Recognition: unknown
Measuring Distribution Shift in User Prompts and Its Effects on LLM Performance
Pith reviewed 2026-05-10 05:23 UTC · model grok-4.3
The pith
Moderate shifts in how users prompt LLMs produce 73 percent average performance losses in real deployments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
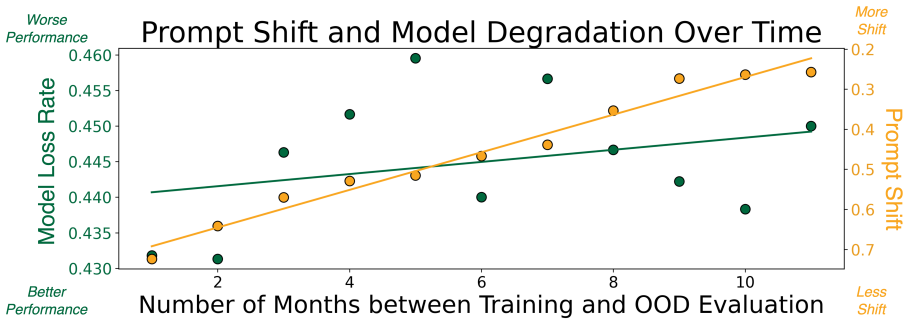
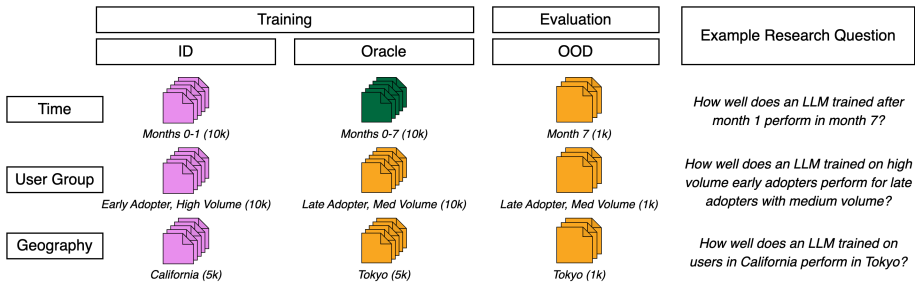
The LENS framework quantifies natural prompt distribution shift in 192 post-deployment settings over time, user groups, and geography. It trains 81 models on 4.68 million prompts and evaluates them on 57.6 thousand test prompts, establishing that even moderate shifts correspond with an average 73 percent performance loss, with stronger effects across different latent groups and regions and clear correlation to shifts over time.
What carries the argument
The LENS framework, a data-centric method that quantifies natural prompt distribution shift and measures its direct effect on LLM instruction-following performance.
Load-bearing premise
The observed performance drops are caused by prompt distribution shift rather than confounding factors such as model changes or evaluation differences.
What would settle it
A controlled deployment in which prompt distributions are deliberately held constant across groups and time while performance is tracked, or one in which prompt distributions are shifted without any corresponding performance change.
Figures





read the original abstract
LLMs are increasingly deployed in dynamic, real-world settings, where the distribution of user prompts can shift substantially over time as new tasks, prompts, and users are introduced to a deployed model. Such natural prompt distribution shift poses a major challenge to LLM reliability, particularly for specialized models designed for narrow domains or user populations. Despite attention to out-of-distribution robustness, there is very limited exploration of measuring natural prompt distribution shift in prior work, and its impact on deployed LLMs remains poorly understood. We introduce the LLM Evaluation under Natural prompt Shift (LENS) framework: a data-centric approach for quantifying natural prompt distribution shift and evaluating its effect on the performance of deployed LLMs. We perform a large-scale evaluation using 192 real-world post-deployment prompt shift settings over time, user group, and geographic axes, training a total of 81 models on 4.68M training prompts, and evaluating on 57.6k prompts. We find that even moderate shifts in user prompt behavior correspond with large performance drops (73% average loss) in deployed LLMs. This performance degradation is particularly prevalent when users from different latent groups and geographic regions interact with models and is correlated with natural prompt distribution shift over time. We systematically characterize how LLM instruction following ability degrades over time and between user groups. Our findings highlight the critical need for data-driven monitoring to ensure LLM performance remains stable across diverse and evolving user populations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the LENS framework, a data-centric method to quantify natural prompt distribution shifts in deployed LLMs along temporal, latent user group, and geographic axes. It reports results from 192 real-world post-deployment settings, 81 models trained on 4.68M prompts, and evaluation on 57.6k prompts, claiming that even moderate shifts correspond to 73% average performance loss, with stronger effects across groups and regions, and that instruction-following degrades over time in correlation with these shifts.
Significance. If the causal attribution to prompt shift can be isolated from confounders, the large-scale empirical evaluation (192 settings, millions of training prompts) would be a valuable contribution to understanding LLM reliability in production. The data-driven monitoring recommendation and characterization of degradation across user populations are practically relevant for deployment.
major comments (2)
- [Abstract and §5] Abstract and §5 (results): The central claim asserts that prompt distribution shifts cause large (73% average) performance drops, yet the experimental design in §4 does not isolate this from temporal confounders (model version updates, data collection changes, or evaluation drifts) that co-occur with time-based shifts. The abstract's wording of 'correspond with' and 'correlated with' is weaker than the asserted causal effect; without controls or counterfactual analysis, the 73% figure cannot be attributed to shift alone.
- [§4] §4 (LENS framework and experimental setup): The quantification of distribution shift and the performance metrics are not described with sufficient detail to verify the 73% loss or rule out selection effects in the 192 settings. The reader's soundness assessment notes the absence of methodology specifics, which is load-bearing because the claim rests on these measurements being unbiased natural shifts.
minor comments (2)
- [§3] Notation for 'latent groups' and 'geographic axes' should be defined explicitly on first use to avoid ambiguity in cross-setting comparisons.
- [§5] Figure captions for performance degradation plots should include error bars or confidence intervals to clarify the variability behind the 73% average.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important issues of causal language and methodological transparency that we address directly below. We have revised the manuscript to improve precision and completeness.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (results): The central claim asserts that prompt distribution shifts cause large (73% average) performance drops, yet the experimental design in §4 does not isolate this from temporal confounders (model version updates, data collection changes, or evaluation drifts) that co-occur with time-based shifts. The abstract's wording of 'correspond with' and 'correlated with' is weaker than the asserted causal effect; without controls or counterfactual analysis, the 73% figure cannot be attributed to shift alone.
Authors: We agree that stronger causal language would be inappropriate given the observational design. The manuscript deliberately employs 'correspond with' and 'correlated with' to reflect that the 73% average loss is the measured performance degradation observed alongside quantified prompt shifts in 192 real-world settings. Full isolation from all temporal confounders is not feasible in post-deployment data, as the LENS framework prioritizes ecological validity over controlled experiments. In revision we have (1) further tightened the abstract and §5 to foreground the correlational nature of the findings, (2) added an explicit limitations paragraph enumerating potential confounders (model updates, collection changes, evaluation drift) and the steps taken to mitigate them (e.g., holding model versions fixed where possible and reporting per-setting statistics), and (3) clarified that the practical recommendation is data-driven monitoring rather than a causal claim. These changes preserve the scale of the empirical evidence while aligning wording with the strength of the design. revision: yes
-
Referee: [§4] §4 (LENS framework and experimental setup): The quantification of distribution shift and the performance metrics are not described with sufficient detail to verify the 73% loss or rule out selection effects in the 192 settings. The reader's soundness assessment notes the absence of methodology specifics, which is load-bearing because the claim rests on these measurements being unbiased natural shifts.
Authors: We accept that §4 lacked sufficient granularity for independent verification. The revised manuscript expands this section with: (a) precise definitions and formulas for the distribution-shift metrics used along each axis (temporal, latent user-group, geographic), including the divergence measures and how latent groups were inferred; (b) the exact performance metric (instruction-following accuracy) and its computation on the 57.6k evaluation prompts; (c) the selection criteria and summary statistics for the 192 settings to demonstrate they represent natural rather than curated shifts; and (d) pseudocode for the overall LENS pipeline together with additional tables reporting per-axis shift magnitudes and the 73% aggregate calculation. These additions directly address concerns about selection effects and allow readers to reproduce the reported performance losses from the described protocol. revision: yes
Circularity Check
No circularity: empirical data-driven framework with no self-referential derivations
full rationale
The paper introduces the LENS framework as a data-centric method for quantifying natural prompt distribution shift across time, user groups, and geography, then reports empirical correlations from 192 real-world settings, 81 trained models, and 57.6k evaluation prompts. No equations, fitted parameters, uniqueness theorems, or self-citations are presented that reduce any claimed result to its own inputs by construction. The performance observations (e.g., 73% average loss) are framed as measured outcomes from external data collection rather than predictions forced by the framework definition itself. This is a standard empirical study whose central claims remain independently falsifiable against the collected prompt and performance data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
CodeMixBench: Evaluating code-mixing capabilities of LLMs across 18 languages , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[2]
1st Workshop on Reliable Evaluation of Large Language Models for Factual Information (REALInfo-2024), Co-located with AAAI ICWSM'24 , year=
Do llms find human answers to fact-driven questions perplexing? a case study on reddit , author=. 1st Workshop on Reliable Evaluation of Large Language Models for Factual Information (REALInfo-2024), Co-located with AAAI ICWSM'24 , year=
2024
-
[3]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
The curious decline of linguistic diversity: Training language models on synthetic text , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[4]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
The ShareLM collection and plugin: contributing human-model chats for the benefit of the community , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
-
[5]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Time waits for no one! analysis and challenges of temporal misalignment , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[6]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[7]
arXiv preprint arXiv:2509.01093 , year=
Natural Context Drift Undermines the Natural Language Understanding of Large Language Models , author=. arXiv preprint arXiv:2509.01093 , year=
-
[8]
Scientific Reports , volume=
” My AI is Lying to Me”: User-reported LLM hallucinations in AI mobile apps reviews , author=. Scientific Reports , volume=. 2025 , publisher=
2025
-
[9]
arXiv preprint arXiv:2401.08329 , year=
Understanding user experience in large language model interactions , author=. arXiv preprint arXiv:2401.08329 , year=
-
[10]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-Distribution Generalization Perspective , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[11]
arXiv preprint arXiv:2502.16523 , year=
Pay Attention to Real World Perturbations! Natural Robustness Evaluation in Machine Reading Comprehension , author=. arXiv preprint arXiv:2502.16523 , year=
-
[12]
arXiv preprint arXiv:2508.11383 , year=
When Punctuation Matters: A Large-Scale Comparison of Prompt Robustness Methods for LLMs , author=. arXiv preprint arXiv:2508.11383 , year=
-
[13]
2024 , note =
Jia, Robin , title =. 2024 , note =
2024
-
[14]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Whispers of Doubt Amidst Echoes of Triumph in NLP Robustness , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[15]
Advances in Neural Information Processing Systems , volume=
Revisiting out-of-distribution robustness in nlp: Benchmarks, analysis, and llms evaluations , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Assaying out-of-distribution generalization in transfer learning , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Id and ood performance are sometimes inversely correlated on real-world datasets , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Demystifying Prompts in Language Models via Perplexity Estimation , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[19]
Findings of the Association for Computational Linguistics: EMNLP 2022 , year=
Impact of Pretraining Term Frequencies on Few-Shot Numerical Reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , year=
2022
-
[20]
Proceedings of the 40th International Conference on Machine Learning , pages =
Large Language Models Struggle to Learn Long-Tail Knowledge , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[21]
arXiv preprint arXiv:2207.14251 , year=
Measuring causal effects of data statistics on language model'sfactual'predictions , author=. arXiv preprint arXiv:2207.14251 , year=
-
[22]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
The language of prompting: What linguistic properties make a prompt successful? , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[23]
Transactions on Machine Learning Research , year=
The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning , author=. Transactions on Machine Learning Research , year=
-
[24]
The Thirteenth International Conference on Learning Representations , year=
Quantifying Generalization Complexity for Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[25]
Nature Machine Intelligence , year=
A taxonomy and review of generalization research in NLP , author=. Nature Machine Intelligence , year=
-
[26]
arXiv preprint arXiv:2006.15680 , year=
Modeling generalization in machine learning: A methodological and computational study , author=. arXiv preprint arXiv:2006.15680 , year=
-
[27]
Teaching and Learning by Doing Corpus Analysis: Proceedings of the Fourth International Conference on Teaching and Language Corpora, Graz 19-24 July, 2000 , number=
Genres, Registers, Text Types, Domains and Styles: Clarifying the Concepts and Navigating a Path through the BNC Jungle David Lee (Lancaster, UK) , author=. Teaching and Learning by Doing Corpus Analysis: Proceedings of the Fourth International Conference on Teaching and Language Corpora, Graz 19-24 July, 2000 , number=. 2002 , organization=
2000
-
[28]
ACM Trans
A Survey on Evaluation of Large Language Models , author=. ACM Trans. Intell. Syst. Technol. , year=
-
[29]
Preserving Diversity in Supervised Fine-Tuning of Large Language Models , author=
-
[30]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
-
[31]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
The death and life of great prompts: analyzing the evolution of LLM prompts from the structural perspective , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[32]
2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR) , pages=
Prompting in the wild: An empirical study of prompt evolution in software repositories , author=. 2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR) , pages=. 2025 , organization=
2025
-
[33]
WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild , author=
-
[34]
arXiv preprint arXiv:2504.01542 , year=
Register Always Matters: Analysis of LLM Pretraining Data Through the Lens of Language Variation , author=. arXiv preprint arXiv:2504.01542 , year=
-
[35]
The Twelfth International Conference on Learning Representations , year=
WildChat: 1M ChatGPT Interaction Logs in the Wild , author=. The Twelfth International Conference on Learning Representations , year=
-
[36]
Developing Story: Case Studies of Generative AI’s Use in Journalism , author=
-
[37]
CoRR , year=
WildVis: Open Source Visualizer for Million-Scale Chat Logs in the Wild , author=. CoRR , year=
-
[38]
2 OLMo 2 Furious , author=. arXiv preprint arXiv:2501.00656 , year=
work page internal anchor Pith review arXiv
-
[39]
CoRR , year=
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2 , author=. CoRR , year=
-
[40]
2024 , url =
Erfei Cui and Yinan He and Zheng Ma and Zhe Chen and Hao Tian and Weiyun Wang and Kunchang Li and Yi Wang and Wenhai Wang and Xizhou Zhu and Lewei Lu and Tong Lu and Yali Wang and Limin Wang and Yu Qiao and Jifeng Dai , title =. 2024 , url =
2024
-
[41]
2025 , url =
John Schulman, Thinking Machines , title=. 2025 , url =
2025
-
[42]
arXiv preprint arXiv:2405.00732 , year=
Lora land: 310 fine-tuned llms that rival gpt-4, A technical report , author=. arXiv preprint arXiv:2405.00732 , year=
-
[43]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[44]
Evaluating Distributional Distortion in Neural Language Modeling , author=
-
[45]
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset , author=
-
[46]
Advances in Neural Information Processing Systems , volume=
Openassistant conversations-democratizing large language model alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Advances in Neural Information Processing Systems , volume=
Factuality enhanced language models for open-ended text generation , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Advances in Neural Information Processing Systems , volume=
Mauve: Measuring the gap between neural text and human text using divergence frontiers , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Advances in Neural Information Processing Systems , volume=
Aligning LLM Agents by Learning Latent Preference from User Edits , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
arXiv preprint arXiv:2403.12388 , year=
Interpretable user satisfaction estimation for conversational systems with large language models , author=. arXiv preprint arXiv:2403.12388 , year=
-
[51]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improving Text Embeddings with Large Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[52]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Statistical Depth for Ranking and Characterizing Transformer-Based Text Embeddings , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[53]
B leu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[54]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Retrieval-augmented generation with knowledge graphs for customer service question answering , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[55]
LREC-COLING 2024-2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , year=
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain , author=. LREC-COLING 2024-2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , year=
2024
-
[56]
Using customer service dialogues for satisfaction analysis with context-assisted multiple instance learning , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[57]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[58]
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method , author=
-
[59]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[60]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[61]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Predict the Next Word , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[62]
Proceedings of the 41st International Conference on Machine Learning , pages=
Online speculative decoding , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[63]
arXiv preprint arXiv:2410.20533 , year=
Guiding Through Complexity: What Makes Good Supervision for Hard Reasoning Tasks? , author=. arXiv preprint arXiv:2410.20533 , year=
-
[64]
Adaptation of Large Language Models , author=. Proceedings of the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 5: Tutorial Abstracts) , pages=
2025
-
[65]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[66]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Toward Verifiable Instruction-Following Alignment for Retrieval Augmented Generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[67]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track) , pages=
DriftWatch: A Tool that Automatically Detects Data Drift and Extracts Representative Examples Affected by Drift , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track) , pages=
2024
-
[68]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
The many faces of robustness: A critical analysis of out-of-distribution generalization , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[69]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Pretrained Transformers Improve Out-of-Distribution Robustness , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[70]
arXiv preprint arXiv:2504.14194 , year=
Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models , author=. arXiv preprint arXiv:2504.14194 , year=
-
[71]
arXiv preprint arXiv:2305.09246 , year=
Maybe only 0.5\ author=. arXiv preprint arXiv:2305.09246 , year=
-
[72]
International Conference on Learning Representations , year=
Evaluating the Zero-shot Robustness of Instruction-tuned Language Models , author=. International Conference on Learning Representations , year=
-
[73]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Learning to Edit: Aligning LLMs with Knowledge Editing , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[74]
Finetuned Language Models are Zero-Shot Learners , author=
-
[75]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
MUSCLE: A Model Update Strategy for Compatible LLM Evolution , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[76]
Advances in Neural Information Processing Systems , volume=
The art of saying no: Contextual noncompliance in language models , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
Advances in Neural Information Processing Systems , volume=
Fedllm-bench: Realistic benchmarks for federated learning of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Safetyprompts: a systematic review of open datasets for evaluating and improving large language model safety , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[79]
Advances in Neural Information Processing Systems , volume=
Explaining datasets in words: Statistical models with natural language parameters , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Examining temporality in document classification , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.