Recognition: unknown
OmniVLA-RL: A Vision-Language-Action Model with Spatial Understanding and Online RL
Pith reviewed 2026-05-10 05:12 UTC · model grok-4.3
The pith
OmniVLA-RL combines a Mix-of-Transformers architecture with Flow-GSPO optimization to address imprecise spatial perception and unstable reinforcement learning in vision-language-action models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
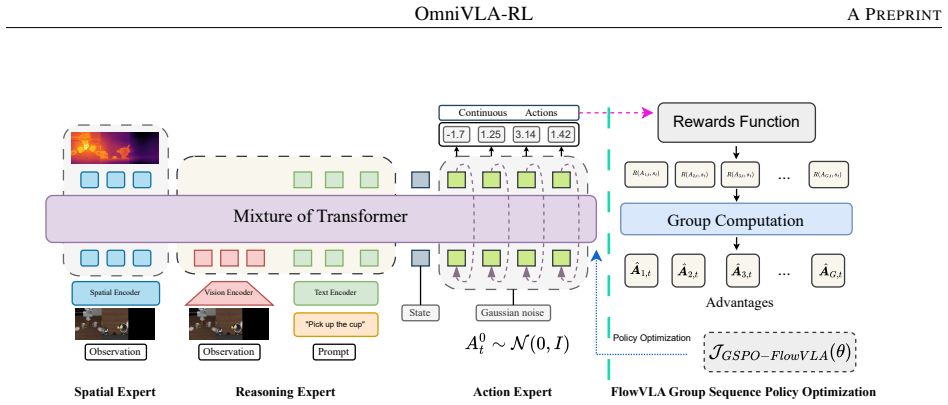
OmniVLA-RL leverages a Mix-of-Transformers (MoT) design to synergistically integrate reasoning, spatial, and action experts, while Flow-GSPO reformulates flow matching as a Stochastic Differential Equation (SDE) process integrated with Group Segmented Policy Optimization (GSPO) to enhance action precision and training robustness, leading to performance that surpasses mainstream existing methods on the LIBERO and LIBERO-Plus benchmarks.
What carries the argument
Mix-of-Transformers (MoT) architecture that routes tasks across reasoning, spatial, and action expert modules, together with Flow-GSPO that reformulates flow matching as an SDE and combines it with Group Segmented Policy Optimization.
If this is right
- Vision-language-action models can achieve more accurate spatial understanding during robot manipulation and navigation.
- Reinforcement learning stages for action generation become more stable and less prone to collapse.
- Specialized expert modules allow tighter fusion of visual, language, and action signals than monolithic transformers.
- Performance advantages observed on LIBERO benchmarks are expected to translate into more reliable real-world embodied control.
- The overall design offers a template for overcoming the three listed limitations across future VLA systems.
Where Pith is reading between the lines
- The same expert-routing pattern could be applied to other embodied domains such as mobile navigation or multi-robot coordination.
- The SDE reformulation inside Flow-GSPO may generalize to other generative policy methods that currently use standard flow matching.
- Scaling the number of expert modules beyond the three described could support more complex long-horizon tasks.
- Online adaptation of the spatial expert using new sensor streams would be a natural next test of the architecture.
Load-bearing premise
The Mix-of-Transformers integration and Flow-GSPO reformulation are what actually produce the claimed gains in spatial perception and reinforcement learning robustness.
What would settle it
An ablation experiment on the LIBERO benchmark that removes the spatial expert module from the Mix-of-Transformers and finds no drop in spatial task performance would falsify the claim that this component drives the reported spatial improvements.
Figures



read the original abstract
Visual-Language-Action (VLA) models represent a paradigm shift in embodied AI, yet existing frameworks often struggle with imprecise spatial perception, suboptimal multimodal fusion, and instability in reinforcement learning. To bridge these gaps, we propose OmniVLA-RL, a novel architecture that leverages a Mix-of-Transformers (MoT) design to synergistically integrate reasoning, spatial, and action experts. Furthermore, we introduce Flow-GSPO, which reformulates flow matching as a Stochastic Differential Equation (SDE) process and integrates it with Group Segmented Policy Optimization (GSPO) to enhance action precision and training robustness. Extensive evaluations on the LIBERO and LIBERO-Plus benchmarks demonstrate that OmniVLA-RL achieves decent overall performance and surpasses mainstream existing methods, effectively overcoming the fundamental limitations of current VLA models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniVLA-RL, a vision-language-action model using a Mix-of-Transformers (MoT) architecture to integrate reasoning, spatial, and action experts, along with Flow-GSPO, which reformulates flow matching as a stochastic differential equation (SDE) and combines it with Group Segmented Policy Optimization (GSPO) to improve action precision and RL robustness. It claims that evaluations on the LIBERO and LIBERO-Plus benchmarks show decent overall performance that surpasses mainstream existing VLA methods.
Significance. If the performance claims hold and the gains can be attributed to the proposed MoT and Flow-GSPO components, the work would offer a useful advance in embodied AI by improving spatial understanding and online RL stability in VLA models. The expert-mixture and SDE-reformulation ideas provide a concrete direction for addressing multimodal fusion and policy optimization challenges.
major comments (2)
- [Abstract] Abstract: The central claim that OmniVLA-RL 'achieves decent overall performance and surpasses mainstream existing methods' is stated without any quantitative metrics, comparison tables, baselines, error bars, or result figures. This absence makes the performance claim unverifiable and load-bearing for the paper's contribution.
- [Methods/Experiments] Methods/Experiments (implied by abstract): No ablation studies are described that isolate the contributions of the Mix-of-Transformers expert integration versus a standard transformer backbone, or of Flow-GSPO versus vanilla flow matching or PPO. Without such controlled comparisons, any reported gains on LIBERO cannot be attributed to the proposed components rather than unstated factors such as data scale, training duration, or hyper-parameter tuning.
minor comments (1)
- [Abstract] Abstract: The qualifier 'decent overall performance' is vague and should be replaced by concrete numbers or a summary of key metrics when results are added.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experimental design. We agree that strengthening the verifiability of claims and clarifying component contributions will improve the manuscript. Below we respond point by point and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that OmniVLA-RL 'achieves decent overall performance and surpasses mainstream existing methods' is stated without any quantitative metrics, comparison tables, baselines, error bars, or result figures. This absence makes the performance claim unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract would be strengthened by including concrete quantitative results. In the revised manuscript we will add key performance numbers (e.g., success rates on LIBERO and LIBERO-Plus), explicit baseline names, and a brief reference to the main comparison table and figures so that the central claim is immediately supported by evidence rather than remaining high-level. revision: yes
-
Referee: [Methods/Experiments] Methods/Experiments (implied by abstract): No ablation studies are described that isolate the contributions of the Mix-of-Transformers expert integration versus a standard transformer backbone, or of Flow-GSPO versus vanilla flow matching or PPO. Without such controlled comparisons, any reported gains on LIBERO cannot be attributed to the proposed components rather than unstated factors such as data scale, training duration, or hyper-parameter tuning.
Authors: We acknowledge that dedicated ablations would provide stronger causal attribution. While the current experiments include comparisons against multiple existing VLA methods that rely on standard transformer backbones, these do not fully isolate the MoT expert integration or the SDE reformulation of flow matching. In the revision we will add controlled ablation studies that directly compare (i) MoT versus a single unified transformer backbone and (ii) Flow-GSPO versus vanilla flow matching and PPO, while keeping data, training steps, and hyperparameters matched. This will allow readers to attribute gains more confidently to the proposed components. revision: yes
Circularity Check
No circularity in architecture proposal or benchmark claims
full rationale
The paper introduces an empirical VLA model (OmniVLA-RL) with MoT integration and Flow-GSPO reformulation, then reports superior performance on LIBERO benchmarks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described structure. Claims rest on experimental results rather than any self-referential reduction of outputs to inputs by construction. The work is self-contained as a standard architecture-plus-evaluation contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mustafa Shukor and Dana Aubakirova and Francesco Capuano and Pepijn Kooijmans and Steven Palma and Adil Zouitine and Michel Aractingi and Caroline Pascal and Martino Russi and Andres Marafioti and Simon Alibert and Matthieu Cord and Thomas Wolf and Remi Cadene , title =
-
[2]
Moo Jin Kim and Karl Pertsch and Siddharth Karamcheti and Ted Xiao and Ashwin Balakrishna and Suraj Nair and Rafael Rafailov and Ethan P Foster and Pannag R Sanketi and Quan Vuong and Thomas Kollar and Benjamin Burchfiel and Russ Tedrake and Dorsa Sadigh and Sergey Levine and Percy Liang and Chelsea Finn , title =
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale , journal =
-
[4]
Tao Lin and Gen Li and Yilei Zhong and Yanwen Zou and Bo Zhao , title =
-
[5]
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =
-
[6]
Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David , title =
-
[7]
Delin Qu and Haoming Song and Qizhi Chen and Yuanqi Yao and Xinyi Ye and Yani Ding and Zhigang Wang and Jiayuan Gu and Bin Zhao and Dong Wang and Xuelong Li , title =
-
[8]
PaliGemma 2: A Family of Versatile VLMs for Transfer , journal =
-
[9]
From Spatial to Actions: Grounding Vision-Language-Action Model in Spatial Foundation Priors , journal =
-
[10]
Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,
Guanxing Lu and Wenkai Guo and Chubin Zhang and Yuheng Zhou and Haonan Jiang and Zifeng Gao and Yansong Tang and Ziwei Wang , title=. ArXiv preprint arXiv:2505.18719 , year=
-
[11]
_. ArXiv preprint arXiv:2510.25889 , year=
-
[12]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
^. ArXiv preprint arXiv:2511.14759 , year=
-
[13]
Proximal Policy Optimization Algorithms , journal=
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , journal=
-
[15]
Group Sequence Policy Optimization , journal=
-
[16]
Sparse Deep Interaction Fusion for 3D Object Detection , journal=
-
[17]
Spatial Forcing: Implicit Spatial Representation Alignment for Vision-language-action Model , journal=
-
[18]
Liu, Wei and Zhang, Yue and Jie, Haoxiang and Hu, Jun , title=. ArXiv preprint arXiv:2510.12276 , year=
-
[19]
G ^2 VLM: Geometry Grounded Vision Language Model with Unified 3D Reconstruction and Spatial Reasoning , journal =
-
[20]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Li, Zhiqi and Wang, Wenhai and Li, Hongyang and Xie, Enze and Sima, Chonghao and Lu, Tong and Yu, Qiao and Dai, Jifeng , title=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[21]
M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation , journal=
Enze Xie and Zhiding Yu and Daquan Zhou and Jonah Philion and Anima Anandkumar and Sanja Fidler and Ping Luo and Jos. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation , journal=
-
[22]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Li, Yangguang and Huang, Bin and Chen, Zeren and Cui, Yufeng and Liang, Feng and Shen, Mingzhu and Liu, Fenggang and Xie, Enze and Sheng, Lu and Ouyang, Wanli and Shao, Jing , title=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[23]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models , journal=
-
[24]
LLaMA: Open and Efficient Foundation Language Models , journal=
-
[25]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , journal=
-
[26]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , journal=
-
[27]
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities , journal=
-
[28]
Yingyan Li and Shuyao Shang and Weisong Liu and Bing Zhan and Haochen Wang and Yu-Quan Wang and Yuntao Chen and Xiaoman Wang and Yasong An and Chufeng Tang and Lu Hou and Lue Fan and Zhaoxiang Zhang , title=. ArXiv preprint arXiv:2510.12796 , year=
-
[29]
Octo: An Open-Source Generalist Robot Policy , journal=
-
[30]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan and Noah Brown and Justice Carbajal and Yevgen Chebotar and Xi Chen and Krzysztof Choromanski and Tianli Ding and Danny Driess and Avinava Dubey and Chelsea Finn and Pete Florence and Chuyuan Fu and Montse Gonzalez Arenas and Keerthana Gopalakrishnan and Kehang Han and Karol Hausman and Alexander Herzog and Jasmine Hsu and Brian Ichter and ...
work page internal anchor Pith review arXiv
-
[31]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black and Noah Brown and Danny Driess and Adnan Esmail and Michael Equi and Chelsea Finn and Niccolo Fusai and Lachy Groom and Karol Hausman and Brian Ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Sergey Levine and Adrian Li-Bell and Mohith Mothukuri and Suraj Nair and Karl Pertsch and Lucy Xiaoyang Shi and James Tanner and Quan Vuon...
work page internal anchor Pith review arXiv
-
[32]
Physical Intelligence and Kevin Black and Noah Brown and James Darpinian and Karan Dhabalia and Danny Driess and Adnan Esmail and Michael Equi and Chelsea Finn and Niccolo Fusai and Manuel Y. Galliker and Dibya Ghosh and Lachy Groom and Karol Hausman and Brian Ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Devin LeBlanc and Sergey Levine an...
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti and Orr Zohar and Miquel Farré and Merve Noyan and Elie Bakouch and Pedro Cuenca and Cyril Zakka and Loubna Ben Allal and Anton Lozhkov and Nouamane Tazi and Vaibhav Srivastav and Joshua Lochner and Hugo Larcher and Mathieu Morlon and Lewis Tunstall and Leandro von Werra and Thomas Wolf , title=. ArXiv preprint arXiv:2504.05299 , year=
work page internal anchor Pith review arXiv
-
[34]
Denoising Diffusion Probabilistic Models
Jonathan Ho and Ajay Jain and Pieter Abbeel , title=. ArXiv preprint arXiv:2006.11239 , year=
work page internal anchor Pith review arXiv 2006
-
[35]
Improved denois- ing diffusion probabilistic models.arXiv preprint arXiv:2102.09672,
Alex Nichol and Prafulla Dhariwal , title=. ArXiv preprint arXiv:2102.09672 , year=
-
[36]
ArXiv preprint arXiv:1907.0560 , year=
Yang Song and Stefano Ermon , title=. ArXiv preprint arXiv:1907.0560 , year=
-
[37]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song and Jascha Sohl-Dickstein and Diederik P. Kingma and Abhishek Kumar and Stefano Ermon and Ben Poole , title=. ArXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[38]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Nikiforos Mimikos-Stamatopoulos and Benjamin Zhang and Markos Katsoulakis , title=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[39]
Yang Song and Prafulla Dhariwal and Mark Chen and Ilya Sutskever , title=. ArXiv preprint arXiv:2303.01469 , year=
work page internal anchor Pith review arXiv
-
[40]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song , title=. ArXiv preprint arXiv:2410.11081 , year=
work page internal anchor Pith review arXiv
-
[42]
Flow Matching for Conditional Text Generation in a Few Sampling Steps , journal=
Hu, Vincent and Wu, Di and Asano, Yuki and Mettes, Pascal and Fernando, Basura and Ommer, Bj. Flow Matching for Conditional Text Generation in a Few Sampling Steps , journal=
-
[43]
Ren and Justin Lidard and Lars Lien Ankile and Anthony Simeonov and Pulkit Agrawal and Anirudha Majumdar and Benjamin Burchfiel and Hongkai Dai and Max Simchowitz , title=
Allen Z. Ren and Justin Lidard and Lars Lien Ankile and Anthony Simeonov and Pulkit Agrawal and Anirudha Majumdar and Benjamin Burchfiel and Hongkai Dai and Max Simchowitz , title=. The Thirteenth International Conference on Learning Representations , year=
- [44]
-
[45]
Wenxuan Song and Jiayi Chen and Pengxiang Ding and Yuxin Huang and Han Zhao and Donglin Wang and Haoang Li , title=. ArXiv preprint arXiv:2506.13725 , year=
-
[46]
Proceedings of Thirty-Ninth AAAI Conference on Artificial Intelligence , year=
Qinglun Zhang and Zhen Liu and Haoqiang Fan and Guanghui Liu and Bing Zeng and Shuaicheng Liu , title=. Proceedings of Thirty-Ninth AAAI Conference on Artificial Intelligence , year=
-
[47]
Thomas and Emma Brunskill , title=
Philip S. Thomas and Emma Brunskill , title=. ArXiv preprint arXiv:1706.06643 , year=
-
[48]
Trust region policy optimization,
John Schulman and Sergey Levine and Philipp Moritz and Michael I. Jordan and Pieter Abbeel , title=. ArXiv preprint arXiv:1502.05477 , archivePrefix=
-
[49]
arXiv preprint arXiv:2411.04996 , year =
Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models , author=. arXiv preprint arXiv:2411.04996 , year=
-
[50]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Droid: A large-scale in-the-wild robot manipulation dataset , author=. arXiv preprint arXiv:2403.12945 , year=
work page internal anchor Pith review arXiv
-
[51]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
arXiv preprint arXiv:2412.03555 (2024) 1
Paligemma 2: A family of versatile vlms for transfer , author=. arXiv preprint arXiv:2412.03555 , year=
-
[53]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
^3 : Permutation-Equivariant Visual Geometry Learning , author=. arXiv preprint arXiv:2507.13347 , year=
work page internal anchor Pith review arXiv
-
[54]
Rectified flow: A marginal preserving approach to o ptimal transport
Rectified flow: A marginal preserving approach to optimal transport , author=. arXiv preprint arXiv:2209.14577 , year=
-
[55]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning , author=. arXiv preprint arXiv:2306.03310 , year=
work page internal anchor Pith review arXiv
-
[56]
VP-VLA: Visual Prompting as an Interface for Vision-Language-Action Models
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization , author=. arXiv preprint arXiv:2510.03827 , year=
-
[57]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[58]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[59]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Vggt: Visual geometry grounded transformer , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[60]
F1: A vision-language-action model bridging understanding and generation to actions , author=. arXiv preprint arXiv:2509.06951 , year=
-
[61]
arXiv preprint arXiv:2511.16546 , year=
Progressive Supernet Training for Efficient Visual Autoregressive Modeling , author=. arXiv preprint arXiv:2511.16546 , year=
-
[62]
arXiv preprint arXiv:2512.21691 , year=
Analyzing the Mechanism of Attention Collapse in VGGT from a Dynamics Perspective , author=. arXiv preprint arXiv:2512.21691 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.