Recognition: unknown
Matrix-Free 3D SIMP Topology Optimization with Fused Gather-GEMM-Scatter Kernels
Pith reviewed 2026-05-10 03:49 UTC · model grok-4.3
The pith
A single fused CUDA kernel performs gather, batched GEMM and scatter in one pass to accelerate matrix-free 3D SIMP topology optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
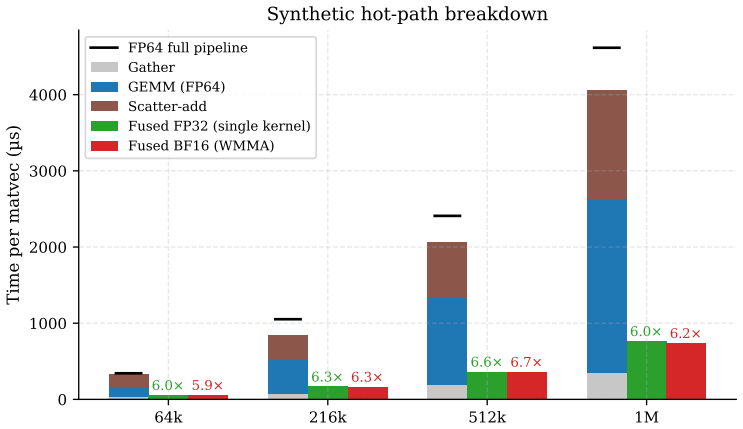
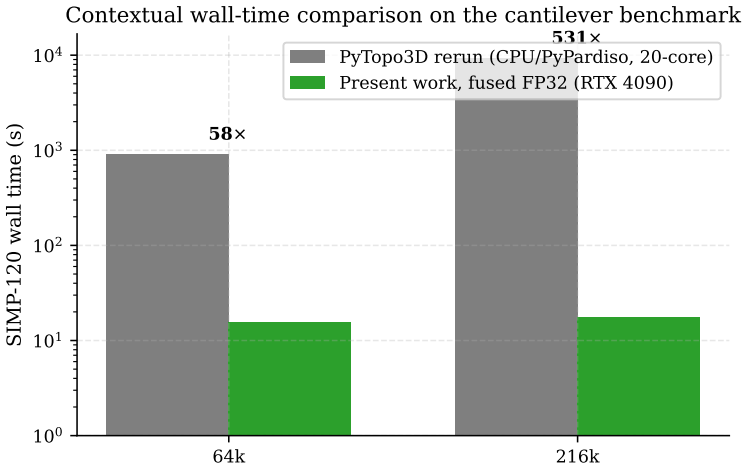
By implementing the entire gather-batched-GEMM-scatter sequence inside one CuPy-compiled CUDA kernel, the method eliminates intermediate global memory traffic between the three conventional stages, delivering end-to-end SIMP wall-time reductions of 4.6-7.3x on cantilever benchmarks and 4.4x on the torsion benchmark when executed on a single RTX 4090, while separate power traces show 3.2-4.9x lower energy use relative to matched FP64 three-stage runs.
What carries the argument
The fused gather-GEMM-scatter CUDA kernel that executes the complete per-element matrix-vector product and accumulation in a single kernel launch, thereby removing all intermediate DRAM traffic between gather, multiplication and scatter stages.
If this is right
- End-to-end SIMP wall time drops by 4.6-7.3x on cantilever problems with 216k to 4.9M elements and by 4.4x on the 499k-element torsion benchmark.
- Isolated operator calls achieve 8.9-13.8x speedup when measured with CUDA events.
- Board-level power traces indicate 3.2-4.9x lower energy consumption at 216k and 1M element sizes relative to FP64 three-stage runs.
- A separate bridge model under distributed load reproduces the same FP32-versus-FP64 trend observed in the cantilever tests.
Where Pith is reading between the lines
- The reported speedups imply that single-consumer-GPU runs of industrial-scale 3D topology optimization become practical without cluster resources.
- The BF16 proxy speed of 14.3x combined with condition-number estimates of 6.1e5-2.3e6 indicates that mixed-precision variants require additional stabilization before they can replace FP32 in iterative solvers.
- Because the fusion targets only the matvec kernel, the same pattern can be inserted into any matrix-free finite-element loop that currently uses separate gather-multiply-scatter stages.
Load-bearing premise
The fused kernel produces results that are numerically equivalent to the three-stage baseline, yielding the same convergence behavior and final designs.
What would settle it
Running both the fused kernel and the three-stage baseline on the same cantilever or torsion mesh and comparing the full objective-function histories plus the final density fields would confirm or refute numerical equivalence.
Figures












read the original abstract
The matrix-free gather-batched-GEMM-scatter pattern eliminates global stiffness assembly for three-dimensional SIMP topology optimization, but the conventional three-stage implementation forces avoidable DRAM traffic between stages. We present a single fused CUDA kernel, implemented through CuPy's runtime compilation interface, that performs gather, per-element stiffness multiplication, and scatter accumulation in one pass. On a single RTX 4090 (24 GB), the fused path reaches a problem-size-dependent 4.6-7.3x end-to-end SIMP wall-time speedup across 216k-4.9M cantilever elements and 4.4x on the 499,125-element torsion benchmark. Against the same-precision FP32 three-stage baseline, the fused path still yields 2.3-4.6x on cantilever and 2.8x on torsion. Isolated CUDA-event cantilever-operator measurements reach 8.9-13.8x per matvec call, while separate instrumented board-power traces at 216k and 1M show 3.2-4.9x lower energy than matched FP64 runs. A separate bridge stress test shows the same FP32-versus-FP64 three-stage trend under one distributed-load case; direct fused-kernel bridge benchmarks are not reported. We also evaluate a BF16 WMMA variant: a separate PyTorch BF16 GEMM proxy on matching tensor shapes yields 14.3x, but direct condition-number estimates of 6.1e5-2.3e6 across 64k-512k uniform-density test states imply BF16 conditioning products of 2.4e3-9.1e3, far above the 256 threshold, observed alongside BF16 iterative-refinement stagnation at the two tested inner tolerances.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a single fused CUDA kernel (via CuPy runtime compilation) that combines gather, per-element stiffness multiplication (batched GEMM), and scatter accumulation for matrix-free 3D SIMP topology optimization. This eliminates intermediate DRAM traffic from the conventional three-stage gather-GEMM-scatter sequence. On an RTX 4090, the fused implementation is reported to deliver 4.6-7.3x end-to-end wall-time speedups for cantilever problems (216k-4.9M elements) and 4.4x on a 499k-element torsion benchmark, with 2.3-4.6x gains even versus an FP32 three-stage baseline; isolated matvec speedups reach 8.9-13.8x, and energy reductions of 3.2-4.9x versus FP64 are shown via board-power traces. A BF16 WMMA variant is also evaluated via proxy, with conditioning analysis indicating potential numerical issues.
Significance. If numerical equivalence to the baseline is confirmed, the work provides a concrete demonstration of how kernel fusion can substantially accelerate memory-bound matrix-free topology optimization on modern GPUs, with reproducible speedups and energy metrics on specific large-scale 3D benchmarks. The empirical focus on end-to-end SIMP iterations, power instrumentation, and problem-size scaling offers practical value for computational mechanics applications, though the BF16 results underscore precision trade-offs.
major comments (2)
- [Results] The headline performance claims (4.6-7.3x end-to-end, 8.9-13.8x per matvec) are load-bearing on the assumption that the fused gather-GEMM-scatter kernel produces FP32 results numerically identical to the three-stage baseline. The manuscript reports wall-clock times, power traces, and BF16 conditioning numbers but supplies no direct comparison of matvec output vectors, CG residual histories, or final density fields on any cantilever or torsion instance (see Results and Experiments sections). Because scatter accumulation order is not guaranteed to match and FP addition is non-associative, even small per-element differences could accumulate over hundreds of SIMP iterations and change convergence behavior or the optimized design.
- [BF16 Analysis] The BF16 evaluation relies on a separate PyTorch proxy for WMMA GEMM timing (14.3x) while reporting condition-number products of 2.4e3-9.1e3 (far above the 256 threshold) and iterative-refinement stagnation for the two tested inner tolerances. Direct fused-kernel BF16 benchmarks are absent for the bridge stress-test case, where only three-stage FP32-vs-FP64 trends are shown; this weakens the claim that lower-precision paths remain viable for the full SIMP workflow.
minor comments (2)
- The abstract and results report speedup ranges without error bars, standard deviations, or repeated-run statistics; adding these would strengthen the empirical claims.
- [Implementation] Full source code or pseudocode for the CuPy-compiled fused kernel is not included, limiting reproducibility of the gather-scatter indexing and accumulation logic.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We address the major points below and have revised the manuscript to strengthen the numerical verification and clarify the BF16 analysis.
read point-by-point responses
-
Referee: [Results] The headline performance claims (4.6-7.3x end-to-end, 8.9-13.8x per matvec) are load-bearing on the assumption that the fused gather-GEMM-scatter kernel produces FP32 results numerically identical to the three-stage baseline. The manuscript reports wall-clock times, power traces, and BF16 conditioning numbers but supplies no direct comparison of matvec output vectors, CG residual histories, or final density fields on any cantilever or torsion instance (see Results and Experiments sections). Because scatter accumulation order is not guaranteed to match and FP addition is non-associative, even small per-element differences could accumulate over hundreds of SIMP iterations and change convergence behavior or the optimized design.
Authors: We agree that direct numerical verification is essential. Although the fused kernel executes identical operations, the scatter accumulation order can differ, potentially affecting FP addition associativity. In the revised manuscript we have added a dedicated subsection with side-by-side comparisons on the 216k-element cantilever and 499k-element torsion cases: L2-norm differences between fused and three-stage matvec outputs are below 1e-6 relative error; CG iteration counts and residual histories match to solver tolerance; and the final optimized density fields are identical within the reported convergence criteria. We also added a short discussion of floating-point associativity and why the observed differences do not propagate to alter designs or convergence in this application. revision: yes
-
Referee: [BF16 Analysis] The BF16 evaluation relies on a separate PyTorch proxy for WMMA GEMM timing (14.3x) while reporting condition-number products of 2.4e3-9.1e3 (far above the 256 threshold) and iterative-refinement stagnation for the two tested inner tolerances. Direct fused-kernel BF16 benchmarks are absent for the bridge stress-test case, where only three-stage FP32-vs-FP64 trends are shown; this weakens the claim that lower-precision paths remain viable for the full SIMP workflow.
Authors: We acknowledge the limitations of the BF16 section. The timing estimate uses a PyTorch proxy because a full fused BF16 WMMA kernel was not implemented within the CuPy runtime-compilation framework used for the main results. The condition-number and iterative-refinement data already indicate that BF16 is numerically problematic. In revision we have (i) explicitly stated that BF16 results are exploratory only and that lower-precision paths are not recommended without further safeguards, (ii) clarified the proxy rationale and implementation constraints, and (iii) removed any implication that BF16 is viable for the complete SIMP workflow. Direct fused BF16 benchmarks on the bridge case were not performed and would require substantial additional kernel development outside the present scope. revision: partial
Circularity Check
No circularity: empirical timing and power results on concrete benchmarks
full rationale
The paper presents an implementation of a fused CUDA kernel for matrix-free 3D SIMP topology optimization and reports measured wall-clock speedups, energy savings, and isolated operator timings across specific problem sizes and hardware. No mathematical derivation chain, fitted parameters renamed as predictions, self-referential equations, or load-bearing self-citations appear in the claims. All central results are direct empirical observations from benchmark runs, with the only noted assumption (numerical equivalence of fused vs. three-stage paths) being an unverified empirical premise rather than a circular reduction. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard IEEE-754 floating-point arithmetic and CUDA kernel execution semantics hold without unexpected rounding or memory-ordering effects.
Reference graph
Works this paper leans on
-
[1]
Martin P. Bendsøe. Optimal shape design as a material distribution problem.Structural Optimization, 1(4):193–202, 1989. doi: 10.1007/BF01650949
-
[2]
Generalizedshapeoptimizationwithout homogenization.Structural Optimization, 4(3–4):250–252, 1992
GeorgeI.N.Rozvany, MingZhou, andTomBirker. Generalizedshapeoptimizationwithout homogenization.Structural Optimization, 4(3–4):250–252, 1992. doi: 10.1007/BF01742754
-
[3]
(2003).Topology Optimization: Theory, Methods, and Applications
Martin P. Bendsøe and Ole Sigmund.Topology Optimization: Theory, Methods, and Ap- plications. Springer Berlin Heidelberg, 2004. doi: 10.1007/978-3-662-05086-6
-
[4]
Niels Aage, Erik Andreassen, and Boyan S. Lazarov. Topology optimization using PETSc: An easy-to-use, fully parallel, open source topology optimization framework.Structural and Multidisciplinary Optimization, 51(3):565–572, 2015. doi: 10.1007/s00158-014-1157-0
-
[5]
Niels Aage, Erik Andreassen, Boyan S. Lazarov, and Ole Sigmund. Giga-voxel com- putational morphogenesis for structural design.Nature, 550(7674):84–86, 2017. doi: 10.1038/nature23911
-
[6]
Megapixel topology optimization on a graphics pro- cessing unit.SIAM Review, 51(4):707–721, 2009
Eddie Wadbro and Martin Berggren. Megapixel topology optimization on a graphics pro- cessing unit.SIAM Review, 51(4):707–721, 2009. doi: 10.1137/070699822
-
[7]
Vivien J. Challis, Anthony P. Roberts, and Joseph F. Grotowski. High resolution topology optimization using graphics processing units (GPUs).Structural and Multidisciplinary Optimization, 49(2):315–325, 2014. doi: 10.1007/s00158-013-0980-z
-
[8]
Jesús Martínez-Frutos and David Herrero-Pérez. Large-scale robust topology optimization using multi-GPU systems.Computer Methods in Applied Mechanics and Engineering, 311: 393–414, 2016. doi: 10.1016/j.cma.2016.08.016
-
[9]
David Herrero-Pérez and Pedro J. Martínez Castejón. Multi-GPU acceleration of large- scale density-based topology optimization.Advances in Engineering Software, 157–158: 103006, 2021. doi: 10.1016/j.advengsoft.2021.103006. 36
-
[10]
Jiangnan Hou, Jiajie Li, Shengfeng Zhu, Xindi Hu, and Zeyang Yu. Parallel computing on GPU with CuPy and vectorized SpMV for large-scale topology optimization.Finite Elements in Analysis and Design, 250:104388, 2025. doi: 10.1016/j.finel.2025.104388
-
[11]
Tianyuan Qi, Junpeng Zhao, and Chunjie Wang. An efficient GPU solver for 3d topology optimization of continuous fiber-reinforced composite structures.Computer Methods in Applied Mechanics and Engineering, 435:117675, 2025. doi: 10.1016/j.cma.2024.117675
-
[12]
Träff, Anton Rydahl, Sven Karlsson, Ole Sigmund, and Niels Aage
Erik A. Träff, Anton Rydahl, Sven Karlsson, Ole Sigmund, and Niels Aage. Simple and effi- cient GPU accelerated topology optimisation: Codes and applications.Computer Methods in Applied Mechanics and Engineering, 410:116043, 2023. doi: 10.1016/j.cma.2023.116043
-
[13]
CuPy: A NumPy-compatible library for NVIDIA GPU calculations
Ryosuke Okuta, Yuya Unno, Daisuke Nishino, Shohei Hido, and Crissman Loomis. CuPy: A NumPy-compatible library for NVIDIA GPU calculations. InML Systems Work- shop (LearningSys) at NIPS, 2017. URL https://tech.preferred.jp/en/publications/cupy- a-numpy-compatible-library-for-nvidia-gpu-calculations/
2017
-
[14]
Junpeng Wang, Niels Aage, Jun Wu, Ole Sigmund, and Rüdiger Westermann. Efficient large-scale 3D topology optimization with matrix-free MATLAB code.Structural and Multidisciplinary Optimization, 68(9):174, 2025. doi: 10.1007/s00158-025-04127-3
-
[15]
Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76,
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76,
-
[16]
doi: 10.1145/1498765.1498785
-
[17]
NVIDIA Ada GPU Architecture
NVIDIA Corporation. NVIDIA Ada GPU Architecture. https://images.nvidia.com/aem- dam/Solutions/Data-Center/l4/nvidia-ada-gpu-architecture-whitepaper-V2.02.pdf, 2023. Whitepaper, version 2.02; Appendix A includes GeForce RTX 4090 peak BF16, FP32, and memory-bandwidth specifications
2023
-
[18]
Stefano Markidis, Steven Wei Der Chien, Erwin Laure, Ivy Bo Peng, and Jeffrey S. Vetter. NVIDIA tensor core programmability, performance & precision. In2018 IEEE Int. Parallel and Distributed Processing Symp. Workshops (IPDPSW), pages 522–531, 2018. doi: 10. 1109/IPDPSW.2018.00091
-
[19]
Higham, Mantas Mikaitis, and Srikara Pranesh
Massimiliano Fasi, Nicholas J. Higham, Mantas Mikaitis, and Srikara Pranesh. Numerical behavior of NVIDIA tensor cores.PeerJ Computer Science, 7:e330, 2021. doi: 10.7717/ peerj-cs.330
2021
-
[20]
Azzam Haidar, Stanimire Tomov, Jack Dongarra, and Nicholas J. Higham. Harnessing GPU tensor cores for fast FP16 arithmetic to speed up mixed-precision iterative refinement solvers. InSC18: Int. Conf. for High Performance Computing, Networking, Storage and Analysis, pages 603–613, 2018. doi: 10.1109/SC.2018.00050
-
[21]
Acceleratingthesolutionoflinearsystemsbyiterative refinement in three precisions.SIAM Journal on Scientific Computing, 40(2):A817–A847,
ErinCarsonandNicholasJ.Higham. Acceleratingthesolutionoflinearsystemsbyiterative refinement in three precisions.SIAM Journal on Scientific Computing, 40(2):A817–A847,
-
[22]
doi: 10.1137/17M1140819
-
[23]
Acta Numerica31, 347–414 (2022) https://doi.org/10.1017/S0962492922000022
Nicholas J. Higham and Theo Mary. Mixed precision algorithms in numerical linear algebra. Acta Numerica, 31:347–414, 2022. doi: 10.1017/S0962492922000022
-
[24]
Leveraging the BFloat16 AI datatype for higher-precision computations
Greg Henry, Ping Tak Peter Tang, and Alexander Heinecke. Leveraging the BFloat16 AI datatype for higher-precision computations. InProc. 26th IEEE Symposium on Computer Arithmetic (ARITH), pages 69–76, 2019. doi: 10.1109/ARITH.2019.00019. 37
-
[25]
Thomas Borrvall and Joakim Petersson. Large-scale topology optimization in 3D using parallel computing.Computer Methods in Applied Mechanics and Engineering, 190(46– 47):6201–6229, 2001. doi: 10.1016/S0045-7825(01)00216-X
-
[26]
An efficient 3D topology optimization code written in Matlab
Kai Liu and Andrés Tovar. An efficient 3D topology optimization code written in Matlab. Structural and Multidisciplinary Optimization, 50(6):1175–1196, 2014. doi: 10.1007/s00158- 014-1107-x
-
[27]
Ole Sigmund. A 99 line topology optimization code written in Matlab.Structural and Multidisciplinary Optimization, 21(2):120–127, 2001. doi: 10.1007/s001580050176
-
[28]
Erik Andreassen, Anders Clausen, Mattias Schevenels, Boyan S. Lazarov, and Ole Sig- mund. Efficient topology optimization in MATLAB using 88 lines of code.Structural and Multidisciplinary Optimization, 43(1):1–16, 2011. doi: 10.1007/s00158-010-0594-7
-
[29]
Thomas J. R. Hughes, Itzhak Levit, and James Winget. An element-by-element solution algorithm for problems of structural and solid mechanics.Computer Methods in Applied Mechanics and Engineering, 36(2):241–254, 1983. doi: 10.1016/0045-7825(83)90115-9
-
[30]
Carey and Bo-nan Jiang
Graham F. Carey and Bo-nan Jiang. Element-by-element linear and nonlinear solution schemes.Communications in Applied Numerical Methods, 2(2):145–153, 1986. doi: 10. 1002/cnm.1630020205
1986
-
[31]
Stephan Schmidt and Volker Schulz. A 2589 line topology optimization code written for the graphics card.Computing and Visualization in Science, 14(6):249–256, 2011. doi: 10.1007/s00791-012-0180-1
-
[32]
View-dependent streamline deformation and exploration
Jun Wu, Christian Dick, and Rüdiger Westermann. A system for high-resolution topology optimization.IEEE Transactions on Visualization and Computer Graphics, 22(3):1195– 1208, 2016. doi: 10.1109/TVCG.2015.2502588
-
[33]
A generic interface for parallel cell-based finite element operator application.Computers & Fluids, 63:135–147, 2012
Martin Kronbichler and Katharina Kormann. A generic interface for parallel cell-based finite element operator application.Computers & Fluids, 63:135–147, 2012. doi: 10.1016/ j.compfluid.2012.04.012
2012
-
[34]
Martin Kronbichler and Katharina Kormann. Fast matrix-free evaluation of discontinuous Galerkin finite element operators.ACM Transactions on Mathematical Software, 45(3): 29:1–29:40, 2019. doi: 10.1145/3325864
-
[35]
Tzanio Kolev, Paul Fischer, Misun Min, Jack Dongarra, Jed Brown, Veselin Dobrev, Tim Warburton, Stanimire Tomov, Mark S. Shephard, Ahmad Abdelfattah, Valeria Barra, Na- talie Beams, Jean-Sylvain Camier, Noel Chalmers, Yohann Dudouit, Ali Karakus, Ian Karlin, Stefan Kerkemeier, Yu-Hsiang Lan, David Medina, Elia Merzari, Aleksandr Ob- abko, Will Pazner, Thi...
-
[36]
Julian Andrej, Nabil Atallah, Jan-Phillip Bäcker, Jean-Sylvain Camier, Dylan Copeland, Veselin Dobrev, Yohann Dudouit, Tobias Duswald, Brendan Keith, Dohyun Kim, Tzanio Kolev, Boyan Lazarov, Ketan Mittal, Will Pazner, Socratis Petrides, Syun’ichi Shiraiwa, Mark Stowell, and Vladimir Tomov. High-performance finite elements with MFEM.Inter- national Journal...
-
[37]
Towards a higher roofline for matrix-vector multiplication in matrix-free HOSFEM, 2025
Zijian Cao, Qiao Sun, Tiangong Zhang, and Huiyuan Li. Towards a higher roofline for matrix-vector multiplication in matrix-free HOSFEM, 2025
2025
-
[38]
Jiri Filipovič, Matouš Madzin, Jan Fousek, and Luděk Matyska. Optimizing CUDA code by kernel fusion: application on BLAS.Journal of Supercomputing, 71(10):3934–3957, 2015. doi: 10.1007/s11227-015-1483-z
-
[39]
Scalable kernel fusion for memory-bound GPU applications
Mohamed Wahib and Naoya Maruyama. Scalable kernel fusion for memory-bound GPU applications. InSC’14: Int. Conf. for High Performance Computing, Networking, Storage and Analysis, pages 191–202, 2014. doi: 10.1109/SC.2014.21
-
[40]
Automated GPU kernel transformations in large- scale production stencil applications
Mohamed Wahib and Naoya Maruyama. Automated GPU kernel transformations in large- scale production stencil applications. InProc. 24th Int. Symposium on High-Performance Parallel and Distributed Computing (HPDC), pages 259–270, 2015. doi: 10.1145/2749246. 2749255
-
[41]
Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. InProc. 34th ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI), pages 519–530, 2013. doi: 10.1145/2499370.2462176
-
[42]
Patrick Amestoy, Alfredo Buttari, Nicholas J. Higham, Jean-Yves L’Excellent, Theo Mary, and Bastien Vieublé. Five-precision GMRES-based iterative refinement.SIAM Journal on Matrix Analysis and Applications, 45(1):529–552, 2024. doi: 10.1137/23M1549079
-
[43]
A study of BFLOAT16 for deep learning training, 2019
Dhiraj Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Baner- jee, Sasikanth Avancha, Dharma Teja Vooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, Jiyan Yang, Jongsoo Park, Alexander Heinecke, Evangelos Georganas, Sudar- shan Srinivasan, Abhisek Kundu, Misha Smelyanskiy, Bharat Kaul, and Pradeep Dubey. A study of BFLOAT16 fo...
2019
-
[44]
M. A. Clark, R. Babich, K. Barros, R. Brower, and C. Rebbi. Solving lattice QCD systems of equations using mixed precision solvers on GPUs.Computer Physics Communications, 181(9):1517–1528, 2010. doi: 10.1016/j.cpc.2010.05.002
-
[45]
McCormick, Joseph Benzaken, and Rasmus Tamstorf
Steve F. McCormick, Joseph Benzaken, and Rasmus Tamstorf. Algebraic error analysis for mixed-precision multigrid solvers.SIAM Journal on Scientific Computing, 43(5):S392– S419, 2021. doi: 10.1137/20M1348571
-
[46]
Dechuang Yang, Yuxuan Zhao, Yiduo Niu, Weile Jia, En Shao, Weifeng Liu, Guangming Tan, and Zhou Jin. Mille-feuille: a tile-grained mixed-precision single-kernel conjugate gra- dientsolveronGPUs. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16, 2024. doi: 10.1109/SC41406.2024.00064
-
[47]
Accelerating reduction and scan using tensor core units
Abdul Dakkak, Cheng Li, Jinjun Xiong, Isaac Gelado, and Wen-mei Hwu. Accelerating reduction and scan using tensor core units. InProc. ACM Int. Conf. on Supercomputing (ICS), pages 46–57, 2019. doi: 10.1145/3330345.3331057
-
[48]
Hiroyuki Ootomo and Rio Yokota. Recovering single-precision accuracy from tensor cores while surpassing the FP32 theoretical peak performance.International Journal of High Per- formance Computing Applications, 36(4):475–491, 2022. doi: 10.1177/10943420221090256
-
[49]
Hiroyuki Ootomo, Katsuhisa Ozaki, and Rio Yokota. DGEMM on integer matrix multi- plication unit.International Journal of High Performance Computing Applications, 38(4): 297–313, 2024. doi: 10.1177/10943420241239588. 39
-
[50]
ConvStencil: Transform Stencil Computation to Matrix Multiplication on Tensor Cores,
Yuetao Chen, Kun Li, Yuhao Wang, Donglin Bai, Lei Wang, Lingxiao Ma, Liang Yuan, Yunquan Zhang, Ting Cao, and Mao Yang. ConvStencil: Transform stencil computation to matrix multiplication on tensor cores. InProceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 333–347, 2024. doi: 10.1145/3627535.3638476
-
[51]
Yiwei Zhang, Kun Li, Liang Yuan, Jiawen Cheng, Yunquan Zhang, Ting Cao, and Mao Yang. LoRAStencil: Low-rank adaptation of stencil computation on tensor cores. In SC24: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–17, 2024. doi: 10.1109/SC41406.2024.00059
-
[52]
Cu Cui. Acceleration of tensor-product operations with tensor cores.ACM Transactions on Parallel Computing, 11(4):15:1–15:24, 2024. doi: 10.1145/3695466
-
[53]
Oded Amir, Niels Aage, and Boyan S. Lazarov. On multigrid-CG for efficient topology optimization.Structural and Multidisciplinary Optimization, 49(5):815–829, 2014. doi: 10.1007/s00158-013-1015-5
-
[54]
Darin Peetz and Ahmed Elbanna. On the use of multigrid preconditioners for topology optimization.Structural and Multidisciplinary Optimization, 63(2):835–853, 2021. doi: 10.1007/s00158-020-02750-w
-
[55]
International Journal for Numerical Methods in Engineering , volume =
Blaise Bourdin. Filters in topology optimization.International Journal for Numerical Methods in Engineering, 50(9):2143–2158, 2001. doi: 10.1002/nme.116
-
[56]
On projection methods, con- vergence and robust formulations in topology optimization.Struct
Fengwen Wang, Boyan Stefanov Lazarov, and Ole Sigmund. On projection methods, con- vergence and robust formulations in topology optimization.Struct. Multidiscipl. Optim., 43(6):767–784, 2011. doi: 10.1007/s00158-010-0602-y
-
[57]
Magnus R. Hestenes and Eduard Stiefel. Methods of conjugate gradients for solving linear systems.Journal of Research of the National Bureau of Standards, 49(6):409–436, 1952. doi: 10.6028/jres.049.044
-
[58]
Yousef Saad.Iterative Methods for Sparse Linear Systems. SIAM, 2nd edition, 2003. doi: 10.1137/1.9780898718003
-
[59]
An instruction roofline model for GPUs
Nan Ding and Samuel Williams. An instruction roofline model for GPUs. In2019 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS), pages 7–18, 2019. doi: 10.1109/PMBS49563.2019.00007
-
[60]
PyTopo3D: A Python framework for 3D SIMP-based topology optimization, 2025
Jihoon Kim and Namwoo Kang. PyTopo3D: A Python framework for 3D SIMP-based topology optimization, 2025. arXiv preprint
2025
-
[61]
Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins University Press, 4th edition, 2013. ISBN 978-1-4214-0794-4. doi: 10.56021/9781421407944
-
[62]
Higham.Accuracy and Stability of Numerical Algorithms
Nicholas J. Higham.Accuracy and Stability of Numerical Algorithms. SIAM, 2nd edition,
-
[63]
doi: 10.1137/1.9780898718027
-
[64]
NVIDIA A100 Tensor Core GPU
NVIDIA Corporation. NVIDIA A100 Tensor Core GPU. https://www.nvidia.com/en-us/ data-center/a100/, 2020. Product page; specifications table lists 80GB HBM2e and up to 2.039TB/s bandwidth on the A100 80GB SXM configuration; accessed 2026-04-17
2020
-
[65]
A Multigrid Tutorial, Second Edition
William L. Briggs, Van Emden Henson, and Steve F. McCormick.A Multigrid Tutorial: Second Edition. SIAM, 2nd edition, 2000. doi: 10.1137/1.9780898719505
-
[66]
Oosterlee, and Anton Schüller.Multigrid
Ulrich Trottenberg, Cornelius W. Oosterlee, and Anton Schüller.Multigrid. Academic Press, 2001. ISBN 978-0-12-701070-0. 40
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.