Recognition: unknown
WISV: Wireless-Informed Semantic Verification for Distributed Speculative Decoding in Device-Edge LLM Inference
Pith reviewed 2026-05-10 04:29 UTC · model grok-4.3
The pith
WISV replaces rigid token matching with semantic verification that fuses wireless channel state and model hidden states to accept longer speculative sequences in device-edge LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
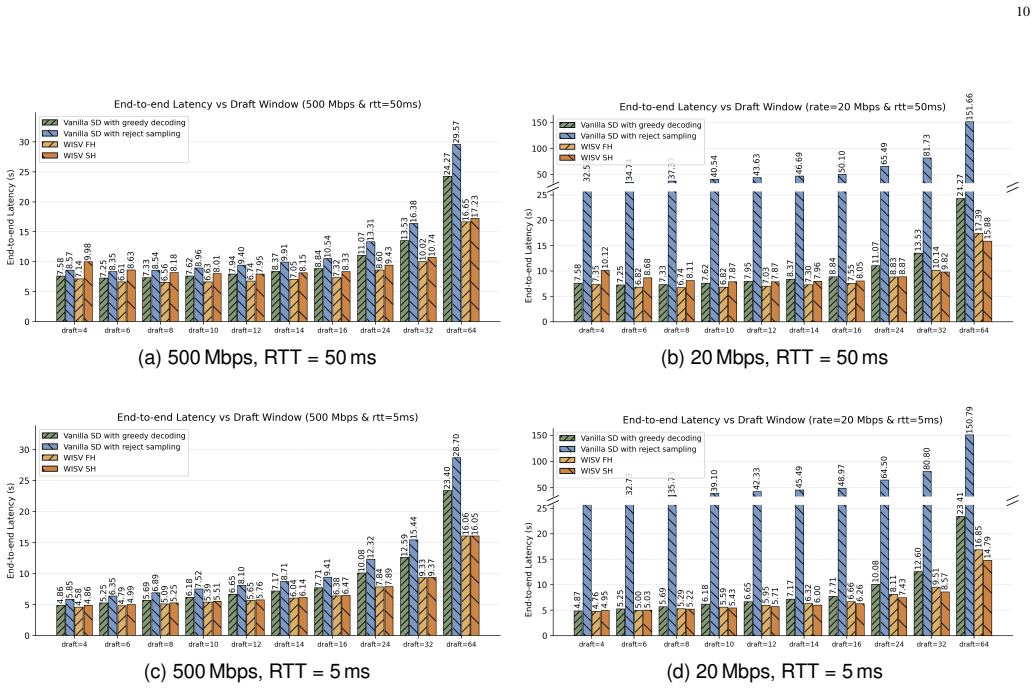
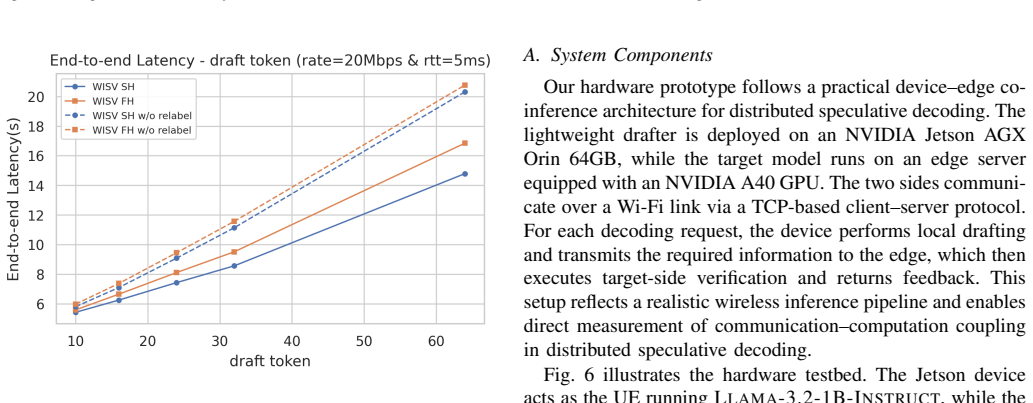
WISV integrates a lightweight decision head into the edge-side target LLM to dynamically evaluate speculative tokens by synthesizing high-dimensional hidden representations with instantaneous channel state information, replacing strict token-level matching with a channel-aware semantic acceptance policy that yields up to 60.8 percent longer accepted sequences, 37.3 percent fewer interaction rounds, and 31.4 percent lower end-to-end latency with under 1 percent accuracy loss.
What carries the argument
The lightweight decision head that combines high-dimensional hidden representations from the target model with instantaneous CSI to decide semantic acceptance of speculative tokens.
If this is right
- Accepted sequence lengths increase by up to 60.8 percent, directly reducing the number of device-edge communication rounds.
- End-to-end latency drops by up to 31.4 percent while task accuracy remains within 1 percent of baseline.
- Two tailored protocols (full-hidden upload and mismatch-first selective upload) let the system trade verification quality against communication cost.
- Hardware results on Jetson AGX Orin plus A40 server confirm the latency gains translate to physical edge hardware.
Where Pith is reading between the lines
- The same CSI-plus-hidden-state fusion could be tested on other sequential generation tasks such as autoregressive image or speech synthesis over wireless links.
- If the decision head proves robust, it may allow smaller drafter models to be used without sacrificing final output quality.
- The selective-hidden protocol suggests a general pattern for compressing intermediate representations when bandwidth is the scarce resource.
Load-bearing premise
The lightweight decision head can reliably fuse hidden representations with instantaneous CSI to produce acceptance decisions that increase accepted lengths without substantially harming downstream task accuracy under fluctuating wireless conditions.
What would settle it
Deploy the system on a real wireless link with rapid channel fluctuations and measure whether the accuracy drop stays below 1 percent while accepted sequence lengths remain at least 20 percent longer than vanilla speculative decoding.
Figures





read the original abstract
While distributed device-edge speculative decoding enhances resource utilization across heterogeneous nodes, its performance is often bottlenecked by conventional token-level verification strategies. Such rigid alignment leads to excessive rejections, significantly diminishing the accepted sequence length and increasing interaction rounds under fluctuating wireless conditions. In this paper, we propose WISV (Wireless-Informed Semantic Verification), a novel distributed speculative decoding framework that goes beyond strict token-level matching via a channel-aware semantic acceptance policy. WISV integrates a lightweight decision head into the edge-side target LLM to dynamically evaluate speculative tokens by synthesizing high-dimensional hidden representations with instantaneous channel state information (CSI). To optimize the trade-off between verification fidelity and communication overhead, we further design two tailored communication protocols: full-hidden upload and mismatch-first selective-hidden upload. Extensive simulations using a 1B drafter and an 8B target model demonstrate that WISV achieves up to a 60.8% increase in accepted length, a 37.3% reduction in interaction rounds, and a 31.4% improvement in end-to-end latency compared to vanilla speculative decoding across tested settings, while maintaining a negligible task accuracy drop (<1%). Finally, we validate WISV on a hardware testbed comprising an NVIDIA Jetson AGX Orin and an A40-equipped server, confirming its real-world efficacy in accelerating edge-deployed LLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WISV, a distributed speculative decoding framework for device-edge LLM inference that replaces rigid token-level verification with a channel-aware semantic acceptance policy. A lightweight decision head on the edge-side target model (8B) fuses high-dimensional hidden representations with instantaneous CSI to decide token acceptance, supported by two communication protocols (full-hidden and mismatch-first selective upload). Simulations with a 1B drafter model report up to 60.8% longer accepted sequences, 37.3% fewer interaction rounds, and 31.4% lower end-to-end latency versus vanilla speculative decoding, with <1% task accuracy drop; results are further validated on a hardware testbed (Jetson AGX Orin + A40 server).
Significance. If the central performance claims hold after addressing validation gaps, the work would be significant for wireless edge AI: it demonstrates how semantic verification informed by CSI can substantially reduce communication overhead in heterogeneous LLM inference without meaningful accuracy loss. The hardware testbed validation and explicit focus on fluctuating wireless conditions are concrete strengths that distinguish it from purely simulation-based speculative decoding papers.
major comments (3)
- [§3] §3 (Proposed Method, decision head description): The lightweight decision head is load-bearing for all headline gains, yet the manuscript gives no architecture details, training objective, input dimensionality reduction steps, or loss function; without these, it is impossible to assess whether the fusion of hidden states and CSI can reliably distinguish semantic equivalence from token identity under noise.
- [§5] §5 (Experiments): The reported improvements (60.8% accepted length, 37.3% round reduction, 31.4% latency) are presented as point estimates without error bars, confidence intervals, or details on data exclusion rules and random seeds, making it difficult to determine whether the gains are statistically robust across wireless channel realizations.
- [§5.2] §5.2 (CSI and ablation analysis): No experiments vary CSI estimation error variance or hidden-state compression ratios and measure the resulting impact on acceptance rate versus downstream task accuracy; this directly tests the weakest assumption that the decision head preserves factual correctness when CSI is noisy, and its absence leaves the <1% accuracy claim unverified under realistic conditions.
minor comments (2)
- [Figures 3-4] Figure 3 and 4: Axis labels and legends do not explicitly indicate the range of SNR or Doppler values used for the fluctuating wireless conditions, reducing clarity of the robustness claims.
- [§2] The related-work section could more explicitly contrast WISV against recent semantic-communication and speculative-decoding papers that also incorporate channel state.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and valuable suggestions. We address each of the major comments point by point below, indicating the changes we will implement in the revised manuscript.
read point-by-point responses
-
Referee: §3 (Proposed Method, decision head description): The lightweight decision head is load-bearing for all headline gains, yet the manuscript gives no architecture details, training objective, input dimensionality reduction steps, or loss function; without these, it is impossible to assess whether the fusion of hidden states and CSI can reliably distinguish semantic equivalence from token identity under noise.
Authors: We acknowledge the need for greater detail in the description of the decision head. The current manuscript provides a high-level overview, but to fully address this concern, we will expand Section 3 with specific information on the architecture, the training objective and procedure, steps for input dimensionality reduction, and the loss function used. This addition will allow readers to evaluate the reliability of the semantic verification under noisy conditions. revision: yes
-
Referee: §5 (Experiments): The reported improvements (60.8% accepted length, 37.3% round reduction, 31.4% latency) are presented as point estimates without error bars, confidence intervals, or details on data exclusion rules and random seeds, making it difficult to determine whether the gains are statistically robust across wireless channel realizations.
Authors: We agree that including statistical measures would enhance the credibility of the reported gains. In the revised manuscript, we will update the experimental results in Section 5 to include error bars (standard deviations over multiple runs), confidence intervals, and explicit details on the random seeds used, data exclusion criteria, and the number of channel realizations considered. revision: yes
-
Referee: §5.2 (CSI and ablation analysis): No experiments vary CSI estimation error variance or hidden-state compression ratios and measure the resulting impact on acceptance rate versus downstream task accuracy; this directly tests the weakest assumption that the decision head preserves factual correctness when CSI is noisy, and its absence leaves the <1% accuracy claim unverified under realistic conditions.
Authors: We recognize that dedicated ablations on CSI estimation errors and compression ratios are important for verifying robustness. Our hardware testbed experiments already reflect real fluctuating wireless conditions, which include CSI inaccuracies. Nevertheless, to strengthen the validation, we will add new simulation results in Section 5.2 that vary CSI error variance and hidden-state compression ratios, reporting their effects on acceptance rates and task accuracy to confirm the <1% drop holds under these conditions. revision: yes
Circularity Check
No circularity detected; framework and gains derived from independent design and validation
full rationale
The paper presents WISV as a new channel-aware semantic acceptance policy that augments the edge-side target LLM with a lightweight decision head fusing hidden representations and instantaneous CSI. Performance improvements (accepted length, round count, latency) are reported from separate simulation runs on 1B/8B model pairs and from hardware measurements on Jetson AGX Orin + A40 server; these are not obtained by fitting parameters to the evaluation data or by renaming prior results. No equations, uniqueness theorems, or self-citations appear as load-bearing steps in the provided derivation chain. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
lightweight decision head
no independent evidence
Forward citations
Cited by 1 Pith paper
-
CR^2: Cost-Aware Risk-Controlled Routing for Wireless Device-Edge LLM Inference
CR^2 matches full-information routing performance for device-edge LLM inference using only device-side signals and cuts normalized deployment cost by up to 16.9% at matched accuracy.
Reference graph
Works this paper leans on
-
[1]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,”IEEE Communications Surveys & Tutorials, vol. 27, no. 6, pp. 3820–3860, 2025
2025
-
[2]
On-device language models: A comprehensive review
J. Xu, Z. Li, W. Chen, Q. Wang, X. Gao, Q. Cai, and Z. Ling, “On-device language models: A comprehensive review,”arXiv preprint arXiv:2409.00088, 2024
-
[3]
Empowering edge intelligence: A comprehensive survey on on-device ai models,
X. Wang, Z. Tang, J. Guo, T. Meng, C. Wang, T. Wang, and W. Jia, “Empowering edge intelligence: A comprehensive survey on on-device ai models,”ACM Computing Surveys, vol. 57, no. 9, pp. 1–39, 2025
2025
-
[4]
Empowering large language models to edge intelligence: A survey of edge efficient llms and techniques,
R. Wang, Z. Gao, L. Zhang, S. Yue, and Z. Gao, “Empowering large language models to edge intelligence: A survey of edge efficient llms and techniques,”Computer Science Review, vol. 57, p. 100755, 2025
2025
-
[5]
Large language models empowered autonomous edge ai for connected intelligence,
Y . Shen, J. Shao, X. Zhang, Z. Lin, H. Pan, D. Li, J. Zhang, and K. B. Letaief, “Large language models empowered autonomous edge ai for connected intelligence,”IEEE Communications Magazine, vol. 62, no. 10, pp. 140–146, 2024
2024
-
[6]
Communication- efficient edge ai: Algorithms and systems,
Y . Shi, K. Yang, T. Jiang, J. Zhang, and K. B. Letaief, “Communication- efficient edge ai: Algorithms and systems,”IEEE communications sur- veys & tutorials, vol. 22, no. 4, pp. 2167–2191, 2020
2020
-
[7]
Pushing ai to wireless network edge: An overview on integrated sensing, communication, and computation towards 6g,
G. Zhu, Z. Lyu, X. Jiao, P. Liu, M. Chen, J. Xu, S. Cui, and P. Zhang, “Pushing ai to wireless network edge: An overview on integrated sensing, communication, and computation towards 6g,”Science China Information Sciences, vol. 66, no. 3, p. 130301, 2023
2023
-
[8]
Wdmoe: Wireless distributed mixture of experts for large language models,
N. Xue, Y . Sun, Z. Chen, M. Tao, X. Xu, L. Qian, S. Cui, W. Zhang, and P. Zhang, “Wdmoe: Wireless distributed mixture of experts for large language models,”IEEE Transactions on Wireless Communications, vol. 25, pp. 559–572, 2026
2026
-
[9]
Petals: Collaborative inference and fine-tuning of large models,
A. Borzunov, D. Baranchuk, T. Dettmers, M. Riabinin, Y . Belkada, A. Chumachenko, P. Samygin, and C. Raffel, “Petals: Collaborative inference and fine-tuning of large models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), 2023, pp. 558–568
2023
-
[10]
Fast inference from transform- ers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transform- ers via speculative decoding,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 19 274–19 286
2023
-
[11]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sam- pling,”arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Dsd: A distributed speculative decoding solution for edge-cloud agile large model serving,
F. Yu, L. Li, B. McDanel, and S. Q. Zhang, “Dsd: A distributed speculative decoding solution for edge-cloud agile large model serving,” arXiv preprint arXiv:2511.21669, 2025
-
[13]
J. Ning, C. Zheng, and T. Yang, “Dssd: Efficient edge-device llm deployment and collaborative inference via distributed split speculative decoding,”arXiv preprint arXiv:2507.12000, 2025
-
[14]
Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,
Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,”ACM SIGARCH Computer Architecture News, vol. 45, no. 1, pp. 615–629, 2017
2017
-
[15]
On-demand accelerating deep neural network inference via edge computing,
S. Lin, Z. Zhou, Z. Zhang, X. Chen, and J. Zhang, “On-demand accelerating deep neural network inference via edge computing,” in Edge Intelligence in the Making: Optimization, Deep Learning, and Applications. Springer, 2022, pp. 151–168
2022
-
[16]
Bottlenet++: An end-to-end approach for feature compression in device-edge co-inference systems,
J. Shao and J. Zhang, “Bottlenet++: An end-to-end approach for feature compression in device-edge co-inference systems,” in2020 IEEE Inter- national Conference on Communications Workshops (ICC Workshops). IEEE, 2020, pp. 1–6. 13
2020
-
[17]
Nestdnn: Resource-aware multi- tenant on-device deep learning for continuous mobile vision,
B. Fang, X. Zeng, and M. Zhang, “Nestdnn: Resource-aware multi- tenant on-device deep learning for continuous mobile vision,” inPro- ceedings of the 24th Annual International Conference on Mobile Com- puting and Networking, 2018, pp. 115–127
2018
-
[18]
Early-exit deep neural network-a comprehensive survey,
H. Rahmath P, V . Srivastava, K. Chaurasia, R. G. Pacheco, and R. S. Couto, “Early-exit deep neural network-a comprehensive survey,”ACM Computing Surveys, vol. 57, no. 3, pp. 1–37, 2024
2024
-
[19]
Split learning for health: Distributed deep learning without sharing raw patient data
P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split learning for health: Distributed deep learning without sharing raw patient data,” arXiv preprint arXiv:1812.00564, 2018
work page Pith review arXiv 2018
-
[20]
Judge decoding: Faster speculative sampling requires going beyond model alignment,
G. Bachmann, S. Anagnostidis, A. Pumarola, M. Georgopoulos, A. Sanakoyeu, Y . Du, E. Sch ¨onfeld, A. Thabet, and J. Kohler, “Judge decoding: Faster speculative sampling requires going beyond model alignment,”arXiv preprint arXiv:2501.19309, 2025
-
[21]
R. Garipov, F. Velikonivtsev, I. Ermakov, R. Svirschevski, V . Egiazarian, and M. Ryabinin, “Autojudge: Judge decoding without manual annota- tion,”arXiv preprint arXiv:2504.20039, 2025
-
[22]
Training-Free Loosely Speculative Decoding: Accepting Semantically Correct Drafts Beyond Exact Match
J. Li, Y . Xu, G. Li, S. Yang, J. Xu, X. Yin, D. Li, E. C. Ngai, and E. Barsoum, “Training-free loosely speculative decoding: Accept- ing semantically correct drafts beyond exact match,”arXiv preprint arXiv:2511.22972, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Overcoming joint intractability with lossless hierarchical speculative decoding,
Y . Zhou, F. Huang, H. Li, F. Wu, T. Wang, J. Zhang, J. Lin, and Z.- Q. Cheng, “Overcoming joint intractability with lossless hierarchical speculative decoding,”arXiv preprint arXiv:2601.05724, 2026
- [24]
-
[25]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
T. Cai, Y . Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao, “Medusa: Simple llm inference acceleration framework with multiple decoding heads,”arXiv preprint arXiv:2401.10774, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Y . Li, F. Wei, C. Zhang, and H. Zhang, “Eagle: Speculative sampling re- quires rethinking feature uncertainty,”arXiv preprint arXiv:2401.15077, 2024
work page internal anchor Pith review arXiv 2024
-
[27]
Eagle-2: Faster inference of language models with dynamic draft trees,
——, “Eagle-2: Faster inference of language models with dynamic draft trees,” inProceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 7421–7432
2024
-
[28]
arXiv preprint arXiv:2503.01840 (2025) 5 16 Z
——, “Eagle-3: Scaling up inference acceleration of large language models via training-time test,”arXiv preprint arXiv:2503.01840, 2025
-
[29]
Draft& verify: Lossless large language model acceleration via self- speculative decoding,
J. Zhang, J. Wang, H. Li, L. Shou, K. Chen, G. Chen, and S. Mehrotra, “Draft& verify: Lossless large language model acceleration via self- speculative decoding,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 11 263–11 282
2024
-
[30]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[31]
Orca: A distributed serving system for{Transformer-Based}generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for{Transformer-Based}generative models,” in16th USENIX symposium on operating systems design and implemen- tation (OSDI 22), 2022, pp. 521–538
2022
-
[32]
Taming{Throughput-Latency}tradeoff in{LLM}inference with{Sarathi-Serve},
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. Gulavani, A. Tumanov, and R. Ramjee, “Taming{Throughput-Latency}tradeoff in{LLM}inference with{Sarathi-Serve},” in18th USENIX symposium on operating systems design and implementation (OSDI 24), 2024, pp. 117–134
2024
-
[33]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 193–210
2024
-
[34]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,”Proceedings of machine learning and systems, vol. 5, pp. 606–624, 2023
2023
-
[35]
Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale,
R. Y . Aminabadi, S. Rajbhandari, A. A. Awan, C. Li, D. Li, E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasleyet al., “Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale,” inSC22: International Conference for High Performance Com- puting, Networking, Storage and Analysis. IEEE, 2022, pp. 1–15
2022
-
[36]
Flexgen: High-throughput generative inference of large language models with a single gpu,
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, P. Liang, C. R ´e, I. Stoica, and C. Zhang, “Flexgen: High-throughput generative inference of large language models with a single gpu,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 31 094–31 116
2023
-
[37]
K. Lv, H. Guo, Q. Guo, and X. Qiu, “Duodecoding: Hardware-aware heterogeneous speculative decoding with dynamic multi-sequence draft- ing,”arXiv preprint arXiv:2503.00784, 2025
-
[38]
Sled: A speculative llm decoding framework for efficient edge serving,
X. Li, D. Spatharakis, S. Ghafouri, J. Fan, H. Vandierendonck, D. John, B. Ji, and D. S. Nikolopoulos, “Sled: A speculative llm decoding framework for efficient edge serving,” inProceedings of the Tenth ACM/IEEE Symposium on Edge Computing, 2025, pp. 1–8
2025
-
[39]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems, 2021,”URL https://arxiv. org/abs/2110.14168, vol. 9, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.