Recognition: unknown
PV-SQL: Synergizing Database Probing and Rule-based Verification for Text-to-SQL Agents
Pith reviewed 2026-05-10 05:19 UTC · model grok-4.3
The pith
PV-SQL combines iterative database probing with rule-based verification to improve text-to-SQL performance on complex queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PV-SQL is an agentic framework consisting of a Probe component that iteratively generates probing queries to retrieve concrete records from the database, resolving ambiguities in value formats, column semantics, and inter-table relationships, and a Verify component that employs a rule-based method to extract verifiable conditions and construct an executable checklist for iterative SQL refinement.
What carries the argument
The Probe and Verify components, where Probe builds richer context by retrieving concrete database records through targeted queries and Verify enforces completeness by turning extracted conditions into a checklist for SQL iteration.
If this is right
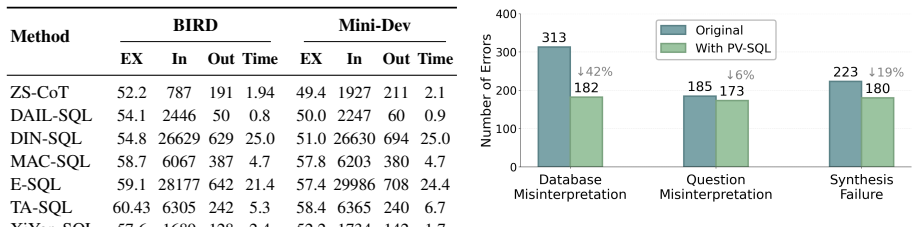
- Outperforms the best text-to-SQL baseline by 5% in execution accuracy on BIRD benchmarks.
- Improves valid efficiency score by 20.8% while using fewer tokens.
- Reduces missing constraints in generated SQL through iterative checklist refinement.
- Handles complex queries with subtle requirements more effectively than generation-only approaches.
Where Pith is reading between the lines
- The approach could extend to other structured generation tasks where LLMs need to ground outputs in external data sources before finalizing results.
- Hybrid agent designs that separate exploration of the environment from verification of constraints may reduce errors in domains like code synthesis or data extraction.
- Real-world database interfaces might become more robust if probing and rule checks are integrated to handle incomplete user specifications or evolving schemas.
Load-bearing premise
Iteratively generating probing queries will reliably resolve ambiguities in value formats, column semantics, and inter-table relationships, and the rule-based checklist will consistently reduce missing constraints without introducing new errors or excessive overhead.
What would settle it
Experiments on the BIRD benchmark showing no gain in execution accuracy or valid efficiency score over the best baseline, or cases where probing queries produce misleading records that lead to incorrect SQL.
Figures




read the original abstract
Text-to-SQL systems often struggle with deep contextual understanding, particularly for complex queries with subtle requirements. We present PV-SQL, an agentic framework that addresses these failures through two complementary components: Probe and Verify. The Probe component iteratively generates probing queries to retrieve concrete records from the database, resolving ambiguities in value formats, column semantics, and inter-table relationships to build richer contextual understanding. The Verify component employs a rule-based method to extract verifiable conditions and construct an executable checklist, enabling iterative SQL refinement that effectively reduces missing constraints. Experiments on the BIRD benchmarks show that PV-SQL outperforms the best text-to-SQL baseline by 5% in execution accuracy and 20.8% in valid efficiency score while consuming fewer tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PV-SQL, an agentic Text-to-SQL framework with two components: Probe, which iteratively generates database probing queries to resolve ambiguities in value formats, column semantics, and inter-table relationships; and Verify, which applies a rule-based method to extract conditions and build an executable checklist for iterative SQL refinement. Experiments on the BIRD benchmark report that PV-SQL outperforms the best baseline by 5% in execution accuracy and 20.8% in valid efficiency score while using fewer tokens.
Significance. If the reported gains hold under rigorous evaluation, the work demonstrates a practical synergy between database probing for richer context and rule-based verification for constraint coverage, addressing common failure modes in complex Text-to-SQL queries. This could inform future agentic systems by showing that lightweight, non-LLM mechanisms can improve accuracy and efficiency without increasing token costs.
major comments (2)
- [Experiments / §4] The central performance claims (5% execution accuracy and 20.8% valid efficiency gains) are load-bearing for the paper's contribution, yet the abstract and experimental description provide no details on the exact baselines, their configurations, statistical significance testing, error bars, or full experimental conditions (e.g., number of runs, prompt templates). This makes it difficult to assess whether the improvements are robust or attributable to the Probe+Verify mechanisms.
- [Method / §3] The assumption that iterative probing reliably resolves ambiguities without introducing new errors or excessive overhead is central to the Probe component, but the manuscript does not appear to include ablation studies isolating the contribution of probing iterations versus the Verify checklist, nor analysis of failure cases where probing might degrade performance.
minor comments (2)
- [§3.2] Clarify the exact rule set used in the Verify component and how the checklist is converted into executable verification steps; this would aid reproducibility.
- [Table 1 or §4.2] The BIRD benchmark results would benefit from a table breaking down performance by query complexity or error type to show where the gains are concentrated.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address each major comment below with specific revisions to improve clarity, reproducibility, and analysis of the proposed components.
read point-by-point responses
-
Referee: [Experiments / §4] The central performance claims (5% execution accuracy and 20.8% valid efficiency gains) are load-bearing for the paper's contribution, yet the abstract and experimental description provide no details on the exact baselines, their configurations, statistical significance testing, error bars, or full experimental conditions (e.g., number of runs, prompt templates). This makes it difficult to assess whether the improvements are robust or attributable to the Probe+Verify mechanisms.
Authors: We agree that greater experimental transparency is needed. In the revised manuscript, Section 4 and the appendix have been expanded to specify: all baselines (including their exact model versions, prompting strategies, and hyper-parameters drawn from their original papers); the full prompt templates for Probe and Verify; the number of runs (three independent runs with different random seeds, reporting mean ± std); and statistical significance via paired t-tests (p < 0.05 for both metrics). Error bars are now shown in Table 1. These additions confirm that the reported gains are robust and directly attributable to the synergy of Probe and Verify rather than implementation variance. revision: yes
-
Referee: [Method / §3] The assumption that iterative probing reliably resolves ambiguities without introducing new errors or excessive overhead is central to the Probe component, but the manuscript does not appear to include ablation studies isolating the contribution of probing iterations versus the Verify checklist, nor analysis of failure cases where probing might degrade performance.
Authors: We acknowledge the value of component-level analysis. The revised Section 4.3 now includes a dedicated ablation study comparing four variants: full PV-SQL, Probe-only, Verify-only, and the strongest baseline. Results show that Probe contributes the larger share of the accuracy improvement while Verify primarily boosts valid efficiency; their combination yields the best overall score. We have also added a failure-case analysis subsection that quantifies cases where probing introduced minor overhead or transient errors (occurring in <6% of BIRD queries) and demonstrates how the Verify checklist mitigates them. Token overhead remains lower than all baselines even with up to three probing iterations. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical agentic framework (Probe for iterative database probing and Verify for rule-based checklist refinement) evaluated directly on the external BIRD benchmark. Reported gains (5% execution accuracy, 20.8% valid efficiency) are experimental outcomes against baselines, not quantities derived from internal equations, fitted parameters, or self-citation chains that reduce to the inputs by construction. No mathematical derivation, ansatz, or uniqueness theorem is invoked; the work is self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S pider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to- SQL Task
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and Zhang, Zilin and Radev, Dragomir. S pider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to- SQL Task. Proceedings of the 2018 Conference on Empirical...
2018
-
[2]
Can LLM Already Serve as A Database Interface? A B ig Bench for Large-Scale Database Grounded Text-to- SQL s
Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and Zhou, Xuanhe and Ma, Chenhao and Li, Guoliang and Chang, Kevin Chen-Chuan and Li, Fei and Hui, Bei and Li, Yongbin. Can LLM Already Serve as A Database Interface? A B ig Bench for Large-Scale Database Grou...
2024
-
[3]
2025 , eprint=
E-SQL: Direct Schema Linking via Question Enrichment in Text-to-SQL , author=. 2025 , eprint=
2025
-
[4]
2022 , eprint=
Evaluating the Text-to-SQL Capabilities of Large Language Models , author=. 2022 , eprint=
2022
-
[5]
Re-examining the Role of Schema Linking in Text-to- SQL
Lei, Wenqiang and Wang, Weixin and Ma, Zhixin and Gan, Tian and Lu, Wei and Kan, Min-Yen and Chua, Tat-Seng. Re-examining the Role of Schema Linking in Text-to- SQL. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.564
-
[6]
Li, Haoyang and Zhang, Jing and Li, Cuiping and Chen, Hong , title =. Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2023 , isbn =. doi:10.1609/aaai.v37i1...
-
[7]
Bridging Textual and Tabular Data for Cross-Domain Text-to- SQL Semantic Parsing
Lin, Xi Victoria and Socher, Richard and Xiong, Caiming. Bridging Textual and Tabular Data for Cross-Domain Text-to- SQL Semantic Parsing. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.438
-
[8]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[9]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[10]
2023 , eprint=
Teaching Large Language Models to Self-Debug , author=. 2023 , eprint=
2023
-
[11]
and Lin, Xi Victoria , title =
Ni, Ansong and Iyer, Srini and Radev, Dragomir and Stoyanov, Ves and Yih, Wen-tau and Wang, Sida I. and Lin, Xi Victoria , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[12]
2024 , eprint=
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters , author=. 2024 , eprint=
2024
-
[13]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[14]
and Cao, Yuan and Narasimhan, Karthik , title =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[15]
DAIL - SQL : Optimized LLM Prompt for Text-to- SQL
Gao, Dawei and Wang, Haibin and Li, Yaliang and Sun, Xiuyu and Qian, Yichen and Ding, Bolin and Zhou, Jingren. DAIL - SQL : Optimized LLM Prompt for Text-to- SQL. Proceedings of the VLDB Endowment. 2024
2024
-
[16]
2023 , eprint=
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction , author=. 2023 , eprint=
2023
-
[17]
2024 , eprint=
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL , author=. 2024 , eprint=
2024
-
[18]
2025 , eprint=
Chain-of-Query: Unleashing the Power of LLMs in SQL-Aided Table Understanding via Multi-Agent Collaboration , author=. 2025 , eprint=
2025
-
[19]
2024 , eprint=
A Survey of Text-to-SQL Methods Enhanced by Large Language Models , author=. 2024 , eprint=
2024
-
[20]
2024 , eprint=
Evaluating SQL Understanding in Large Language Models , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
RSL-SQL: Robust Schema Linking for Text-to-SQL , author=. 2024 , eprint=
2024
-
[22]
2023 , eprint=
Enhancing Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies , author=. 2023 , eprint=
2023
-
[23]
2024 , eprint=
PURPLE: Making a Large Language Model a Better SQL Writer , author=. 2024 , eprint=
2024
-
[24]
JAMIA Open , volume=
Automating Pharmacovigilance Evidence Generation: Using Large Language Models to Produce Context-Aware Structured Query Language , author=. JAMIA Open , volume=. 2025 , publisher=
2025
-
[25]
Proceedings of the VLDB Endowment , year=
ValueNet: A Neural Text-to-SQL Architecture Incorporating Values , author=. Proceedings of the VLDB Endowment , year=
-
[26]
2025 , eprint=
A Study of In-Context-Learning-Based Text-to-SQL Errors , author=. 2025 , eprint=
2025
-
[27]
2024 , eprint=
Large Language Models Cannot Self-Correct Reasoning Yet , author=. 2024 , eprint=
2024
-
[28]
2022 , eprint=
CodeT: Code Generation with Generated Tests , author=. 2022 , eprint=
2022
-
[29]
Science , volume=
Competition-Level Code Generation with AlphaCode , author=. Science , volume=. 2022 , publisher=
2022
-
[30]
Proceedings of the Fifth ACM SIGPLAN International Conference on Functional Programming , pages=
QuickCheck: A Lightweight Tool for Random Testing of Haskell Programs , author=. Proceedings of the Fifth ACM SIGPLAN International Conference on Functional Programming , pages=
-
[31]
and Huang, Fei and Cheng, Reynold and Li, Yongbin , booktitle=
Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Cao, Rongyu and Geng, Ruiying and Huo, Nan and Zhou, Xuanhe and Ma, Chenhao and Li, Guoliang and Chang, Kevin C.-C. and Huang, Fei and Cheng, Reynold and Li, Yongbin , booktitle=
-
[32]
, booktitle=
Xu, Wenbo and Zhu, Haifeng and Yan, Liang and Liu, Chuanyi and Han, Peiyi and Duan, Shaoming and Pan, Jeff Z. , booktitle=
-
[33]
Pourreza, Mohammadreza and Rafiei, Davood , journal=
-
[34]
arXiv preprint arXiv:2409.16751 , year=
Cafero. arXiv preprint arXiv:2409.16751 , year=
-
[35]
Askari, Arian and Poelitz, Christian and Tang, Xinye , journal=
-
[36]
Cen, Jipeng and Liu, Jiaxin and Li, Zhixu and Wang, Jingjing , journal=
-
[37]
Shi, Jie and Xu, Bo and Liang, Jiaqing and Xiao, Yanghua and Chen, Jia and Xie, Chenhao and Wang, Peng and Wang, Wei , booktitle=
-
[38]
Teaching Large Language Models to Self-Debug
Teaching Large Language Models to Self-Debug , author=. arXiv preprint arXiv:2304.05128 , year=
work page internal anchor Pith review arXiv
-
[39]
Li, Zhenwen and Xie, Tao , journal=. Using
-
[40]
Advances in Neural Information Processing Systems , volume=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
2025 , eprint=
SQL-of-Thought: Multi-agentic Text-to-SQL with Guided Error Correction , author=. 2025 , eprint=
2025
-
[42]
2024 , eprint=
Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation , author=. 2024 , eprint=
2024
-
[43]
2024 , eprint=
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL , author=. 2024 , eprint=
2024
-
[44]
2024 , eprint=
CHESS: Contextual Harnessing for Efficient SQL Synthesis , author=. 2024 , eprint=
2024
-
[45]
2025 , eprint=
XiYan-SQL: A Novel Multi-Generator Framework For Text-to-SQL , author=. 2025 , eprint=
2025
-
[46]
2025 , eprint=
AmbiSQL: Interactive Ambiguity Detection and Resolution for Text-to-SQL , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going? , author=. 2025 , eprint=
2025
-
[48]
2025 , eprint=
SQLens: An End-to-End Framework for Error Detection and Correction in Text-to-SQL , author=. 2025 , eprint=
2025
-
[49]
2025 , eprint=
RubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System , author=. 2025 , eprint=
2025
-
[50]
TTD - SQL : Tree-Guided Token Decoding for Efficient and Schema-Aware SQL Generation
Sharma, Chetan and Narayanam, Ramasuri and Pal, Soumyabrata and Yeturu, Kalidas and Saini, Shiv Kumar and Mukherjee, Koyel. TTD - SQL : Tree-Guided Token Decoding for Efficient and Schema-Aware SQL Generation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2025. doi:10.18653/v1/2025.emnlp-industry.90
-
[51]
Jihyung Lee, Jin-Seop Lee, Jaehoon Lee, YunSeok Choi, and Jee-Hyong Lee
Lee, Jihyung and Lee, Jin-Seop and Lee, Jaehoon and Choi, YunSeok and Lee, Jee-Hyong. DCG - SQL : Enhancing In-Context Learning for Text-to- SQL with Deep Contextual Schema Link Graph. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.748
-
[52]
Small LLM s Are Weak Tool Learners: A Multi- LLM Agent
Shen, Weizhou and Li, Chenliang and Chen, Hongzhan and Yan, Ming and Quan, Xiaojun and Chen, Hehong and Zhang, Ji and Huang, Fei. Small LLM s Are Weak Tool Learners: A Multi- LLM Agent. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.929
-
[53]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[54]
2025 , eprint=
LLM-as-a-qualitative-judge: automating error analysis in natural language generation , author=. 2025 , eprint=
2025
-
[55]
Tian, Yuan and Kummerfeld, Jonathan K. and Li, Toby Jia-Jun and Zhang, Tianyi , title =. Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2024 , isbn =. doi:10.1145/3654777.3676368 , abstract =
-
[56]
Tian, Yuan and Zhang, Zheng and Ning, Zheng and Li, Toby Jia-Jun and Kummerfeld, Jonathan K. and Zhang, Tianyi. Interactive Text-to- SQL Generation via Editable Step-by-Step Explanations. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.1004
-
[57]
Proceedings of the 30th International Conference on Intelligent User Interfaces , pages =
Tian, Yuan and Lee, Daniel and Wu, Fei and Mai, Tung and Qian, Kun and Sahai, Siddhartha and Zhang, Tianyi and Li, Yunyao , title =. Proceedings of the 30th International Conference on Intelligent User Interfaces , pages =. 2025 , isbn =. doi:10.1145/3708359.3712083 , abstract =
-
[58]
Ning, Zheng and Tian, Yuan and Zhang, Zheng and Zhang, Tianyi and Li, Toby Jia-Jun , title =. ACM Trans. Interact. Intell. Syst. , month = dec, articleno =. 2024 , issue_date =. doi:10.1145/3650114 , abstract =
-
[59]
URL http://dx.doi.org/10.1145/3581641.3584066
Ning, Zheng and Zhang, Zheng and Sun, Tianyi and Tian, Yuan and Zhang, Tianyi and Li, Toby Jia-Jun , title =. Proceedings of the 28th International Conference on Intelligent User Interfaces , pages =. 2023 , isbn =. doi:10.1145/3581641.3584067 , abstract =
-
[60]
Zhang, Tianshu and Qian, Kun and Sahai, Siddhartha and Tian, Yuan and Garg, Shaddy and Sun, Huan and Li, Yunyao , title =. Proc. VLDB Endow. , month = jun, pages =. 2025 , issue_date =. doi:10.14778/3748191.3748222 , abstract =
-
[61]
2026 , eprint=
ALL-FEM: Agentic Large Language models Fine-tuned for Finite Element Methods , author=. 2026 , eprint=
2026
-
[62]
2025 , eprint=
ALLOY: Generating Reusable Agent Workflows from User Demonstration , author=. 2025 , eprint=
2025
-
[63]
2026 , eprint=
Attention-Aligned Reasoning for Large Language Models , author=. 2026 , eprint=
2026
-
[64]
2025 , eprint=
Selective Prompt Anchoring for Code Generation , author=. 2025 , eprint=
2025
-
[65]
2025 , eprint=
Supporting Construction Worker Well-Being with a Multi-Agent Conversational AI System , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.