Recognition: unknown
Contrastive Attribution in the Wild: An Interpretability Analysis of LLM Failures on Realistic Benchmarks
Pith reviewed 2026-05-10 05:08 UTC · model grok-4.3
The pith
Token-level contrastive attribution using LRP yields informative signals for some LLM failures on realistic benchmarks but is not universally applicable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
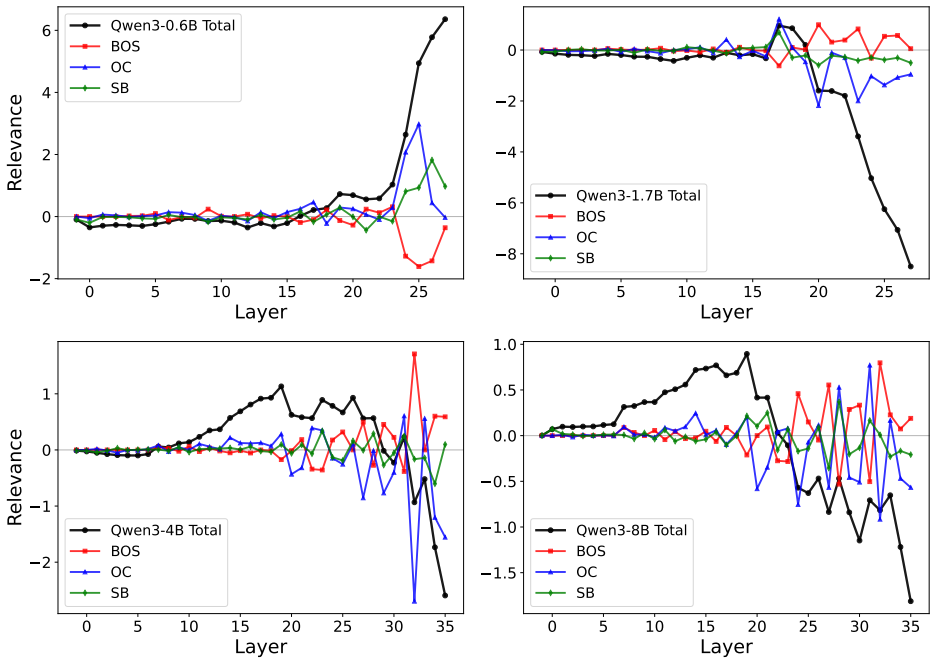
We formulate failure analysis as contrastive attribution, attributing the logit difference between an incorrect output token and a correct alternative to input tokens and internal model states, and introduce an efficient extension that enables construction of cross-layer attribution graphs for long-context inputs. Our systematic empirical study across benchmarks shows that this token-level contrastive attribution can yield informative signals in some failure cases, but is not universally applicable.
What carries the argument
Contrastive attribution, which traces the logit difference between a wrong output token and a correct alternative back to input tokens and states via LRP rules, extended to cross-layer graphs for long sequences.
If this is right
- Attribution patterns differ systematically across datasets, model sizes, and training checkpoints.
- In applicable failure cases the method can isolate specific input tokens or internal states driving the error.
- The approach has clear limits so it cannot replace broader suites of diagnostic tools for LLM analysis.
- Efficient cross-layer graph construction makes the technique feasible for realistic long-context benchmarks.
Where Pith is reading between the lines
- Developers could track how attribution quality evolves across training checkpoints to decide when interpretability tools become reliable.
- Combining contrastive attribution with other methods might cover the failure cases where LRP signals stay weak.
- The observed variability suggests benchmark design should include failure subsets where attribution is known to work well.
Load-bearing premise
The contrastive logit difference and LRP propagation rules accurately reflect the model's causal decision process rather than method-specific artifacts or correlations.
What would settle it
Compare attribution scores to results from causal interventions such as ablating the highest-scoring input tokens and checking whether the model's output flips as the scores would predict.
Figures















read the original abstract
Interpretability tools are increasingly used to analyze failures of Large Language Models (LLMs), yet prior work largely focuses on short prompts or toy settings, leaving their behavior on commonly used benchmarks underexplored. To address this gap, we study contrastive, LRP-based attribution as a practical tool for analyzing LLM failures in realistic settings. We formulate failure analysis as \textit{contrastive attribution}, attributing the logit difference between an incorrect output token and a correct alternative to input tokens and internal model states, and introduce an efficient extension that enables construction of cross-layer attribution graphs for long-context inputs. Using this framework, we conduct a systematic empirical study across benchmarks, comparing attribution patterns across datasets, model sizes, and training checkpoints. Our results show that this token-level contrastive attribution can yield informative signals in some failure cases, but is not universally applicable, highlighting both its utility and its limitations for realistic LLM failure analysis. Our code is available at: https://aka.ms/Debug-XAI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces contrastive LRP-based attribution to analyze LLM failures on realistic benchmarks. It formulates the task as attributing the logit difference between an incorrect output token and a correct alternative, extends LRP with an efficient cross-layer mechanism for long-context inputs, and reports a systematic empirical comparison of attribution patterns across datasets, model sizes, and training checkpoints. The central conclusion is that token-level contrastive attribution produces informative signals in some failure cases but is not universally applicable.
Significance. If the attributions are faithful to causal token contributions, the work would supply a practical interpretability tool for debugging LLMs on standard benchmarks rather than toy settings, with the multi-model, multi-dataset design helping to delineate the method's scope and limits.
major comments (2)
- [§4] §4 (Empirical evaluation): the paper reports observed attribution patterns but provides no quantitative definition or metric for what constitutes an 'informative signal' (e.g., no correlation with perturbation effects on the incorrect-vs-correct logit gap), leaving the strength of the utility claim only partially supported.
- [§3.2] §3.2 (LRP extension): no intervention or faithfulness tests (token ablation, activation patching, or logit-difference sensitivity) are described to confirm that the contrastive LRP scores track causal contributions rather than propagation artifacts from LayerNorm, attention, or residual handling; this is load-bearing for interpreting the patterns as diagnostic of failure modes.
minor comments (2)
- The abstract would be improved by naming the specific benchmarks and model families used, rather than referring only to 'realistic benchmarks.'
- [Figures] Figure captions for the cross-layer graphs should explicitly define the sign and magnitude encoding of the attribution edges.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our approach and outlining planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Empirical evaluation): the paper reports observed attribution patterns but provides no quantitative definition or metric for what constitutes an 'informative signal' (e.g., no correlation with perturbation effects on the incorrect-vs-correct logit gap), leaving the strength of the utility claim only partially supported.
Authors: We agree that a quantitative metric would make the notion of 'informative signal' more precise and would better support the utility claims. In the current manuscript, we use the term to describe attribution patterns that highlight input tokens whose removal or perturbation would be expected to affect the incorrect-versus-correct logit difference, based on the systematic visual and comparative analysis across datasets, model sizes, and checkpoints. To address the concern, the revised version will introduce an explicit quantitative metric: the Spearman rank correlation between token attribution scores and the change in logit gap after ablating the highest-attributed tokens. We will report these correlations separately for the subsets of cases where patterns appeared informative versus those where they did not, thereby providing a clearer, data-driven delineation of the method's scope. revision: yes
-
Referee: [§3.2] §3.2 (LRP extension): no intervention or faithfulness tests (token ablation, activation patching, or logit-difference sensitivity) are described to confirm that the contrastive LRP scores track causal contributions rather than propagation artifacts from LayerNorm, attention, or residual handling; this is load-bearing for interpreting the patterns as diagnostic of failure modes.
Authors: We acknowledge that explicit faithfulness validation is important for any attribution method, especially when extending LRP to contrastive logit differences and long contexts. The cross-layer mechanism we introduce follows the standard LRP propagation rules for attention, residuals, and LayerNorm that have been validated in prior transformer work; our contribution is the efficient aggregation across layers for long sequences. Because the paper's primary goal was to apply the method to realistic benchmarks and document observed patterns (including where they fail to be informative), we did not include new intervention experiments. In the revision we will add a dedicated limitations subsection that explicitly discusses potential propagation artifacts from LayerNorm and residual connections, notes the absence of direct causal tests, and frames the multi-model, multi-dataset consistency as indirect empirical support rather than definitive proof of causality. This will allow readers to interpret the diagnostic value of the patterns with appropriate caution. revision: partial
Circularity Check
No circularity: purely empirical comparison of attribution patterns
full rationale
The paper defines contrastive attribution as the attribution of logit differences between incorrect and correct output tokens using LRP propagation, introduces a cross-layer extension for long contexts, and reports observed patterns across benchmarks, model sizes, and checkpoints. No derivations, predictions, or first-principles results are claimed; conclusions rest on direct empirical comparisons without parameter fitting to target outcomes, self-definitional reductions, or load-bearing self-citations. The analysis is self-contained and falsifiable via replication on the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LRP attribution rules can be applied to the logit difference between incorrect and correct tokens in transformer models
Reference graph
Works this paper leans on
-
[1]
Achtibat, R., Hatefi, S. M. V., Dreyer, M., Jain, A., Wiegand, T., Lapuschkin, S., and Samek, W. Attnlrp: Attention-aware layer-wise relevance propagation for transformers. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URLhttps://openreview.net/forum?id=emtXYlBrNF
2024
-
[2]
XAI for transformers: Better explanations through conservative propagation
Ali, A., Schnake, T., Eberle, O., Montavon, G., Müller, K., and Wolf, L. XAI for transformers: Better explanations through conservative propagation. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvári, C., Niu, G., and Sabato, S. (eds.),International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 ofProceed...
2022
-
[3]
Ameisen, E., Lindsey, J., Pearce, A., Gurnee, W., Turner, N. L., Chen, B., Citro, C., Abrahams, D., Carter, S., Hosmer, B., Marcus, J., Sklar, M., Templeton, A., Bricken, T., McDougall, C., Cunningham, H., Henighan, T., Jermyn, A., Jones, A., Persic, A., Qi, Z., Ben Thompson, T., Zimmerman, S., Rivoire, K., Conerly, T., Olah, C., and Batson, J. Circuit tr...
2025
-
[4]
Y.Gan,C.Li,J.Xie,L.Wen,M.Purver,andM.Poesio
Andrews, P., Benhalloum, A., Bertran, G. M.-T., Bettini, M., Budhiraja, A., Cabral, R. S., Do, V., Froger, R., Garreau, E., Gaya, J.-B., Laurençon, H., Lecanu, M., Malkan, K., Mekala, D., Ménard, P., Mialon, G., Piterbarg, U., Plekhanov, M., Rita, M., Rusakov, A., Scialom, T., Vorotilov, V., Wang, M., and Yu, I. Are: Scaling up agent environments and eval...
-
[5]
A close look at decomposition-based xai-methods for transformer language models, 2025
Arras, L., Puri, B., Kahardipraja, P., Lapuschkin, S., and Samek, W. A close look at decomposition-based xai-methods for transformer language models, 2025. URL https:// arxiv.org/abs/2502.15886
-
[6]
Ashury-Tahan, S., Mai, Y., Bandel, E., Shmueli-Scheuer, M., and Choshen, L. Errormap and erroratlas: Charting the failure landscape of large language models, 2026. URLhttps: //arxiv.org/abs/2601.15812
-
[7]
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one, 10(7):e0130140, 2015
Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.-R., and Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one, 10(7):e0130140, 2015
2015
-
[8]
Monitoring reasoning models for misbehavior.arXiv preprint arXiv:2503.11926,
Baker, B., Huizinga, J., Gao, L., Dou, Z., Guan, M. Y., Madry, A., Zaremba, W., Pachocki, J., and Farhi, D. Monitoring reasoning models for misbehavior and the risks of promoting obfuscation, 2025. URLhttps://arxiv.org/abs/2503.11926
-
[9]
doi:10.48550/arXiv.2504.17550 , abstract =
Bang, Y., Ji, Z., Schelten, A., Hartshorn, A., Fowler, T., Zhang, C., Cancedda, N., and Fung, P. Hallulens: Llm hallucination benchmark, 2025. URLhttps://arxiv.org/abs/2504.17550
-
[10]
Spectral filters, dark signals, and attention sinks
Cancedda, N. Spectral filters, dark signals, and attention sinks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 4792–4808, 2024. 16
2024
-
[11]
Why Do Multi-Agent LLM Systems Fail?
Cemri, M., Pan, M. Z., Yang, S., Agrawal, L. A., Chopra, B., Tiwari, R., Keutzer, K., Parameswaran, A., Klein, D., Ramchandran, K., Zaharia, M., Gonzalez, J. E., and Stoica, I. Why do multi-agent llm systems fail?, 2025. URLhttps://arxiv.org/abs/2503.13657
work page internal anchor Pith review arXiv 2025
-
[12]
, Xie X: A survey on evaluation of large language models
Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P. S., Yang, Q., and Xie, X. A survey on evaluation of large language models.ACM Trans. Intell. Syst. Technol., 15(3), March 2024. ISSN 2157-6904. doi: 10.1145/3641289. URLhttps://doi.org/10.1145/3641289
-
[13]
M., and Lee, S
Covert, I., Lundberg, S. M., and Lee, S. Explaining by removing: A unified framework for model explanation.J. Mach. Learn. Res., 22:209:1–209:90, 2021. URLhttps://jmlr.org/ papers/v22/20-1316.html
2021
-
[14]
URL https://doi.org/10.18653/v1/2022.acl -long.581
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., and Wei, F. Knowledge neurons in pretrained transformers. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.),Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8493–8502, Dublin, Ireland, May 2022. Association for Computational Linguistic...
-
[15]
Graphghost: Tracing structures behind large language models, 2025
Dai, X., Guo, K., Lo, C.-H., Zeng, S., Ding, J., Luo, D., Mukherjee, S., and Tang, J. Graphghost: Tracing structures behind large language models, 2025. URLhttps://arxiv.org/abs/2510. 08613
2025
-
[16]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI, Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al. Deepseek-v3.2: Pushing the frontier of open large language models, 2025. URL https://arxiv.org/abs/2512.02556
work page internal anchor Pith review arXiv 2025
-
[17]
Extraction of salient sentences from labelled documents, 2015
Denil, M., Demiraj, A., and de Freitas, N. Extraction of salient sentences from labelled documents, 2015. URLhttps://arxiv.org/abs/1412.6815
-
[18]
Transcoders find interpretable LLM feature circuits
Dunefsky, J., Chlenski, P., and Nanda, N. Transcoders find interpretable LLM feature circuits. In Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J. M., and Zhang, C. (eds.),Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, Dec...
2024
-
[19]
and Voita, E
Ferrando, J. and Voita, E. Information flow routes: Automatically interpreting language models at scale. In Al-Onaizan, Y., Bansal, M., and Chen, Y. (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pp. 17432–17445. Association for Computational Linguistics,
2024
-
[20]
Information Flow Routes: Automatically Interpreting Language Models at Scale , booktitle =
doi: 10.18653/V1/2024.EMNLP-MAIN.965. URL https://doi.org/10.18653/v1/ 2024.emnlp-main.965
-
[21]
I., Tsiamas, I., and Costa-jussà, M
Ferrando, J., Gállego, G. I., Tsiamas, I., and Costa-jussà, M. R. Explaining how transformers use context to build predictions. In Rogers, A., Boyd-Graber, J. L., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 5486–5513...
- [22]
-
[23]
Fong, R. C. and Vedaldi, A. Interpretable explanations of black boxes by meaningful perturba- tion. InIEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pp. 3449–3457. IEEE Computer Society, 2017. doi: 10.1109/ICCV.2017.371. URL https://doi.org/10.1109/ICCV.2017.371
-
[24]
The llm evaluation guidebook, 2025
Fourrier, C., Frere, T., Penedo, G., and Wolf, T. The llm evaluation guidebook, 2025. URL https://huggingface.co/spaces/OpenEvals/evaluation-guidebook#recommendations
2025
-
[25]
Boyi Deng, Yu Wan, Baosong Yang, Yidan Zhang, and Fuli Feng
Galichin, A., Dontsov, A., Druzhinina, P., Razzhigaev, A., Rogov, O. Y., Tutubalina, E., and Oseledets, I. I have covered all the bases here: Interpreting reasoning features in large language models via sparse autoencoders, 2025. URLhttps://arxiv.org/abs/2503.18878
-
[26]
Transformer Feed-Forward Layers Are Key-Value Memories
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.),Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 5484–5495, Online and Punta Cana, Dominican Republic, November 2021. Association for Computatio...
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[27]
Goldowsky-Dill, N., MacLeod, C., Sato, L., and Arora, A. Localizing model behavior with path patching, 2023. URLhttps://arxiv.org/abs/2304.05969
-
[28]
Circuit-tracer: A new library for finding feature circuits
Hanna, M., Piotrowski, M., Lindsey, J., and Ameisen, E. Circuit-tracer: A new library for finding feature circuits. In Belinkov, Y., Mueller, A., Kim, N., Mohebbi, H., Chen, H., Arad, D., and Sarti, G. (eds.),Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp. 239–249, Suzhou, China, November 2025. Associat...
-
[29]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
Heimersheim, S. and Nanda, N. How to use and interpret activation patching, 2024. URL https://arxiv.org/abs/2404.15255
-
[30]
Measuring mathematical problem solving with the MATH dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URLhttps://openreview.net/forum?id=7Bywt2mQsCe
2021
-
[31]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., and Liu, T. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Trans. Inf. Syst., 43(2), January 2025. ISSN 1046-8188. doi: 10.1145/3703155. URLhttps://doi.org/10.1145/3703155
-
[32]
J., Madotto, A., and Fung, P
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., and Fung, P. Survey of hallucination in natural language generation.ACM Comput. Surv., 55(12), March
-
[33]
ISSN 0360-0300. doi: 10.1145/3571730. URLhttps://doi.org/10.1145/3571730
-
[34]
Beyond black & white: Leveraging annotator disagreement via soft-label multi-task learning,
Kobayashi, G., Kuribayashi, T., Yokoi, S., and Inui, K. Incorporating residual and normalization layers into analysis of masked language models. In Moens, M., Huang, X., Specia, L., and Yih, S. W. (eds.),Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 ...
-
[35]
Kramár, J., Lieberum, T., Shah, R., and Nanda, N. Atp*: An efficient and scalable method for localizing LLM behaviour to components.CoRR, abs/2403.00745, 2024. doi: 10.48550/ARXIV. 2403.00745. URLhttps://doi.org/10.48550/arXiv.2403.00745
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[36]
HaluEval: A large-scale hallucination evaluation benchmark for large language models
Li, J., Cheng, X., Zhao, X., Nie, J.-Y., and Wen, J.-R. HaluEval: A large-scale hallucination evaluation benchmark for large language models. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 6449–6464, Singapore, December 2023. Association for Computational Linguisti...
2023
-
[37]
From System 1 to System 2: A Survey of Reasoning Large Language Models
Li, Z.-Z., Zhang, D., Zhang, M.-L., Zhang, J., Liu, Z., Yao, Y., Xu, H., Zheng, J., Wang, P.-J., Chen, X., Zhang, Y., Yin, F., Dong, J., Li, Z., Bi, B.-L., Mei, L.-R., Fang, J., Liang, X., Guo, Z., Song, L., and Liu, C.-L. From system 1 to system 2: A survey of reasoning large language models, 2025. URLhttps://arxiv.org/abs/2502.17419
work page internal anchor Pith review arXiv 2025
-
[38]
Lin, S., Hilton, J., and Evans, O. TruthfulQA: Measuring how models mimic human falsehoods. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.),Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.186...
-
[39]
Lindsey, J., Gurnee, W., Ameisen, E., Chen, B., Pearce, A., Turner, N. L., Citro, C., Abrahams, D., Carter, S., Hosmer, B., Marcus, J., Sklar, M., Templeton, A., Bricken, T., McDougall, C., Cunningham, H., Henighan, T., Jermyn, A., Jones, A., Persic, A., Qi, Z., Thompson, T. B., Zimmerman, S., Rivoire, K., Conerly, T., Olah, C., and Batson, J. On the biol...
2025
-
[40]
Attribot: A bag of tricks for efficiently approximating leave-one-out context attribution
Liu, F., Kandpal, N., and Raffel, C. Attribot: A bag of tricks for efficiently approximating leave-one-out context attribution. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/forum?id=9kJperA2a4
2025
-
[41]
S., Wang, Y., and Zhang, L
Liu, J., Xia, C. S., Wang, Y., and Zhang, L. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id= 1qvx610Cu7
2023
-
[42]
Evaluating language models for efficient code generation
Liu, J., Xie, S., Wang, J., Wei, Y., Ding, Y., and Zhang, L. Evaluating language models for efficient code generation. InFirst Conference on Language Modeling, 2024. URLhttps: //openreview.net/forum?id=IBCBMeAhmC
2024
-
[43]
Lundberg, S. M. and Lee, S. A unified approach to interpreting model predictions. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (eds.),Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, US...
2017
-
[44]
From understanding to utilization: A survey on explainability for large language models, 2024
Luo, H. and Specia, L. From understanding to utilization: A survey on explainability for large language models, 2024. URLhttps://arxiv.org/abs/2401.12874. 19
-
[45]
DoVer : Intervention-driven auto debugging for LLM multi-agent systems
Ma, M., Zhang, J., Yang, F., Kang, Y., Lin, Q., Yang, T., Rajmohan, S., and Zhang, D. Dover: Intervention-driven auto debugging for llm multi-agent systems, 2025. URLhttps: //arxiv.org/abs/2512.06749
-
[47]
Locating and editing factual associations in gpt
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in gpt. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 17359–17372. Curran Associates, Inc., 2022
2022
-
[48]
S., Andonian, A
Meng, K., Sharma, A. S., Andonian, A. J., Belinkov, Y., and Bau, D. Mass-editing memory in a transformer. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=MkbcAHIYgyS
2023
-
[49]
Attribution patching: Activation patching at industrial scale
Nanda, N. Attribution patching: Activation patching at industrial scale. 2023. URLhttps: //www.neelnanda.io/mechanistic-interpretability/attribution-patching
2023
-
[50]
and Bloom, J
Nanda, N. and Bloom, J. Transformerlens. https://github.com/TransformerLensOrg/ TransformerLens, 2022
2022
-
[51]
Olmo, T., :, Ettinger, A., Bertsch, A., Kuehl, B., Graham, D., Heineman, D., Groeneveld, D., Brahman, F., Timbers, F., Ivison, H., Morrison, J., Poznanski, J., Lo, K., Soldaini, L., Jordan, M., Chen, M., Noukhovitch, M., Lambert, N., Walsh, P., Dasigi, P., Berry, R., Malik, S., Shah, S., Geng, S., Arora, S., Gupta, S., Anderson, T., Xiao, T., Murray, T., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. URLhttps://arxiv.org/abs/2508. 10925
2025
-
[53]
Introducing gpt-5, 2025
OpenAI. Introducing gpt-5, 2025. URLhttps://openai.com/index/introducing-gpt-5/
2025
-
[54]
D., Ermon, S., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
- [55]
-
[56]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Simonyan, K., Vedaldi, A., and Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In Bengio, Y. and LeCun, Y. (eds.),2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Workshop Track Proceedings, 2014. URLhttp://arxiv.org/abs/1312.6034. 20
work page Pith review arXiv 2014
-
[57]
SmoothGrad: removing noise by adding noise
Smilkov, D., Thorat, N., Kim, B., Viégas, F. B., and Wattenberg, M. Smoothgrad: removing noise by adding noise.CoRR, abs/1706.03825, 2017. URL http://arxiv.org/abs/1706. 03825
work page Pith review arXiv 2017
-
[58]
A survey on large language model reasoning failures
Song, P., Han, P., and Goodman, N. A survey on large language model reasoning failures. In 2nd AI for Math Workshop @ ICML 2025, 2025. URLhttps://openreview.net/forum?id= hsgMn4KBFG
2025
-
[59]
Axiomatic attribution for deep networks
Sundararajan, M., Taly, A., and Yan, Q. Axiomatic attribution for deep networks. In Precup, D. and Teh, Y. W. (eds.),Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 ofProceedings of Machine Learning Research, pp. 3319–3328. PMLR, 2017. URLhttp://proceedings.mlr.press/v70/...
2017
-
[60]
Kimi K2: Open Agentic Intelligence
Team, K., Bai, Y., Bao, Y., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., et al. Kimi k2: Open agentic intelligence, 2025. URLhttps://arxiv.org/abs/2507.20534
work page internal anchor Pith review arXiv 2025
-
[61]
N., Kaiser, L
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I. Attention is all you need. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.),Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[62]
R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J
Wang, K. R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[63]
URLhttps://openreview.net/forum?id=NpsVSN6o4ul
OpenReview.net, 2023. URLhttps://openreview.net/forum?id=NpsVSN6o4ul
2023
-
[64]
Efficient streaming language models with attention sinks
Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=NG7sS51zVF
2024
-
[65]
Diagnosing failures in large language models’ answers: Integrating error attribution into evaluation framework
Xu, Z., Xie, S., Lv, Q., Xiao, S., Song, L., Wenjuan, S., and Lin, F. Diagnosing failures in large language models’ answers: Integrating error attribution into evaluation framework. In Findings of the Association for Computational Linguistics: ACL 2025, pp. 21148–21165, 2025
2025
-
[66]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Token-importance guided direct preference optimization, 2025
Yang, N., Lin, H., Liu, Y., Tian, B., Liu, G., and Zhang, H. Token-importance guided direct preference optimization, 2025. URLhttps://arxiv.org/abs/2505.19653
-
[68]
Knowledge circuits in pretrained transformers
Yao, Y., Zhang, N., Xi, Z., Wang, M., Xu, Z., Deng, S., and Chen, H. Knowledge circuits in pretrained transformers. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Advances in Neural Information Processing Systems, volume 37, pp. 118571–118602. Curran Associates, Inc., 2024. doi: 10.52202/079017-3765. 21
-
[70]
and Nanda, N
Zhang, F. and Nanda, N. Towards best practices of activation patching in language mod- els: Metrics and methods. InThe Twelfth International Conference on Learning Repre- sentations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=Hf17y6u9BC
2024
-
[71]
From reasoning to answer: Empirical, attention- based and mechanistic insights into distilled DeepSeek r1 models
Zhang, J., Lin, Q., Rajmohan, S., and Zhang, D. From reasoning to answer: Empirical, attention- based and mechanistic insights into distilled DeepSeek r1 models. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 3985–4002, Suzhou, China, November
2025
-
[72]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/ 2025.emnlp-main.198. URLhttps://aclanthology.org/2025.emnlp-main.198/
-
[73]
Which agent causes task failures and when? on automated failure attribution of LLM multi-agent systems
Zhang, S., Yin, M., Zhang, J., Liu, J., Han, Z., Zhang, J., Li, B., Wang, C., Wang, H., Chen, Y., and Wu, Q. Which agent causes task failures and when? on automated failure attribution of LLM multi-agent systems. InForty-second International Conference on Machine Learning,
-
[74]
URLhttps://openreview.net/forum?id=GazlTYxZss
-
[75]
S iren ' s Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Zhang, Y., Li, Y., Cui, L., Cai, D., Liu, L., Fu, T., Huang, X., Zhao, E., Zhang, Y., Chen, Y., Wang, L., Luu, A. T., Bi, W., Shi, F., and Shi, S. Siren’s song in the ai ocean: A survey on hallucination in large language models.Computational Linguistics, 51(4):1373–1418, 12 2025. ISSN 0891-2017. doi: 10.1162/COLI.a.16. URLhttps://doi.org/10.1162/COLI.a.16
-
[76]
Verifyingchain-of-thought reasoning via its computational graph.CoRR, abs/2510.09312, 2025
Zhao, Z., Koishekenov, Y., Yang, X., Murray, N., and Cancedda, N. Verifying chain-of-thought reasoning via its computational graph, 2025. URLhttps://arxiv.org/abs/2510.09312
-
[77]
latency (seconds) / memory (MB)
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., and Hou, L. Instruction- following evaluation for large language models, 2023. URLhttps://arxiv.org/abs/2311. 07911. 22 A Batch-Packed Multi-Target Backpropagation for Attribution Graph Construction This appendix presents an efficient procedure for constructing attribution-graph edges...
2023
-
[78]
add all source nodes(s,i)such that|R(s) i |>0
-
[79]
add all target nodes(t,j)such that|R(t) j |>0
-
[80]
Dataset Description
add directed edges(s,i)→(t,j)for selected entriesA (s→t) j,i after pruning, with edge weight w(s,i)→(t,j)=A (s→t) j,i .(18) Pruning objectives.The interaction matricesA (s→t)are generally dense, making direct graph construction impractical. We therefore prune edges using magnitude-based criteria applied to |A(s→t)|. Pruning is performedindependently for e...
-
[81]
, "ground_truth
Lyon[13] .[14]", "ground_truth": "Paris, the capital of France." } - The "indexed_completion" field provides a tokenized version of the completion, where each token is followed by its index in square brackets. This will help you localize the position of tokens in the completion. - Both the "prompt" and "completion" fields may contain special tokens, e.g.,...
-
[82]
Assuming the target token is the model’s top-1 output token at the failure position (i.e., the token with the highest logit)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.