Recognition: unknown
Copy First, Translate Later: Interpreting Translation Dynamics in Multilingual Pretraining
Pith reviewed 2026-05-10 05:33 UTC · model grok-4.3
The pith
In multilingual pretraining, models first copy tokens before developing general translation abilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We find that the model quickly acquires basic linguistic capabilities in parallel with token-level copying, while translation develops in two distinct phases: an initial phase dominated by copying and surface-level similarities, and a second phase in which more generalizing translation mechanisms are developed while copying is refined.
What carries the argument
The two-phase trajectory of translation acquisition, traced via behavioral analyses, model-component inspections, and parameter-based ablations on fine-grained checkpoints of a 1.7B multilingual model with a novel word-level translation dataset.
Load-bearing premise
The behavioral analyses, model-component inspections, and parameter-based ablations on the chosen checkpoints and novel dataset accurately isolate translation dynamics from confounding factors such as data overlap or model architecture specifics.
What would settle it
Pretraining an equivalent model on languages with no surface-level word similarities between them and checking whether the initial copying-dominated translation phase disappears.
Figures


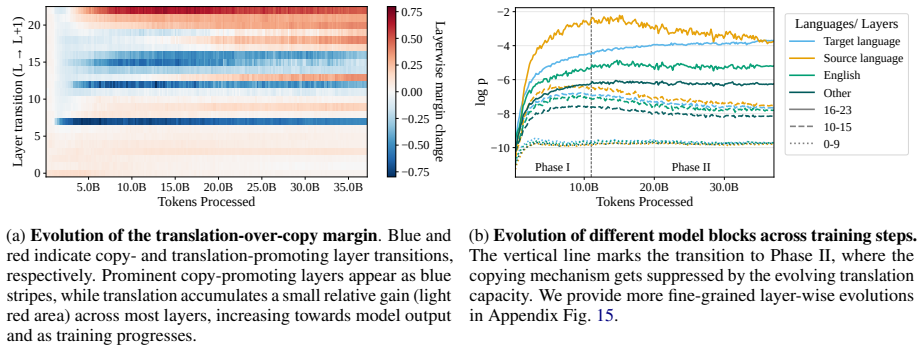
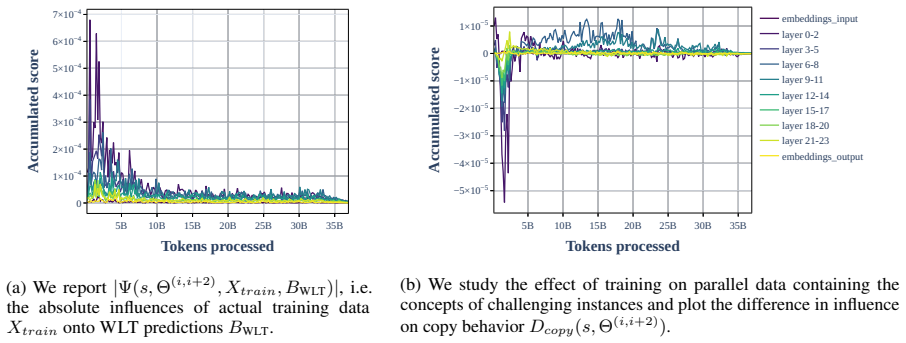
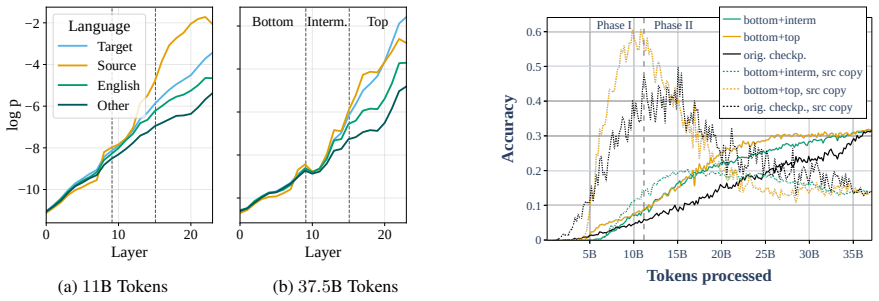



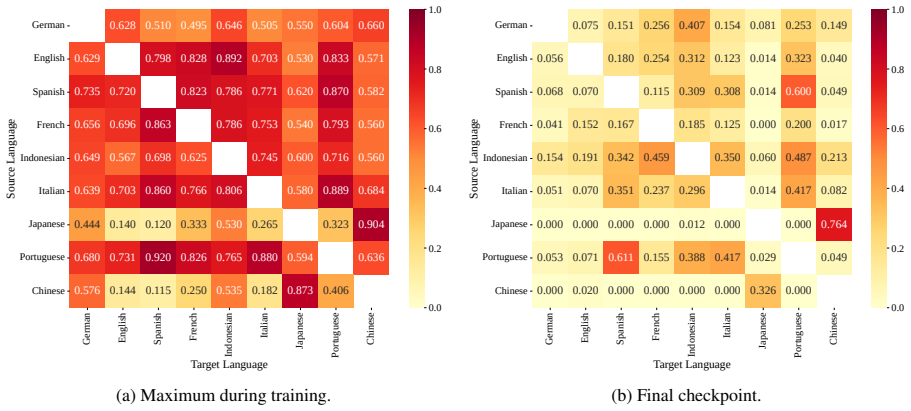

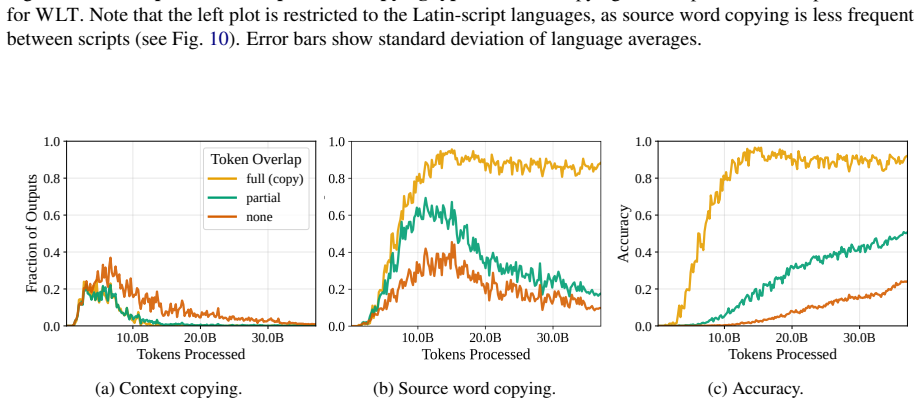
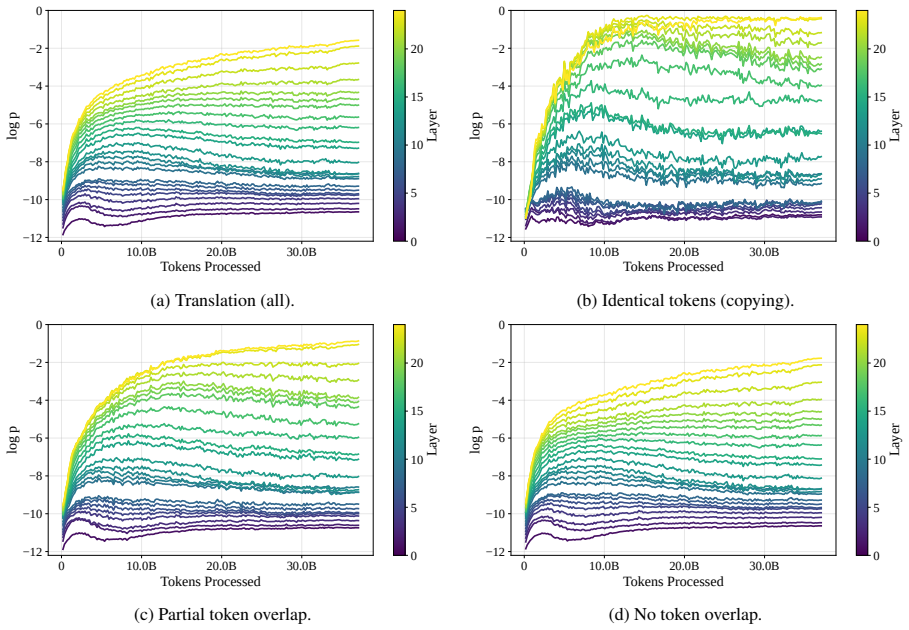
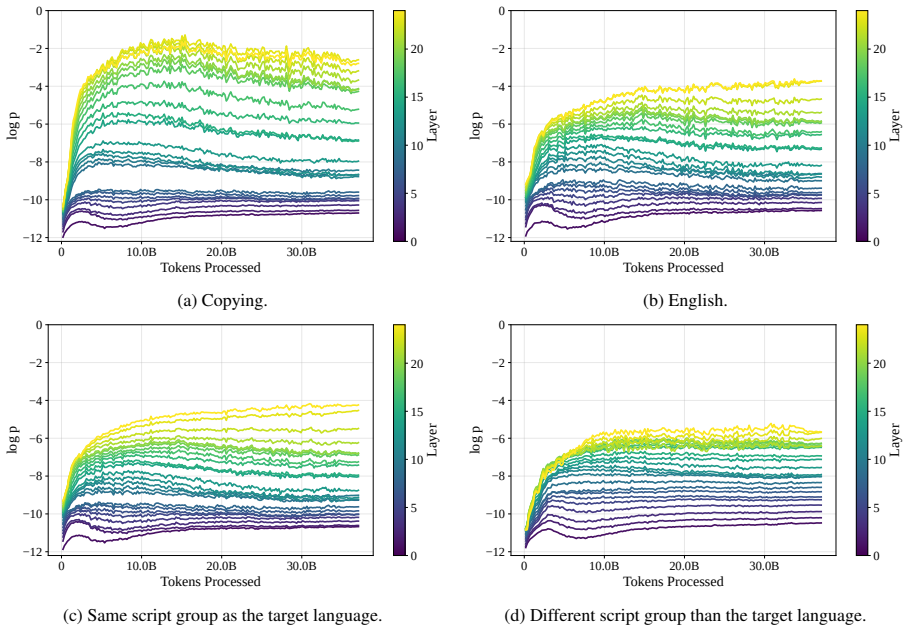
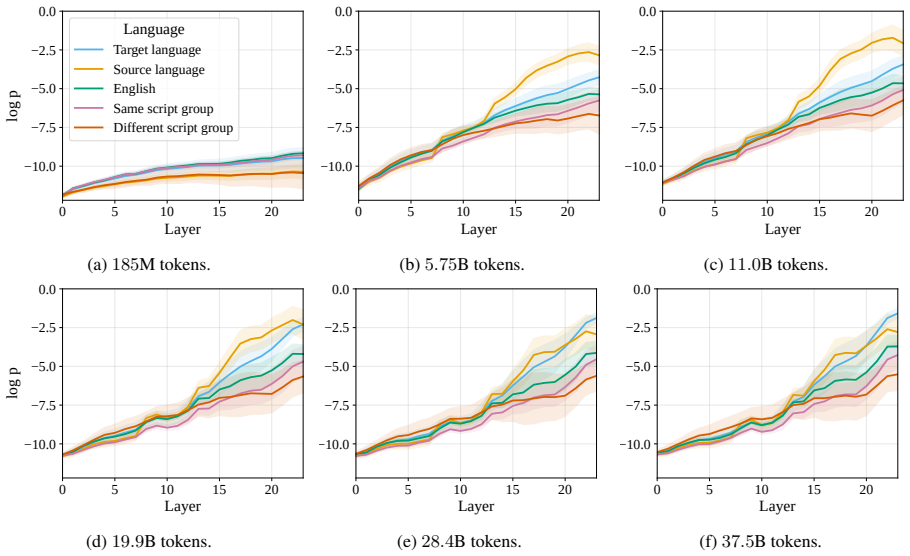
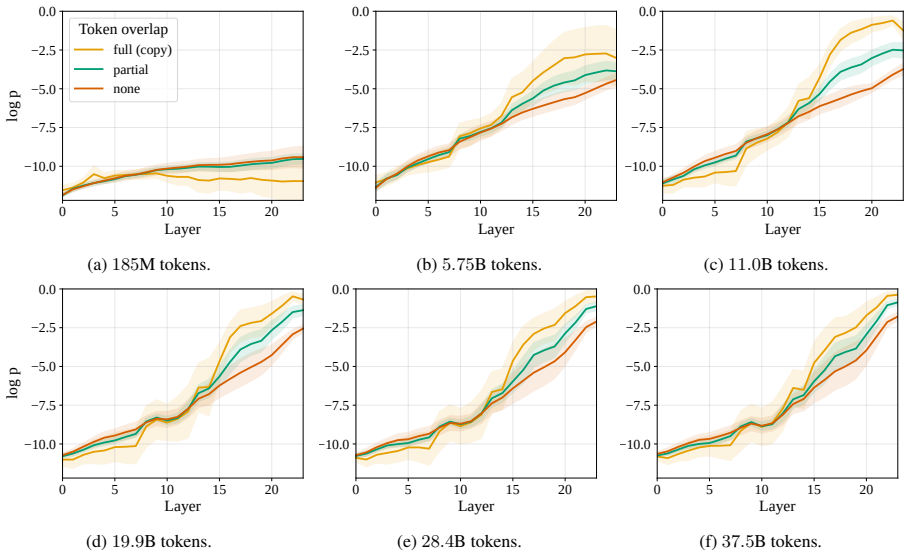
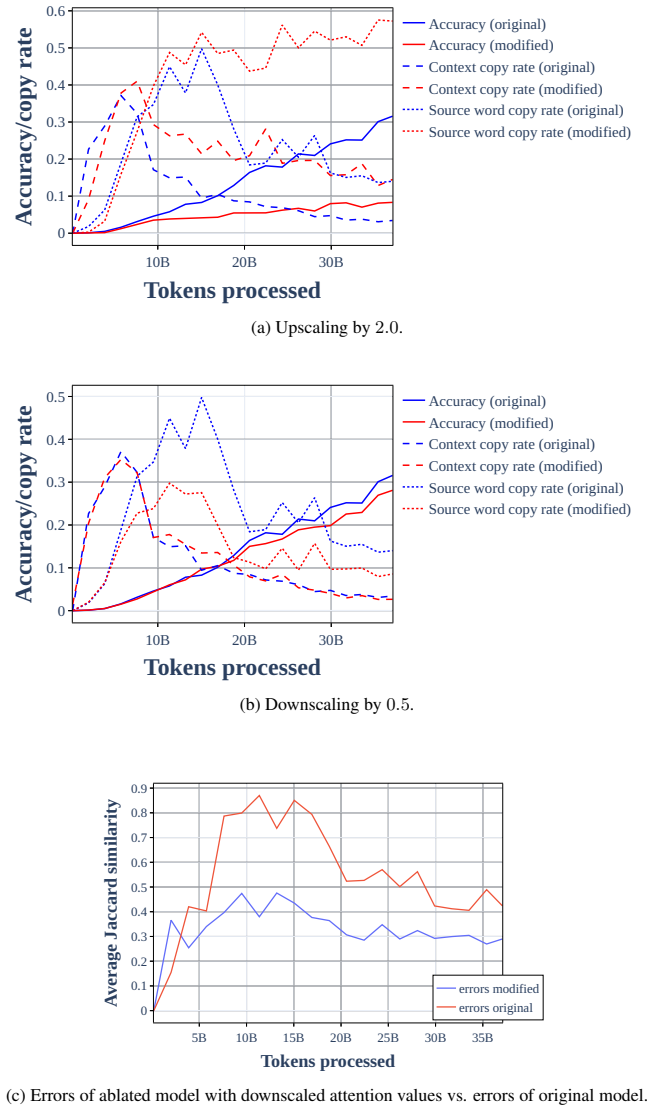
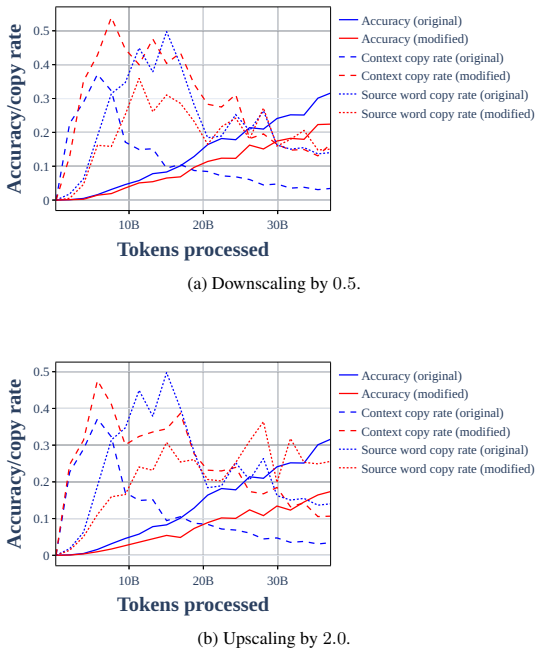

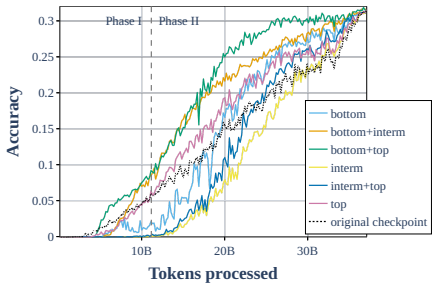
read the original abstract
Large language models exhibit impressive cross-lingual capabilities. However, prior work analyzes this phenomenon through isolated factors and at sparse points during training, limiting our understanding of how cross-lingual generalization emerges--particularly in the early phases of learning. To study the early trajectory of linguistic and translation capabilities, we pretrain a multilingual 1.7B model on nine diverse languages, capturing checkpoints at a much finer granularity. We further introduce a novel word-level translation dataset and trace how translation develops over training through behavioral analyses, model-component analysis, and parameter-based ablations. We find that the model quickly acquires basic linguistic capabilities in parallel with token-level copying, while translation develops in two distinct phases: an initial phase dominated by copying and surface-level similarities, and a second phase in which more generalizing translation mechanisms are developed while copying is refined. Together, these findings provide a fine-grained view of how cross-lingual generalization develops during multilingual pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper pretrains a 1.7B-parameter multilingual model on nine languages with fine-grained checkpoints, introduces a novel word-level translation dataset, and uses behavioral analyses, model-component inspections, and parameter-based ablations to trace the emergence of linguistic and translation capabilities. It claims that basic linguistic skills and token-level copying arise quickly in parallel, while translation proceeds in two phases: an early phase driven by copying and surface similarities, followed by a later phase of more generalizing translation mechanisms accompanied by refined copying.
Significance. If the two-phase translation dynamic is robust to confounds, the work supplies a high-resolution empirical map of cross-lingual generalization during pretraining that is currently missing from the literature. The fine-grained checkpointing, the new word-level dataset, and the combination of behavioral, representational, and ablation methods are concrete strengths that could guide future mechanistic studies of multilingual models.
major comments (3)
- [§4.2 and §5.1] §4.2 (Dataset Construction) and §5.1 (Behavioral Analyses): the manuscript does not report lexical or structural overlap statistics between the novel word-level translation pairs and the nine-language pretraining corpus. Without these controls, the early “copying-dominated” phase could be an artifact of data leakage rather than an intrinsic learning dynamic, directly undermining the two-phase claim.
- [§5.3] §5.3 (Parameter-based Ablations): the ablations remove or freeze parameters at selected checkpoints but do not intervene on the optimization schedule or learning-rate schedule. Consequently, the observed transition from surface copying to generalization may reflect training dynamics rather than the development of distinct translation mechanisms.
- [§5.2] §5.2 (Model-Component Analysis): the reported attention and representation probes are performed on a single 1.7B model without architecture-matched controls (e.g., monolingual or randomly initialized baselines). This leaves open whether the phase transition is specific to multilingual pretraining or an artifact of shared embeddings and joint optimization.
minor comments (2)
- [Abstract and §1] The abstract and §1 use “parameter-based ablations” without clarifying whether these are zero-ablation, gradient-ablation, or pruning experiments; a brief definition would improve clarity.
- [Figure 3] Figure 3 caption does not state the number of translation pairs per language pair or the exact checkpoint indices used for the phase-transition plots.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the potential strengths of our fine-grained checkpointing, new dataset, and multi-pronged analysis. We address each major comment below, indicating the revisions we will incorporate to strengthen the evidence for the two-phase translation dynamic.
read point-by-point responses
-
Referee: [§4.2 and §5.1] §4.2 (Dataset Construction) and §5.1 (Behavioral Analyses): the manuscript does not report lexical or structural overlap statistics between the novel word-level translation pairs and the nine-language pretraining corpus. Without these controls, the early “copying-dominated” phase could be an artifact of data leakage rather than an intrinsic learning dynamic, directly undermining the two-phase claim.
Authors: We agree that explicit overlap statistics are required to exclude data leakage as a potential confound. In the revised manuscript we will add a dedicated paragraph (and accompanying table) in §4.2 reporting (i) lexical overlap, measured as the percentage of exact word-form matches between the held-out translation pairs and the pretraining corpus, and (ii) structural overlap, quantified via n-gram and POS-tag overlap statistics. We will also document the curation steps taken to ensure the word-level pairs are novel relative to the training data. These additions will allow readers to directly assess whether the early copying phase reflects an intrinsic dynamic. revision: yes
-
Referee: [§5.3] §5.3 (Parameter-based Ablations): the ablations remove or freeze parameters at selected checkpoints but do not intervene on the optimization schedule or learning-rate schedule. Consequently, the observed transition from surface copying to generalization may reflect training dynamics rather than the development of distinct translation mechanisms.
Authors: The referee correctly observes that the ablations preserve the original optimization and learning-rate schedules. The design isolates the functional contribution of parameters at different stages while keeping all other training factors fixed; the phase transition itself is first documented in the unablated training trajectory. In the revision we will expand §5.3 with an explicit discussion of the cosine learning-rate schedule, noting that the observed behavioral shift occurs during a smooth portion of the schedule rather than at any discontinuity. We will also add a short paragraph clarifying why the ablation results cannot be explained solely by schedule effects. A full schedule-intervention experiment is computationally prohibitive at 1.7 B scale, but the added discussion will tighten the mechanistic interpretation. revision: partial
-
Referee: [§5.2] §5.2 (Model-Component Analysis): the reported attention and representation probes are performed on a single 1.7B model without architecture-matched controls (e.g., monolingual or randomly initialized baselines). This leaves open whether the phase transition is specific to multilingual pretraining or an artifact of shared embeddings and joint optimization.
Authors: We acknowledge that architecture-matched controls would further isolate multilingual-specific effects. Our component analyses focus on patterns (cross-lingual attention heads, representation alignment) that only arise under joint multilingual optimization; a randomly initialized model produces no structured representations, and a monolingual model cannot exhibit translation. In the revised manuscript we will add a brief comparison subsection that contrasts the observed attention patterns with those reported for monolingual models in the literature and will include a small-scale monolingual control run (same architecture, single language) to demonstrate the absence of cross-lingual generalization. These additions will strengthen the claim that the two-phase dynamic is tied to multilingual pretraining. revision: partial
Circularity Check
No circularity: purely empirical observational study
full rationale
The paper describes an empirical workflow: pretraining a 1.7B multilingual model on nine languages, saving fine-grained checkpoints, constructing a novel word-level translation dataset, and performing behavioral analyses, component inspections, and parameter ablations. No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text or abstract. Claims about two translation phases rest on direct observation of model behavior across training, not on any reduction to inputs by construction. This matches the default non-circular case for empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavioral probes, component analyses, and ablations on model checkpoints accurately reflect the emergence of translation capabilities without major artifacts from training dynamics or data selection.
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
When Meanings Meet: Investigating the Emergence and Quality of Shared Concept Spaces during Multilingual Language Model Training , author=. 2026 , eprint=
2026
-
[2]
2025 , eprint=
ExPLAIND: Unifying Model, Data, and Training Attribution to Study Model Behavior , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
MultiBLiMP 1.0: A Massively Multilingual Benchmark of Linguistic Minimal Pairs , author=. 2025 , eprint=
2025
-
[4]
Warstadt, Alex and Parrish, Alicia and Liu, Haokun and Mohananey, Anhad and Peng, Wei and Wang, Sheng-Fu and Bowman, Samuel R. , title =. Transactions of the Association for Computational Linguistics , volume =. 2020 , doi =. https://doi.org/10.1162/tacl_a_00321 , abstract =
-
[5]
M. Subspace Chronicles: How Linguistic Information Emerges, Shifts and Interacts during Language Model Training. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.879
-
[6]
2025 , eprint=
PolyPythias: Stability and Outliers across Fifty Language Model Pre-Training Runs , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
Do Multilingual LLMs Think In English? , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
The Translation Barrier Hypothesis: Multilingual Generation with Large Language Models Suffers from Implicit Translation Failure , author=. 2025 , eprint=
2025
-
[9]
Tezuka, Hinata and Inoue, Naoya. The Transfer Neurons Hypothesis: An Underlying Mechanism for Language Latent Space Transitions in Multilingual LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1618
-
[10]
2024 , eprint=
One Mind, Many Tongues: A Deep Dive into Language-Agnostic Knowledge Neurons in Large Language Models , author=. 2024 , eprint=
2024
-
[11]
Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
Stanczak, Karolina and Ponti, Edoardo and Torroba Hennigen, Lucas and Cotterell, Ryan and Augenstein, Isabelle. Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi...
-
[12]
URL https: //aclanthology.org/2024.acl-long.309/
Tang, Tianyi and Luo, Wenyang and Huang, Haoyang and Zhang, Dongdong and Wang, Xiaolei and Zhao, Xin and Wei, Furu and Wen, Ji-Rong. Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1...
-
[13]
Kojima, Takeshi and Okimura, Itsuki and Iwasawa, Yusuke and Yanaka, Hitomi and Matsuo, Yutaka. On the Multilingual Ability of Decoder-based Pre-trained Language Models: Finding and Controlling Language-Specific Neurons. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[14]
Unraveling B abel: Exploring Multilingual Activation Patterns of LLM s and Their Applications
Liu, Weize and Xu, Yinlong and Xu, Hongxia and Chen, Jintai and Hu, Xuming and Wu, Jian. Unraveling B abel: Exploring Multilingual Activation Patterns of LLM s and Their Applications. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.662
-
[15]
2025 , eprint=
Cross-Lingual Generalization and Compression: From Language-Specific to Shared Neurons , author=. 2025 , eprint=
2025
-
[16]
2022 , eprint=
Analyzing the Mono- and Cross-Lingual Pretraining Dynamics of Multilingual Language Models , author=. 2022 , eprint=
2022
-
[17]
Wang, Mingyang and Adel, Heike and Lange, Lukas and Liu, Yihong and Nie, Ercong and Str. Lost in Multilinguality: Dissecting Cross-lingual Factual Inconsistency in Transformer Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.253
-
[18]
2025 , eprint=
Tracing Multilingual Factual Knowledge Acquisition in Pretraining , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Hidden Breakthroughs in Language Model Training , author=. 2025 , eprint=
2025
-
[21]
Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline
Lu, Meng and Zhang, Ruochen and Eickhoff, Carsten and Pavlick, Ellie. Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.762
-
[22]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
2020
-
[23]
interpreting GPT: the logit lens , author=
-
[24]
GOOGLETRANSLATE Function , author =
-
[25]
2025 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2025 , eprint=
2025
-
[26]
B abel N et: Building a Very Large Multilingual Semantic Network
Navigli, Roberto and Ponzetto, Simone Paolo. B abel N et: Building a Very Large Multilingual Semantic Network. Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. 2010
2010
-
[27]
Language
Deletang, Gregoire and Ruoss, Anian and Duquenne, Paul-Ambroise and Catt, Elliot and Genewein, Tim and Mattern, Christopher and. Language. The
-
[28]
Second Conference on Language Modeling , year=
The Dual-Route Model of Induction , author=. Second Conference on Language Modeling , year=
-
[30]
Opening the. doi:10.48550/arXiv.1703.00810 , url =. arXiv , keywords =:1703.00810 , primaryclass =
-
[31]
Enhancing Multilingual
Bettina Messmer and Vinko Sabol. Enhancing Multilingual. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[32]
arXiv , year=
Enhancing Multilingual LLM Pretraining with Model-Based Data Selection , author=. arXiv , year=
-
[33]
Advances in Neural Information Processing Systems , author =
-
[34]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[35]
2025 , eprint=
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments , author=. 2025 , eprint=
2025
-
[36]
Mistral NeMo , author =
-
[37]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , year =. Attention. doi:10.48550/arXiv.1706.03762 , urldate =. arXiv , keywords =:1706.03762 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762
-
[38]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[39]
The Smol Training Playbook: The Secrets to Building World-Class LLMs , author=
-
[40]
2025 , eprint=
EuroLLM-9B: Technical Report , author=. 2025 , eprint=
2025
-
[41]
Wei Qi Leong and Jian Gang Ngui and Yosephine Susanto and Hamsawardhini Rengarajan and Kengatharaiyer Sarveswaran and William. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2309.06085 , eprinttype =. 2309.06085 , timestamp =
-
[42]
Yikang Liu and Yeting Shen and Hongao Zhu and Lilong Xu and Zhiheng Qian and Siyuan Song and Kejia Zhang and Jialong Tang and Pei Zhang and Baosong Yang and Rui Wang and Hai Hu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.06096 , eprinttype =. 2411.06096 , timestamp =
-
[43]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu and Yuge Tu and Xu Han and Chaoqun He and Ganqu Cui and Xiang Long and Zhi Zheng and Yewei Fang and Yuxiang Huang and Weilin Zhao and Xinrong Zhang and Zhen Leng Thai and Kai Zhang and Chongyi Wang and Yuan Yao and Chenyang Zhao and Jie Zhou and Jie Cai and Zhongwu Zhai and Ning Ding and Chao Jia and Guoyang Zeng and Dahai Li and Zhiyuan Liu ...
work page internal anchor Pith review doi:10.48550/arxiv.2404.06395 2024
-
[44]
ArXiv , year=
ChiKhaPo: A Large-Scale Multilingual Benchmark for Evaluating Lexical Comprehension and Generation in Large Language Models , author=. ArXiv , year=
-
[45]
Annual Meeting of the Association for Computational Linguistics , year=
NLTK: The Natural Language Toolkit , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[46]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[47]
Proceedings of The 1st Transfer Learning for Natural Language Processing Workshop , pages =
Languages You Know Influence Those You Learn: Impact of Language Characteristics on Multi-Lingual Text-to-Text Transfer , author =. Proceedings of The 1st Transfer Learning for Natural Language Processing Workshop , pages =. 2023 , editor =
2023
-
[48]
2025 , eprint=
The Multilingual Divide and Its Impact on Global AI Safety , author=. 2025 , eprint=
2025
-
[49]
2022 , month =
Saphra, Naomi , title =. 2022 , month =
2022
-
[50]
The Twelfth International Conference on Learning Representations , year=
What's In My Big Data? , author=. The Twelfth International Conference on Learning Representations , year=
-
[51]
, author=
The dominance analysis approach for comparing predictors in multiple regression. , author=. Psychological methods , volume=. 2003 , publisher=
2003
-
[52]
2024 , cdate=
Yiran Zhao and Wenxuan Zhang and Guizhen Chen and Kenji Kawaguchi and Lidong Bing , title=. 2024 , cdate=
2024
-
[53]
2024 , eprint=
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier , author=. 2024 , eprint=
2024
-
[54]
2020 , eprint=
Beyond English-Centric Multilingual Machine Translation , author=. 2020 , eprint=
2020
-
[55]
2023 , eprint=
MADLAD-400: A Multilingual And Document-Level Large Audited Dataset , author=. 2023 , eprint=
2023
-
[56]
2022 , eprint=
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. 2022 , eprint=
2022
-
[57]
Ryan Wong, Necati Cihan Camgoz, and Richard Bow- den
Yuqing Tang and Chau Tran and Xian Li and Peng. Multilingual Translation with Extensible Multilingual Pretraining and Finetuning , journal =. 2020 , url =. 2008.00401 , timestamp =
-
[58]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2211.05100 , eprinttype =. 2211.05100 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2211.05100 2022
-
[59]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[60]
CoRR , volume=
Lucas Bandarkar and Benjamin Muller and Pritish Yuvraj and Rui Hou and Nayan Singhal and Hongjiang Lv and Bing Liu , title=. CoRR , volume=. 2024 , cdate=
2024
-
[61]
The Unreasonable Effectiveness of Model Merging for Cross-Lingual Transfer in LLM s
Bandarkar, Lucas and Peng, Nanyun. The Unreasonable Effectiveness of Model Merging for Cross-Lingual Transfer in LLM s. Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025). 2025. doi:10.18653/v1/2025.mrl-main.10
-
[62]
Beyond Data Quantity: Key Factors Driving Performance in Multilingual Language Models
Bagheri Nezhad, Sina and Agrawal, Ameeta and Pokharel, Rhitabrat. Beyond Data Quantity: Key Factors Driving Performance in Multilingual Language Models. Proceedings of the First Workshop on Language Models for Low-Resource Languages. 2025
2025
-
[63]
False F riends Are Not Foes: Investigating Vocabulary Overlap in Multilingual Language Models
Kallini, Julie and Jurafsky, Dan and Potts, Christopher and Bartelds, Martijn. False F riends Are Not Foes: Investigating Vocabulary Overlap in Multilingual Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1153
-
[64]
Converging to a Lingua Franca: Evolution of Linguistic Regions and Semantics Alignment in Multilingual Large Language Models
Zeng, Hongchuan and Han, Senyu and Chen, Lu and Yu, Kai. Converging to a Lingua Franca: Evolution of Linguistic Regions and Semantics Alignment in Multilingual Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[65]
Cross-Lingual Generalization and Compression: From Language-Specific to Shared Neurons
Riemenschneider, Frederick and Frank, Anette. Cross-Lingual Generalization and Compression: From Language-Specific to Shared Neurons. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.661
-
[66]
Dumas, Cl \'e ment and Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/20...
-
[67]
Kondo, Minato and Utsuro, Takehito and Nagata, Masaaki. Enhancing Translation Accuracy of Large Language Models through Continual Pre-Training on Parallel Data. Proceedings of the 21st International Conference on Spoken Language Translation (IWSLT 2024). 2024. doi:10.18653/v1/2024.iwslt-1.26
-
[68]
Understanding Cross-Lingual A lignment --- A Survey
H. Understanding Cross-Lingual A lignment --- A Survey. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.649
-
[69]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[70]
JBL i MP : J apanese Benchmark of Linguistic Minimal Pairs
Someya, Taiga and Oseki, Yohei. JBL i MP : J apanese Benchmark of Linguistic Minimal Pairs. Findings of the Association for Computational Linguistics: EACL 2023. 2023. doi:10.18653/v1/2023.findings-eacl.117
-
[71]
Limisiewicz, Tomasz and Balhar, Ji r \'i and Mare c ek, David. Tokenization Impacts Multilingual Language Modeling: Assessing Vocabulary Allocation and Overlap Across Languages. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.350
-
[72]
Philippy, Fred and Guo, Siwen and Haddadan, Shohreh. Towards a Common Understanding of Contributing Factors for Cross-Lingual Transfer in Multilingual Language Models: A Review. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.323
-
[73]
Briakou, Eleftheria and Cherry, Colin and Foster, George. Searching for Needles in a Haystack: On the Role of Incidental Bilingualism in P a LM ' s Translation Capability. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.524
-
[74]
Language Contamination Helps Explains the Cross-lingual Capabilities of E nglish Pretrained Models
Blevins, Terra and Zettlemoyer, Luke. Language Contamination Helps Explains the Cross-lingual Capabilities of E nglish Pretrained Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.233
-
[75]
Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages
Patil, Vaidehi and Talukdar, Partha and Sarawagi, Sunita. Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.18
-
[76]
OPUS - MT -- Building open translation services for the World
Tiedemann, J. OPUS - MT -- Building open translation services for the World. Proceedings of the 22nd Annual Conference of the European Association for Machine Translation. 2020
2020
-
[77]
Beto, bentz, becas: The surprising cross-lingual effectiveness of BERT
Wu, Shijie and Dredze, Mark. Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1077
-
[78]
Learning Word Vectors for 157 Languages
Grave, Edouard and Bojanowski, Piotr and Gupta, Prakhar and Joulin, Armand and Mikolov, Tomas. Learning Word Vectors for 157 Languages. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.