Recognition: unknown
CodePivot: Bootstrapping Multilingual Transpilation in LLMs via Reinforcement Learning without Parallel Corpora
Pith reviewed 2026-05-10 04:55 UTC · model grok-4.3
The pith
CodePivot shows that routing all code translations through Python as an intermediate step, combined with a novel reinforcement learning reward, allows a 7B model to develop multilingual transpilation abilities without any parallel corpora.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
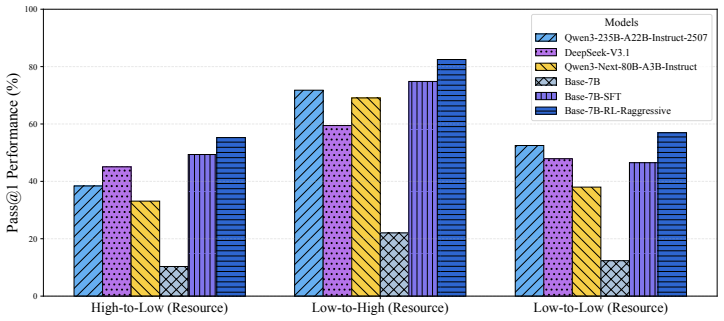
The paper establishes that a 7B LLM trained exclusively on Python-to-Others transpilation tasks using reinforcement learning with the Aggressive-Partial-Functional reward bootstraps the model's ability to perform multilingual transpilation, leading to consistent improvements on general and low-resource PL-related tasks and outperforming larger models such as Deepseek-R1 on Python-to-Others tasks and Qwen3-235B-A22B-Instruct-2507 on Others-to-All tasks.
What carries the argument
The CodePivot framework that routes every translation through Python as an intermediate representation, paired with the Aggressive-Partial-Functional reward in the reinforcement learning process to enable learning without parallel corpora for all pairs.
If this is right
- Training only on Python-to-Others tasks produces gains on both Python-to-Others and Others-to-All transpilation tasks.
- The 7B model outperforms substantially larger mainstream models on Python-to-Others tasks and on Others-to-All tasks.
- The approach yields better results on general transpilation tasks than a model trained directly on Any-to-Any tasks.
- Low-resource programming languages benefit because the method reduces reliance on scarce parallel data.
Where Pith is reading between the lines
- A similar pivot strategy could lower data needs in other multi-way adaptation settings where paired examples are limited.
- Rewards that credit partial functionality may prove useful in additional code-related training scenarios where exact outputs are rare at the start.
- The framework might allow quick addition of new programming languages by extending only the Python-to-new-language direction.
Load-bearing premise
The method assumes that Python can serve as an effective bridge for all language pairs and that the Aggressive-Partial-Functional reward will teach the model general translation rules that apply to unseen directions and low-resource languages.
What would settle it
A direct evaluation of the trained model on transpilation between two non-Python languages that share no training connections would show whether the claimed generalization holds without the Python pivot.
Figures




read the original abstract
Transpilation, or code translation, aims to convert source code from one programming language (PL) to another. It is beneficial for many downstream applications, from modernizing large legacy codebases to augmenting data for low-resource PLs. Recent large language model (LLM)-based approaches have demonstrated immense potential for code translation. Among these approaches, training-based methods are particularly important because LLMs currently do not effectively adapt to domain-specific settings that suffer from a lack of knowledge without targeted training. This limitation is evident in transpilation tasks involving low-resource PLs. However, existing training-based approaches rely on a pairwise transpilation paradigm, making it impractical to support a diverse range of PLs. This limitation is particularly prominent for low-resource PLs due to a scarcity of training data. Furthermore, these methods suffer from suboptimal reinforcement learning (RL) reward formulations. To address these limitations, we propose CodePivot, a training framework that leverages Python as an intermediate representation (IR), augmented by a novel RL reward mechanism, Aggressive-Partial-Functional reward, to bootstrap the model's multilingual transpilation ability without requiring parallel corpora. Experiments involving 10 PLs show that the resulting 7B model, trained on Python-to-Others tasks, consistently improves performance across both general and low-resource PL-related transpilation tasks. It outperforms substantially larger mainstream models with hundreds of billions more parameters, such as Deepseek-R1 and Qwen3-235B-A22B-Instruct-2507, on Python-to-Others tasks and Others-to-All tasks, respectively. In addition, it outperforms its counterpart trained directly on Any-to-Any tasks on general transpilation tasks. The code and data are available at https://github.com/lishangyu-hkust/CodePivot.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CodePivot, a training framework that uses Python as an intermediate representation combined with a novel Aggressive-Partial-Functional RL reward to enable multilingual code transpilation in LLMs without any parallel corpora. A 7B model is trained only on Python-to-Others tasks across 10 programming languages and is reported to improve performance on both general and low-resource transpilation benchmarks, outperforming substantially larger models (e.g., Deepseek-R1, Qwen3-235B) on Python-to-Others and Others-to-All tasks respectively, while also beating a direct Any-to-Any baseline.
Significance. If the central results hold, the work would be significant for low-resource language support in code models, as it removes the pairwise data requirement that currently limits scaling to many PLs. The public release of code and data at the GitHub link is a clear strength that supports reproducibility. The pivot-plus-RL approach, if shown to produce semantically faithful intermediates, could generalize to other domain-adaptation settings where parallel data is scarce.
major comments (2)
- [§3.2] §3.2 (Aggressive-Partial-Functional reward definition): the reward is load-bearing for the entire bootstrapping claim, yet the manuscript provides no correlation analysis or held-out unit-test results demonstrating that the reward (whether syntax-based, partial-execution, or model-judged) aligns with actual input-output semantic equivalence across the 10 languages; without this, the generalization from Python-to-Others training to reliable Others-to-All chaining remains unverified.
- [§4.3, Table 3] §4.3 and Table 3 (Others-to-All results): the headline outperformance over models with hundreds of billions more parameters is reported without error bars, multiple random seeds, or statistical significance tests; given the potential for error propagation through the Python pivot, these omissions make it impossible to assess whether the gains are robust or merely artifacts of the evaluation distribution.
minor comments (2)
- [Abstract] The abstract states performance gains but supplies no numerical metrics, baselines, or language-pair breakdowns; adding a compact results summary would improve readability.
- [§3.2] Notation for the reward components (e.g., how 'partial' and 'aggressive' are operationalized) is introduced without a compact equation or pseudocode box, making the method harder to re-implement from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments raise valid points regarding validation of the reward mechanism and statistical robustness of the results. We address each major comment point by point below, indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Aggressive-Partial-Functional reward definition): the reward is load-bearing for the entire bootstrapping claim, yet the manuscript provides no correlation analysis or held-out unit-test results demonstrating that the reward (whether syntax-based, partial-execution, or model-judged) aligns with actual input-output semantic equivalence across the 10 languages; without this, the generalization from Python-to-Others training to reliable Others-to-All chaining remains unverified.
Authors: We agree that explicit validation of the reward's alignment with semantic equivalence would strengthen the bootstrapping claim. The Aggressive-Partial-Functional reward combines aggressive partial execution, syntax verification, and model-based functional judgments to approximate input-output equivalence without parallel corpora. While the manuscript prioritizes end-to-end empirical gains on transpilation benchmarks, we acknowledge the value of direct correlation evidence. In the revised manuscript, we will add a new analysis subsection under §3.2 that reports Pearson correlations and held-out unit-test pass rates across all 10 languages, showing that reward scores positively correlate with semantic correctness. This addition will support the reliability of chaining through the Python pivot for Others-to-All tasks. revision: yes
-
Referee: [§4.3, Table 3] §4.3 and Table 3 (Others-to-All results): the headline outperformance over models with hundreds of billions more parameters is reported without error bars, multiple random seeds, or statistical significance tests; given the potential for error propagation through the Python pivot, these omissions make it impossible to assess whether the gains are robust or merely artifacts of the evaluation distribution.
Authors: We thank the referee for highlighting this important omission in statistical reporting. The results in Table 3 were obtained from single-run evaluations owing to substantial computational requirements for training the 7B model and evaluating against large baselines. To address potential error propagation in the pivot-based approach and to demonstrate robustness, we will revise §4.3 and Table 3 to include multiple random seeds (at least three), report means with standard deviations as error bars, and add paired statistical significance tests against the compared models. These changes will enable a clearer assessment of whether the observed outperformance is consistent. revision: yes
Circularity Check
No circularity: empirical RL training result on external benchmarks
full rationale
The paper presents an empirical training framework (Python pivot + Aggressive-Partial-Functional reward) whose central claim is measured performance gains on held-out transpilation benchmarks across 10 languages. No equations, fitted parameters, or self-citations are shown to reduce the reported improvements to the training inputs by construction. The reward mechanism and evaluation rest on external test cases rather than re-using the same fitted quantities or self-referential definitions. This is the normal non-circular outcome for an applied RL paper whose success is falsifiable on independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Python serves as an effective universal intermediate representation for transpilation across the tested languages
invented entities (1)
-
Aggressive-Partial-Functional reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Avatar: A parallel corpus for java-python program translation
Wasi Ahmad, Md Golam Rahman Tushar, Saikat Chakraborty, and Kai-Wei Chang. Avatar: A parallel corpus for java-python program translation. InFindings of the Association for Computational Linguistics: ACL 2023, pages 2268–2281, 2023
2023
-
[2]
Integrating large language models and reinforcement learning for non-linear reasoning.Proc
Yoav Alon and Cristina David. Integrating large language models and reinforcement learning for non-linear reasoning.Proc. ACM Softw. Eng., 2(FSE), June 2025
2025
-
[3]
Smollm-corpus, 2024
Loubna Ben Allal, Anton Lozhkov, Guilherme Penedo, Thomas Wolf, and Leandro von Werra. Smollm-corpus, 2024
2024
-
[4]
Verified code transpilation with llms.Advances in Neural Information Processing Systems, 37:41394–41424, 2024
Sahil Bhatia, Jie Qiu, Niranjan Hasabnis, Sanjit A Seshia, and Alvin Cheung. Verified code transpilation with llms.Advances in Neural Information Processing Systems, 37:41394–41424, 2024
2024
-
[5]
Enhancing code translation in language models with few-shot learning via retrieval- augmented generation
Manish Bhattarai, Javier E Santos, Shawn Jones, Ayan Biswas, Boian Alexandrov, and Daniel O’Malley. Enhancing code translation in language models with few-shot learning via retrieval- augmented generation. In2024 IEEE High Performance Extreme Computing Conference (HPEC), pages 1–8. IEEE, 2024
2024
-
[6]
Bigcode models leaderboard
BigCode. Bigcode models leaderboard. https://huggingface.co/spaces/bigcode/ bigcode-models-leaderboard, 2023. Accessed: 2024-05-24
2023
-
[7]
C2rust, January 2026
C2Rust. C2rust, January 2026
2026
-
[8]
Knowledge transfer from high-resource to low-resource programming languages for code llms.Proceedings of the ACM on Programming Languages, 8(OOPSLA2):677–708, 2024
Federico Cassano, John Gouwar, Francesca Lucchetti, Claire Schlesinger, Anders Freeman, Carolyn Jane Anderson, Molly Q Feldman, Michael Greenberg, Abhinav Jangda, and Arjun Guha. Knowledge transfer from high-resource to low-resource programming languages for code llms.Proceedings of the ACM on Programming Languages, 8(OOPSLA2):677–708, 2024
2024
-
[9]
Multipl-e: A scalable and polyglot approach to benchmarking neural code generation.IEEE Trans
Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. Multipl-e: A scalable and polyglot approach to benchmarking neural code generation.IEEE Trans. Softw. Eng., 49(7):3675–3691, July 2023. 15
2023
-
[10]
Evaluating Large Language Models Trained on Code
Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Seal: Towards diverse specification inference for linux interfaces from security patches
Wei Chen, Bowen Zhang, Chengpeng Wang, Wensheng Tang, and Charles Zhang. Seal: Towards diverse specification inference for linux interfaces from security patches. InProceedings of the Twentieth European Conference on Computer Systems, pages 1246–1262, 2025
2025
-
[12]
Cxgo, January 2026
Cxgo. Cxgo, January 2026
2026
-
[13]
The design and application of a retargetable peephole optimizer.ACM Transactions on Programming Languages and Systems (TOPLAS), 2(2):191–202, 1980
Jack W Davidson and Christopher W Fraser. The design and application of a retargetable peephole optimizer.ACM Transactions on Programming Languages and Systems (TOPLAS), 2(2):191–202, 1980
1980
-
[14]
Translating c to safer rust
Mehmet Emre, Ryan Schroeder, Kyle Dewey, and Ben Hardekopf. Translating c to safer rust. Proceedings of the ACM on Programming Languages, 5(OOPSLA):1–29, 2021
2021
-
[15]
Large language models for code translation: An in-depth analysis of code smells and functional correctness.ACM Transactions on Software Engineering and Methodology, 2025
Christof Feischl and Roman Kern. Large language models for code translation: An in-depth analysis of code smells and functional correctness.ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[16]
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Quentin Carbonneaux, Taco Cohen, and Gabriel Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning.arXiv preprint arXiv:2410.02089, 2024
-
[17]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. Deepseek-coder: When the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
Suchin Gururangan, Ana Marasovi´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. Don’t stop pretraining: Adapt language models to domains and tasks. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, ...
2020
-
[19]
Automated testing of cobol to java transformation.arXiv preprint arXiv:2504.10548, 2025
Sandeep Hans, Atul Kumar, Toshikai Yasue, Kouichi Ono, Saravanan Krishnan, Devika Sondhi, Fumiko Satoh, Gerald Mitchell, Sachin Kumar, and Diptikalyan Saha. Automated testing of cobol to java transformation.arXiv preprint arXiv:2504.10548, 2025
-
[20]
To tag, or not to tag: Translating c’s unions to rust’s tagged unions
Jaemin Hong and Sukyoung Ryu. To tag, or not to tag: Translating c’s unions to rust’s tagged unions. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 40–52, 2024
2024
-
[21]
Type-migrating c-to-rust translation using a large language model.Empirical Software Engineering, 30(1):3, 2025
Jaemin Hong and Sukyoung Ryu. Type-migrating c-to-rust translation using a large language model.Empirical Software Engineering, 30(1):3, 2025
2025
-
[22]
Neliac—dialect of algol.Communica- tions of the ACM, 3(8):463–468, 1960
Harry D Huskey, Maurice H Halstead, and R McArthur. Neliac—dialect of algol.Communica- tions of the ACM, 3(8):463–468, 1960
1960
-
[23]
Alphatrans: A neuro-symbolic compositional approach for repository-level code translation and validation.Proceedings of the ACM on Software Engineering, 2(FSE):2454–2476, 2025
Ali Reza Ibrahimzada, Kaiyao Ke, Mrigank Pawagi, Muhammad Salman Abid, Rangeet Pan, Saurabh Sinha, and Reyhaneh Jabbarvand. Alphatrans: A neuro-symbolic compositional approach for repository-level code translation and validation.Proceedings of the ACM on Software Engineering, 2(FSE):2454–2476, 2025
2025
-
[24]
J2cstranslator, January 2026
J2cstranslator. J2cstranslator, January 2026
2026
-
[25]
Cotran: An llm-based code translator using reinforcement learning with feedback from compiler and symbolic execution
Prithwish Jana, Piyush Jha, Haoyang Ju, Gautham Kishore, Aryan Mahajan, and Vijay Ganesh. Cotran: An llm-based code translator using reinforcement learning with feedback from compiler and symbolic execution. InECAI 2024, pages 4011–4018. IOS Press, 2024
2024
-
[26]
Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, and Jeffrey Dean
Melvin Johnson, Mike Schuster, Quoc V . Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, and Jeffrey Dean. Google’s multilingual neural machine translation system: Enabling zero-shot translation.Transactions of the Association for Computational Linguistics, 5:339–351, 2017. 16
2017
-
[27]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[28]
Llvm: A compilation framework for lifelong program analysis & transformation
Chris Lattner and Vikram Adve. Llvm: A compilation framework for lifelong program analysis & transformation. InInternational symposium on code generation and optimization, 2004. CGO 2004., pages 75–86. IEEE, 2004
2004
-
[29]
Codei/o: Condensingreasoning patterns via code input-output prediction, 2025
Junlong Li, Daya Guo, Dejian Yang, Runxin Xu, Yu Wu, and Junxian He. Codei/o: Condensing reasoning patterns via code input-output prediction.arXiv preprint arXiv:2502.07316, 2025
-
[30]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Shangyu Li, Juyong Jiang, Tiancheng Zhao, and Jiasi Shen. Osvbench: Benchmarking llms on specification generation tasks for operating system verification.arXiv preprint arXiv:2504.20964, 2025
-
[32]
A sound static analysis approach to i/o api migration.Proceedings of the ACM on Programming Languages, 9(OOPSLA2):584–614, 2025
Shangyu Li, Zhaoyang Zhang, Sizhe Zhong, Diyu Zhou, and Jiasi Shen. A sound static analysis approach to i/o api migration.Proceedings of the ACM on Programming Languages, 9(OOPSLA2):584–614, 2025
2025
-
[33]
Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
2022
-
[34]
In rust we trust: a transpiler from unsafe c to safer rust
Michael Ling, Yijun Yu, Haitao Wu, Yuan Wang, James R Cordy, and Ahmed E Hassan. In rust we trust: a transpiler from unsafe c to safer rust. InProceedings of the ACM/IEEE 44th international conference on software engineering: companion proceedings, pages 354–355, 2022
2022
-
[35]
Alive2: bounded translation validation for llvm
Nuno P Lopes, Juneyoung Lee, Chung-Kil Hur, Zhengyang Liu, and John Regehr. Alive2: bounded translation validation for llvm. InProceedings of the 42nd ACM SIGPLAN Inter- national Conference on Programming Language Design and Implementation, pages 65–79, 2021
2021
-
[36]
Provably correct peephole optimizations with alive
Nuno P Lopes, David Menendez, Santosh Nagarakatte, and John Regehr. Provably correct peephole optimizations with alive. InProceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 22–32, 2015
2015
-
[37]
StarCoder 2 and The Stack v2: The Next Generation
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Noua- mane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. Starcoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173, 2024
work page internal anchor Pith review arXiv 2024
-
[38]
Cogo, and Bram Adams.InterTrans: Leveraging Transitive Intermediate Translations to Enhance LLM-Based Code Translation, page 1153–1164
Marcos Macedo, Yuan Tian, Pengyu Nie, Filipe R. Cogo, and Bram Adams.InterTrans: Leveraging Transitive Intermediate Translations to Enhance LLM-Based Code Translation, page 1153–1164. IEEE Press, 2025
2025
-
[39]
GitHut 2.0: GitHub Language Discovery
madnight. GitHut 2.0: GitHub Language Discovery. https://madnight.github.io/ githut/#/, 2026. Accessed: 2026-1-24
2026
-
[40]
Automated transpilation of imperative to functional code using neural-guided program synthesis.Proceedings of the ACM on Programming Languages, 6(OOPSLA1):1–27, 2022
Benjamin Mariano, Yanju Chen, Yu Feng, Greg Durrett, and I¸ sil Dillig. Automated transpilation of imperative to functional code using neural-guided program synthesis.Proceedings of the ACM on Programming Languages, 6(OOPSLA1):1–27, 2022
2022
-
[41]
The rust language
Nicholas D Matsakis and Felix S Klock. The rust language. InProceedings of the 2014 ACM SIGAda annual conference on High integrity language technology, pages 103–104, 2014
2014
-
[42]
Generic and gimple: A new tree representation for entire functions
Jason Merrill. Generic and gimple: A new tree representation for entire functions. InProceed- ings of the 2003 GCC Summit, pages 171–180, 2003
2003
-
[43]
GitHub Copilot – Your AI pair programmer
Microsoft. GitHub Copilot – Your AI pair programmer. GitHub repository, 2026. 17
2026
-
[44]
Ai-assisted code authoring at scale: Fine-tuning, deploying, and mixed methods evaluation.Proceedings of the ACM on Software Engineering, 1(FSE):1066–1085, 2024
Vijayaraghavan Murali, Chandra Maddila, Imad Ahmad, Michael Bolin, Daniel Cheng, Negar Ghorbani, Renuka Fernandez, Nachiappan Nagappan, and Peter C Rigby. Ai-assisted code authoring at scale: Fine-tuning, deploying, and mixed methods evaluation.Proceedings of the ACM on Software Engineering, 1(FSE):1066–1085, 2024
2024
-
[45]
Hyperkernel: Push-button verification of an os kernel
Luke Nelson, Helgi Sigurbjarnarson, Kaiyuan Zhang, Dylan Johnson, James Bornholt, Emina Torlak, and Xi Wang. Hyperkernel: Push-button verification of an os kernel. InProceedings of the 26th Symposium on Operating Systems Principles, pages 252–269, 2017
2017
-
[46]
Vikram Nitin, Rahul Krishna, Luiz Lemos do Valle, and Baishakhi Ray. C2saferrust: Transform- ing c projects into safer rust with neurosymbolic techniques.arXiv preprint arXiv:2501.14257, 2025
-
[47]
Repository-level code translation benchmark targeting rust.arXiv preprint arXiv:2411.13990, 2024
Guangsheng Ou, Mingwei Liu, Yuxuan Chen, Xin Peng, and Zibin Zheng. Repository-level code translation benchmark targeting rust.arXiv preprint arXiv:2411.13990, 2024
-
[48]
Lost in translation: A study of bugs introduced by large language models while translating code
Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. Lost in translation: A study of bugs introduced by large language models while translating code. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, p...
2024
-
[49]
Towards inclusive source code readability based on the preferences of programmers with visual impairments
Maulishree Pandey, Steve Oney, and Andrew Begel. Towards inclusive source code readability based on the preferences of programmers with visual impairments. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–18, 2024
2024
-
[50]
IRCoder: Intermediate representations make language models robust multilingual code generators
Indraneil Paul, Goran Glavaš, and Iryna Gurevych. IRCoder: Intermediate representations make language models robust multilingual code generators. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 15023–15041, Bangkok, Thailand, A...
2024
-
[51]
arXiv preprint arXiv:2105.12655 (2021)
Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks.arXiv preprint arXiv:2105.12655, 2021
-
[52]
Batfix: Repairing language model-based transpilation.ACM Transactions on Software Engineering and Methodology, 33(6):1–29, 2024
Daniel Ramos, Inês Lynce, Vasco Manquinho, Ruben Martins, and Claire Le Goues. Batfix: Repairing language model-based transpilation.ACM Transactions on Software Engineering and Methodology, 33(6):1–29, 2024
2024
-
[53]
Unsu- pervised translation of programming languages
Baptiste Roziere, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample. Unsu- pervised translation of programming languages. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc
2020
-
[54]
Approximating KL divergence, 2020
John Schulman. Approximating KL divergence, 2020. Accessed: 2025-02-22
2020
-
[55]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Sharpen, January 2026
Sharpen. Sharpen, January 2026
2026
-
[57]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[58]
Pinpoint: Fast and precise sparse value flow analysis for million lines of code
Qingkai Shi, Xiao Xiao, Rongxin Wu, Jinguo Zhou, Gang Fan, and Charles Zhang. Pinpoint: Fast and precise sparse value flow analysis for million lines of code. InProceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 693–706, 2018. 18
2018
-
[59]
arXiv preprint arXiv:2301.13816 , year=
Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K Reddy. Execution-based code generation using deep reinforcement learning.arXiv preprint arXiv:2301.13816, 2023
-
[60]
Migrating from cobol to java
Harry M Sneed. Migrating from cobol to java. In2010 IEEE International Conference on Software Maintenance, pages 1–7. IEEE, 2010
2010
-
[61]
The problem of programming communication with changing machines: a proposed solution.Communications of the ACM, 1(8):12–18, 1958
J Strong, J Wegstein, A Tritter, J Olsztyn, O Mock, and T Steel. The problem of programming communication with changing machines: a proposed solution.Communications of the ACM, 1(8):12–18, 1958
1958
-
[62]
On-demand strong update analysis via value-flow refinement
Yulei Sui and Jingling Xue. On-demand strong update analysis via value-flow refinement. InProceedings of the 2016 24th ACM SIGSOFT international symposium on foundations of software engineering, pages 460–473, 2016
2016
-
[63]
Svf: interprocedural static value-flow analysis in llvm
Yulei Sui and Jingling Xue. Svf: interprocedural static value-flow analysis in llvm. InProceed- ings of the 25th international conference on compiler construction, pages 265–266, 2016
2016
-
[64]
Static memory leak detection using full-sparse value-flow analysis
Yulei Sui, Ding Ye, and Jingling Xue. Static memory leak detection using full-sparse value-flow analysis. InProceedings of the 2012 International Symposium on Software Testing and Analysis, pages 254–264, 2012
2012
-
[65]
Detecting memory leaks statically with full-sparse value-flow analysis.IEEE Transactions on Software Engineering, 40(2):107–122, 2014
Yulei Sui, Ding Ye, and Jingling Xue. Detecting memory leaks statically with full-sparse value-flow analysis.IEEE Transactions on Software Engineering, 40(2):107–122, 2014
2014
-
[66]
Code translation with compiler representations.arXiv preprint arXiv:2207.03578, 2022
Marc Szafraniec, Baptiste Roziere, Hugh Leather, Francois Charton, Patrick Labatut, and Gabriel Synnaeve. Code translation with compiler representations.arXiv preprint arXiv:2207.03578, 2022
-
[67]
Profix: Improving profile-guided optimization in compilers with graph neural networks
Huiri Tan, Juyong Jiang, and Jiasi Shen. Profix: Improving profile-guided optimization in compilers with graph neural networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[68]
Octopus: Scaling value-flow analysis via parallel collection of realizable path conditions.ACM Transactions on Software Engineering and Methodology, 33(3):1–33, 2024
Wensheng Tang, Dejun Dong, Shijie Li, Chengpeng Wang, Peisen Yao, Jinguo Zhou, and Charles Zhang. Octopus: Scaling value-flow analysis via parallel collection of realizable path conditions.ACM Transactions on Software Engineering and Methodology, 33(3):1–33, 2024
2024
-
[69]
Terekhov and Chris Verhoef
Andrey A. Terekhov and Chris Verhoef. The realities of language conversions.IEEE Softw., 17(6):111–124, November 2000
2000
-
[70]
Tiobe, January 2026
TIOBE. Tiobe, January 2026
2026
-
[71]
User- customizable transpilation of scripting languages.Proceedings of the ACM on Programming Languages, 7(OOPSLA1):201–229, 2023
Bo Wang, Aashish Kolluri, Ivica Nikoli ´c, Teodora Baluta, and Prateek Saxena. User- customizable transpilation of scripting languages.Proceedings of the ACM on Programming Languages, 7(OOPSLA1):201–229, 2023
2023
-
[72]
Translating to a low-resource language with compiler feedback: A case study on cangjie.IEEE Transactions on Software Engineering, 2025
Jun Wang, Chenghao Su, Yijie Ou, Yanhui Li, Jialiang Tan, Lin Chen, and Yuming Zhou. Translating to a low-resource language with compiler feedback: A case study on cangjie.IEEE Transactions on Software Engineering, 2025
2025
-
[73]
Ru Wang, Wei Huang, Qi Cao, Yusuke Iwasawa, Yu- taka Matsuo, and Jiaxian Guo
Junqiao Wang, Zeng Zhang, Yangfan He, Zihao Zhang, Xinyuan Song, Yuyang Song, Tianyu Shi, Yuchen Li, Hengyuan Xu, Kunyu Wu, et al. Enhancing code llms with reinforcement learning in code generation: A survey.arXiv preprint arXiv:2412.20367, 2024
-
[74]
Reinforcement-learning-guided source code summarization using hierarchical attention.IEEE Transactions on software Engineering, 48(1):102–119, 2020
Wenhua Wang, Yuqun Zhang, Yulei Sui, Yao Wan, Zhou Zhao, Jian Wu, Philip S Yu, and Guandong Xu. Reinforcement-learning-guided source code summarization using hierarchical attention.IEEE Transactions on software Engineering, 48(1):102–119, 2020
2020
-
[75]
Repotransbench: A real-world multilingual benchmark for repository-level code translation.IEEE Transactions on Software Engineering, 2025
Yanli Wang, Yanlin Wang, Suiquan Wang, Daya Guo, Jiachi Chen, John Grundy, Xilin Liu, Yuchi Ma, Mingzhi Mao, Hongyu Zhang, et al. Repotransbench: A real-world multilingual benchmark for repository-level code translation.IEEE Transactions on Software Engineering, 2025
2025
-
[76]
Effireasontrans: Rl-optimized reasoning for code translation.arXiv preprint arXiv:2510.18863, 2025
Yanlin Wang, Rongyi Ou, Yanli Wang, Mingwei Liu, Jiachi Chen, Ensheng Shi, Xilin Liu, Yuchi Ma, and Zibin Zheng. Effireasontrans: Rl-optimized reasoning for code translation.arXiv preprint arXiv:2510.18863, 2025. 19
-
[77]
arXiv preprint arXiv:2502.18449 , year=
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida I Wang. Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution.arXiv preprint arXiv:2502.18449, 2025
-
[78]
Classeval-t: Evaluating large language models in class-level code translation.Proceedings of the ACM on Software Engineering, 2(ISSTA):1421–1444, 2025
Pengyu Xue, Linhao Wu, Zhen Yang, Chengyi Wang, Xiang Li, Yuxiang Zhang, Jia Li, Ruikai Jin, Yifei Pei, Zhaoyan Shen, et al. Classeval-t: Evaluating large language models in class-level code translation.Proceedings of the ACM on Software Engineering, 2(ISSTA):1421–1444, 2025
2025
-
[79]
Vert: Verified equivalent rust transpilation with large language models as few-shot learners,
Aidan ZH Yang, Yoshiki Takashima, Brandon Paulsen, Josiah Dodds, and Daniel Kroening. Vert: Verified equivalent rust transpilation with large language models as few-shot learners. arXiv preprint arXiv:2404.18852, 2024
-
[80]
Scaling laws for code: Every programming language matters.arXiv preprint arXiv:2512.13472, 2025
Jian Yang, Shawn Guo, Lin Jing, Wei Zhang, Aishan Liu, Chuan Hao, Zhoujun Li, Wayne Xin Zhao, Xianglong Liu, Weifeng Lv, et al. Scaling laws for code: Every programming language matters.arXiv preprint arXiv:2512.13472, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.