Recognition: unknown
Bridging the Reasoning Gap in Vietnamese with Small Language Models via Test-Time Scaling
Pith reviewed 2026-05-10 04:32 UTC · model grok-4.3
The pith
Supervised fine-tuning unlocks coherent reasoning explanations in small Vietnamese language models with a 77% quality gain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
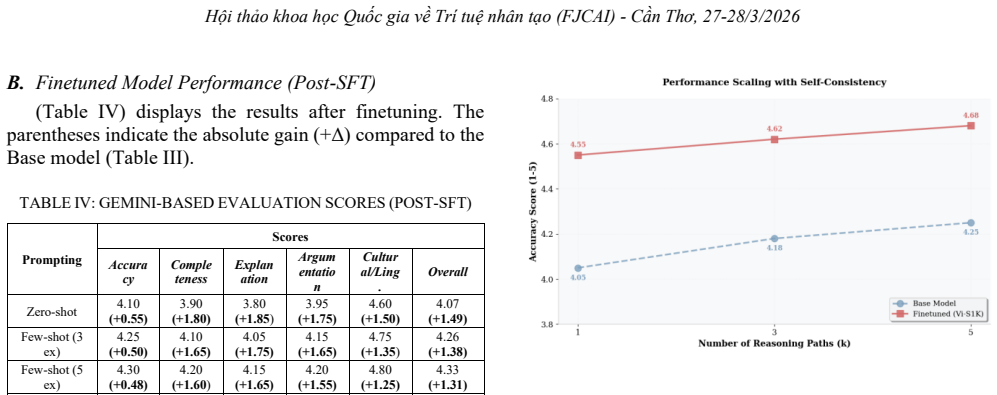
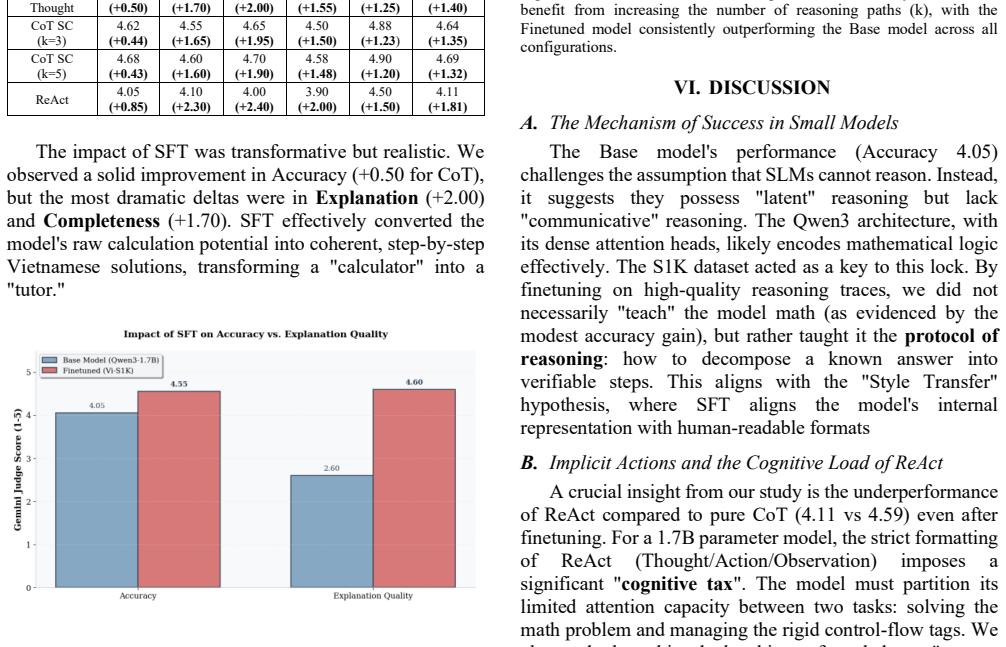
The Qwen3-1.7B base model shows robust latent knowledge (Accuracy: 4.05/5.00) yet suffers from a severe formatting gap in communication. Supervised Fine-Tuning on the Vi-S1K dataset functions as a critical reasoning unlocker, producing a 77% improvement in Explanation Quality and connecting raw calculation to pedagogical coherence. Prompting analysis finds that frameworks like ReAct impose a cognitive tax on small capacity, while pure Chain-of-Thought combined with Self-Consistency performs better, establishing SFT with simplified test-time scaling as the preferred strategy for edge deployment.
What carries the argument
Supervised Fine-Tuning (SFT) on the Vi-S1K localized reasoning dataset, which acts as a reasoning unlocker to convert latent calculation ability into coherent explanations.
Load-bearing premise
The LLM-as-a-Judge protocol reliably measures explanation quality and pedagogical coherence without introducing bias from the judge model or translation artifacts in the dataset.
What would settle it
A blind human evaluation of explanation samples from the base model and the SFT model on the Vi-Elementary-Bench to determine whether the reported 77% gain in quality holds under human assessment.
Figures

read the original abstract
The democratization of ubiquitous AI hinges on deploying sophisticated reasoning capabilities on resource-constrained devices. However, Small Language Models (SLMs) often face a "reasoning gap", particularly in non-English languages like Vietnamese, where they struggle to maintain coherent chains of thought. This paper investigates Test-Time Scaling strategies for the Qwen3-1.7B architecture within the context of Vietnamese Elementary Mathematics. We introduce Vi-S1K, a high-fidelity reasoning dataset localized via a Gemini 2.5 Flash-Lite powered pipeline, and Vi-Elementary-Bench, a dual-resource benchmark for rigorous evaluation. Using an LLM-as-a-Judge protocol, we reveal that the base model possesses robust latent knowledge (Accuracy: 4.05/5.00) but suffers from a severe "formatting gap" in communication. Supervised Fine-Tuning (SFT) acts as a critical "reasoning unlocker", yielding a 77% improvement in Explanation Quality and bridging the gap between raw calculation and pedagogical coherence. Furthermore, our analysis of prompting strategies uncovers a significant trade-off: structured frameworks like ReAct impose a "cognitive tax" on the 1.7B parameter capacity, degrading performance relative to pure Chain-of-Thought (CoT) combined with Self-Consistency. These findings establish a deployment hierarchy for SLMs, demonstrating that SFT combined with simplified test-time scaling is superior to complex agentic workflows for edge-based reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper explores test-time scaling strategies for the Qwen3-1.7B small language model on Vietnamese elementary mathematics tasks. It introduces the Vi-S1K dataset, created through a Gemini-powered localization pipeline, and the Vi-Elementary-Bench benchmark. The authors claim that the base model demonstrates high latent knowledge (4.05/5) but poor communication skills, and that supervised fine-tuning (SFT) serves as a 'reasoning unlocker' providing a 77% improvement in explanation quality according to an LLM-as-a-Judge evaluation. They also report that simpler prompting like Chain-of-Thought with Self-Consistency outperforms complex agentic approaches such as ReAct due to a 'cognitive tax' on small models.
Significance. If the reported improvements are robustly validated, the work would be significant for advancing reasoning capabilities in small models for non-English languages. It offers practical insights into when SFT is beneficial versus relying on test-time methods, and the new dataset and benchmark could facilitate further research in multilingual AI. The emphasis on deployment hierarchies for resource-constrained settings addresses an important gap in the field.
major comments (3)
- [Abstract] The 77% improvement in Explanation Quality is a key result, but the abstract does not specify the LLM judge model, the detailed rubric for assessing 'pedagogical coherence', any human validation or inter-annotator agreement, or statistical tests. This information is necessary to substantiate the claim that SFT bridges the gap between raw calculation and coherent explanations.
- [Abstract] Details on experimental setup are missing, including the baselines compared against, the train/test splits for Vi-S1K, the size of the dataset, and how Vi-Elementary-Bench is constructed. These omissions make it difficult to evaluate the reliability of the performance trade-offs between prompting strategies.
- [Abstract] The use of Gemini 2.5 Flash-Lite for localizing the dataset raises questions about potential stylistic bias in the evaluation if the judge model shares similar characteristics; the paper should address whether the judge favors outputs aligned with the localization style.
minor comments (1)
- The abstract employs colloquial phrases such as 'reasoning unlocker' and 'cognitive tax'; these should be defined more formally in the introduction or methods section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of clarity and rigor in our presentation. We address each major comment point by point below, committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The 77% improvement in Explanation Quality is a key result, but the abstract does not specify the LLM judge model, the detailed rubric for assessing 'pedagogical coherence', any human validation or inter-annotator agreement, or statistical tests. This information is necessary to substantiate the claim that SFT bridges the gap between raw calculation and coherent explanations.
Authors: We agree that the abstract, due to length constraints, omits key methodological details supporting this central claim. The LLM judge model, rubric for pedagogical coherence, human validation procedures, inter-annotator agreement, and statistical tests are described in full in Section 4.2 and the appendices. We will revise the abstract to name the judge model and briefly reference the evaluation protocol, directing readers to the main text for complete substantiation. revision: yes
-
Referee: [Abstract] Details on experimental setup are missing, including the baselines compared against, the train/test splits for Vi-S1K, the size of the dataset, and how Vi-Elementary-Bench is constructed. These omissions make it difficult to evaluate the reliability of the performance trade-offs between prompting strategies.
Authors: We acknowledge that the abstract lacks these experimental details, which are essential for assessing the reported trade-offs. The baselines, Vi-S1K train/test splits, dataset size, and Vi-Elementary-Bench construction are fully specified in Sections 3.1, 3.2, and 4.1. We will update the abstract with a concise summary of the setup and key elements to improve evaluability while maintaining brevity. revision: yes
-
Referee: [Abstract] The use of Gemini 2.5 Flash-Lite for localizing the dataset raises questions about potential stylistic bias in the evaluation if the judge model shares similar characteristics; the paper should address whether the judge favors outputs aligned with the localization style.
Authors: This concern about possible stylistic bias is valid and merits explicit treatment. Localization used Gemini 2.5 Flash-Lite, while the judge follows a distinct model and rubric centered on reasoning content and coherence. We will add a dedicated paragraph in the Limitations section of the revised manuscript to discuss this potential issue, describe mitigation steps via prompt design, and report any relevant sensitivity analyses. revision: yes
Circularity Check
No significant circularity; empirical measurements support the claims.
full rationale
The paper's derivation proceeds from dataset construction (Vi-S1K via Gemini pipeline), benchmark creation (Vi-Elementary-Bench), model training (SFT on Qwen3-1.7B), and evaluation via LLM-as-a-Judge protocol. The 77% Explanation Quality improvement is reported as a measured delta between base-model and SFT outputs on the same judge rubric, not a quantity presupposed by definition or obtained by fitting a parameter that is then renamed as a prediction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core result. The chain from inputs (dataset, models, prompts) to outputs (accuracy and quality scores) remains externally falsifiable against the benchmark and does not reduce to tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-as-a-Judge protocol produces unbiased and accurate scores for explanation quality and pedagogical coherence
Reference graph
Works this paper leans on
-
[1]
Scaling laws for neural language models,
J. Kaplan et al., “Scaling laws for neural language models,” ArXiv Prepr. ArXiv200108361, 2020, Accessed: Nov. Input Question (Vietnamese) Đề bài: "Hiện nay anh 15 tuổi. Năm trước tuổi anh gấp đôi tuổi em. Hỏi năm nay em bao nhiêu tuổi?" (Translation: Currently the brother is 15 years old. Last year, the brother was twice as old as the younger sibling. Ho...
2020
-
[2]
Năm trước, tuổi của anh là: 15 - 1 = 14 (tuổi)
-
[3]
Năm trước, tuổi của em là: 14 : 2 = 7 (tuổi)
-
[4]
Scaling Laws for Neural Language Models
Năm nay, tuổi của em là: 7 + 1 = 8 (tuổi). Đáp số: 8 tuổi. Analysis: The model correctly identifies the logic steps but struggles to maintain the strictly required Thought/Action/Observation structure, leading to "context crowding" and eventual generation failure. Analysis: The finetuned CoT model focuses purely on the arithmetic logic. The solution is co...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei et al., “Chain-of-thought prompting elicits reasoning in large language models,” Adv. Neural Inf. Process. Syst., vol. 35, pp. 24824–24837, 2022
2022
-
[6]
s1: Simple test-time scaling,
N. Muennighoff et al., “s1: Simple test-time scaling,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 20286–20332. Accessed: Nov. 23, 2025. [Online]. Available: https://aclanthology.org/2025.emnlp-main.1025/
2025
-
[8]
React: Synergizing reasoning and acting in language models,
S. Yao et al., “React: Synergizing reasoning and acting in language models,” in The eleventh international conference on learning representations, 2022. Accessed: Nov. 13, 2025. [Online]. Available: https://openreview.net/forum?id=WE_vluYUL-X
2022
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu et al., “LoRA: Low-Rank Adaptation of Large Language Models,” Oct. 16, 2021, arXiv: arXiv:2106.09685. doi: 10.48550/arXiv.2106.09685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2021
-
[10]
Language Models are Few-Shot Learners
T. B. Brown et al., “Language Models are Few-Shot Learners,” July 22, 2020, arXiv: arXiv:2005.14165. doi: 10.48550/arXiv.2005.14165
work page internal anchor Pith review doi:10.48550/arxiv.2005.14165 2020
-
[11]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
X. Wang et al., “Self-Consistency Improves Chain of Thought Reasoning in Language Models,” Mar. 07, 2023, arXiv: arXiv:2203.11171. doi: 10.48550/arXiv.2203.11171
-
[12]
Gemini: A Family of Highly Capable Multimodal Models
G. Team et al., “Gemini: A Family of Highly Capable Multimodal Models,” May 09, 2025, arXiv: arXiv:2312.11805. doi: 10.48550/arXiv.2312.11805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2025
-
[13]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng et al., “Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena,” Dec. 24, 2023, arXiv: arXiv:2306.05685. doi: 10.48550/arXiv.2306.05685. APPENDIX A. System Prompt for LLM-as-a-Judge Evaluation The following prompt was used to instruct Gemini 2.5 Flash-Lite in evaluating student model outputs. The content is presented in its original Vietnamese ...
work page internal anchor Pith review doi:10.48550/arxiv.2306.05685 2023
-
[14]
Đánh giá cả quá trình giải và kết quả cuối
Độ chính xác (Accuracy): So sánh kết quả cuối cùng với đáp án chuẩn. Đánh giá cả quá trình giải và kết quả cuối. - 5 điểm: Kết quả cuối cùng đúng hoàn toàn; cách giải đúng, không có sai sót quan trọng. - 4 điểm: Kết quả đúng; cách gi ải có l ỗi nhỏ (nhưng không làm thay đổi kết quả và không gây hiểu nhầm nghiêm trọng). - 3 điểm: Kết quả đúng nhưng cách gi...
-
[15]
- 5 điểm: Giải quyết đầy đủ tất cả yêu cầu của đề bài; không bỏ sót câu hỏi phụ; có kết luận rõ ràng
Tính đầy đủ (Completeness): Đánh giá việc giải quyết tất cả các yêu cầu của bài toán. - 5 điểm: Giải quyết đầy đủ tất cả yêu cầu của đề bài; không bỏ sót câu hỏi phụ; có kết luận rõ ràng. - 4 điểm: Hầu hết yêu cầu được giải quyết; có thể thiếu một chi tiết nhỏ hoặc kết luận chưa thật rõ ràng nhưng không làm mất ý chính. - 3 điểm: Đã giải quyết được yêu cầ...
-
[16]
- 5 điểm: Diễn đạt rất rõ ràng, mạch lạc; sử dụng thuật ngữ toán học tiếng Việt đúng và tự nhiên; mỗi bước đều dễ hiểu với học sinh tiểu học
Kh ả năng di ễn gi ải (Explanation): Khả năng gi ải thích rõ ràng bằng tiếng Việt. - 5 điểm: Diễn đạt rất rõ ràng, mạch lạc; sử dụng thuật ngữ toán học tiếng Việt đúng và tự nhiên; mỗi bước đều dễ hiểu với học sinh tiểu học. - 4 điểm: Nhìn chung rõ ràng, ch ỉ có vài chỗ diễn đạt hơi lủng củng nhưng vẫn dễ hiểu; thuật ngữ dùng đúng hầu hết. - 3 điểm: Giải ...
-
[17]
- 4 điểm: Logic chủ yếu đúng; có một vài chỗ chưa giải thích kỹ hoặc nhảy bước nhưng không dẫn tới sai lầm nghiêm trọng
Tính logic (Argumentation / Logical Structure): Lý luận có ch ặt ch ẽ không? Có hallucination (b ịa chuy ện) không? Hội thảo khoa học Quốc gia về Trí tuệ nhân tạo (FJCAI) - Cần Thơ, 27-28/3/2026 10 - 5 điểm: Logic hoàn toàn chặt chẽ từ đầu đến cuối; các bước suy lu ận h ợp lý, không mâu thu ẫn; không có hallucination; không dùng công thức sai. - 4 điểm: L...
2026
-
[18]
Bài giải: …
Phù hợp ngữ cảnh văn hóa (Cultural Context): Đánh giá mức độ phù hợp với bối cảnh văn hóa Việt Nam. - 5 điểm: Lời giải hoàn toàn phù hợp với cách trình bày thường thấy trong sách giáo khoa và giáo viên tiểu học Việt Nam; dùng dạng câu “Bài giải: …”, “Vậy số … là: …”, v.v. - 4 điểm: Chủ yếu phù h ợp; có vài cách di ễn đạt hơi “tây” nhưng vẫn chấp nhận được...
-
[19]
Độ chính xác (Accuracy): ?/5
-
[20]
Tính đầy đủ (Completeness): ?/5
-
[21]
Khả năng diễn giải (Explanation): ?/5
-
[22]
Tính logic (Argumentation): ?/5
-
[23]
Phù hợp ngữ cảnh văn hóa (Cultural Context): ?/5 Điểm trung bình: ?/5 Giải thích cho từng tiêu chí (ngắn gọn): “
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.