Recognition: unknown
Bayesian Active Learning with Gaussian Processes Guided by LLM Relevance Scoring for Dense Passage Retrieval
Pith reviewed 2026-05-10 04:22 UTC · model grok-4.3
The pith
A Gaussian process over embedding space lets sparse LLM scores guide retrieval beyond initial dense clusters under fixed budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
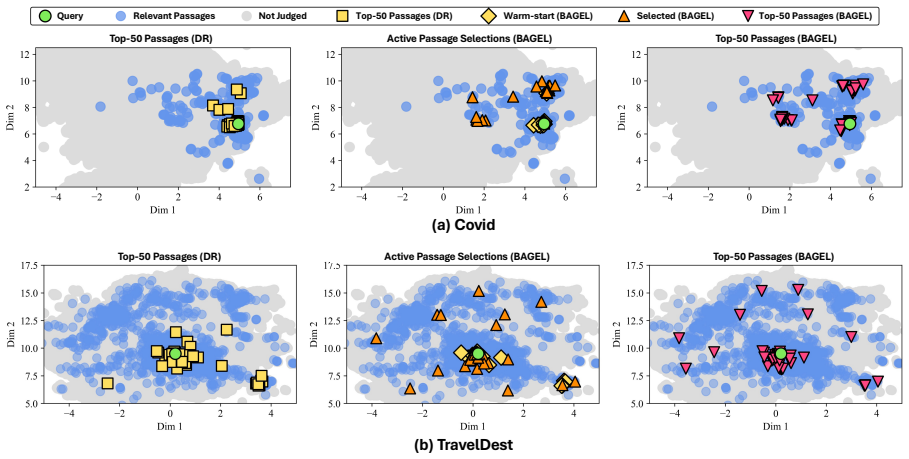
BAGEL models the multimodal relevance distribution across the entire embedding space with a query-specific Gaussian Process based on LLM relevance scores. It then iteratively selects passages for scoring by strategically balancing the exploitation of high-confidence regions with the exploration of uncertain areas, and this procedure outperforms LLM reranking methods under the same LLM budget on all four evaluated datasets.
What carries the argument
Query-specific Gaussian Process fitted to sparse LLM relevance scores in embedding space; its posterior mean and variance drive an acquisition function that chooses the next passages to label.
If this is right
- Relevance signals from a small number of LLM scores can be propagated to the full corpus without requiring exhaustive scoring.
- Exploration of uncertain embedding regions recovers passages missed by first-stage dense retrieval.
- The same LLM budget yields higher recall when selection is active rather than passive.
- The framework works with different LLM backbones and across multiple retrieval benchmarks.
Where Pith is reading between the lines
- The approach could be tested with non-Euclidean embeddings or hybrid retrievers to check whether better alignment between embedding geometry and relevance improves the GP fit.
- Similar active GP selection might reduce expensive oracle calls in other ranking or recommendation settings where labels are costly.
- If the embedding space fails to separate relevance modes, the method would need an adaptive embedding or kernel to remain effective.
Load-bearing premise
The Gaussian process fitted to sparse LLM scores in embedding space can reliably capture multimodal relevance and steer the acquisition function toward relevant passages outside the initial retriever clusters.
What would settle it
On a corpus where known relevant passages lie in embedding clusters distant from the dense retriever's top results, measure whether BAGEL recovers a higher fraction of those passages than passive reranking when both are limited to the same number of LLM evaluations.
Figures

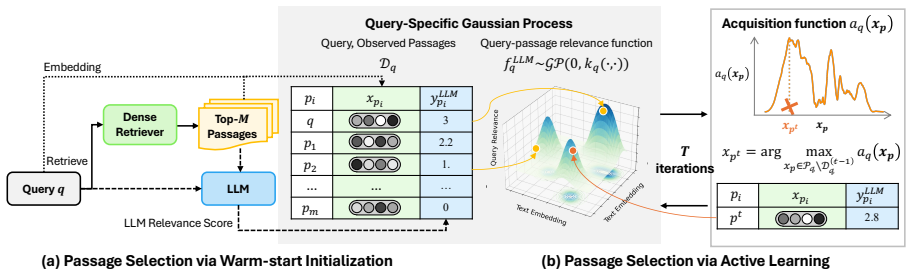


read the original abstract
While Large Language Models (LLMs) exhibit exceptional zero-shot relevance modeling, their high computational cost necessitates framing passage retrieval as a budget-constrained global optimization problem. Existing approaches passively rely on first-stage dense retrievers, which leads to two limitations: (1) failing to retrieve relevant passages in semantically distinct clusters, and (2) failing to propagate relevance signals to the broader corpus. To address these limitations, we propose Bayesian Active Learning with Gaussian Processes guided by LLM relevance scoring (BAGEL), a novel framework that propagates sparse LLM relevance signals across the embedding space to guide global exploration. BAGEL models the multimodal relevance distribution across the entire embedding space with a query-specific Gaussian Process (GP) based on LLM relevance scores. Subsequently, it iteratively selects passages for scoring by strategically balancing the exploitation of high-confidence regions with the exploration of uncertain areas. Extensive experiments across four benchmark datasets and two LLM backbones demonstrate that BAGEL effectively explores and captures complex relevance distributions and outperforms LLM reranking methods under the same LLM budget on all four datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BAGEL, a Bayesian active learning framework that fits a query-specific Gaussian Process to sparse LLM relevance scores in embedding space and uses an acquisition function to iteratively select passages for LLM scoring. The goal is to overcome the limitations of passive first-stage dense retrievers by propagating relevance signals globally and exploring semantically distinct clusters under a fixed LLM budget. Experiments on four benchmark datasets with two LLM backbones are claimed to show that BAGEL outperforms standard LLM reranking baselines.
Significance. If the empirical results are robust, the work could provide a practical method for budget-constrained retrieval that leverages LLMs more efficiently than passive reranking, by actively exploring multimodal relevance landscapes in embedding space. This would be a useful contribution at the intersection of Bayesian optimization and neural IR.
major comments (3)
- [Abstract and §5] Abstract and §5 (Experiments): The central claim that BAGEL 'outperforms LLM reranking methods under the same LLM budget on all four datasets' lacks reported details on experimental controls, statistical significance tests, ablation of the GP versus a non-Bayesian baseline, or sensitivity to the acquisition-function trade-off parameter. Without these, the performance advantage cannot be confidently attributed to the proposed modeling.
- [§3.1–3.2] §3.1–3.2 (GP formulation): Standard stationary kernels (RBF or Matérn) are used for the query-specific GP. In high-dimensional embedding space with sparse labels, the posterior mean tends to produce smooth interpolations rather than distinct modes. The paper must show (via posterior visualizations or quantitative metrics) that the model recovers multimodal relevance clusters distant from the initial dense-retriever top-k; otherwise the claimed exploration advantage is at risk.
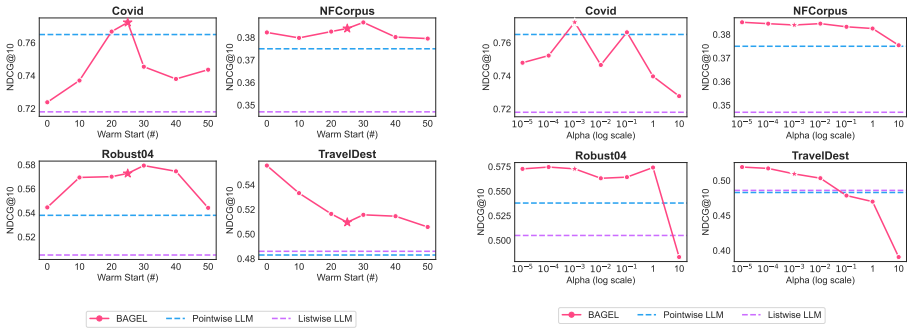
- [§4] §4 (Acquisition strategy): The acquisition function balances exploitation and exploration, yet no ablation or sensitivity analysis is described for the trade-off hyperparameter. If this parameter is tuned on the test sets or if results are sensitive to its value, the reported gains may not generalize.
minor comments (2)
- [§3] Notation for the GP kernel and mean function should be introduced once and used consistently; a small table summarizing all free parameters would help.
- [Figures in §5] Figure captions should explicitly state the number of LLM calls used in each curve so that budget equivalence with baselines is immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): The central claim that BAGEL 'outperforms LLM reranking methods under the same LLM budget on all four datasets' lacks reported details on experimental controls, statistical significance tests, ablation of the GP versus a non-Bayesian baseline, or sensitivity to the acquisition-function trade-off parameter. Without these, the performance advantage cannot be confidently attributed to the proposed modeling.
Authors: We agree that greater experimental detail is needed to support the central claim. In the revised manuscript we will expand §5 with: (1) explicit controls confirming identical LLM call budgets and the same first-stage dense retriever for all compared methods; (2) statistical significance results from the Wilcoxon signed-rank test across repeated runs; (3) an ablation that replaces the GP posterior with a non-Bayesian active-learning baseline (e.g., pure uncertainty sampling); and (4) a sensitivity plot for the acquisition-function trade-off parameter. These additions will allow readers to attribute performance differences more confidently to the Bayesian component. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2 (GP formulation): Standard stationary kernels (RBF or Matérn) are used for the query-specific GP. In high-dimensional embedding space with sparse labels, the posterior mean tends to produce smooth interpolations rather than distinct modes. The paper must show (via posterior visualizations or quantitative metrics) that the model recovers multimodal relevance clusters distant from the initial dense-retriever top-k; otherwise the claimed exploration advantage is at risk.
Authors: We acknowledge the concern that stationary kernels may limit multimodality in high dimensions. In the revision we will add, in §3.2 and the appendix, (i) t-SNE visualizations of the GP posterior mean and variance for selected queries that illustrate distinct high-relevance modes lying outside the initial dense-retriever top-k, and (ii) quantitative metrics (cluster count via DBSCAN on high-posterior regions and mean distance of acquired points from the initial top-k). These will demonstrate that the sparse LLM labels suffice to recover multimodal structure despite the kernel choice. revision: yes
-
Referee: [§4] §4 (Acquisition strategy): The acquisition function balances exploitation and exploration, yet no ablation or sensitivity analysis is described for the trade-off hyperparameter. If this parameter is tuned on the test sets or if results are sensitive to its value, the reported gains may not generalize.
Authors: We agree that sensitivity to the trade-off hyperparameter must be examined. In the revised §4 and §5 we will include an ablation that sweeps the hyperparameter (denoted β) over a wide grid and reports performance on held-out validation data. The analysis will show that BAGEL remains superior to baselines across a broad range of β values, with the chosen operating point selected on validation data only, thereby addressing concerns about test-set tuning and generalization. revision: yes
Circularity Check
Standard GP regression and acquisition on external LLM scores; no reduction to fitted inputs or self-citations
full rationale
The paper frames retrieval as budget-constrained optimization and applies established Gaussian Process regression (with stationary kernels) plus standard acquisition functions (e.g., expected improvement or upper confidence bound) to sparse, externally supplied LLM relevance labels in embedding space. No equation in the derivation chain equates a claimed prediction or performance gain to a parameter that is itself defined by that same gain. The central claims rest on empirical comparisons across datasets rather than any self-definitional or load-bearing self-citation step. This is the normal non-circular case for a method that composes existing components on new data sources.
Axiom & Free-Parameter Ledger
free parameters (2)
- GP kernel hyperparameters
- Acquisition-function trade-off parameter
axioms (1)
- domain assumption Embedding-space proximity corresponds to semantic similarity sufficient for relevance propagation
Forward citations
Cited by 1 Pith paper
-
Goal-Oriented Reasoning for RAG-based Memory in Conversational Agentic LLM Systems
Goal-Mem improves RAG memory retrieval in agentic LLMs by explicit goal decomposition and backward chaining via Natural Language Logic, outperforming nine baselines on multi-hop and implicit inference tasks.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
The Cluster Hypothesis in Information Retrieval , author=. Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[2]
Proceedings of the 2021 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
Passage Similarity and Diversification in Non-factoid Question Answering , author=. Proceedings of the 2021 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
2021
-
[3]
Advances in Neural Information Processing Systems , volume=
Gaussian Processes for Regression , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
2006 , publisher=
Gaussian Processes for Machine Learning , author=. 2006 , publisher=
2006
-
[5]
Journal of Machine Learning Research , volume=
On the Influence of the Kernel on the Consistency of Support Vector Machines , author=. Journal of Machine Learning Research , volume=
-
[6]
Proceedings of the 27th International Conference on Machine Learning , pages=
Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design , author=. Proceedings of the 27th International Conference on Machine Learning , pages=
-
[7]
Biometrika , volume=
On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples , author=. Biometrika , volume=
-
[8]
Journal of Basic Engineering , volume=
A New Method of Locating the Maximum Point of an Arbitrary Multipeak Curve in the Presence of Noise , author=. Journal of Basic Engineering , volume=
-
[9]
Towards Global Optimization , volume=
The Application of Bayesian Methods for Seeking the Extremum , author=. Towards Global Optimization , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Practical Bayesian Optimization of Machine Learning Algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
2023 , publisher=
Bayesian Optimization , author=. 2023 , publisher=
2023
-
[12]
Proceedings of the IEEE , volume=
Taking the Human Out of the Loop: A Review of Bayesian Optimization , author=. Proceedings of the IEEE , volume=
-
[13]
arXiv , eprint=
Active Learning and Bayesian Optimization: A Unified Perspective to Learn with a Goal , author=. arXiv , eprint=
-
[14]
The Thirteenth International Conference on Learning Representations , year=
Standard Gaussian Process is All You Need for High-Dimensional Bayesian Optimization , author=. The Thirteenth International Conference on Learning Representations , year=
-
[15]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Is ChatGPT Good at Search? Investigating Large Language Models as Re-ranking Agents , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[16]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2024
-
[17]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Improving Passage Retrieval with Zero-Shot Question Generation , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[18]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Large Language Models Are Effective Text Rankers with Pairwise Ranking Prompting , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[19]
arXiv , eprint=
Large Language Models Are Strong Zero-Shot Retriever , author=. arXiv , eprint=
-
[20]
arXiv , eprint=
Zero-Shot Listwise Document Reranking with a Large Language Model , author=. arXiv , eprint=
-
[21]
2008 , publisher=
Introduction to Information Retrieval , author=. 2008 , publisher=
2008
-
[22]
Proceedings of the Third Text REtrieval Conference (TREC-3) , pages=
Okapi at TREC-3 , author=. Proceedings of the Third Text REtrieval Conference (TREC-3) , pages=
-
[23]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages=
Dense Passage Retrieval for Open-Domain Question Answering , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages=
2020
-
[24]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna , journal=. Sentence-BERT: Sentence Embeddings Using Siamese. 1908.10084 , archivePrefix=
work page internal anchor Pith review arXiv 1908
-
[25]
Khattab, Omar and Zaharia, Matei , booktitle=
-
[26]
arXiv preprint arXiv:1910.14424 , year=
Nogueira, Rodrigo and Yang, Wei and Cho, Kyunghyun and Lin, Jimmy , journal=. Multi-Stage Document Ranking with. 1910.14424 , archivePrefix=
-
[27]
Nogueira, Rodrigo and Cho, Kyunghyun , journal=. Passage Re-Ranking with. 1901.04085 , archivePrefix=
work page internal anchor Pith review arXiv 1901
-
[28]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[29]
Diversify-Verify-Adapt: Efficient and Robust Retrieval-Augmented Ambiguous Question Answering , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2025 , url=
2025
-
[30]
arXiv , eprint=
Qwen3 Technical Report , author=. arXiv , eprint=
-
[31]
arXiv , eprint=
GPT-4o System Card , author=. arXiv , eprint=
-
[32]
arXiv , eprint=
Umbrela: Umbrela Is the (Open-Source Reproduction of the) Bing Relevance Assessor , author=. arXiv , eprint=
-
[33]
Advances in Neural Information Processing Systems , volume=
GPyTorch: Blackbox Matrix-Matrix Gaussian Process Inference with GPU Acceleration , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv , eprint=
Adam: A Method for Stochastic Optimization , author=. arXiv , eprint=
-
[35]
ACM Transactions on Mathematical Software , volume=
Algorithm 778: L-BFGS-B: Fortran Subroutines for Large-Scale Bound-Constrained Optimization , author=. ACM Transactions on Mathematical Software , volume=
-
[36]
Journal of Open Source Software , volume=
UMAP: Uniform Manifold Approximation and Projection , author=. Journal of Open Source Software , volume=
-
[37]
arXiv , eprint=
BEIR: A Heterogeneous Benchmark for Zero-Shot Evaluation of Information Retrieval Models , author=. arXiv , eprint=
-
[38]
arXiv , eprint=
Elaborative Subtopic Query Reformulation for Broad and Indirect Queries in Travel Destination Recommendation , author=. arXiv , eprint=
-
[39]
arXiv , eprint=
A Simple but Effective Elaborative Query Reformulation Approach for Natural Language Recommendation , author=. arXiv , eprint=
-
[40]
arXiv , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. arXiv , eprint=
-
[41]
Lin, Jimmy and Ma, Xueguang and Lin, Sheng-Chieh and Yang, Jheng-Hong and Pradeep, Ronak and Nogueira, Rodrigo , booktitle=
-
[42]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
MBA-RAG: A Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[43]
Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence , pages=
Adapting to Non-Stationary Environments: Multi-Armed Bandit Enhanced Retrieval-Augmented Generation on Knowledge Graphs , author=. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence , pages=
-
[44]
Advances in Neural Information Processing Systems , year=
AcuRank: Uncertainty-Aware Adaptive Computation for Listwise Reranking , author=. Advances in Neural Information Processing Systems , year=
-
[45]
Multimodal Item Scoring for Natural Language Recommendation via Gaussian Process Regression with LLM Relevance Judgments , author=. arXiv preprint arXiv:2510.22023 , year=
-
[46]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
MA-DPR: Manifold-aware Distance Metrics for Dense Passage Retrieval , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.