma. Diff-retinex: Rethinking low-light image enhance- ment with a generative diffusion model. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 12302–12311, 2023. 11, 12
2023
-
[71]
Stochastic segmentation with conditional categorical diffusion models
Lukas Zbinden, Lars Doorenbos, Theodoros Pissas, Adrian Thomas Huber, Raphael Sznitman, and Pablo M´arquez-Neila. Stochastic segmentation with conditional categorical diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1119–1129, 2023. 12
2023
-
[72]
Kernel adap- tive convolution for scene text detection via distance map prediction
Jinzhi Zheng, Heng Fan, and Libo Zhang. Kernel adap- tive convolution for scene text detection via distance map prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5957–5966,
-
[73]
Got-10k: A large high-diversity benchmark for generic object track- ing in the wild.IEEE transactions on pattern analysis and machine intelligence, 43(5):1562–1577, 2019
Lianghua Huang, Xin Zhao, and Kaiqi Huang. Got-10k: A large high-diversity benchmark for generic object track- ing in the wild.IEEE transactions on pattern analysis and machine intelligence, 43(5):1562–1577, 2019. 11
2019
-
[74]
Lasot: A high-quality benchmark for large-scale single ob- ject tracking
Heng Fan, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Hexin Bai, Yong Xu, Chunyuan Liao, and Haibin Ling. Lasot: A high-quality benchmark for large-scale single ob- ject tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5374– 5383, 2019. 11
2019
-
[75]
Trackingnet: A large-scale dataset and benchmark for object tracking in the wild
Matthias Muller, Adel Bibi, Silvio Giancola, Salman Al- subaihi, and Bernard Ghanem. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European conference on computer vi- sion (ECCV), pages 300–317, 2018. 11
2018
-
[76]
Deep Retinex Decomposition for Low-Light Enhancement
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560, 2018. 12
work page Pith review arXiv 2018
-
[77]
The lung image database con- sortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans
Samuel G Armato III, Geoffrey McLennan, Luc Bidaut, Michael F McNitt-Gray, Charles R Meyer, Anthony P Reeves, Binsheng Zhao, Denise R Aberle, Claudia I Hen- schke, Eric A Hoffman, et al. The lung image database con- sortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical physics, 38...
2011
-
[78]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 12
2016
-
[79]
Make me a bnn: A simple strategy for estimating bayesian uncertainty from pre-trained models
Gianni Franchi, Olivier Laurent, Maxence Legu ´ery, Andrei Bursuc, Andrea Pilzer, and Angela Yao. Make me a bnn: A simple strategy for estimating bayesian uncertainty from pre-trained models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 12194–12204, 2024. 13
2024
-
[80]
Uncertainty-aware unsupervised multi- object tracking
Kai Liu, Sheng Jin, Zhihang Fu, Ze Chen, Rongxin Jiang, and Jieping Ye. Uncertainty-aware unsupervised multi- object tracking. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 9996–10005,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.