Recognition: unknown
SLO-Guard: Crash-Aware, Budget-Consistent Autotuning for SLO-Constrained LLM Serving
Pith reviewed 2026-05-10 05:56 UTC · model grok-4.3
The pith
SLO-Guard treats crashes as useful data so that a fixed tuning budget for latency-constrained LLM serving produces more consistent results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
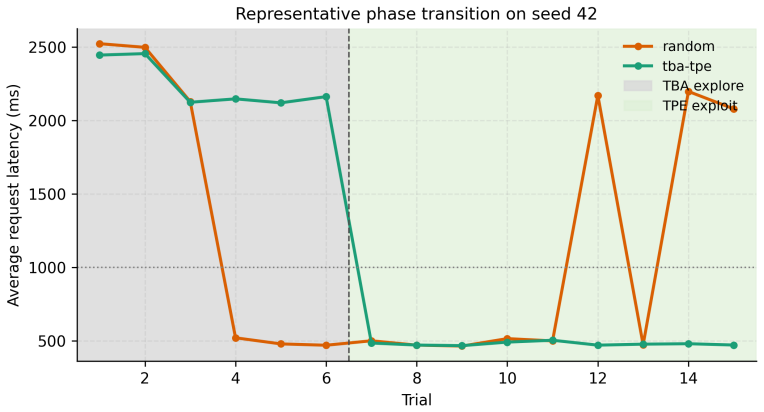
SLO-Guard pairs feasible-first Thermal Budget Annealing exploration with a warm-started Tree-structured Parzen Estimator exploitation phase whose handoff replays the entire history, including crashes encoded as extreme constraint violations. It adds a configuration-repair pass, a GPU-aware KV-cache memory guard, and a four-category crash taxonomy. On Qwen2-1.5B with vLLM 0.19 on A100 hardware, it reaches the same feasibility and best latency as uniform random search yet allocates more trials to the fast regime and reduces cross-seed latency variance by a factor of 4.4 under concurrent load.
What carries the argument
A two-phase optimizer that first explores with Thermal Budget Annealing to locate feasible regions while avoiding crashes, then exploits with a Tree-structured Parzen Estimator that re-uses all prior observations including those marked as extreme constraint violations.
Load-bearing premise
The four-category crash taxonomy, configuration-repair pass, and GPU-aware KV-cache guard must generalize beyond the tested Qwen2-1.5B plus vLLM 0.19 plus A100 combination, and the concurrent harness must reflect real production load patterns.
What would settle it
Replicate the five-seed study with the same total trial budget and measure whether the count of fast-regime trials and the standard deviation of best latency become statistically indistinguishable between SLO-Guard and random search.
Figures





read the original abstract
Serving large language models under latency service-level objectives (SLOs) is a configuration-heavy systems problem with an unusually failure-prone search space: many plausible configurations crash outright or miss user-visible latency targets, and standard black-box optimizers treat these failures as wasted trials. We present SLO-Guard, a crash-aware autotuner for vLLM serving that treats crashes as first-class observations. SLO-Guard combines a feasible-first Thermal Budget Annealing (TBA) exploration phase with a warm-started Tree-structured Parzen Estimator (TPE) exploitation phase; the handoff replays all exploration history, including crashes encoded as extreme constraint violations. We additionally contribute a configuration-repair pass, a GPU-aware KV-cache memory guard, and a four-category crash taxonomy. We evaluate SLO-Guard on Qwen2-1.5B served with vLLM 0.19 on an NVIDIA A100 40GB. Across a pre-specified five-seed study, both SLO-Guard and uniform random search attain 75/75 feasibility with zero crashes under the corrected concurrent harness, and are statistically tied on best-achieved latency (Mann-Whitney two-sided p=0.84). SLO-Guard's advantage is in budget consistency: more trials in the fast-serving regime (10.20 vs. 7.40 out of 15; one-sided p=0.014) and higher post-handoff consistency (0.876 vs. 0.539; p=0.010). Under concurrent load, SLO-Guard's cross-seed standard deviation on best latency is 4.4x tighter than random search's (2.26 ms vs. 10.00 ms). A harness-replication analysis shows that the consistency findings survive an independent sequential-dispatch measurement condition. The central claim is not that SLO-Guard finds a better final configuration, but that it spends a fixed tuning budget more predictably once the fast regime has been found.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SLO-Guard, a crash-aware autotuner for vLLM-based LLM serving under latency SLOs. It combines a feasible-first Thermal Budget Annealing (TBA) exploration phase with a warm-started Tree-structured Parzen Estimator (TPE) exploitation phase that replays all prior trials (including crashes encoded as extreme violations). Additional contributions are a four-category crash taxonomy, a configuration-repair pass, and a GPU-aware KV-cache memory guard. In a pre-specified five-seed study on Qwen2-1.5B with vLLM 0.19 on A100, both SLO-Guard and uniform random search achieve 75/75 feasibility with no crashes; they are statistically tied on best latency (Mann-Whitney p=0.84) but SLO-Guard shows superior budget consistency (more trials in the fast-serving regime, higher post-handoff consistency, and 4.4x tighter cross-seed latency variance), with supporting one-sided p-values and a sequential-dispatch harness replication.
Significance. If the consistency results hold, the work offers a practical advance for autotuning in failure-prone LLM serving spaces by prioritizing predictable use of a fixed tuning budget over merely finding a better final configuration. The statistical tests (Mann-Whitney, p-values), explicit acknowledgment of best-latency tie, and independent harness replication are strengths that increase credibility. The approach could influence production tuning pipelines where crashes and variance are costly.
major comments (2)
- [Evaluation / Results] Evaluation section (results on fast-serving regime): the claim of 10.20 vs. 7.40 trials in the fast regime (p=0.014) is load-bearing for the central consistency argument, yet the exact latency threshold or quantitative definition of 'fast-serving regime' is not stated in the reported results or methods; without it the metric cannot be independently verified or reproduced.
- [§3] §3 (TBA-to-TPE handoff and crash encoding): the replay of exploration history with crashes as extreme constraint violations is described at a high level, but no detail is given on how the TPE surrogate model incorporates these values (e.g., the precise penalty magnitude or kernel handling); this step is central to the claimed advantage over random search and requires explicit pseudocode or equations for reproducibility.
minor comments (3)
- [Abstract / Evaluation] The abstract and results mention 'one-sided p=0.014' and 'p=0.010' but should consistently name the test (Mann-Whitney) and confirm whether the one-sided direction was pre-specified.
- [Evaluation] The concurrent harness is used for the main results while a sequential-dispatch replication is reported as a check; the paper should clarify the exact differences in load modeling between the two and why the sequential version is only a replication rather than the primary condition.
- [Methods] Hyperparameters for TBA (budget schedule, temperature decay) and TPE (number of initial samples, acquisition function) are not listed; these are needed to reproduce the 15-trial budget experiments.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the recognition of our statistical approach and replication efforts, and the recommendation for minor revision. The comments correctly identify areas where additional clarity will strengthen reproducibility. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation section (results on fast-serving regime): the claim of 10.20 vs. 7.40 trials in the fast regime (p=0.014) is load-bearing for the central consistency argument, yet the exact latency threshold or quantitative definition of 'fast-serving regime' is not stated in the reported results or methods; without it the metric cannot be independently verified or reproduced.
Authors: We agree that the quantitative definition of the fast-serving regime must be stated explicitly for reproducibility. This definition was applied in our analysis but was omitted from the manuscript text. In the revision we will add a precise statement of the latency threshold (and its relation to the target SLO) to both the methods and the results sections so that the reported trial counts and p-value can be independently verified. revision: yes
-
Referee: [§3] §3 (TBA-to-TPE handoff and crash encoding): the replay of exploration history with crashes as extreme constraint violations is described at a high level, but no detail is given on how the TPE surrogate model incorporates these values (e.g., the precise penalty magnitude or kernel handling); this step is central to the claimed advantage over random search and requires explicit pseudocode or equations for reproducibility.
Authors: We acknowledge that the description of crash encoding and the TPE handoff is currently high-level. In the revised manuscript we will expand §3 with the exact penalty magnitude used for crashes, the manner in which these values are passed to the TPE surrogate (including kernel handling), and pseudocode for the replay procedure. This will make the mechanism fully reproducible and clarify its contribution relative to random search. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical systems contribution. It defines SLO-Guard as a two-phase autotuner (TBA exploration followed by TPE exploitation with crash encoding and repair), then measures its behavior on a fixed harness against random search. All load-bearing claims (budget consistency, post-handoff stability, cross-seed variance) are backed by direct experimental counts, Mann-Whitney tests, and a replication check under sequential dispatch. No equations, fitted parameters, or self-citations are used to derive the reported metrics; the results are independent observations of the implemented system.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sarathi-serve: Efficient LLM inference by piggybacking decodes with chunked prefills.arXiv preprint, 2024
Amey Agrawal et al. Sarathi-serve: Efficient LLM inference by piggybacking decodes with chunked prefills.arXiv preprint, 2024. Verify final bibliographic details before submission
2024
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 2623–2631, 2019
2019
-
[3]
Amazon SageMaker automatic model tuning
Amazon Web Services. Amazon SageMaker automatic model tuning. https://docs. aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning.html, 2025. Doc- umentation page
2025
-
[4]
Algorithms for hyper-parameter optimization
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper-parameter optimization. InAdvances in Neural Information Processing Systems 24, pages 2546–2554, 2011
2011
-
[5]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems 35, pages 16344–16359, 2022
2022
-
[6]
Gelbart, Jasper Snoek, and Ryan P
Michael A. Gelbart, Jasper Snoek, and Ryan P . Adams. Bayesian optimization with unknown constraints.arXiv preprint arXiv:1403.5607, 2014. 17
-
[7]
Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, David Kochanski, John Karro, and D. Sculley. Google vizier: A service for black-box optimization. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1487–1495, 2017
2017
-
[8]
Hoos, and Kevin Leyton-Brown
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. InProceedings of the 5th International Conference on Learning and Intelligent Optimization, pages 507–523, 2011
2011
-
[9]
Gonzalez, Hao Zhang, and Ion Stoica
Woojin Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Jinyang Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
2023
-
[10]
Constrained bayesian optimization with noisy experiments.Bayesian Analysis, 14(2):495–519, 2019
Benjamin Letham, Brian Karrer, Guilherme Ottoni, and Eytan Bakshy. Constrained bayesian optimization with noisy experiments.Bayesian Analysis, 14(2):495–519, 2019
2019
-
[11]
SLO-Guard: Crash-aware autotuning for llm serving, 2026
Christian Lysen. SLO-Guard: Crash-aware autotuning for llm serving, 2026. URL https://github.com/Chrislysen/SLO-Guard
2026
-
[12]
Thermal budget annealing: Feasible-first exploration for con- strained ml deployment, 2026
Christian Lysenstøen. Thermal budget annealing: Feasible-first exploration for con- strained ml deployment, 2026. arXiv preprint pending; update citation details after public release
2026
-
[13]
GenAI-Perf: Generative AI performance measurement for Triton and OpenAI-compatible apis
NVIDIA. GenAI-Perf: Generative AI performance measurement for Triton and OpenAI-compatible apis. https://docs.nvidia.com/ deeplearning/triton-inference-server/user-guide/docs/perf _benchmark/ genai-perf-README.html, 2025. Documentation page
2025
-
[14]
Scott Gardner, Itay Hubara, Sachin Idgunji, Thomas B
Vijay Janapa Reddi, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, Max Breughe, Maximilien Charlebois, William Chou, et al. MLPerf inference benchmark.arXiv preprint arXiv:1911.02549, 2020
-
[15]
Gonzalez, Cho-Jui Hsieh, and Ion Stoica
Ying Sheng, Lianmin Zheng, Binhang Yu, Siyuan Zhuang, Zhuohan Li, Max Ryabinin, Alex Touzalin, Joseph E. Gonzalez, Cho-Jui Hsieh, and Ion Stoica. Flexgen: High- throughput generative inference of large language models with a single GPU or CPU. InProceedings of the 40th International Conference on Machine Learning, pages 31094–31116, 2023
2023
-
[16]
David Stenger, Dominik Scheurenberg, and Sebastian Trimpe. Local bayesian opti- mization for controller tuning with crash constraints.arXiv preprint arXiv:2411.16267, 2024
-
[17]
Morphling: Fast, near-optimal auto-configuration for cloud-native model serving
Luping Wang, Lingyun Yang, Yinghao Yu, Wei Wang, Bo Li, Xianchao Sun, Jian He, and Liping Zhang. Morphling: Fast, near-optimal auto-configuration for cloud-native model serving. InProceedings of the 12th ACM Symposium on Cloud Computing, pages 639–653, 2021
2021
-
[18]
Revisiting SLO and goodput metrics in LLM serving.arXiv preprint arXiv:2410.14257, 2024
Zhibin Wang, Shipeng Li, Yuhang Zhou, Xue Li, Rong Gu, Cam-Tu Nguyen, Chen Tian, and Sheng Zhong. Revisiting SLO and goodput metrics in LLM serving.arXiv preprint arXiv:2410.14257, 2024. 18
-
[19]
Orca: A distributed serving system for transformer-based generative models
Gyeong-In Yu, Jeongmin Jeong, Gunho Kim, Soojeong Shin, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative models. In16th USENIX Symposium on Operating Systems Design and Implementation, pages 521–538, 2022
2022
-
[20]
Gonzalez, and Ion Stoica
Lianmin Zheng, Zhen Jia, Minmin Sun, Sheng Wu, Juncen Yu, Ameer Haj-Ali, Yida Wang, Jie Yang, Danyang Zhuo, Kaushik Sen, Joseph E. Gonzalez, and Ion Stoica. Alpa: Automating inter- and intra-operator parallelism for distributed deep learning. In16th USENIX Symposium on Operating Systems Design and Implementation, pages 559–578, 2022
2022
-
[21]
Distserve: Disaggregating prefill and decoding for goodput- optimized large language model serving.arXiv preprint, 2024
Yongkang Zhong et al. Distserve: Disaggregating prefill and decoding for goodput- optimized large language model serving.arXiv preprint, 2024. Verify final bibliographic details before submission. A Per-seed summaries Tables 3 and 4 expand the aggregate statistics to the per-seed level. With only five seeds, the reader should be able to see every point th...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.