Recognition: unknown
AnchorRefine: Synergy-Manipulation Based on Trajectory Anchor and Residual Refinement for Vision-Language-Action Models
Pith reviewed 2026-05-10 05:07 UTC · model grok-4.3
The pith
AnchorRefine factorizes VLA action prediction into a coarse trajectory anchor plus residual refinement to raise manipulation precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AnchorRefine decomposes VLA action modeling into a trajectory anchor planner that produces a coarse motion scaffold and a residual refinement module that corrects execution-level deviations to improve geometric and contact precision, together with a decision-aware gripper refinement mechanism. The approach is applied on top of existing regression-based and diffusion-based VLA backbones and evaluated on LIBERO, CALVIN, and real-robot tasks.
What carries the argument
The AnchorRefine hierarchical factorization that separates coarse trajectory anchor prediction from residual refinement of execution deviations.
If this is right
- Both regression and diffusion VLA models gain consistent success-rate improvements when the anchor-residual split is added.
- Simulation success rises by as much as 7.8 percent and real-world success by as much as 18 percent across the tested tasks.
- Geometric accuracy and contact-rich manipulation both benefit from the dedicated refinement stage.
- The same factorization works across multiple existing VLA backbones without requiring architecture redesign.
Where Pith is reading between the lines
- The separation could allow the anchor and refinement modules to be trained or optimized at different frequencies or with different loss weightings.
- Similar anchor-residual splits might apply to other robot control domains that mix large-scale navigation with fine manipulation.
- Real-world gains suggest the method may reduce sensitivity to small perceptual noise that currently causes contact failures.
Load-bearing premise
The premise that large motions inherently suppress small corrective signals in a single action space and that explicitly separating anchor from residual will improve precision without creating new coordination problems between the stages.
What would settle it
An experiment in which the identical VLA backbone trained without the anchor-residual split achieves equal or higher task success rates than the AnchorRefine version on the same LIBERO, CALVIN, and real-robot suites would falsify the central claim.
Figures







read the original abstract
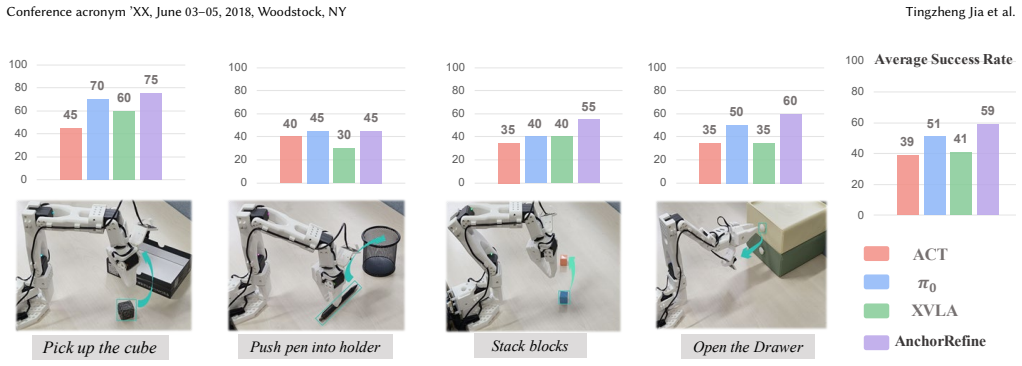
Precision-critical manipulation requires both global trajectory organization and local execution correction, yet most vision-language-action (VLA) policies generate actions within a single unified space. This monolithic formulation forces macro-level transport and micro-level refinement to be optimized under the same objective, causing large motions to dominate learning while suppressing small but failure-critical corrective signals. In contrast, human manipulation is structured by global movement planning together with continuous local adjustment during execution. Motivated by this principle, we propose AnchorRefine, a hierarchical framework that factorizes VLA action modeling into trajectory anchor and residual refinement. The anchor planner predicts a coarse motion scaffold, while the refinement module corrects execution-level deviations to improve geometric and contact precision. We further introduce a decision-aware gripper refinement mechanism to better capture the discrete and boundary-sensitive nature of gripper control. Experiments on LIBERO, CALVIN, and real-robot tasks demonstrate that AnchorRefine consistently improves both regression-based and diffusion-based VLA backbones, yielding gains of up to 7.8% in simulation success rate and 18% in real-world success rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AnchorRefine, a hierarchical framework for vision-language-action (VLA) models that factorizes action generation into a coarse trajectory anchor planner and a residual refinement module (plus a decision-aware gripper refinement component). It argues that monolithic unified action spaces cause large motions to dominate optimization and suppress small corrective signals critical for precision manipulation, and reports empirical gains of up to 7.8% success rate on LIBERO/CALVIN simulation benchmarks and 18% on real-robot tasks when applied to both regression- and diffusion-based VLA backbones.
Significance. If the reported gains prove robust and causally linked to the anchor-residual factorization (rather than added capacity or separate objectives), the approach could provide a lightweight, backbone-agnostic way to improve geometric and contact precision in VLA policies for manipulation, addressing a practical limitation in current end-to-end models.
major comments (2)
- [§1] §1: The core hypothesis that monolithic action spaces cause large motions to dominate learning and suppress micro-level corrective signals is presented without any direct quantitative support, such as measurements of relative gradient norms, loss contributions, or optimization dynamics for |Δa| below a threshold versus macro actions in the baseline models.
- [§4] §4: The experimental claims of consistent improvements (up to 7.8% simulation success rate and 18% real-world) over regression and diffusion baselines lack supporting details on statistical significance, error bars, number of evaluation trials, or ablation studies that isolate the residual refinement module's contribution from confounding factors such as increased parameter count or auxiliary loss terms.
minor comments (1)
- [Abstract] The abstract and §1 could more explicitly name the specific VLA backbone architectures and task suites used in the reported experiments to allow immediate assessment of the scope of the gains.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without misrepresenting our current results.
read point-by-point responses
-
Referee: §1: The core hypothesis that monolithic action spaces cause large motions to dominate learning and suppress micro-level corrective signals is presented without any direct quantitative support, such as measurements of relative gradient norms, loss contributions, or optimization dynamics for |Δa| below a threshold versus macro actions in the baseline models.
Authors: We acknowledge that the submitted manuscript motivates the hypothesis from task structure and empirical gains but does not supply direct quantitative diagnostics such as gradient-norm ratios or per-component loss contributions. The consistent improvements across both regression and diffusion backbones provide indirect support, yet we agree that explicit measurements would strengthen the claim. In the revised version we will add a dedicated analysis subsection that reports relative gradient magnitudes and loss contributions for small versus large actions on the LIBERO benchmark for the baseline models, thereby furnishing the requested quantitative evidence. revision: yes
-
Referee: §4: The experimental claims of consistent improvements (up to 7.8% simulation success rate and 18% real-world) over regression and diffusion baselines lack supporting details on statistical significance, error bars, number of evaluation trials, or ablation studies that isolate the residual refinement module's contribution from confounding factors such as increased parameter count or auxiliary loss terms.
Authors: We agree that the experimental reporting would be more rigorous with explicit statistical details and controlled ablations. The current manuscript presents mean success rates but omits error bars, trial counts, and capacity-matched controls. In the revision we will (i) report standard deviations over at least three random seeds, (ii) state the exact number of evaluation episodes per task, (iii) add p-value or confidence-interval indicators for the reported gains, and (iv) include an ablation that compares AnchorRefine against a capacity-matched baseline and against a version without the decision-aware gripper refinement, thereby isolating the contribution of the residual module. revision: yes
Circularity Check
No significant circularity; empirical validation on external benchmarks is independent of the architectural proposal.
full rationale
The paper's core contribution is an architectural factorization of VLA action spaces into a coarse trajectory anchor plus residual refinement (plus gripper module), motivated by an analogy to human manipulation. This is presented as a design choice rather than a derivation from equations or fitted parameters. All reported gains (up to 7.8% simulation, 18% real-robot) are empirical results on held-out external benchmarks (LIBERO, CALVIN, real-robot tasks) against regression and diffusion baselines. No self-definitional reductions, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the abstract or described claims. The method is therefore self-contained: the factorization is an explicit modeling decision whose value is measured externally rather than forced by construction from the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal
-
[2]
In2025 IEEE International Conference on Robotics and Automation (ICRA)
From imitation to refinement-residual rl for precise assembly. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschan- nen, Emanuele Bugliarello, et al. 2024. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726(2024)
work page internal anchor Pith review arXiv 2024
-
[5]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. 2024. 𝜋0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164(2024)
work page internal anchor Pith review arXiv 2024
-
[6]
Kevin Black, Mitsuhiko Nakamoto, Pranav Atreya, Homer Rich Walke, Chelsea Finn, Aviral Kumar, and Sergey Levine. [n. d.]. Zero-Shot Robotic Manipulation with Pre-Trained Image-Editing Diffusion Models. InThe Twelfth International Conference on Learning Representations
-
[7]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control.7th Annual Conference on Robot Learning(2023)
2023
-
[8]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al . 2025. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv:2503.06669(2025)
work page internal anchor Pith review arXiv 2025
-
[9]
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. 2025. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111(2025)
work page internal anchor Pith review arXiv 2025
- [10]
- [11]
-
[12]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burch- fiel, Russ Tedrake, and Shuran Song. 2025. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research44, 10-11 (2025), 1684–1704
2025
-
[13]
Todor Davchev, Kevin Sebastian Luck, Michael Burke, Franziska Meier, Stefan Schaal, and Subramanian Ramamoorthy. 2022. Residual learning from demonstra- tion: Adapting dmps for contact-rich manipulation.IEEE Robotics and Automation Letters7, 2 (2022), 4488–4495
2022
-
[14]
Digby Elliott, Steve Hansen, Lawrence EM Grierson, James Lyons, Simon J Ben- nett, and Spencer J Hayes. 2010. Goal-directed aiming: two components but multiple processes.Psychological bulletin136, 6 (2010), 1023
2010
-
[15]
Digby Elliott, Werner F Helsen, and Romeo Chua. 2001. A century later: Wood- worth’s (1899) two-component model of goal-directed aiming.Psychological bulletin127, 3 (2001), 342
2001
-
[16]
Jiayuan Gu, Sean Kirmani, Paul Wohlhart, Yao Lu, Montserrat Gonzalez Arenas, Kanishka Rao, Wenhao Yu, Chuyuan Fu, Keerthana Gopalakrishnan, Zhuo Xu, et al. 2023. Robotic task generalization via hindsight trajectory sketches. InFirst Workshop on Out-of-Distribution Generalization in Robotics at CoRL 2023
2023
-
[17]
Siddhant Haldar, Zhuoran Peng, and Lerrel Pinto. 2024. Baku: An efficient transformer for multi-task policy learning.Advances in Neural Information Processing Systems37 (2024), 141208–141239
2024
-
[18]
Siddhant Haldar and Lerrel Pinto. [n. d.]. Point Policy: Unifying Observations and Actions with Key Points for Robot Manipulation. In9th Annual Conference on Robot Learning
-
[19]
Peng Hao, Tao Lu, Shaowei Cui, Junhang Wei, Yinghao Cai, and Shuo Wang
-
[20]
Meta-Residual Policy Learning: Zero-Trial Robot Skill Adaptation via Knowledge Fusion.IEEE Robotics and Automation Letters7, 2 (2022), 3656–3663. doi:10.1109/LRA.2022.3146916
-
[21]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[22]
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, et al . 2025. Dita: Scaling diffusion transformer for generalist vision-language-action policy. InProceedings of the IEEE/CVF International Conference on Computer Vision. 7686–7697
2025
-
[23]
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. [n. d.]. Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations. InForty- second International Conference on Machine Learning
-
[24]
Haifeng Huang, Xinyi Chen, Yilun Chen, Hao Li, Xiaoshen Han, Zehan Wang, Tai Wang, Jiangmiao Pang, and Zhou Zhao. 2025. Roboground: Robotic manipulation with grounded vision-language priors. InProceedings of the Computer Vision and Pattern Recognition Conference. 22540–22550
2025
-
[25]
Tobias Johannink, Shikhar Bahl, Ashvin Nair, Jianlan Luo, Avinash Kumar, Matthias Loskyll, Juan Aparicio Ojea, Eugen Solowjow, and Sergey Levine. 2019. Residual Reinforcement Learning for Robot Control. In2019 International Con- ference on Robotics and Automation (ICRA)
2019
-
[26]
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. 2024. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning
2024
-
[27]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakr- ishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. OpenVLA: An Open-Source Vision- Language-Action Model. In8th Annual Conference on Robo...
2024
-
[28]
Michelle A Lee, Yuke Zhu, Krishnan Srinivasan, Parth Shah, Silvio Savarese, Li Fei-Fei, Animesh Garg, and Jeannette Bohg. 2019. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In2019 International conference on robotics and automation (ICRA). IEEE, 8943–8950
2019
-
[29]
Yi Li, Yuquan Deng, Jesse Zhang, Joel Jang, Marius Memmel, Caelan Reed Garrett, Fabio Ramos, Dieter Fox, Anqi Li, Abhishek Gupta, et al. [n. d.]. HAMSTER: Hi- erarchical Action Models for Open-World Robot Manipulation. InThe Thirteenth International Conference on Learning Representations
-
[30]
Juyi Lin, Amir Taherin, Arash Akbari, Arman Akbari, Lei Lu, Guangyu Chen, Taskin Padir, Xiaomeng Yang, Weiwei Chen, Yiqian Li, et al. 2025. Vote: vision- language-action optimization with trajectory ensemble voting.arXiv preprint arXiv:2507.05116(2025). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Tingzheng Jia et al
-
[31]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36 (2023), 44776–44791
2023
-
[32]
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. [n. d.]. RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation. InThe Thirteenth International Conference on Learning Representations
-
[33]
Xiao Ma, Sumit Patidar, Iain Haughton, and Stephen James. 2024. Hierarchical diffusion policy for kinematics-aware multi-task robotic manipulation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18081–18090
2024
-
[34]
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. 2024. A survey on vision-language-action models for embodied ai.arXiv preprint arXiv:2405.14093(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Oier Mees, Dibya Ghosh, Karl Pertsch, Kevin Black, Homer Rich Walke, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. 2024. Octo: An open-source generalist robot policy. InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024
2024
-
[36]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. 2022. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters7, 3 (2022), 7327–7334
2022
-
[37]
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. 2024. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 6892–6903
2024
-
[38]
Y Paulignan, C MacKenzie, R Marteniuk, and Marc Jeannerod. 1991. Selective perturbation of visual input during prehension movements: 1. The effects of changing object position.Experimental brain research83, 3 (1991), 502–512
1991
-
[39]
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Yağmurlu, Fabian Otto, and Rudolf Lioutikov. [n. d.]. FLOWER: Democratizing Generalist Robot Policies with Efficient Vision-Language-Flow Models. In9th Annual Conference on Robot Learning
- [40]
-
[41]
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. [n. d.]. Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation. InThe Thirteenth International Conference on Learning Representations
-
[42]
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. 2023. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning. PMLR, 1723–1736
2023
-
[43]
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. [n. d.]. DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control. In9th Annual Conference on Robot Learning
-
[44]
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. 2025. Tinyvla: Towards fast, data- efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters(2025)
2025
-
[45]
Junjie Wen, Yichen Zhu, Minjie Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Xiaoyu Liu, Chaomin Shen, Yaxin Peng, and Feifei Feng. 2025. Diffusionvla: Scaling robot foundation models via unified diffusion and autoregression. In Forty-second International Conference on Machine Learning
2025
-
[46]
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. 2024. Unleashing Large-Scale Video Gen- erative Pre-training for Visual Robot Manipulation. InThe Twelfth International Conference on Learning Representations
2024
-
[47]
Zhou Xian, Nikolaos Gkanatsios, Theophile Gervet, Tsung-Wei Ke, and Katerina Fragkiadaki. 2023. Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation. In7th Annual Conference on Robot Learning
2023
-
[48]
Hewen Xiao, Youmin Gong, Jie Mei, Zihou Wu, Guangfu Ma, and Weiren Wu. 2026. Residual-learning-based landing control with gravity estimation for quadruped robot in low-gravity scenarios.Astrodynamics(2026), 1–14
2026
-
[49]
Likui Zhang, Tao Tang, Zhihao Zhan, Xiuwei Chen, Zisheng Chen, Jianhua Han, Jiangtong Zhu, Pei Xu, Hang Xu, Hefeng Wu, et al. 2026. AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2026
-
[50]
Wenbo Zhang, Tianrun Hu, Hanbo Zhang, Yanyuan Qiao, Yuchu Qin, Yang Li, Jiajun Liu, Tao Kong, Lingqiao Liu, and Xiao Ma. [n. d.]. Chain-of-Action: Trajectory Autoregressive Modeling for Robotic Manipulation. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems
-
[51]
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al . 2025. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference. 1702–1713
2025
-
[52]
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. 2023. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705(2023)
work page internal anchor Pith review arXiv 2023
-
[53]
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Tai Wang, Ya-Qin Zhang, Jingjing Liu, and Xianyuan Zhan. 2026. X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model. InThe Fourteenth International Conference on Learning Representations
2026
-
[54]
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. [n. d.]. TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies. InThe Thirteenth International Conference on Learning Representations
-
[55]
Dongxu Zhou, Ruiqing Jia, Haifeng Yao, and Mingzuo Xie. 2021. Robotic arm mo- tion planning based on residual reinforcement learning. In2021 13th International Conference on Computer and Automation Engineering (ICCAE). IEEE, 89–94. AnchorRefine: Trajectory Anchoring and Residual Refinement Conference acronym ’XX, June 03–05, 2018, Woodstock, NY A Appendix...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.