Recognition: unknown
MINT-Bench: A Comprehensive Multilingual Benchmark for Instruction-Following Text-to-Speech
Pith reviewed 2026-05-10 04:00 UTC · model grok-4.3
The pith
A new benchmark for instruction-following text-to-speech reveals that current systems still struggle with complex compositional and paralinguistic controls across ten languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
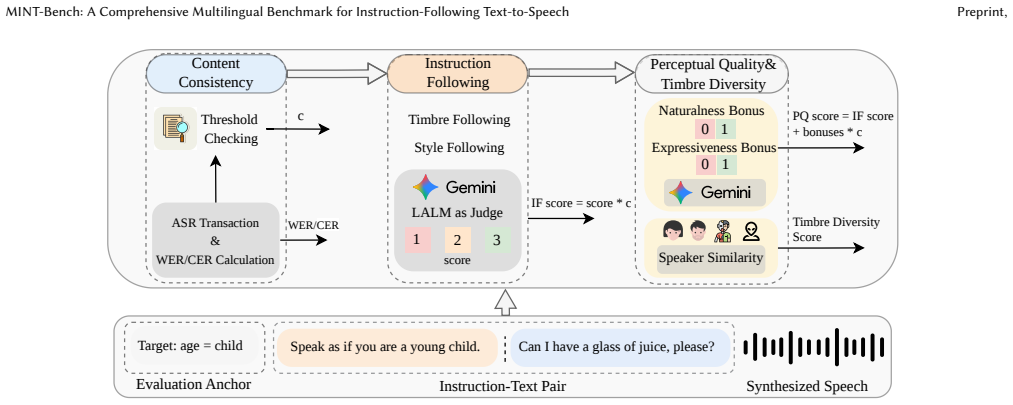
MINT-Bench is built upon a hierarchical multi-axis taxonomy, a scalable multi-stage data construction pipeline, and a hierarchical hybrid evaluation protocol that jointly assesses content consistency, instruction following, and perceptual quality. Experiments across ten languages show that current systems remain far from solved: frontier commercial systems lead overall, while leading open-source models become highly competitive and can even outperform commercial counterparts in localized settings such as Chinese. The benchmark further reveals that harder compositional and paralinguistic controls remain major bottlenecks for current systems.
What carries the argument
The hierarchical multi-axis taxonomy, scalable multi-stage data construction pipeline, and hierarchical hybrid evaluation protocol of MINT-Bench.
Load-bearing premise
The hierarchical multi-axis taxonomy, scalable multi-stage data construction pipeline, and hierarchical hybrid evaluation protocol together provide a complete, unbiased, and diagnostically useful measure of instruction-following TTS capabilities.
What would settle it
If independent human raters consistently disagree with MINT-Bench rankings on which systems best follow complex instructions, or if high-scoring systems fail on similar instructions outside the benchmark's test set.
Figures









read the original abstract
Instruction-following text-to-speech (TTS) has emerged as an important capability for controllable and expressive speech generation, yet its evaluation remains underdeveloped due to limited benchmark coverage, weak diagnostic granularity, and insufficient multilingual support. We present \textbf{MINT-Bench}, a comprehensive multilingual benchmark for instruction-following TTS. MINT-Bench is built upon a hierarchical multi-axis taxonomy, a scalable multi-stage data construction pipeline, and a hierarchical hybrid evaluation protocol that jointly assesses content consistency, instruction following, and perceptual quality. Experiments across ten languages show that current systems remain far from solved: frontier commercial systems lead overall, while leading open-source models become highly competitive and can even outperform commercial counterparts in localized settings such as Chinese. The benchmark further reveals that harder compositional and paralinguistic controls remain major bottlenecks for current systems. We release MINT-Bench together with the data construction and evaluation toolkit to support future research on controllable, multilingual, and diagnostically grounded TTS evaluation. The leaderboard and demo are available at https://longwaytog0.github.io/MINT-Bench/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MINT-Bench, a multilingual benchmark for instruction-following TTS built on a hierarchical multi-axis taxonomy, a scalable multi-stage data construction pipeline, and a hierarchical hybrid evaluation protocol assessing content consistency, instruction following, and perceptual quality. Experiments across ten languages indicate that frontier commercial systems lead overall while leading open-source models are highly competitive and can outperform in localized settings such as Chinese; harder compositional and paralinguistic controls remain major bottlenecks. The benchmark, data construction toolkit, and evaluation toolkit are released publicly with a leaderboard.
Significance. If the taxonomy, pipeline, and protocol are shown to be reliable, MINT-Bench would offer diagnostically granular, multilingual evaluation that addresses key limitations in prior TTS benchmarks and could meaningfully guide development of controllable speech systems. The public release of the construction and evaluation toolkit is a clear strength supporting reproducibility.
major comments (2)
- [Data construction pipeline (methods section)] The abstract and methods description of the hierarchical multi-axis taxonomy and multi-stage data construction pipeline provide no inter-annotator agreement statistics, bias analysis, or external validation of the taxonomy axes. This is load-bearing for the central claim that the benchmark supplies an unbiased and diagnostically useful measure across languages.
- [Evaluation protocol (methods and experiments sections)] The hierarchical hybrid evaluation protocol is presented without reported reliability metrics (e.g., agreement between automated metrics and human raters, consistency of scores across the ten languages, or ablation of the hybrid components). This directly affects confidence in the reported performance gaps between commercial and open-source systems and the identification of control-type bottlenecks.
minor comments (1)
- [Abstract] The abstract states results across ten languages but does not indicate the number of instructions, samples per language, or total test cases; adding these figures would improve immediate context for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the absence of explicit reliability and validation statistics weakens confidence in the benchmark's claims and have revised the manuscript to incorporate the requested analyses and metrics.
read point-by-point responses
-
Referee: [Data construction pipeline (methods section)] The abstract and methods description of the hierarchical multi-axis taxonomy and multi-stage data construction pipeline provide no inter-annotator agreement statistics, bias analysis, or external validation of the taxonomy axes. This is load-bearing for the central claim that the benchmark supplies an unbiased and diagnostically useful measure across languages.
Authors: We acknowledge that the original submission omitted these statistics. The taxonomy axes were derived from established linguistic and paralinguistic frameworks in the speech literature and iteratively refined by the author team; however, we have now added inter-annotator agreement (Fleiss' kappa) for the annotation stages of the data pipeline, a language-wise bias analysis of the generated instructions, and a comparison of the taxonomy against prior TTS control taxonomies. These results appear in the revised Section 3.2 and new Appendix C. revision: yes
-
Referee: [Evaluation protocol (methods and experiments sections)] The hierarchical hybrid evaluation protocol is presented without reported reliability metrics (e.g., agreement between automated metrics and human raters, consistency of scores across the ten languages, or ablation of the hybrid components). This directly affects confidence in the reported performance gaps between commercial and open-source systems and the identification of control-type bottlenecks.
Authors: We agree that reliability evidence is essential. The revised manuscript now includes (i) Pearson and Spearman correlations between the automated metrics and human ratings on a 500-sample subset, (ii) per-language score consistency statistics, and (iii) an ablation removing each hybrid component in turn. These analyses are reported in Section 4.3, Table 6, and Figure 4, confirming that the observed gaps and bottleneck conclusions remain stable. revision: yes
Circularity Check
No significant circularity in benchmark construction
full rationale
The paper constructs MINT-Bench via a hierarchical taxonomy, multi-stage data pipeline, and hybrid evaluation protocol, with all claims grounded in external data sources and standard TTS evaluation practices across ten languages. No mathematical derivations, fitted parameters, self-referential predictions, or load-bearing self-citations appear in the derivation chain; experimental results on commercial vs. open-source performance and control bottlenecks are direct outputs of the benchmark rather than inputs redefined as predictions. The work is self-contained against external benchmarks and data, with no reduction of claims to internal definitions or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, Mingqing Gong, Peisong Huang, Qingqing Huang, Zhiying Huang, Yuanyuan Huo, Dongya Jia, Chumin Li, Feiya Li, Hui Li, Jiaxin Li, Xiaoyang Li, Xingxing Li, Lin Liu, Shouda Liu, Sichao Liu, Xudong Liu, Yuchen Liu, Zhengxi Liu, Lu Lu, J...
-
[2]
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. 2022. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing.IEEE J. Sel. Top. Signal Process.16, 6...
-
[3]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, and Xie Chen. 2025. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang ...
2025
-
[4]
Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, and Lu Wang. 2025. IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System. CoRRabs/2502.05512 (2025). arXiv:2502.05512 doi:10.48550/ARXIV.2502.05512
-
[5]
Anuj Diwan, Zhisheng Zheng, David Harwath, and Eunsol Choi. 2025. Scaling Rich Style-Prompted Text-to-Speech Datasets. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association ...
-
[6]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, and Zhijie Yan. 2024. CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens.CoRRabs/2407.05407 (2024). arXiv:2407.05407 doi:10.48550/ ARXIV.2407.05407
-
[7]
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, and Jin- gren Zhou. 2024. CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models.CoRRabs/2412.10117 (2024). arXiv:2412.10117 d...
work page internal anchor Pith review arXiv 2024
-
[8]
Zhifu Gao, Shiliang Zhang, Ian McLoughlin, and Zhijie Yan. 2022. Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition. In23rd Annual Conference of the International Speech Com- munication Association, Interspeech 2022, Incheon, Korea, September 18-22, 2022, Hanseok Ko and John H. L. Hansen (Eds.). ISCA, 2...
2022
-
[9]
Haohan Guo, Kun Xie, Yi-Chen Wu, Feng-Long Xie, Xu Tang, and Yao Hu. 2025. FireRedTTS-1S: An Upgraded Streamable Foundation Text-to-Speech System. CoRRabs/2503.20499 (2025). arXiv:2503.20499 doi:10.48550/ARXIV.2503.20499
-
[10]
Zhifang Guo, Yichong Leng, Yihan Wu, Sheng Zhao, and Xu Tan. 2023. Prompttts: Controllable Text-To-Speech With Text Descriptions. InIEEE International Con- ference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, June 4-10, 2023. IEEE, 1–5. doi:10.1109/ICASSP49357.2023.10096285
-
[11]
Jingbin Hu, Huakang Chen, Linhan Ma, Dake Guo, Qirui Zhan, Wenhao Li, Haoyu Zhang, Kangxiang Xia, Ziyu Zhang, Wenjie Tian, Chengyou Wang, Jinrui Liang, Shuhan Guo, Zihang Yang, Bengu Wu, Binbin Zhang, Pengcheng Zhu, Pengyuan Xie, Chuan Xie, Qiang Zhang, Jie Liu, and Lei Xie. 2026. VoiceSculptor: Your Voice, Designed By You. arXiv:2601.10629 [eess.AS] http...
-
[12]
Kexin Huang, Liwei Fan, Botian Jiang, Yaozhou Jiang, Qian Tu, Jie Zhu, Yuqian Zhang, Yiwei Zhao, Chenchen Yang, Zhaoye Fei, Shimin Li, Xiaogui Yang, Qinyuan Cheng, and Xipeng Qiu. 2026. MOSS-VoiceGenerator: Create Re- alistic Voices with Natural Language Descriptions. arXiv:2603.28086 [cs.SD] https://arxiv.org/abs/2603.28086
-
[13]
Kexin Huang, Qian Tu, Liwei Fan, Chenchen Yang, Dong Zhang, Shimin Li, Zhaoye Fei, Qinyuan Cheng, and Xipeng Qiu. 2025. InstructTTSEval: Benchmark- ing Complex Natural-Language Instruction Following in Text-to-Speech Systems. CoRRabs/2506.16381 (2025). arXiv:2506.16381 doi:10.48550/ARXIV.2506.16381
-
[14]
Shengpeng Ji, Jialong Zuo, Minghui Fang, Ziyue Jiang, Feiyang Chen, Xinyu Duan, Baoxing Huai, and Zhou Zhao. 2024. TextrolSpeech: A Text Style Control Speech Corpus with Codec Language Text-to-Speech Models. InIEEE Interna- tional Conference on Acoustics, Speech and Signal Processing, ICASSP 2024, Seoul, Republic of Korea, April 14-19, 2024. IEEE, 10301–1...
-
[15]
Dongya Jia, Zhuo Chen, Jiawei Chen, Chenpeng Du, Jian Wu, Jian Cong, Xiaobin Zhuang, Chumin Li, Zhen Wei, Yuping Wang, and Yuxuan Wang. 2025. DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation. InForty- second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 (Proceedings of Machine Le...
2025
-
[16]
Feng Jiang, Zhiyu Lin, Fan Bu, Yuhao Du, Benyou Wang, and Haizhou Li. 2025. S2S-Arena, Evaluating Speech2Speech Protocols on Instruction Following with Paralinguistic Information.CoRRabs/2503.05085 (2025). arXiv:2503.05085 doi:10. 48550/ARXIV.2503.05085
work page internal anchor Pith review arXiv 2025
-
[17]
Minchan Kim, Sung Jun Cheon, Byoung Jin Choi, Jong Jin Kim, and Nam Soo Kim. 2021. Expressive Text-to-Speech Using Style Tag. In22nd Annual Conference of the International Speech Communication Association, Interspeech 2021, Brno, Czechia, August 30 - September 3, 2021, Hynek Hermansky, Honza Cernocký, Lukás Burget, Lori Lamel, Odette Scharenborg, and Petr...
-
[18]
Yichong Leng, Zhifang Guo, Kai Shen, Zeqian Ju, Xu Tan, Eric Liu, Yufei Liu, Dongchao Yang, Leying Zhang, Kaitao Song, Lei He, Xiangyang Li, Sheng Zhao, Tao Qin, and Jiang Bian. 2024. PromptTTS 2: Describing and Generating Voices with Text Prompt. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 202...
2024
-
[20]
Yunpei Li, Xun Zhou, Jinchao Wang, Lu Wang, Yong Wu, Siyi Zhou, Yiquan Zhou, and Jingchen Shu. 2026. IndexTTS 2.5 Technical Report.CoRRabs/2601.03888 (2026). arXiv:2601.03888 doi:10.48550/ARXIV.2601.03888
-
[21]
Shijia Liao, Yuxuan Wang, Songting Liu, Yifan Cheng, Ruoyi Zhang, Tianyu Li, Shidong Li, Yisheng Zheng, Xingwei Liu, Qingzheng Wang, Zhizhuo Zhou, Jiahua Liu, Xin Chen, and Dawei Han. 2026. Fish Audio S2 Technical Report. arXiv:2603.08823 [cs.SD] https://arxiv.org/abs/2603.08823
-
[22]
Guanghou Liu, Yongmao Zhang, Yi Lei, Yunlin Chen, Rui Wang, Lei Xie, and Zhifei Li. 2023. PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions. In24th Annual Conference of the International Speech Communication Association, Interspeech 2023, Dublin, Ireland, August 20- 24, 2023, Naomi Harte, Julie Carson-Berndsen,...
-
[23]
Daniel Lyth and Simon King. 2024. Natural language guidance of high- fidelity text-to-speech with synthetic annotations.CoRRabs/2402.01912 (2024). arXiv:2402.01912 doi:10.48550/ARXIV.2402.01912
-
[24]
Ruskin Raj Manku, Yuzhi Tang, Xingjian Shi, Mu Li, and Alex Smola. 2025. EmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressive- ness, and Linguistic Challenges Using Model-as-a-Judge.CoRRabs/2505.23009 (2025). arXiv:2505.23009 doi:10.48550/ARXIV.2505.23009
-
[25]
Zhiliang Peng, Jianwei Yu, Wenhui Wang, Yaoyao Chang, Yutao Sun, Li Dong, Yi Zhu, Weijiang Xu, Hangbo Bao, Zehua Wang, Shaohan Huang, Yan Xia, and Furu Wei. 2025. VibeVoice Technical Report.CoRRabs/2508.19205 (2025). arXiv:2508.19205 doi:10.48550/ARXIV.2508.19205
-
[26]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust Speech Recognition via Large-Scale Weak Supervision. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara En...
2023
-
[27]
Jiatong Shi, Jionghao Han, Yichen Lu, Santiago Pascual, Pengfei Wu, Chenye Cui, Shinji Watanabe, Chao Weng, and Cong Zhou. 2025. Speech-DRAME: A Frame- work for Human-Aligned Benchmarks in Speech Role-Play.CoRRabs/2511.01261 (2025). arXiv:2511.01261 doi:10.48550/ARXIV.2511.01261
-
[28]
Reo Shimizu, Ryuichi Yamamoto, Masaya Kawamura, Yuma Shirahata, Hironori Doi, Tatsuya Komatsu, and Kentaro Tachibana. 2024. PromptTTS++: Control- ling Speaker Identity in Prompt-Based Text-To-Speech Using Natural Language Descriptions. InIEEE International Conference on Acoustics, Speech and Signal Pro- cessing, ICASSP 2024, Seoul, Republic of Korea, Apri...
-
[29]
Gemini Team. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.CoRR abs/2507.06261 (2025). arXiv:2507.06261 doi:10.48550/ARXIV.2507.06261
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[30]
Qwen Team. 2026. Qwen3-TTS Technical Report.CoRRabs/2601.15621 (2026). arXiv:2601.15621 doi:10.48550/ARXIV.2601.15621
-
[32]
Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, Weizhen Bian, Zhen Ye, Sitong Cheng, Ruibin Yuan, Zhixian Zhao, Xinfa Zhu, Jiahao Pan, Liumeng Xue, Pengcheng Zhu, Yunlin Chen, Zhifei Li, Xie Chen, Lei Xie, Yike Guo, and Wei Xue
-
[33]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single- Stream Decoupled Speech Tokens.CoRRabs/2503.01710 (2025). arXiv:2503.01710 doi:10.48550/ARXIV.2503.01710
-
[34]
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Ji- achen Zheng, Qiang Zhang, Xueyao Zhang, Shunsi Zhang, and Zhizheng Wu
-
[35]
InThe Thirteenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28, 2025
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer. InThe Thirteenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https: //openreview.net/forum?id=ExuBFYtCQU
2025
-
[36]
Kangxiang Xia, Xinfa Zhu, Jixun Yao, Wenjie Tian, Wenhao Li, and Lei Xie. 2026. KALL-E: Autoregressive Speech Synthesis with Next-Distribution Prediction. In Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educa- tional Advances in Artificial Intell...
-
[37]
LLM-Core Xiaomi. 2025. MiMo-Audio: Audio Language Models are Few-Shot Learners.CoRRabs/2512.23808 (2025). arXiv:2512.23808 doi:10.48550/ARXIV. 2512.23808
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[38]
Hanke Xie, Haopeng Lin, Wenxiao Cao, Dake Guo, Wenjie Tian, Jun Wu, Hanlin Wen, Ruixuan Shang, Hongmei Liu, Zhiqi Jiang, Yuepeng Jiang, Wenxi Chen, Ruiqi Yan, Jiale Qian, Yichao Yan, Shunshun Yin, Ming Tao, Xie Chen, Lei Xie, and Xinsheng Wang. 2025. SoulX-Podcast: Towards Realistic Long-form Podcasts with Dialectal and Paralinguistic Diversity. arXiv:251...
-
[39]
Liumeng Xue, Weizhen Bian, Jiahao Pan, Wenxuan Wang, Yilin Ren, Boyi Kang, Jingbin Hu, Ziyang Ma, Shuai Wang, Xinyuan Qian, Hung yi Lee, and Yike Guo. 2026. NVBench: A Benchmark for Speech Synthesis with Non-Verbal Vocalizations. arXiv:2604.16211 [cs.SD] https://arxiv.org/abs/2604.16211
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Dongchao Yang, Songxiang Liu, Rongjie Huang, Chao Weng, and Helen Meng
-
[41]
InstructTTS: Modelling Expressive TTS in Discrete Latent Space With Natural Language Style Prompt.IEEE ACM Trans. Audio Speech Lang. Process.32 (2024), 2913–2925. doi:10.1109/TASLP.2024.3402088
-
[42]
Guanrou Yang, Chen Yang, Qian Chen, Ziyang Ma, Wenxi Chen, Wen Wang, Tianrui Wang, Yifan Yang, Zhikang Niu, Wenrui Liu, Fan Yu, Zhihao Du, Zhifu Gao, Shiliang Zhang, and Xie Chen. 2025. EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting. InProceedings of the 33rd ACM International Conference on Multimedia, MM 2025, Dublin, Ir...
-
[43]
Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi Dai, Hongzhan Lin, Jianyi Chen, Xingjian Du, Li- umeng Xue, Yunlin Chen, Zhifei Li, Lei Xie, Qiuqiang Kong, Yike Guo, and Wei Xue. 2025. Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis.CoRRabs/2502.04128 (2025). ar...
-
[44]
Jun Zhan, Mingyang Han, Yuxuan Xie, Chen Wang, Dong Zhang, Kexin Huang, Haoxiang Shi, DongXiao Wang, Tengtao Song, Qinyuan Cheng, Shimin Li, Jun Song, Xipeng Qiu, and Bo Zheng. 2025. VStyle: A Benchmark for Voice Style Adap- tation with Spoken Instructions.CoRRabs/2509.09716 (2025). arXiv:2509.09716 doi:10.48550/ARXIV.2509.09716
-
[45]
Xueyao Zhang, Junan Zhang, Yuancheng Wang, Chaoren Wang, Yuanzhe Chen, Dongya Jia, Zhuo Chen, and Zhizheng Wu. 2025. Vevo2: Bridging Controllable Speech and Singing Voice Generation via Unified Prosody Learning.CoRR abs/2508.16332 (2025). arXiv:2508.16332 doi:10.48550/ARXIV.2508.16332
- [46]
-
[47]
Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. 2026. IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech. InFortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Sympo...
-
[48]
Yixuan Zhou, Xiaoyu Qin, Zeyu Jin, Shuoyi Zhou, Shun Lei, Songtao Zhou, Zhiyong Wu, and Jia Jia. 2024. VoxInstruct: Expressive Human Instruction- to-Speech Generation with Unified Multilingual Codec Language Modelling. InProceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 202...
-
[49]
Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, Zhiyong Wu, and Zhiyuan Liu. 2025. VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning.CoRRabs/2509.24650 (2025). arXiv:2509.24650 doi:10.48550/ARXIV.2509.24650
-
[50]
Xinfa Zhu, Wenjie Tian, Xinsheng Wang, Lei He, Yujia Xiao, Xi Wang, Xu Tan, Sheng Zhao, and Lei Xie. 2024. UniStyle: Unified Style Modeling for Speaking Style Captioning and Stylistic Speech Synthesis. InProceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 2024, Jianfei Cai, M...
-
[51]
the control target(s), 3
the taxonomy path, 2. the control target(s), 3. the intended target value(s),
-
[52]
the intended text semantic type and text length,
the realization style needed later, 5. the intended text semantic type and text length,
-
[53]
The goal of this stage is to create a clean, diverse, balanced, non-leaking, benchmark-ready scratch plan that can later be converted into final instruction-text pairs
any constraints needed later for generating the final instruction and text. The goal of this stage is to create a clean, diverse, balanced, non-leaking, benchmark-ready scratch plan that can later be converted into final instruction-text pairs. — GENERAL RULES —
-
[54]
Only plan the later instruction style and constraints
Do NOT generate final polished instructions. Only plan the later instruction style and constraints
-
[55]
Only specify text_semantic, text_length, and text_constraints
Do NOT generate final text sentences. Only specify text_semantic, text_length, and text_constraints
-
[56]
Text semantics must not trivially leak the target control attributes. Examples: - if the target is age=child, do not force child-themed lexical content - if the target is emotion=angry, do not force obviously angry words into the text - if the target is accent=sichuan, do not force dialect words unless explicitly required
-
[57]
Keep the difficulty determined mainly by the taxonomy node, not by overly complicated text content
-
[58]
Prefer diversity across: target values, semantic content types, attribute combinations, and instruction realization styles when the node allows more than one realization style
-
[59]
Do not invent out-of-scope labels or values
Use the provided allowed_labels and allowed_values strictly. Do not invent out-of-scope labels or values
-
[60]
Speak in Japanese
Output ONLY valid JSON. No explanations outside JSON. — LANGUAGE REALIZATION POLICY — A. Primary languages - If language is zh, the later final instruction and final text must both be Chinese. - If language is en, the later final instruction and final text must both be English. B. Non-primary languages - If language is ja / ko / pt / fr / de / it / ru / e...
-
[61]
Do not change meta_path
Follow the label plan strictly. Do not change meta_path. Do not add extra control targets. Do not ignore instruction_form, text_semantic, or instruction_constraints
-
[62]
The instruction must match the intended realization mechanism:tag(fixed key-value tags) ordirect(natural voice-direction)
-
[63]
Avoid fragments unless explicitly required
The text must be natural and speakable for TTS. Avoid fragments unless explicitly required. Avoid obscure wording
-
[64]
The text must NOT trivially leak the target. Examples: - child voice target does not mean child-themed lexical content - angry target does not mean explicit angry wording - accent target does not mean dialect spellings unless explicitly required
-
[65]
Difficulty should come mainly from the control design, not from making the text content artificially complicated
-
[66]
Do NOT copy franchise names, titles, or character names into the final instruction or text
Respect aux_values only as interpretation hints. Do NOT copy franchise names, titles, or character names into the final instruction or text
-
[67]
Speak in Japanese
Output ONLY valid JSON. — LANGUAGE POLICY — A. zh: instruction must be Chinese, text must be Chinese. B. en: instruction must be English, text must be English. C. ja / ko / pt / fr / de / it / ru / es: - instruction must be English - instruction must explicitly cue the target language with a prefix like: "Speak in Japanese. " - text must be written in the...
-
[68]
shuxing: zhi
Chinese tag instructions must use fixed "shuxing: zhi" format
-
[69]
Attribute: Value
All non-Chinese instruction languages must use fixed "Attribute: Value" format
-
[70]
For multi-attribute tag items, every attribute must appear in the same fixed format
-
[71]
Do not paraphrase tag items into free prose
-
[72]
Speak in Japanese. Attribute: Value, Attribute: Value
For non-primary languages, keep the English target-language prefix and then use English key-value tags. Example pattern: "Speak in Japanese. Attribute: Value, Attribute: Value" — DIRECT INSTRUCTION RULES — If instruction_form is direct: - use natural, operational voice-direction phrasing - keep easy items concise, make hard items richer only when the cont...
-
[73]
If only partial, assign level 2
complex_comp/static: judge whether multiple requested attributes are simultaneously realized. If only partial, assign level 2
-
[74]
Check if multiple stages are audible, order matches, and progression is clear
complex_comp/dynamic: judge temporal progression explicitly. Check if multiple stages are audible, order matches, and progression is clear. If too weak or binary, do not give level 3
-
[75]
complex_comp/layered: judge whether both surface and hidden affect are audible
-
[76]
complex_comp/conflict: judge whether both conflicting cues are present
-
[77]
Do not reward generic style if the requested persona is not clearly formed
persona (scenario/social_role/archetype): judge the overall role/scenario impression. Do not reward generic style if the requested persona is not clearly formed
-
[78]
Full credit requires the audio strongly evokes the described portrait through audible cues (age, texture, pitch, rhythm, accent, temperament)
persona/ip_portrait: evaluate against the abstract vocal portrait described in the instruction. Full credit requires the audio strongly evokes the described portrait through audible cues (age, texture, pitch, rhythm, accent, temperament). Vague generic resemblance is not enough for level 3. — INSTRUCTION-FOLLOWING LEVELS — 1 = bad: the requested structure...
-
[79]
If it does not clearly occur, it cannot receive high credit
explicit_nv / implicit_nv Evaluate in two steps: Step A: event existence - first judge whether the requested nonverbal event actually occurs. If it does not clearly occur, it cannot receive high credit. Step B: placement / frequency / appropriateness - if the event occurs, judge whether its placement/frequency roughly matches the instruction, and its real...
-
[80]
The disfluency must be sustained enough or patterned enough to be an intentional abnormal speaking state
abnormal/disfluency Only count clearly speaker-produced fluency disruption. The disfluency must be sustained enough or patterned enough to be an intentional abnormal speaking state. Do not count a single irregularity or isolated hesitation as full realization
-
[81]
The state must be audibly sustained, not a single rough syllable or isolated artifact
abnormal/dysphonia Only count a continuous abnormal voice-state condition. The state must be audibly sustained, not a single rough syllable or isolated artifact. Do not confuse ordinary texture with pathological/abnormal phonation unless clearly sustained. — INSTRUCTION-FOLLOWING LEVELS — 1 = bad: the requested event/state is absent, unclear, accidental, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.