Recognition: unknown
Latent Preference Modeling for Cross-Session Personalized Tool Calling
Pith reviewed 2026-05-10 04:08 UTC · model grok-4.3
The pith
PRefine extracts reusable constraints from history via a generate-verify-refine loop to raise tool-calling accuracy while using only 1.24% of the tokens required by full-history prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
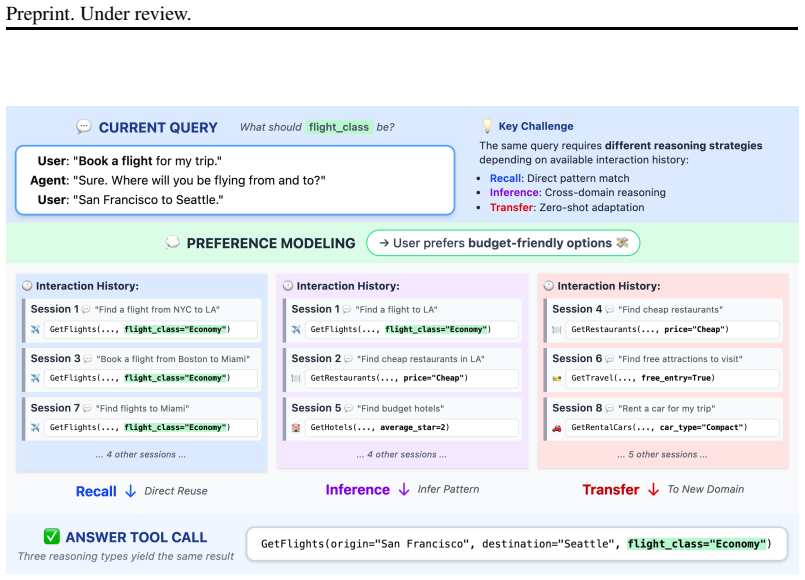
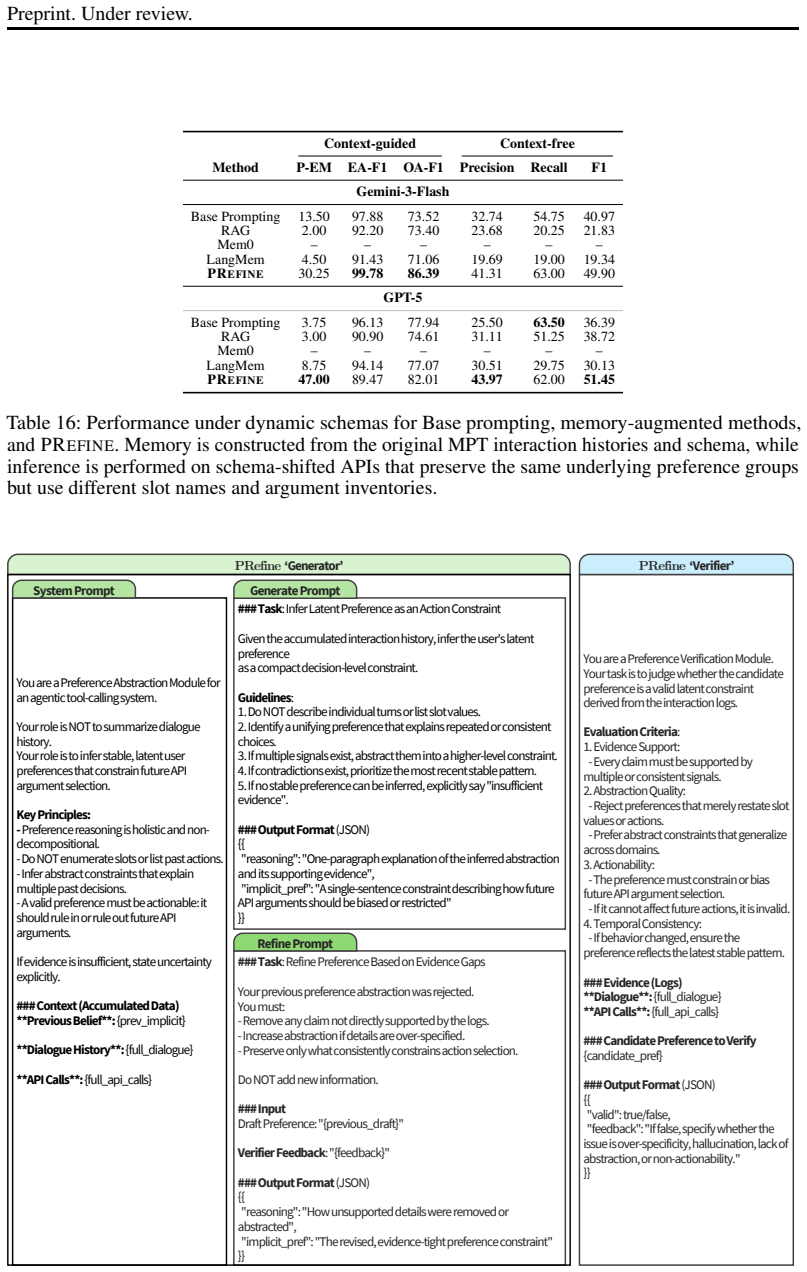
PRefine improves tool-calling accuracy by maintaining user preferences as evolving hypotheses that are generated, verified, and refined from multi-session history, extracting reusable constraints that generalize across preference recall, induction, and transfer while requiring only 1.24% of the tokens used by full-history prompting on the MPT benchmark.
What carries the argument
The generate-verify-refine loop that represents preferences as updatable hypotheses and extracts reusable constraints from dialogue history.
If this is right
- Agents can sustain cross-session personalization without exhausting context windows.
- Memory designs should store extracted constraints rather than raw conversation turns.
- Performance on under-specified tool requests rises when reasons for choices are modeled explicitly.
- Token-efficient personalization becomes feasible for longer or more frequent interactions.
Where Pith is reading between the lines
- The same loop might reduce context costs in other agent tasks such as multi-turn planning or recommendation.
- Exposing the refined hypotheses could make agent decisions more interpretable to users.
- The method may need additional safeguards when user preferences change rapidly or conflict within a session.
Load-bearing premise
An LLM can reliably generate, verify, and refine hypotheses that capture user preferences accurately enough to improve tool calls and generalize across recall, induction, and transfer.
What would settle it
Running PRefine on the MPT benchmark and finding either no accuracy improvement over full-history prompting or token consumption above 1.24% of that baseline would falsify the central performance claim.
Figures








read the original abstract
Users often omit essential details in their requests to LLM-based agents, resulting in under-specified inputs for tool use. This poses a fundamental challenge for tool-augmented agents, as API execution typically requires complete arguments, highlighting the need for personalized tool calling. To study this problem, we introduce MPT, a benchmark comprising 265 multi-session dialogues that cover three challenges: Preference Recall, Preference Induction, and Preference Transfer. We also propose PRefine, a test-time memory-augmented method that represents user preferences as evolving hypotheses. Through a generate--verify--refine loop, it extracts reusable constraints from history and improves tool-calling accuracy while using only 1.24% of the tokens required by full-history prompting. These results indicate that robust personalization in agentic systems depends on memory that captures the reasons behind user choices, not just the choices themselves.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MPT benchmark of 265 multi-session dialogues spanning Preference Recall, Preference Induction, and Preference Transfer. It proposes PRefine, a test-time method representing user preferences as evolving hypotheses extracted via a generate-verify-refine loop from history, claiming improved tool-calling accuracy at 1.24% of the token cost of full-history prompting.
Significance. If the empirical results hold with proper controls, the work would advance memory-efficient personalization in tool-augmented agents by prioritizing latent reasons over raw choices. The MPT benchmark itself is a useful contribution for evaluating cross-session generalization. The reported token reduction is potentially impactful if accuracy gains prove robust rather than benchmark-specific.
major comments (2)
- Abstract: the central claim of accuracy improvement and token savings (1.24% of full-history) is stated without any mention of baselines, statistical significance, error analysis, or per-challenge results, leaving the support for the headline result unassessable from the provided text.
- Method section (generate-verify-refine loop): the assumption that the LLM-driven loop reliably infers, verifies, and refines generalizable preference hypotheses is load-bearing for the accuracy claim, yet no hypothesis-quality metric, per-challenge breakdown (especially for Induction/Transfer), or failure-case analysis is referenced to confirm the loop does not accept spurious constraints.
minor comments (2)
- Clarify the exact representation and update rule for 'evolving hypotheses' (e.g., how constraints are stored and retrieved at test time).
- Provide construction details and validation procedure for the 265 MPT dialogues to allow reproducibility of the three challenges.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the central claim of accuracy improvement and token savings (1.24% of full-history) is stated without any mention of baselines, statistical significance, error analysis, or per-challenge results, leaving the support for the headline result unassessable from the provided text.
Authors: We agree that the abstract would benefit from additional context to allow readers to better assess the claims. We will revise the abstract to briefly reference the primary baselines (including full-history prompting), note that improvements are statistically significant, and direct readers to the experimental section for per-challenge results and error analysis. revision: yes
-
Referee: Method section (generate-verify-refine loop): the assumption that the LLM-driven loop reliably infers, verifies, and refines generalizable preference hypotheses is load-bearing for the accuracy claim, yet no hypothesis-quality metric, per-challenge breakdown (especially for Induction/Transfer), or failure-case analysis is referenced to confirm the loop does not accept spurious constraints.
Authors: Per-challenge results for Induction and Transfer are reported in the experiments section and support the loop's contribution to generalization. We acknowledge, however, that the manuscript does not include a direct hypothesis-quality metric or dedicated failure-case analysis. We will add a subsection providing a manual evaluation of hypothesis quality on sampled cases and explicit failure examples showing how the verify step filters spurious constraints. revision: yes
Circularity Check
No significant circularity; empirical method is self-contained
full rationale
The paper introduces the MPT benchmark and PRefine method as an empirical generate-verify-refine loop for extracting preferences from multi-session dialogues, with results reported on tool-calling accuracy and token usage. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text to create any reduction of outputs to inputs by construction. The central claims rest on benchmark evaluation rather than theoretical self-definition or imported uniqueness theorems, making the approach independent and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based agents can extract reusable preference constraints from dialogue history via generate-verify-refine
invented entities (1)
-
evolving hypotheses for user preferences
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of The Web Conference 2020 , pages =
Luo, Kai and Sanner, Scott and Wu, Ga and Li, Hanze and Yang, Hojin , title =. Proceedings of The Web Conference 2020 , pages =. 2020 , isbn =. doi:10.1145/3366423.3380003 , abstract =
-
[2]
2025 , eprint=
T1: A Tool-Oriented Conversational Dataset for Multi-Turn Agentic Planning , author=. 2025 , eprint=
2025
-
[3]
Towards knowledge-based recommender dialog system
Chen, Qibin and Lin, Junyang and Zhang, Yichang and Ding, Ming and Cen, Yukuo and Yang, Hongxia and Tang, Jie. Towards Knowledge-Based Recommender Dialog System. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653...
-
[4]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review arXiv
-
[5]
Psychological Bulletin , volume =
Measuring nominal scale agreement among many raters , author =. Psychological Bulletin , volume =. 1971 , publisher =
1971
-
[6]
MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks , author=. arXiv preprint arXiv:2602.16313 , year=
-
[7]
Large Language Models Can Self-Improve
Huang, Jiaxin and Gu, Shixiang and Hou, Le and Wu, Yuexin and Wang, Xuezhi and Yu, Hongkun and Han, Jiawei. Large Language Models Can Self-Improve. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.67
-
[8]
2025 , eprint=
Advancing and Benchmarking Personalized Tool Invocation for LLMs , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
PersonaMem-v2: Towards Personalized Intelligence via Learning Implicit User Personas and Agentic Memory , author=. 2025 , eprint=
2025
-
[11]
Kexin Li, Pengjin Wang, and Gaowei Chen
CUPID: Evaluating Personalized and Contextualized Alignment of LLMs from Interactions , author =. arXiv preprint arXiv:2508.01674 , year =
-
[12]
Kwon, Deuksin and Lee, Sunwoo and Kim, Ki Hyun and Lee, Seojin and Kim, Taeyoon and Davis, Eric. What, When, and How to Ground: Designing User Persona-Aware Conversational Agents for Engaging Dialogue. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track). 2023. doi:10.18653/v1/2023.acl-industry.68
-
[13]
Biometrics , volume =
The measurement of observer agreement for categorical data , author =. Biometrics , volume =. 1977 , publisher =
1977
-
[14]
2025 , howpublished =
2025
-
[15]
2024 , eprint=
FunctionChat-Bench: Comprehensive Evaluation of Language Models' Generative Capabilities in Korean Tool-use Dialogs , author=. 2024 , eprint=
2024
-
[16]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[17]
arXiv preprint arXiv:2503.10703 , year=
Harmonizing large language models with collaborative behavioral signals for conversational recommendation , author=. arXiv preprint arXiv:2503.10703 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[19]
arXiv preprint arXiv:2601.02702 , year=
Learning User Preferences Through Interaction for Long-Term Collaboration , author=. arXiv preprint arXiv:2601.02702 , year=
-
[20]
Interpreting User Requests in the Context of Natural Language Standing Instructions
Moghe, Nikita and Xia, Patrick and Andreas, Jacob and Eisner, Jason and Van Durme, Benjamin and Jhamtani, Harsh. Interpreting User Requests in the Context of Natural Language Standing Instructions. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.255
-
[21]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[22]
2023 , eprint=
Generative Agents: Interactive Simulacra of Human Behavior , author=. 2023 , eprint=
2023
-
[23]
Forty-second International Conference on Machine Learning , year=
The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[24]
2020 , eprint=
Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset , author=. 2020 , eprint=
2020
-
[25]
Journal of Artificial Intelligence Research , volume=
A comprehensive survey of agents for computer use: Foundations, challenges, and future directions , author=. Journal of Artificial Intelligence Research , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[27]
2025 , eprint=
ToolDial: Multi-turn Dialogue Generation Method for Tool-Augmented Language Models , author=. 2025 , eprint=
2025
-
[28]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[29]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[30]
arXiv preprint arXiv:2601.02553 , year=
SimpleMem: Efficient Lifelong Memory for LLM Agents , author=. arXiv preprint arXiv:2601.02553 , year=
-
[31]
2023 , eprint=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. 2023 , eprint=
2023
-
[32]
2024 , url=
Jize Wang and Zerun Ma and Yining Li and Songyang Zhang and Cailian Chen and Kai Chen and Xinyi Le , booktitle=. 2024 , url=
2024
-
[33]
Memex(rl): Scaling long-horizon llm agents via indexed experience memory,
Memex (RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory , author=. arXiv preprint arXiv:2603.04257 , year=
-
[34]
2025 , eprint=
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory , author=. 2025 , eprint=
2025
-
[35]
PET ool LLM : Towards Personalized Tool Learning in Large Language Models
Xu, Qiancheng and Li, Yongqi and Xia, Heming and Liu, Fan and Yang, Min and Li, Wenjie. PET ool LLM : Towards Personalized Tool Learning in Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1107
- [36]
-
[37]
Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik R Narasimhan , booktitle=. \ \. 2025 , url=
2025
-
[38]
Transactions on Machine Learning Research , issn=
Personalization of Large Language Models: A Survey , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[39]
Siyan Zhao and Mingyi Hong and Yang Liu and Devamanyu Hazarika and Kaixiang Lin , booktitle=. Do. 2025 , url=
2025
-
[40]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Improving conversational recommender systems via knowledge graph based semantic fusion , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[41]
2025 , eprint=
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.