Recognition: unknown
Prosody as Supervision: Bridging the Non-Verbal--Verbal for Multilingual Speech Emotion Recognition
Pith reviewed 2026-05-10 04:39 UTC · model grok-4.3
The pith
Non-verbal vocalizations can provide supervision for recognizing emotions in verbal speech across languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NOVA-ARC models affective structure in the Poincaré ball, discretizes paralinguistic patterns via a hyperbolic vector-quantized prosody codebook, and captures emotion intensity through a hyperbolic emotion lens. For adaptation, it performs optimal transport based prototype alignment between source emotion prototypes and target utterances to induce soft supervision.
What carries the argument
The NOVA-ARC framework, which uses hyperbolic geometry in the Poincaré ball for prosody codebook discretization and optimal transport for cross-domain prototype alignment.
If this is right
- It consistently outperforms Euclidean geometry versions and strong self-supervised learning baselines in non-verbal-to-verbal adaptation.
- It also shows strong results in the verbal-to-verbal transfer setting.
- It stabilizes the adaptation process through consistency regularization while providing soft labels for unlabeled speech.
- By moving beyond verbal-speech-centric supervision, it opens a new paradigm for low-resource multilingual SER.
Where Pith is reading between the lines
- This could lower the barrier for building emotion-aware applications in under-resourced languages by relying on more universal non-verbal signals.
- Future work might test whether the same hyperbolic alignment works for other paralinguistic tasks like detecting sarcasm or speaker intent.
- Applying the method to real-world noisy recordings would check how robust the prosody cues remain outside controlled datasets.
Load-bearing premise
Non-verbal vocalizations hold prosody-based emotion information that can be aligned to verbal speech in different languages without losing important details.
What would settle it
A controlled test showing that removing the hyperbolic geometry or the optimal transport step causes performance to drop to the level of standard Euclidean methods on the same multilingual datasets.
Figures

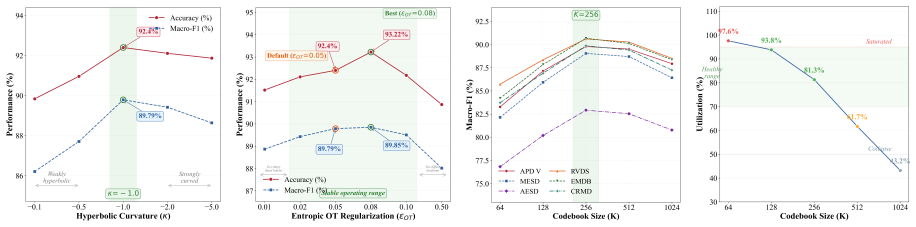


read the original abstract
In this work, we introduce a paralinguistic supervision paradigm for low-resource multilingual speech emotion recognition (LRM-SER) that leverages non-verbal vocalizations to exploit prosody-centric emotion cues. Unlike conventional SER systems that rely heavily on labeled verbal speech and suffer from poor cross-lingual transfer, our approach reformulates LRM-SER as non-verbal-to-verbal transfer, where supervision from a labeled non-verbal source domain is adapted to unlabeled verbal speech across multiple target languages. To this end, we propose NOVA ARC, a geometry-aware framework that models affective structure in the Poincar\'e ball, discretizes paralinguistic patterns via a hyperbolic vector-quantized prosody codebook, and captures emotion intensity through a hyperbolic emotion lens. For unsupervised adaptation, NOVA-ARC performs optimal transport based prototype alignment between source emotion prototypes and target utterances, inducing soft supervision for unlabeled speech while being stabilized through consistency regularization. Experiments show that NOVA-ARC delivers the strongest performance under both non-verbal-to-verbal adaptation and the complementary verbal-to-verbal transfer setting, consistently outperforming Euclidean counterparts and strong SSL baselines. To the best of our knowledge, this work is the first to move beyond verbal-speech-centric supervision by introducing a non-verbal-to-verbal transfer paradigm for SER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NOVA-ARC, a geometry-aware framework for low-resource multilingual speech emotion recognition that reformulates the task as non-verbal-to-verbal transfer. It models affective structure in the Poincaré ball, discretizes paralinguistic patterns with a hyperbolic vector-quantized prosody codebook, captures emotion intensity via a hyperbolic emotion lens, and performs unsupervised adaptation through optimal transport prototype alignment stabilized by consistency regularization. Experiments are reported to show that NOVA-ARC achieves the strongest performance in both non-verbal-to-verbal adaptation and verbal-to-verbal transfer, outperforming Euclidean counterparts and strong SSL baselines, and the work claims to be the first to introduce this non-verbal-to-verbal paradigm for SER.
Significance. If the results hold, the work has moderate significance for advancing low-resource and cross-lingual SER by shifting supervision to non-verbal vocalizations, which may be more abundant and less language-dependent. The application of hyperbolic geometry and optimal transport to induce soft labels from prosody cues is a coherent technical extension of existing tools to a new setting, and the dual evaluation on non-verbal-to-verbal plus verbal-to-verbal transfer provides a useful benchmark. Reproducible code or detailed ablations would strengthen the contribution.
major comments (2)
- [§3] §3 (Method): The hyperbolic emotion lens is introduced as capturing intensity but its exact formulation, parameterization, and integration with the VQ codebook are not specified in sufficient detail to determine whether it adds expressive power beyond standard hyperbolic embeddings or simply reparameterizes existing intensity modeling.
- [§4] §4 (Experiments): The claim that NOVA-ARC 'delivers the strongest performance' and 'consistently outperforming' baselines requires the specific datasets, languages, metrics (e.g., UA, WA, F1), number of runs, and statistical significance tests; without these the magnitude and reliability of the reported gains cannot be assessed.
minor comments (2)
- [Abstract] Abstract: The acronym NOVA-ARC is used without expansion; provide the full name on first use.
- [Related Work] Related Work: A more explicit contrast with prior uses of hyperbolic embeddings or optimal transport in SER or paralinguistics would clarify the precise novelty of the geometry-aware components.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, with proposed revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3] §3 (Method): The hyperbolic emotion lens is introduced as capturing intensity but its exact formulation, parameterization, and integration with the VQ codebook are not specified in sufficient detail to determine whether it adds expressive power beyond standard hyperbolic embeddings or simply reparameterizes existing intensity modeling.
Authors: We thank the referee for highlighting this. We agree that the current description of the hyperbolic emotion lens in Section 3 lacks sufficient mathematical detail. In the revised manuscript we will expand the relevant subsection to include: (i) the exact formulation as a radial intensity modulator within the Poincaré ball, (ii) the parameterization (learnable intensity scalar combined with hyperbolic distance-based mapping), and (iii) its integration with the VQ prosody codebook through the joint loss that couples reconstruction, quantization, and emotion supervision objectives. This will explicitly show how the lens contributes geometry-aware intensity modeling beyond standard hyperbolic embeddings. revision: yes
-
Referee: [§4] §4 (Experiments): The claim that NOVA-ARC 'delivers the strongest performance' and 'consistently outperforming' baselines requires the specific datasets, languages, metrics (e.g., UA, WA, F1), number of runs, and statistical significance tests; without these the magnitude and reliability of the reported gains cannot be assessed.
Authors: We agree that the experimental claims require more explicit supporting details for reproducibility and assessment. In the revised manuscript we will add a consolidated table in Section 4 that enumerates all datasets (non-verbal vocalization source corpora and multilingual verbal target datasets), languages covered, evaluation metrics (unweighted accuracy, weighted accuracy, and F1), number of independent runs (with random seeds), and statistical significance results (e.g., paired t-tests or McNemar’s tests against baselines). This will allow direct evaluation of the reported performance gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical framework (NOVA-ARC) that applies standard tools—Poincaré-ball geometry, hyperbolic VQ codebook, optimal transport prototype alignment, and consistency regularization—to the non-verbal-to-verbal transfer setting for multilingual SER. No equations, derivations, or self-citations are shown that reduce any claimed result to fitted parameters or prior outputs by construction. Performance claims rest on experimental comparisons against baselines rather than on any load-bearing self-referential step. The derivation chain is therefore self-contained and externally falsifiable via the reported metrics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hyperbolic space (Poincaré ball) provides a superior geometry for modeling emotion intensity and prosodic patterns compared to Euclidean space.
- domain assumption Non-verbal vocalizations contain prosody-centric emotion cues that are transferable to verbal speech across languages.
invented entities (2)
-
Hyperbolic vector-quantized prosody codebook
no independent evidence
-
Hyperbolic emotion lens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Large-Scale Nonverbal Vocalization Detection Using Transformers , year=
Tzirakis, Panagiotis and Baird, Alice and Brooks, Jeffrey and Gagne, Christopher and Kim , booktitle=. Large-Scale Nonverbal Vocalization Detection Using Transformers , year=
-
[9]
Designing and Evaluating Speech Emotion Recognition Systems: A Reality Check Case Study with IEMOCAP , year=
Antoniou, Nikolaos and Katsamanis, Athanasios and Giannakopoulos, Theodoros and Narayanan, Shrikanth , booktitle=. Designing and Evaluating Speech Emotion Recognition Systems: A Reality Check Case Study with IEMOCAP , year=
-
[10]
Liebenthal, Einat and Silbersweig, David A. and Stern, Emily , TITLE=. Frontiers in Neuroscience , VOLUME=. 2016 , URL=. doi:10.3389/fnins.2016.00506 , ISSN=
-
[11]
Tracy and Dacher Keltner , title =
Alan Cowen and Disa Sauter and Jessica L. Tracy and Dacher Keltner , title =. Psychological Science in the Public Interest , volume =. 2019 , doi =
2019
-
[12]
The impact of speech impairment in early childhood: Investigating parents’ and speech-language pathologists’ perspectives using the ICF-CY , journal =. 2010 , issn =. doi:https://doi.org/10.1016/j.jcomdis.2010.04.009 , url =
-
[13]
doi:10.21437/Interspeech.2025-1006 , issn =
Ziwei Gong and Pengyuan Shi and Kaan Donbekci and Lin Ai and Run Chen and David Sasu and Zehui Wu and Julia Hirschberg , year =. doi:10.21437/Interspeech.2025-1006 , issn =
-
[14]
doi:10.21437/Interspeech.2025-2123 , issn =
Pravin Mote and Donita Robinson and Elizabeth Richerson and Carlos Busso , year =. doi:10.21437/Interspeech.2025-2123 , issn =
-
[15]
Upadhyay and Carlos Busso and Chi-Chun Lee , year =
Shreya G. Upadhyay and Carlos Busso and Chi-Chun Lee , year =. doi:10.21437/Interspeech.2024-469 , issn =
-
[16]
Multi-Lingual Multi-Task Speech Emotion Recognition Using wav2vec 2.0 , year=
Sharma, Mayank , booktitle=. Multi-Lingual Multi-Task Speech Emotion Recognition Using wav2vec 2.0 , year=
-
[17]
Cross-Lingual Speech Emotion Recognition: Humans vs
Han, Zhichen and Geng, Tianqi and Feng, Hui and Yuan, Jiahong and Richmond, Korin and Li, Yuanchao , booktitle=. Cross-Lingual Speech Emotion Recognition: Humans vs. Self-Supervised Models , year=
-
[18]
Strong Alone, Stronger Together: Synergizing Modality-Binding Foundation Models with Optimal Transport for Non-Verbal Emotion Recognition , year=
Phukan, Orchid Chetia and Mujtaba Akhtar, Mohd and Girish and Ranjan Behera, Swarup and Kalita, Sishir and Buduru, Arun Balaji and Sharma, Rajesh and Prasanna, S.R Mahadeva , booktitle=. Strong Alone, Stronger Together: Synergizing Modality-Binding Foundation Models with Optimal Transport for Non-Verbal Emotion Recognition , year=
-
[19]
Shah, Siddhant Bikram and Johnson, Kristina T. N- CORE : N-View Consistency Regularization for Disentangled Representation Learning in Nonverbal Vocalizations. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1693
-
[20]
Global Scientific Journals , volume=
ASVP-ESD: A dataset and its benchmark for emotion recognition using both speech and non-speech utterances , author=. Global Scientific Journals , volume=
-
[21]
and Alonso-Valerdi, Luz M
Duville, Mathilde M. and Alonso-Valerdi, Luz M. and Ibarra-Zarate, David I. , booktitle=. The Mexican Emotional Speech Database (MESD): elaboration and assessment based on machine learning , year=
-
[22]
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English , year =. PLOS ONE , publisher =. doi:10.1371/journal.pone.0196391 , author =
-
[23]
A database of German emotional speech , author =. 2005 , booktitle =. doi:10.21437/Interspeech.2005-446 , issn =
-
[24]
and Keutmann, Michael K
Cao, Houwei and Cooper, David G. and Keutmann, Michael K. and Gur, Ruben C. and Nenkova, Ani and Verma, Ragini , journal=. CREMA-D: Crowd-Sourced Emotional Multimodal Actors Dataset , year=
-
[25]
Speech Emotion Recognition for Performance Interaction , volume =
Vryzas, Nikolaos and Kotsakis, Rigas and Liatsou, Aikaterini and Dimoulas, Charalampos and Kalliris, George , year =. Speech Emotion Recognition for Performance Interaction , volume =. Journal of the Audio Engineering Society. Audio Engineering Society , doi =
-
[26]
Journal of Machine Learning Research , volume=
Scaling speech technology to 1,000+ languages , author=. Journal of Machine Learning Research , volume=
-
[27]
IEEE Journal of Selected Topics in Signal Processing , volume=
Wavlm: Large-scale self-supervised pre-training for full stack speech processing , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[28]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[29]
voc2vec: A Foundation Model for Non-Verbal Vocalization , year=
Koudounas, Alkis and La Quatra, Moreno and Siniscalchi, Sabato Marco and Baralis, Elena , booktitle=. voc2vec: A Foundation Model for Non-Verbal Vocalization , year=
-
[30]
doi:10.21437/Interspeech.2024-1248 , issn =
Pravin Mote and Berrak Sisman and Carlos Busso , year =. doi:10.21437/Interspeech.2024-1248 , issn =
-
[31]
Unsupervised Adversarial Domain Adaptation for Cross-Lingual Speech Emotion Recognition , year=
Latif, Siddique and Qadir, Junaid and Bilal, Muhammad , booktitle=. Unsupervised Adversarial Domain Adaptation for Cross-Lingual Speech Emotion Recognition , year=
-
[32]
doi:10.21437/Interspeech.2025-2191 , issn =
Orchid Chetia Phukan and Girish and Mohd Mujtaba Akhtar and Swarup Ranjan Behera and Pailla Balakrishna Reddy and Arun Balaji Buduru and Rajesh Sharma , year =. doi:10.21437/Interspeech.2025-2191 , issn =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.