Recognition: unknown
PBSBench: A Multi-Level Vision-Language Framework and Benchmark for Hematopathology Whole Slide Image Interpretation
Pith reviewed 2026-05-10 05:49 UTC · model grok-4.3
The pith
A specialized vision-language model trained on blood smear data outperforms general pathology AI on hematopathology tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
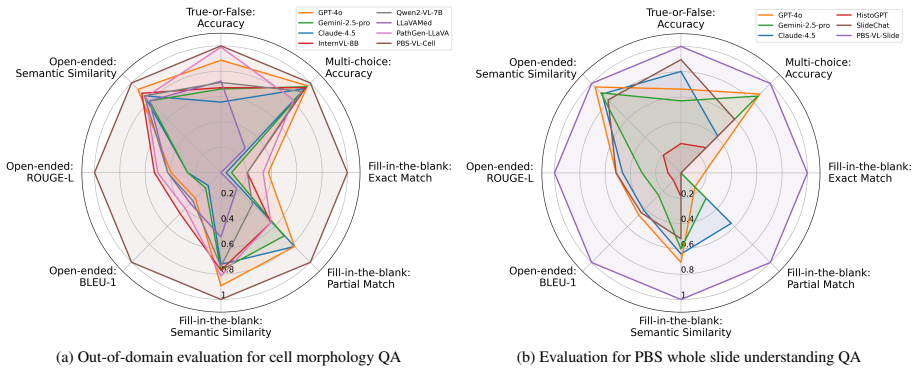
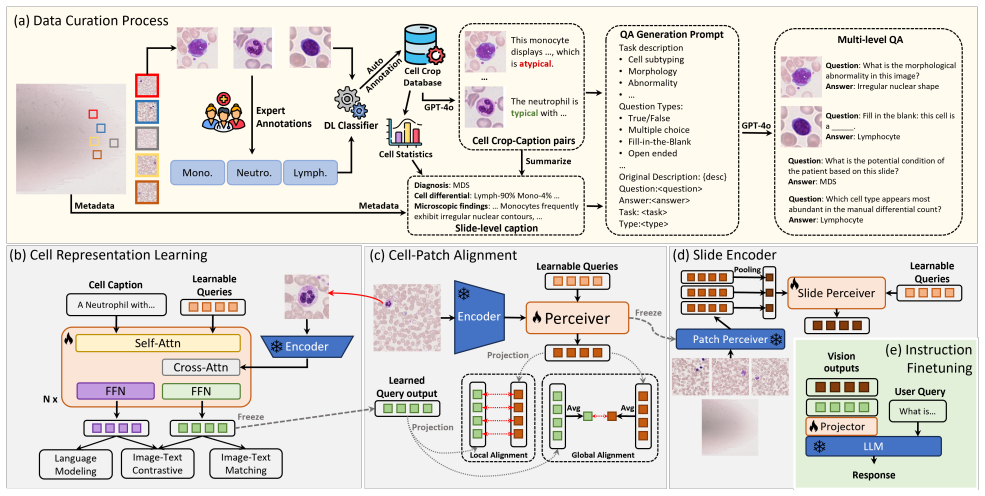
We construct PBSInstr, the first vision-language dataset for PBS interpretation comprising 353 WSIs with microscopic impressions, 29k cell-level crops with type and morphology labels, and over 28k QA pairs. Building on this, we develop PBS-VL, a hematopathology-tailored vision-language model for multi-level interpretation at cell and slide levels. On the new PBSBench benchmark with four question categories and six tasks, PBS-VL outperforms existing general-purpose and pathology MLLMs, showing the value of PBS-specific training data.
What carries the argument
PBS-VL, a vision-language model instruction-tuned on PBS-specific cell crops, slide images, and QA pairs to perform both cell morphology classification and higher-level slide interpretation.
If this is right
- PBS-specific instruction data produces measurable gains over models trained only on tissue pathology images.
- A single model can address both cell-level details and full-slide context in the same framework.
- PBSBench supplies a standardized testbed with defined tasks for comparing future PBS interpretation systems.
- Public release of the dataset, benchmark, and model weights enables other researchers to build on this starting point.
Where Pith is reading between the lines
- The same data-construction approach could be applied to create resources for related microscopic exams such as bone marrow aspirates or urine cytology.
- Clinical deployment might allow AI to flag unusual cell morphologies in real time during routine smear review, potentially shortening turnaround for common blood disorder cases.
- Combining this model with electronic health record data on patient history could support more integrated diagnostic suggestions beyond image analysis alone.
Load-bearing premise
That the PBSInstr dataset and the four question categories in PBSBench are representative enough of real-world blood smear variability and diagnostic reasoning to support general claims about model improvement.
What would settle it
Measuring whether PBS-VL still outperforms general models when tested on a fresh collection of PBS slides from different hospitals, staining protocols, or patient demographics not seen in the original dataset.
Figures






read the original abstract
Peripheral Blood Smear (PBS) is a critical microscopic examination in hematopathology that yields whole-slide imaging (WSI). Unlike solid tissue pathology, PBS interpretation focuses on individual cell morphologies rather than tissue architecture, making it distinct in both visual characteristics and diagnostic reasoning. However, current multimodal large language models (MLLMs) for pathology are primarily developed on solid-tissue WSIs and struggle to generalize to PBS. To bridge this gap, we construct PBSInstr, the first vision-language dataset for PBS interpretation, comprising 353 PBS WSIs paired with microscopic impression paragraphs and 29k cell-level image crops annotated with cell type labels and morphological descriptions. To facilitate instruction tuning, PBSInstr further includes 27k question-answer (QA) pairs for cell crops and 1,286 QA pairs for PBS slides. Building upon PBSInstr, we develop PBS-VL, a hematopathology-tailored vision-language model for multi-level PBS interpretation at both cell and slide levels. To comprehensively evaluate PBS understanding, we construct PBSBench, a visual question answering (VQA) benchmark featuring four question categories and six PBS interpretation tasks. Experiments show that PBS-VL outperforms existing general-purpose and pathology MLLMs, underscoring the value of PBS-specific data. We release our code, datasets, and model weights to facilitate future research. Our proposed framework lays the foundation for developing practical AI assistants supporting decision-making in hematopathology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PBSInstr, the first vision-language dataset for peripheral blood smear (PBS) interpretation comprising 353 WSIs with impression paragraphs, 29k cell-level crops with type labels and morphological descriptions, and over 27k QA pairs (plus 1,286 slide-level QA pairs). It develops PBS-VL, a hematopathology-specific MLLM for multi-level (cell and slide) interpretation, and PBSBench, a VQA benchmark with four question categories and six tasks. Experiments show PBS-VL outperforming general-purpose and pathology MLLMs, and the authors release code, datasets, and model weights.
Significance. If the empirical results hold under scrutiny, the work fills a clear gap by providing the first dedicated PBS resources, recognizing that PBS analysis centers on cell morphology rather than tissue architecture and that existing pathology MLLMs do not transfer well. The explicit release of datasets, code, and weights is a concrete strength that supports reproducibility and future extensions in this specialized domain.
major comments (2)
- [§3] §3 (PBSInstr construction): The 353-WSI collection is described only by aggregate counts (29k crops, 27k+ QA pairs) with no details on acquisition sources, staining variability, patient demographics, or inclusion of rare cell types/morphologies. This omission directly undermines the central inference that measured gains demonstrate the value of PBS-specific data rather than an artifact of a narrow collection.
- [§5] §5 (Experiments): The headline outperformance tables report raw metrics for PBS-VL versus baselines but contain no statistical significance tests, confidence intervals, or variance estimates across runs or data splits. Without these, the claim that PBS-VL 'outperforms' cannot be distinguished from training or evaluation noise and is therefore not yet load-bearing evidence for the paper's conclusion.
minor comments (2)
- [PBSBench] The mapping from the four question categories to the six PBS interpretation tasks is stated at a high level; an explicit table or diagram would clarify coverage of diagnostic reasoning steps.
- [Abstract and §3] Minor notation inconsistency: '27k' is used for cell-crop QA pairs while '1,286' is given exactly for slide-level pairs; uniform precision or a breakdown by task would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects for improving the clarity and rigor of our work. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (PBSInstr construction): The 353-WSI collection is described only by aggregate counts (29k crops, 27k+ QA pairs) with no details on acquisition sources, staining variability, patient demographics, or inclusion of rare cell types/morphologies. This omission directly undermines the central inference that measured gains demonstrate the value of PBS-specific data rather than an artifact of a narrow collection.
Authors: We agree that greater transparency on dataset construction is necessary to substantiate our claims. In the revised manuscript, we will expand Section 3 with details on WSI acquisition sources (specific clinical sites and laboratories), staining protocols and observed variability, patient demographics (age and sex distributions, subject to ethical de-identification constraints), and the full distribution of cell types including rare morphologies (e.g., blasts, schistocytes, and atypical forms). These additions will demonstrate the collection's breadth and support that performance gains arise from PBS-specific characteristics rather than narrow sampling. revision: yes
-
Referee: [§5] §5 (Experiments): The headline outperformance tables report raw metrics for PBS-VL versus baselines but contain no statistical significance tests, confidence intervals, or variance estimates across runs or data splits. Without these, the claim that PBS-VL 'outperforms' cannot be distinguished from training or evaluation noise and is therefore not yet load-bearing evidence for the paper's conclusion.
Authors: We concur that statistical validation is required for robust conclusions. In the revised version, we will augment the experimental results in Section 5 with appropriate statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests on per-task metrics), 95% confidence intervals, and variance estimates derived from multiple independent training runs with different random seeds or bootstrap resampling of the evaluation sets. This will provide quantitative support for the observed improvements. revision: yes
Circularity Check
No significant circularity: empirical benchmark paper with held-out evaluation
full rationale
The paper constructs PBSInstr (353 WSIs, cell crops, QA pairs) and PBSBench (four categories, six tasks), trains PBS-VL via instruction tuning, and reports empirical outperformance on the benchmark. No mathematical derivation, equations, or first-principles results exist that could reduce to inputs by construction. Performance claims rest on experimental comparisons against general and pathology MLLMs using held-out evaluation rather than fitted parameters or self-referential predictions. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling appear in the derivation chain. The central claim (value of PBS-specific data) is supported by external benchmark results, not tautological redefinition of the training data itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard machine learning assumptions hold, including that training and test splits are representative and that VQA performance correlates with clinical utility.
Reference graph
Works this paper leans on
-
[1]
Claude sonnet 4.5.https : / / www
Anthropic. Claude sonnet 4.5.https : / / www . anthropic.com/claude/sonnet, 2025. Model page; accessed 2025-11-13. 7
2025
-
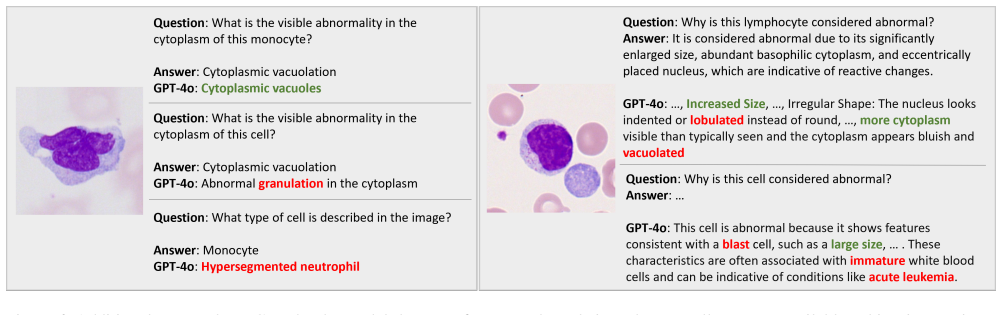
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 7, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
H-optimus-0: the world’s largest open-source ai foundation model for pathology, 2024
Bioptimus. H-optimus-0: the world’s largest open-source ai foundation model for pathology, 2024. 3
2024
-
[4]
H-optimus-1: Foundation models for histology,
Bioptimus. H-optimus-1: Foundation models for histology,
-
[5]
Company/model announcement. 3
-
[6]
Pingyi Chen, Honglin Li, Chenglu Zhu, Sunyi Zheng, Zhongyi Shui, and Lin Yang. WsiCaption: Multiple instance generation of pathology reports for gigapixel whole-slide im- ages.arXiv:2311.16480, 2023. 3
-
[7]
WSI-VQA: Interpreting whole slide images by generative visual question answering
Pingyi Chen, Chenglu Zhu, Sunyi Zheng, Honglin Li, and Lin Yang. WSI-VQA: Interpreting whole slide images by generative visual question answering. InECCV, 2024. 3, 4
2024
-
[8]
Chen et al
Richard J. Chen et al. Towards a general-purpose foundation model for computational pathology.Nature Medicine, 2024. 3
2024
-
[9]
Slidechat: A large vision-language assistant for whole- slide pathology image understanding
Ying Chen, Guoan Wang, Yuanfeng Ji, Yanjun Li, Jin Ye, et al. Slidechat: A large vision-language assistant for whole- slide pathology image understanding. InCVPR, 2025. 2, 3, 4, 7
2025
-
[10]
Peripheral blood smear.https://my
Cleveland Clinic. Peripheral blood smear.https://my. clevelandclinic . org / health / diagnostics / 22742 - peripheral - blood - smear - test, 2022. Accessed: 2025-10-14. 1
2022
-
[11]
Pa-LLaV A: A large language-vision assis- tant for human pathology image understanding, 2024
Dawei Dai et al. Pa-LLaV A: A large language-vision assis- tant for human pathology image understanding, 2024. 4, 7
2024
-
[12]
Computa- tional analysis of peripheral blood smears detects disease- associated cytomorphologies.Nature Communications, 14 (1):4378, 2023
Jos ´e Guilherme de Almeida, Emma Gudgin, Martin Besser, William G Dunn, Jonathan Cooper, Torsten Haferlach, George S Vassiliou, and Moritz Gerstung. Computa- tional analysis of peripheral blood smears detects disease- associated cytomorphologies.Nature Communications, 14 (1):4378, 2023. 4, 1
2023
-
[13]
Gemini 2.5 pro.https : / / deepmind.google/models/gemini/pro/, 2025
Google DeepMind. Gemini 2.5 pro.https : / / deepmind.google/models/gemini/pro/, 2025. Model page; accessed 2025-11-13. 7
2025
-
[14]
Pathvqa: 30000+ questions for medical visual question answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering. InAAAI Workshop on Health Intelli- gence, 2020. 2
2020
-
[15]
CHIEF: Clinical histopathology imaging eval- uation foundation model, 2024
HMS DBMI. CHIEF: Clinical histopathology imaging eval- uation foundation model, 2024. Code repository and model card. 4
2024
-
[16]
Densely connected convolutional net- works
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kil- ian Q Weinberger. Densely connected convolutional net- works. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017. 1
2017
-
[17]
A visual–language foundation model for pathology image analysis.Nature Medicine, 2023
Ziyi Huang et al. A visual–language foundation model for pathology image analysis.Nature Medicine, 2023. 3
2023
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Wisdom O. Ikezogwo, Mehmet S. Seyfioglu, Fatemeh Ghezloo, Dylan S. C. Geva, Fatwir S. Mohammed, Pa- van K. Anand, Ranjay Krishna, and Linda Shapiro. Quilt- 1M: One million image-text pairs for histopathology. arXiv:2306.11207, 2023. 3
-
[20]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational confer- ence on machine learning, pages 4651–4664. PMLR, 2021. 6
2021
-
[21]
TCGA-Reports: A machine-readable pathol- ogy reports dataset for the cancer genome atlas.Scientific Data, 2024
J Kefeli et al. TCGA-Reports: A machine-readable pathol- ogy reports dataset for the cancer genome atlas.Scientific Data, 2024. 3
2024
-
[22]
Dinobloom: A foundation model for generalizable cell embeddings in hematology
Vincent Koch et al. Dinobloom: A foundation model for generalizable cell embeddings in hematology. InMICCAI,
-
[23]
Building and better understanding vision-language models: insights and future directions
Hugo Laurenc ¸on, Andr´es Marafioti, Victor Sanh, and L ´eo Tronchon. Building and better understanding vision- language models: insights and future directions.arXiv preprint arXiv:2408.12637, 2024. 7
-
[24]
Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
-
[25]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 6, 7
2023
-
[26]
WSI-LLaV A: A multimodal large lan- guage model for whole slide image.arXiv:2412.02141,
Yuci Liang, Xinheng Lyu, Meidan Ding, Wenting Chen, Jipeng Zhang, et al. WSI-LLaV A: A multimodal large lan- guage model for whole slide image.arXiv:2412.02141,
-
[27]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 6
2004
-
[28]
Llavanext: Im- proved reasoning, ocr, and world knowledge.https: / / llava - vl
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Im- proved reasoning, ocr, and world knowledge.https: / / llava - vl . github . io / blog / 2024 - 01 - 30 - llava-next/, 2024. 7
2024
-
[29]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review arXiv
-
[30]
Lu et al
Ming Y . Lu et al. A visual-language foundation model for computational pathology.Nature Medicine, 2024. 4
2024
-
[31]
Lu et al
Ming Y . Lu et al. TITAN: A multimodal whole-slide foun- dation model for pathology.Nature Medicine, 2025. 4, 7
2025
-
[32]
A single-cell morphological dataset of leukocytes from aml patients and non-malignant controls,
Christian Matek, Simone Schwarz, Carsten Marr, and Karsten Spiekermann. A single-cell morphological dataset of leukocytes from aml patients and non-malignant controls,
-
[33]
Med-flamingo: a multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Ya- sunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Ed- uardo Pontes Reis, and Pranav Rajpurkar. Med-flamingo: a multimodal medical few-shot learner. InMachine Learning for Health (ML4H), pages 353–367. PMLR, 2023. 7
2023
-
[34]
Cellpose-sam: Superhuman generalization for cellular seg- mentation.bioRxiv, 2025
Marius Pachitariu, Michael Rariden, and Carsen Stringer. Cellpose-sam: Superhuman generalization for cellular seg- mentation.bioRxiv, 2025. 4
2025
-
[35]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[36]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Lan- guage Processing. Association for Computational Linguis- tics, 2019. 6
2019
-
[37]
Au- tomatic recognition of five types of white blood cells in pe- ripheral blood.Computerized Medical Imaging and Graph- ics, 35(4):333–343, 2011
Seyed Hamid Rezatofighi and Hamid Soltanian-Zadeh. Au- tomatic recognition of five types of white blood cells in pe- ripheral blood.Computerized Medical Imaging and Graph- ics, 35(4):333–343, 2011. 5
2011
-
[38]
Quilt-LLaV A: Visual in- struction tuning by extracting localized narratives from open- source histopathology videos, 2023
Mehmet Saygin Seyfioglu et al. Quilt-LLaV A: Visual in- struction tuning by extracting localized narratives from open- source histopathology videos, 2023. 2, 4, 7
2023
-
[39]
PRISM: A multi-modal generative foundation model for slide-level histopathology, 2024
George Shaikovski et al. PRISM: A multi-modal generative foundation model for slide-level histopathology, 2024. 4
2024
-
[40]
Acute promyelocytic leukemia (apl) peripheral blood smear images.https : / / www.kaggle.com/datasets/eugeneshenderov/ acute - promyelocytic - leukemia - apl, 2020
Eugene Shenderov. Acute promyelocytic leukemia (apl) peripheral blood smear images.https : / / www.kaggle.com/datasets/eugeneshenderov/ acute - promyelocytic - leukemia - apl, 2020. Dataset on Kaggle; accessed 2025-11-10. 5, 1, 2
2020
-
[41]
PathMMU: A massive multimodal expert-level benchmark for understanding and reasoning in pathology
Yuxuan Sun, Hao Wu, Chenglu Zhu, Sunyi Zheng, et al. PathMMU: A massive multimodal expert-level benchmark for understanding and reasoning in pathology. arXiv:2401.16355, 2024. 3
-
[42]
Yuxuan Sun, Chenglu Zhu, Sunyi Zheng, Kai Zhang, Lin Sun, Zhongyi Shui, Yunlong Zhang, Honglin Li, and Lin Yang. PathAsst: A Generative Foundation AI Assistant to- wards Artificial General Intelligence of Pathology.Proceed- ings of the AAAI Conference on Artificial Intelligence, 38(5): 5034–5042, 2024. 4
2024
-
[43]
Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computa- tional pathology
Yuxuan Sun, Yixuan Si, Chenglu Zhu, Xuan Gong, Kai Zhang, Pingyi Chen, Ye Zhang, Zhongyi Shui, Tao Lin, and Lin Yang. Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computa- tional pathology. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10360–10371, 2025. 4
2025
-
[44]
Pathgen-1.6m: 1.6 million pathology image-text pairs generation through multi-agent collabora- tion, 2024
Yuxuan Sun et al. Pathgen-1.6m: 1.6 million pathology image-text pairs generation through multi-agent collabora- tion, 2024. 4
2024
-
[45]
The cancer genome atlas (tcga) program.https : / / www
The Cancer Genome Atlas (TCGA) Research Network. The cancer genome atlas (tcga) program.https : / / www . cancer . gov / ccg / research / genome - sequencing/tcga, 2025. National Cancer Institute; ac- cessed 2025-11-13. 2
2025
-
[46]
Generating dermatopathology reports from gigapixel whole-slide images.Nature Communica- tions, 2025
Minh Tran et al. Generating dermatopathology reports from gigapixel whole-slide images.Nature Communica- tions, 2025. 4, 7
2025
-
[47]
A foundation model for clinical- grade computational pathology.Nature Medicine, 2024
Eugene V orontsov et al. A foundation model for clinical- grade computational pathology.Nature Medicine, 2024. 3
2024
-
[48]
Evaluating open-QA eval- uation
Cunxiang Wang, Sirui Cheng, Qipeng Guo, Yuanhao Yue, Bowen Ding, Zhikun Xu, Yidong Wang, Xiangkun Hu, Zheng Zhang, and Yue Zhang. Evaluating open-QA eval- uation. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. 6
2023
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 7
work page internal anchor Pith review arXiv 2025
-
[51]
Wbc lisc dataset.https : / / universe
WBCs. Wbc lisc dataset.https : / / universe . roboflow.com/wbcs/wbc- lisc, 2022. visited on 2025-11-10. 5, 1, 2
2022
-
[52]
A vision–language foundation model for precision oncology.Nature Cancer, 2025
Jinxi Xiang et al. A vision–language foundation model for precision oncology.Nature Cancer, 2025. 4
2025
-
[53]
A whole-slide foundation model for digital pathology from real-world data.Nature, 2024
Han Xu et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 2024. 3
2024
-
[54]
virchow2: scaling self-supervised mixed magnification pretraining for computational pathol- ogy, 2024
Eric Zimmermann et al. virchow2: scaling self-supervised mixed magnification pretraining for computational pathol- ogy, 2024. 3 PBSBench: A Multi-Level Vision-Language Framework and Benchmark for Hematopathology Whole Slide Image Interpretation Supplementary Material
2024
-
[55]
4, we present more detailed statistics on the number of questions in our datasets, with a breakdown by question type
Dataset Statistics Here in Tab. 4, we present more detailed statistics on the number of questions in our datasets, with a breakdown by question type. Note that we remove questions with high similarity or trivial answers, leading to some small sub- groups
-
[56]
We also publish PBSInstr,PBSBench, and our evaluation toolkit together with the training code
Code and Data Availability We publish our code for trainingPBS-VL2. We also publish PBSInstr,PBSBench, and our evaluation toolkit together with the training code
-
[57]
Ethical Statement Our proposed datasetsPBSInstrandPBSBenchare pri- marily built on a publicly available PBS dataset [11] and several blood cell datasets [31, 39, 50]
Ethical, Limitation, and Hallucination Statements 8.1. Ethical Statement Our proposed datasetsPBSInstrandPBSBenchare pri- marily built on a publicly available PBS dataset [11] and several blood cell datasets [31, 39, 50]. They are thoroughly de-identified and reveal no personal information. PBSInstr,PBSBench, andPBS-VLare released solely for research and ...
-
[58]
Oth- ers
Additional Data Processing Details 9.1. Patch Quality Control We apply the tile quality control model from [11] to identify and remove patches with extremely low or high cell con- centrations, as well as patches dominated by artifacts. Fol- lowing [11], we extract patches of size512×512at40× magnification and reuse their released DenseNet121-based quality...
-
[59]
Prompts As we scale up our annotation using GPT-4o, we present the prompt used for various tasks in Fig. 7, Fig. 8, Fig. 9, and Fig. 10. Note that we remove some prompt sections on input/output formatting and examples for simplicity
-
[60]
Breakdown Performance on PBSBench In this section, we report a detailed breakdown of bench- mark performance by task and question types
Additional Experimental Results 11.1. Breakdown Performance on PBSBench In this section, we report a detailed breakdown of bench- mark performance by task and question types. They can be found in Tab. 8, Tab. 9, Tab. 10, Tab. 11, and Tab. 12. For cell-level questions, we report only one metric per ques- tion type for simplicity: accuracy for True-or-False...
-
[61]
this cell
Additional Case Study We provide an additional case study in Fig. 6 that illus- trates how model performance degrades when explicit cell type information is removed from the question. In this case study, we modify the original questions by replacing spe- cific cell types (e.g. monocyte) with a generic reference (“this cell”). Thus, we eliminate hints that...
-
[62]
Figure 7
Large Tables and Figures See below. Figure 7. Prompts for cell crop captioning Table 7. The mapping of cell type from out-of-distribution cell image datasets for normalization. AML-Cytomorphology LMU APL-kaggle fine-coarsed types normalized types fine-coarsed types normalized types BAS Basophil Artifact Others EBO Others Band neutrophils Neutrophil EOS Eo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.