Recognition: unknown
Language models recognize dropout and Gaussian noise applied to their activations
Pith reviewed 2026-05-10 05:34 UTC · model grok-4.3
The pith
Language models can detect, localize, and distinguish dropout masking from Gaussian noise applied to their own activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
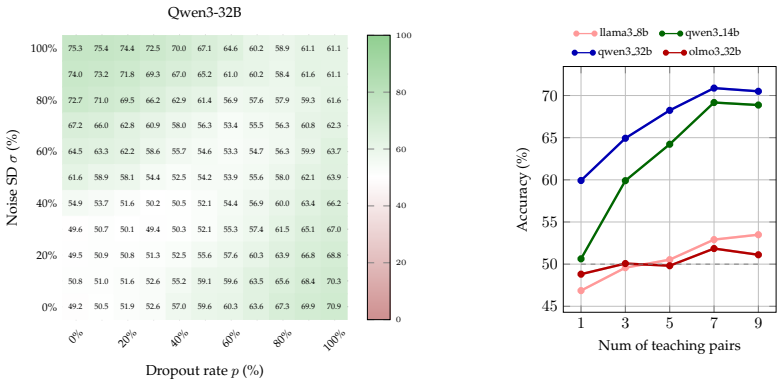
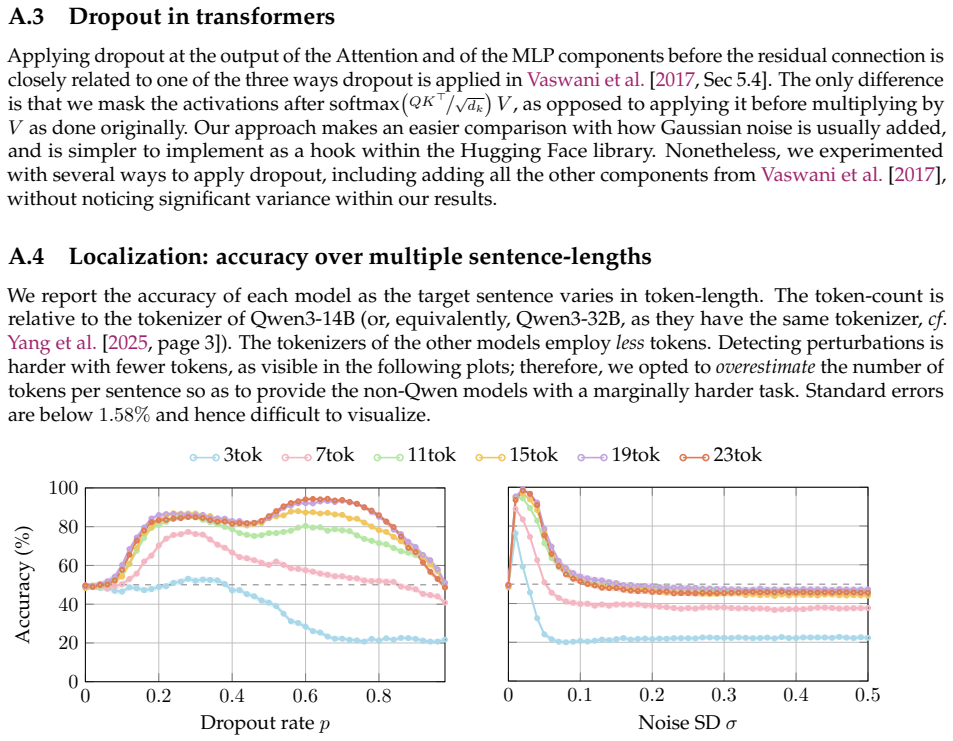
We provide evidence that language models can detect, localize and, to a certain degree, verbalize the difference between perturbations applied to their activations. We either mask activations, simulating dropout, or add Gaussian noise to them at a target sentence. We then ask a multiple-choice question such as which of the previous sentences was perturbed or which of the two perturbations was applied. The tested models can easily detect and localize the perturbations, often with perfect accuracy. These models can also learn, when taught in context, to distinguish between dropout and Gaussian noise. Accuracy in one case improves with perturbation strength and drops when in-context labels are翻
What carries the argument
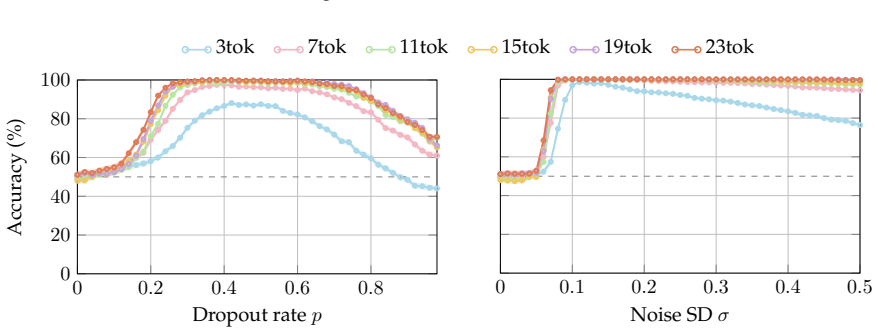
Multiple-choice questions that ask the model to identify which sentence received an activation perturbation or which type of perturbation (dropout-style masking versus added Gaussian noise) occurred, serving as a probe for whether the model registers changes to its internal states.
If this is right
- Models can identify which specific sentence in a sequence had its activations altered.
- Models can acquire the ability to label a perturbation as dropout or as Gaussian noise after seeing a few in-context examples.
- Accuracy on identifying the perturbation type rises with the magnitude of the applied noise or masking for at least some models.
- Flipping the correct labels in the in-context examples reduces accuracy, consistent with the model holding a prior favoring the true distinction.
Where Pith is reading between the lines
- The detection mechanism might be usable to let models flag other unexpected modifications to their internal computations.
- If the signal is robust, it could serve as one component in protocols that check whether a deployed model is operating under the conditions it was trained for.
- The same approach could be extended to other internal operations such as attention masking or activation scaling to map what else models can report about their own processing.
Load-bearing premise
The models' high accuracy on these tasks reflects genuine detection of the activation changes rather than exploitation of surface statistical cues created by how the perturbations were introduced or how the questions were worded.
What would settle it
If accuracy falls to chance level when the same perturbations are applied but the questions are rephrased to remove any direct reference to perturbation type or location, or when the perturbations are chosen so they leave the model's token outputs unchanged, that would indicate the original performance did not rely on internal detection.
Figures



















read the original abstract
We provide evidence that language models can detect, localize and, to a certain degree, verbalize the difference between perturbations applied to their activations. More precisely, we either (a) mask activations, simulating dropout, or (b) add Gaussian noise to them, at a target sentence. We then ask a multiple-choice question such as "Which of the previous sentences was perturbed?" or "Which of the two perturbations was applied?". We test models from the Llama, Olmo, and Qwen families, with sizes between 8B and 32B, all of which can easily detect and localize the perturbations, often with perfect accuracy. These models can also learn, when taught in context, to distinguish between dropout and Gaussian noise. Notably, Qwen3-32B's zero-shot accuracy in identifying which perturbation was applied improves as a function of the perturbation strength and, moreover, decreases if the in-context labels are flipped, suggesting a prior for the correct ones -- even modulo controls. Because dropout has been used as a training-regularization technique, while Gaussian noise is sometimes added during inference, we discuss the possibility of a data-agnostic "training awareness" signal and the implications for AI safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that language models (Llama, Olmo, Qwen families, 8B–32B) can detect, localize, and to some degree verbalize activation-level perturbations consisting of either dropout masking or additive Gaussian noise applied at a target sentence during the forward pass. This is tested via multiple-choice queries such as 'Which of the previous sentences was perturbed?' or 'Which of the two perturbations was applied?', with reported near-perfect accuracies, a scaling trend with perturbation strength for Qwen3-32B, and reduced performance under label flips that is taken to indicate a prior for the correct labels.
Significance. If the central empirical findings are robust, the work supplies evidence that current-scale language models maintain some form of meta-representation of their own internal activation statistics, with possible relevance to training-versus-inference distinctions and AI safety. The cross-model replication and the in-context learning result for perturbation-type discrimination are concrete strengths; the absence of machine-checked proofs or parameter-free derivations is expected for this empirical style of paper.
major comments (2)
- [Methods / Experimental Setup] The experimental design does not include controls that isolate internal detection from exploitation of downstream statistical signatures. No comparison is reported to a frozen copy of the model receiving the same perturbed activations but answering via an independent head, nor is KL divergence or logit-shift magnitude quantified between perturbed and clean forward passes before the query is posed.
- [Results] Results for Qwen3-32B report scaling of zero-shot accuracy with perturbation strength and sensitivity to label flips, yet the manuscript provides no statistical significance tests, trial counts, or exclusion criteria. This leaves the scaling claim and the 'prior for correct labels' interpretation difficult to evaluate quantitatively.
minor comments (3)
- [Abstract] The abstract states that results hold 'modulo controls' without enumerating those controls; this phrasing should be replaced by an explicit list or reference to the relevant subsection.
- [Methods] Notation for the perturbation parameters (dropout probability, Gaussian variance) is introduced without a consolidated table; adding one would improve reproducibility.
- [Discussion] The discussion of 'data-agnostic training awareness' would benefit from a short paragraph contrasting the training-time use of dropout with inference-time Gaussian noise, including any cited references.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] The experimental design does not include controls that isolate internal detection from exploitation of downstream statistical signatures. No comparison is reported to a frozen copy of the model receiving the same perturbed activations but answering via an independent head, nor is KL divergence or logit-shift magnitude quantified between perturbed and clean forward passes before the query is posed.
Authors: We acknowledge that additional controls could further isolate whether detection relies on internal activation statistics versus downstream output signatures. Our core setup applies perturbations directly to activations during the forward pass at a target sentence, after which the model processes the query using those modified states; this requires the model to draw on its updated internal representations to localize or classify the perturbation. A frozen-copy comparison with an independent head was not included, as it would necessitate separate infrastructure outside the scope of testing integrated introspection in a single forward pass. However, we agree that quantifying the perturbations' effects is valuable and will add KL divergence and logit-shift magnitude measurements between perturbed and clean passes (prior to the query) in the revised manuscript. revision: partial
-
Referee: [Results] Results for Qwen3-32B report scaling of zero-shot accuracy with perturbation strength and sensitivity to label flips, yet the manuscript provides no statistical significance tests, trial counts, or exclusion criteria. This leaves the scaling claim and the 'prior for correct labels' interpretation difficult to evaluate quantitatively.
Authors: We agree that these details are needed for quantitative evaluation. The Qwen3-32B experiments were run over a fixed number of trials per condition (to be specified explicitly, e.g., 50–100 trials), with exclusion limited to clearly invalid or non-responsive outputs. We will add the exact trial counts, exclusion criteria, and statistical tests (binomial tests for accuracy against chance, and appropriate trend tests for scaling with perturbation strength and label-flip sensitivity) to the revised manuscript. This will allow readers to assess the robustness of the scaling trend and the prior-for-correct-labels interpretation. revision: yes
Circularity Check
No circularity: purely empirical intervention-and-query design
full rationale
The paper reports direct experiments in which dropout masks or Gaussian noise are injected into activations at chosen positions, followed by multiple-choice queries to the same model about the intervention. Reported accuracies are measured outcomes of these interventions and queries, not quantities derived from equations or parameters fitted to the target data. The label-flip control is an independent manipulation that tests sensitivity to surface cues without reducing the main result to a fit. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the central claims; the work is self-contained against external benchmarks of model behavior under perturbation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intervening on activations at a target sentence produces detectable changes in the model's subsequent behavior.
Reference graph
Works this paper leans on
-
[1]
The falcon series of open language models.arXiv preprint arXiv:2311.16867, 2023
URLhttps://arxiv.org/abs/2311.16867. Yoshua Bengio, Stephen Clare, Carina Prunkl, Maksym Andriushchenko, Ben Bucknall, Malcolm Murray, 10 Rishi Bommasani, Stephen Casper, Tom Davidson, Raymond Douglas, et al. International ai safety report 2026.arXiv preprint arXiv:2602.21012,
-
[2]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901,
1901
-
[3]
URL https://proceedings.neurips.cc/paper_files/paper/2020/ file/c16a5320fa475530d9583c34fd356ef5-Paper.pdf. Iulia M Comsa and Murray Shanahan. Does it make sense to speak of introspection in large language models?arXiv preprint arXiv:2506.05068,
-
[4]
Reducing transformer depth on demand with structured dropout.arXiv preprint arXiv:1909.11556, 2019
URLhttps://arxiv.org/abs/1909.11556. Ely Hahami, Lavik Jain, and Ishaan Sinha. Feeling the strength but not the source: Partial introspection in llms.arXiv preprint arXiv:2512.12411,
-
[6]
E., Srivastava, N., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R
URL http://arxiv.org/abs/1207.0580. Harvey Lederman and Kyle Mahowald. Dissociating direct access from inference in ai introspection.arXiv preprint arXiv:2603.05414,
-
[7]
Emergent introspective awareness in large language models
Jack Lindsey. Emergent introspective awareness in large language models. https:// transformer-circuits.pub/2025/introspection/index.html,
2025
-
[8]
Houjun Liu, John Bauer, and Christopher D
Anthropic, Transformer Circuits thread, accessed 2026-03-27. Houjun Liu, John Bauer, and Christopher D. Manning. Drop dropout on single-epoch language model pretraining, 2025a. URLhttps://arxiv.org/abs/2505.24788. Litian Liu, Reza Pourreza, Sunny Panchal, Apratim Bhattacharyya, Yubing Jian, Yao Qin, and Roland Memisevic. Enhancing hallucination detection ...
-
[9]
Steering Llama 2 via Contrastive Activation Addition
URLhttps://arxiv.org/abs/2312.06681. Theia Pearson-Vogel, Martin Vanek, Raymond Douglas, and Jan Kulveit. Latent introspection: Models can detect prior concept injections.arXiv preprint arXiv:2602.20031, 2026a. Theia Pearson-Vogel, Martin Vanek, Raymond Douglas, and Jan Kulveit. Latent introspection: Models can detect prior concept injections, 2026b. URLh...
work page internal anchor Pith review arXiv
-
[10]
URL https://arxiv.org/abs/2412. 01784. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review arXiv
-
[11]
URL https://proceedings.neurips.cc/paper_files/ paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Wangchunshu Zhou, Tao Ge, Ke Xu, Furu Wei, and Ming Zhou
URL https://arxiv.org/ abs/1907.11065. Wangchunshu Zhou, Tao Ge, Ke Xu, Furu Wei, and Ming Zhou. Scheduled drophead: A regularization method for transformer models,
-
[13]
URLhttps://arxiv.org/abs/2004.13342. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405,
-
[14]
the answer is: A
A Appendix A.1 Models The exact model nouns we experimented with are:Llama-3.1-8B-Instruct, Olmo-3.1-32B-Instruct, Qwen3-14B, orQwen3-32B. We also experimented withGemma-3-1b-it,Olmo-3-7B-Instruct, Qwen3-4B-Instruct-2507, Qwen3-8B, and Qwen3-30B-A3B-Instruct-2507, but did not find enough variance in the results to justify allocating compute resources for ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.