Recognition: unknown
From Heads to Neurons: Causal Attribution and Steering in Multi-Task Vision-Language Models
Pith reviewed 2026-05-10 05:41 UTC · model grok-4.3
The pith
HONES ranks FFN neurons in multi-task vision-language models by their causal write-in contributions conditioned on task-relevant attention heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
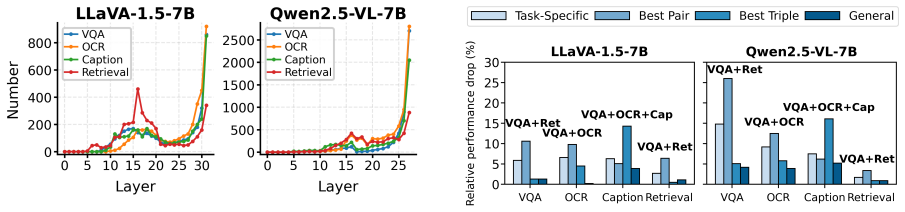
HONES ranks FFN neurons by their causal write-in contributions conditioned on task-relevant attention heads, and further modulates salient neurons via lightweight scaling, yielding more accurate task-critical neuron identification and improved performance after steering in multi-task VLMs.
What carries the argument
Head-oriented conditioning of neuron ranking, which ties FFN write-in effects to the task-dependent pathways carried by attention heads.
If this is right
- HONES identifies task-critical neurons more accurately than methods that score neurons in isolation.
- Lightweight scaling of the ranked neurons improves model performance on the tested multimodal tasks.
- The gradient-free design works across diverse tasks without requiring task-specific retraining.
- The approach reduces the impact of neuron polysemanticity when the same model handles multiple tasks.
- Results hold on two popular VLMs, suggesting broader applicability to transformer-based vision-language architectures.
Where Pith is reading between the lines
- The same head-conditioning step could be tested on single-task models to see whether it sharpens neuron attributions even without explicit multi-task pressure.
- Attention-head selection might serve as a general prior for other forms of causal intervention, such as activation patching or weight editing.
- If cross-task interactions prove small, HONES could support modular editing where one task is adjusted without disturbing others.
- The lightweight scaling step offers a practical route for post-training control of model behavior in deployed VLMs.
Load-bearing premise
That identifying and conditioning on task-relevant attention heads fully captures the causal write-in effects of neurons without missing cross-task interactions or introducing selection bias.
What would settle it
An ablation showing that scaling the neurons HONES ranks highest produces no greater performance gain than scaling neurons chosen by existing single-task or unconditioned methods.
Figures







read the original abstract
Recent work has increasingly explored neuron-level interpretation in vision-language models (VLMs) to identify neurons critical to final predictions. However, existing neuron analyses generally focus on single tasks, limiting the comparability of neuron importance across tasks. Moreover, ranking strategies tend to score neurons in isolation, overlooking how task-dependent information pathways shape the write-in effects of feed-forward network (FFN) neurons. This oversight can exacerbate neuron polysemanticity in multi-task settings, introducing noise into the identification and intervention of task-critical neurons. In this study, we propose HONES (Head-Oriented Neuron Explanation & Steering), a gradient-free framework for task-aware neuron attribution and steering in multi-task VLMs. HONES ranks FFN neurons by their causal write-in contributions conditioned on task-relevant attention heads, and further modulates salient neurons via lightweight scaling. Experiments on four diverse multimodal tasks and two popular VLMs show that HONES outperforms existing methods in identifying task-critical neurons and improves model performance after steering. Our source code is released at: https://github.com/petergit1/HONES.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HONES, a gradient-free framework for task-aware neuron attribution and steering in multi-task vision-language models. It ranks FFN neurons according to their causal write-in contributions conditioned on task-relevant attention heads and applies lightweight scaling to modulate salient neurons. Experiments across four diverse multimodal tasks and two popular VLMs report that HONES outperforms prior methods in identifying task-critical neurons and yields performance gains after steering.
Significance. If the head-conditioned ranking validly isolates causal write-in effects, the approach offers a principled way to reduce polysemanticity noise when comparing neuron importance across tasks, extending single-task neuron analyses. The public release of source code at the cited GitHub repository is a clear strength for reproducibility.
major comments (2)
- [§3.2] §3.2 (Head Selection): The procedure for identifying task-relevant attention heads is described at a high level but lacks explicit validation (e.g., stability across random seeds or cross-task overlap metrics); because neuron rankings are defined conditionally on these heads, any selection bias or incompleteness directly undermines the central causal-attribution claim.
- [§4.3] §4.3 and Table 3: The reported outperformance on neuron identification and steering is shown relative to baselines, yet no ablation removes the head-conditioning step while keeping other components fixed; without this, it is impossible to attribute gains specifically to the proposed conditioning rather than to scaling or ranking heuristics.
minor comments (2)
- [Abstract] The abstract lists 'four diverse multimodal tasks' without naming them; adding the task names (e.g., VQA, captioning, etc.) would improve immediate clarity.
- [§3.1] Notation for the write-in contribution score is introduced without a compact equation reference in the main text; placing the defining equation in a numbered display would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Head Selection): The procedure for identifying task-relevant attention heads is described at a high level but lacks explicit validation (e.g., stability across random seeds or cross-task overlap metrics); because neuron rankings are defined conditionally on these heads, any selection bias or incompleteness directly undermines the central causal-attribution claim.
Authors: We agree that the head selection procedure requires more explicit validation to support the conditional causal claims. In the revised manuscript we will add quantitative validation in §3.2, including stability of selected heads across multiple random seeds and cross-task overlap statistics. These results will be presented alongside the existing description to demonstrate that the selected heads are robust and do not introduce systematic bias into the downstream neuron rankings. revision: yes
-
Referee: [§4.3] §4.3 and Table 3: The reported outperformance on neuron identification and steering is shown relative to baselines, yet no ablation removes the head-conditioning step while keeping other components fixed; without this, it is impossible to attribute gains specifically to the proposed conditioning rather than to scaling or ranking heuristics.
Authors: We acknowledge that the current experiments do not isolate the contribution of head-conditioning. We will add a controlled ablation in the revised §4.3: a variant of HONES that performs neuron ranking without the head-conditioning step while retaining the same scaling and ranking heuristics. Updated results will be included in Table 3, allowing direct attribution of performance differences to the conditioning mechanism. revision: yes
Circularity Check
No circularity detected; HONES derivation is self-contained.
full rationale
The paper defines HONES as a gradient-free method that first identifies task-relevant attention heads and then ranks FFN neurons by their conditioned causal write-in contributions before applying lightweight scaling for steering. No equations, parameter fits, or self-citations in the abstract or described framework reduce the neuron ranking or performance improvements back to the inputs by construction. The multi-task experiments on four tasks and two VLMs serve as independent validation rather than tautological confirmation. The derivation chain therefore stands on its own definitions and external benchmarks without self-referential collapse.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Visual Instruction Tuning , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[2]
Advances in Neural Information Processing Systems , volume =
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , author=. Advances in Neural Information Processing Systems , volume =. 2023 , volume=
2023
-
[5]
2023 , volume =
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =. 2023 , volume =
2023
-
[7]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[8]
Advances in Neural Information Processing Systems , volume =
WikiDO: A New Benchmark Evaluating Cross-Modal Retrieval for Vision-Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[11]
Advances in Neural Information Processing Systems , year =
Locating and Editing Factual Associations in GPT , author =. Advances in Neural Information Processing Systems , year =
-
[14]
Style-Specific Neurons for Steering
Lai, Wen and Hangya, Viktor and Fraser, Alexander , booktitle =. Style-Specific Neurons for Steering. 2024 , address =. doi:10.18653/v1/2024.emnlp-main.745 , url =
-
[17]
Proceedings of the 33rd ACM International Conference on Multimedia , pages =
Deciphering Functions of Neurons in Vision-Language Models , author =. Proceedings of the 33rd ACM International Conference on Multimedia , pages =. 2025 , url =
2025
-
[18]
Proceedings of the 41st International Conference on Machine Learning , series =
Linear Explanations for Individual Neurons , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[19]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Neurons Speak in Ranges: Breaking Free from Discrete Neuronal Attribution , author =. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
2025
-
[20]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=. 2024 , url=
2024
-
[22]
mPLUG-OwI2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration , year=
Ye, Qinghao and Xu, Haiyang and Ye, Jiabo and Yan, Ming and Hu, Anwen and Liu, Haowei and Qian, Qi and Zhang, Ji and Huang, Fei , booktitle=. mPLUG-OwI2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration , year=
-
[23]
2025 , eprint =
Qwen2.5-VL Technical Report , author =. 2025 , eprint =
2025
-
[24]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Network Dissection: Quantifying Interpretability of Deep Visual Representations , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[25]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Interpreting Arithmetic Mechanism in Large Language Models through Comparative Neuron Analysis , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2024
-
[27]
From Redundancy to Relevance: Information Flow in
Zhang, Xiaofeng and Quan, Yihao and Shen, Chen and Yuan, Xiaosong and Yan, Shaotian and Xie, Liang and Wang, Wenxiao and Gu, Chaochen and Tang, Hao and Ye, Jieping , editor =. From Redundancy to Relevance: Information Flow in. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human ...
-
[28]
International Conference on Learning Representations (ICLR) , year =
Towards Interpreting Visual Information Processing in Vision-Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , month =
Palit, Vedant and Pandey, Rohan and Arora, Aryaman and Liang, Paul Pu , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , month =. 2023 , pages =
2023
-
[30]
Golovanevsky, Michal and Rudman, William and Palit, Vedant and Eickhoff, Carsten and Singh, Ritambhara , editor =. What Do. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , month = apr, year =. doi:10.18653/v1/2025.naacl-long.57...
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Understanding Information Storage and Transfer in Multi-modal Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[33]
Finding Culture-Sensitive Neurons in Vision-Language Models , booktitle =
Zhao, Xiutian and Choenni, Rochelle and Saxena, Rohit and Titov, Ivan. Finding Culture-Sensitive Neurons in Vision-Language Models , booktitle =. 2026 , url =
2026
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , month =
Schwettmann, Sarah and Chowdhury, Neil and Klein, Samuel and Bau, David and Torralba, Antonio , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , month =. 2023 , pages =
2023
-
[36]
Advances in Neural Information Processing Systems , volume =
Towards Neuron Attributions in Multi-Modal Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2024 , publisher =
2024
-
[37]
Microsoft
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. Microsoft. European Conference on Computer Vision (ECCV) , year =
-
[38]
Veit, Andreas and Matera, Tomas and Neumann, Lukas and Matas, Jiri and Belongie, Serge , journal =
-
[40]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[41]
2002 , pages =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle =. 2002 , pages =
2002
-
[42]
Cumulated Gain-Based Evaluation of
J. Cumulated Gain-Based Evaluation of. ACM Transactions on Information Systems , volume =
-
[43]
Biten, Ali Furkan and Tito, Ruben and Mafla, Andres and Gomez, Lluis and Rusinol, Marcal and Valveny, Ernest and Jawahar, C. V. and Karatzas, Dimosthenis , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[44]
2024 , url =
Explainability for Large Language Models: A Survey , author =. 2024 , url =
2024
-
[45]
Does Large Language Model Contain Task-Specific Neurons?
Song, Ran and He, Shizhu and Jiang, Shuting and Xian, Yantuan and Gao, Shengxiang and Liu, Kang and Yu, Zhengtao. Does Large Language Model Contain Task-Specific Neurons?. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.403
-
[46]
NeurIPS 2025 Workshop on Mechanistic Interpretability , year =
Interpreting Attention Heads for Image-to-Text Information Flow in Large Vision-Language Models , author =. NeurIPS 2025 Workshop on Mechanistic Interpretability , year =
2025
-
[49]
2023 , howpublished =
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. 2023 , howpublished =
2023
-
[50]
The Twelfth International Conference on Learning Representations,
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods , author =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[51]
and Manning, Christopher D
Hudson, Drew A. and Manning, Christopher D. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2019 , pages =
2019
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Singh, Amanpreet and Natarajan, Vivek and Shah, Meet and Jiang, Yu and Chen, Xinlei and Batra, Dhruv and Parikh, Devi and Rohrbach, Marcus , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2019 , pages=
2019
-
[55]
arXiv preprint arXiv:2504.02821 , year=
Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models , author =. arXiv preprint arXiv:2504.02821 , year =
-
[56]
Understanding Multimodal LLMs: the Mechanistic Interpretability of Llava in Visual Question Answering , author =. 2024 , eprint =. doi:10.48550/arXiv.2411.10950 , url =
-
[57]
2024 , eprint =
Interpreting the Second-Order Effects of Neurons in CLIP , author =. 2024 , eprint =
2024
-
[58]
International Conference on Learning Representations (ICLR) , year =
Sparse autoencoders reveal selective remapping of visual concepts during adaptation , author =. International Conference on Learning Representations (ICLR) , year =
-
[60]
CoRR , volume =
Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey , author =. CoRR , volume =. 2024 , url =
2024
-
[61]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=. 2021 , url=
2021
-
[62]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Identifying query-relevant neurons in large language models for long-form texts , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[63]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
SteerVLM: Robust Model Control through Lightweight Activation Steering for Vision Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[64]
Menick, Sebastian Borgeaud, and 8 others
Jean - Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L. Menick, Sebastian Borgeaud, and 8 others. 2022. Flamingo: a visual language model for fe...
2022
-
[65]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . Preprint, arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, and Daniela Massiceti. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/0dfe31d6e703e138d46a7d2fced38b7c-Abstract-Conference.html Understanding information storage and transfer in multi-modal large language models . In Advances in Neural Information Processing Sy...
2024
-
[67]
Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marcal Rusinol, Ernest Valveny, C. V. Jawahar, and Dimosthenis Karatzas. 2019. Scene text visual question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4291--4301
2019
-
[68]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nicholas L. Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, and 5 others. 2023. https://transformer-circuits.pub/2023/monosemantic-featu...
2023
-
[69]
Lihu Chen, Adam Dejl, and Francesca Toni. 2025. Identifying query-relevant neurons in large language models for long-form texts. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23595--23604
2025
-
[70]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Doll \'a r, and C. Lawrence Zitnick. 2015. https://arxiv.org/abs/1504.00325 Microsoft COCO captions: Data collection and evaluation server . arXiv preprint arXiv:1504.00325
work page internal anchor Pith review arXiv 2015
-
[71]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2024. https://doi.org/10.1109/CVPR52733.2024.02283 Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks . In Proceedings of the IEEE/CVF conferenc...
-
[72]
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. https://doi.org/10.18653/v1/2022.acl-long.581 Knowledge neurons in pretrained transformers . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493--8502
-
[73]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. https://papers.nips.cc/paper_files/paper/2023/hash/9a6a435e75419a836fe47ab6793623e6-Abstract-Conference.html Instructblip: Towards general-purpose vision-language models with instruction tuning . In Advances in Neural Information ...
2023
-
[74]
Yunkai Dang, Kaichen Huang, Jiahao Huo, Yibo Yan, Sirui Huang, Dongrui Liu, Mengxi Gao, Jie Zhang, Chen Qian, Kun Wang, Yong Liu, Jing Shao, Hui Xiong, and Xuming Hu. 2024. https://doi.org/10.48550/ARXIV.2412.02104 Explainable and interpretable multimodal large language models: A comprehensive survey . CoRR, abs/2412.02104
-
[75]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, and 6 others. 2021. https://transformer-circuits.pub/2021/framework/index.html A mat...
2021
-
[76]
Junfeng Fang, Zongze Bi, Ruipeng Wang, Houcheng Jiang, Yuan Gao, Kun Wang, An Zhang, Jie Shi, Xiang Wang, and Tat-Seng Chua. 2024. https://doi.org/10.52202/079017-3904 Towards neuron attributions in multi-modal large language models . In Advances in Neural Information Processing Systems, volume 37, pages 122867--122890. Curran Associates, Inc
-
[77]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.446 Transformer feed-forward layers are key-value memories . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484--5495
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[78]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. 2017. https://ieeexplore.ieee.org/document/8100153 Making the v in vqa matter: Elevating the role of image understanding in visual question answering . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6325--6334
-
[79]
Muhammad Umair Haider, Hammad Rizwan, Hassan Sajjad, Peizhong Ju, and A. B. Siddique. 2025. Neurons speak in ranges: Breaking free from discrete neuronal attribution. In Mechanistic Interpretability Workshop at NeurIPS 2025
2025
-
[80]
Anwen Hu, Haiyang Xu, Liang Zhang, Jiabo Ye, Ming Yan, Ji Zhang, Qin Jin, Fei Huang, and Jingren Zhou. 2025. https://doi.org/10.18653/v1/2025.acl-long.291 m PLUG - D oc O wl2: High-resolution compressing for OCR -free multi-page document understanding . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
- [81]
-
[82]
Hudson and Christopher D
Drew A. Hudson and Christopher D. Manning. 2019. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6700--6709
2019
-
[83]
Jiahao Huo, Yibo Yan, Boren Hu, Yutao Yue, and Xuming Hu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.387 MMN euron: Discovering neuron-level domain-specific interpretation in multimodal large language model . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6801--6816, Miami, Florida, USA. Association...
-
[84]
a rvelin and Jaana Kek \
Kalervo J \"a rvelin and Jaana Kek \"a l \"a inen. 2002. Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems, 20(4):422--446
2002
-
[85]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. https://proceedings.mlr.press/v202/li23q.html BLIP -2: Bootstrapping language-image pre-training with frozen image encoders and large language models . In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 19730--19...
2023
-
[86]
Hyesu Lim, Jinho Choi, Jaegul Choo, and Steffen Schneider. 2025. https://openreview.net/forum?id=imT03YXlG2 Sparse autoencoders reveal selective remapping of visual concepts during adaptation . In International Conference on Learning Representations (ICLR). Poster
2025
-
[87]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll \'a r, and C. Lawrence Zitnick. 2014. https://link.springer.com/chapter/10.1007/978-3-319-10602-1_48 Microsoft COCO : Common objects in context . In European Conference on Computer Vision (ECCV), pages 740--755
-
[88]
Zihao Lin, Samyadeep Basu, Mohammad Beigi, Varun Manjunatha, Ryan A. Rossi, Zichao Wang, Yufan Zhou, Sriram Balasubramanian, Arman Zarei, Keivan Rezaei, Ying Shen, Barry Menglong Yao, Zhiyang Xu, Qin Liu, Yuxiang Zhang, Yan Sun, Shilong Liu, Li Shen, Hongxuan Li, and 2 others. 2025. https://arxiv.org/abs/2502.17516 A survey on mechanistic interpretability...
-
[89]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. https://papers.nips.cc/paper_files/paper/2023/hash/6dcf277ea32ce3288914faf369fe6de0-Abstract-Conference.html Visual instruction tuning . In Advances in Neural Information Processing Systems, volume 36, pages 34892--34916
2023
-
[90]
Zhihang Liu, Chen-Wei Xie, Bin Wen, Feiwu Yu, Jixuan Chen, Pandeng Li, Boqiang Zhang, Nianzu Yang, Yinglu Li, Zuan Gao, Yun Zheng, and Hongtao Xie. 2025. https://arxiv.org/abs/2502.14914 Capability: A comprehensive visual caption benchmark for evaluating both correctness and thoroughness . arXiv preprint arXiv:2502.14914
-
[91]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/6f1d43d5a82a37e89b0665b33bf3a182-Paper-Conference.pdf Locating and editing factual associations in gpt . In Advances in Neural Information Processing Systems, pages 17359--17372
2022
-
[92]
Clement Neo, Luke Ong, Philip Torr, Mor Geva, David Krueger, and Fazl Barez. 2025. https://doi.org/10.48550/arXiv.2410.07149 Towards interpreting visual information processing in vision-language models . In International Conference on Learning Representations (ICLR)
-
[93]
Tuomas Oikarinen and Tsui-Wei Weng. 2024. https://proceedings.mlr.press/v235/oikarinen24a.html Linear explanations for individual neurons . In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 38639--38662. PMLR
2024
-
[94]
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. 2025. https://doi.org/10.48550/arXiv.2504.02821 Sparse autoencoders learn monosemantic features in vision-language models . arXiv preprint arXiv:2504.02821
-
[95]
Haowen Pan, Yixin Cao, Xiaozhi Wang, Xun Yang, and Meng Wang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.60 Finding and editing multi-modal neurons in pre-trained transformers . In Findings of the Association for Computational Linguistics: ACL 2024, pages 1012--1037, Bangkok, Thailand. Association for Computational Linguistics
-
[96]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. https://aclanthology.org/P02-1040/ BLEU : a method for automatic evaluation of machine translation . In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages 311--318
2002
-
[97]
Hassan Sajjad, Nadir Durrani, and Fahim Dalvi. 2022. https://doi.org/10.1162/tacl_a_00519 Neuron-level interpretation of deep NLP models: A survey . Transactions of the Association for Computational Linguistics, 10:1285--1303
-
[98]
Sarah Schwettmann, Neil Chowdhury, Samuel Klein, David Bau, and Antonio Torralba. 2023. Multimodal neurons in pretrained text-only transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 2862--2867
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.