Recognition: unknown
HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval
Pith reviewed 2026-05-10 04:47 UTC · model grok-4.3
The pith
HABIT framework uses mutual information transition rates and dual model consistency to robustly retrieve images from noisy composed queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
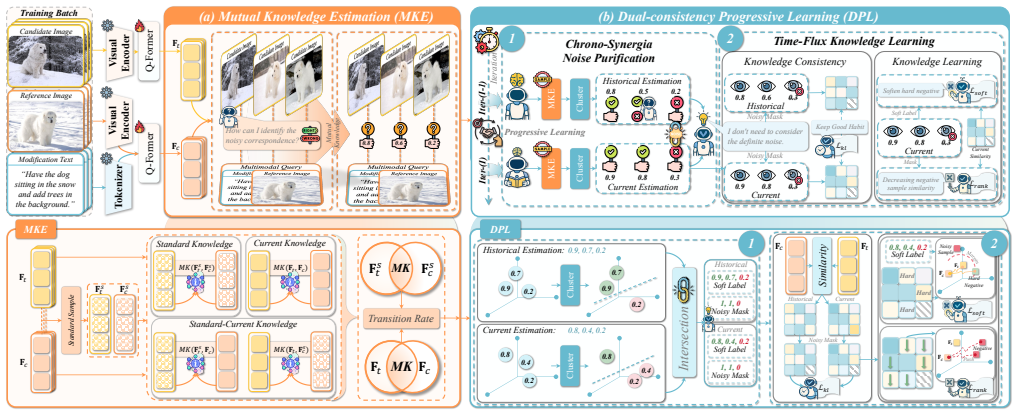
HABIT consists of the Mutual Knowledge Estimation Module, which quantifies sample cleanliness by calculating the Transition Rate of mutual information between the composed feature and the target image to identify samples aligned with intended modification semantics, and the Dual-consistency Progressive Learning Module, which introduces a collaborative mechanism between historical and current models to retain good habits and calibrate bad habits for robust adaptation under the presence of NTC.
What carries the argument
HABIT's Mutual Knowledge Estimation Module, which computes the transition rate of mutual information to score sample cleanliness, together with its Dual-consistency Progressive Learning Module, which simulates habit formation by letting historical and current models jointly retain reliable behaviors and correct unreliable ones.
Load-bearing premise
The transition rate of mutual information accurately estimates how well a sample aligns with the intended modification semantics, and the dual-consistency mechanism between historical and current models reliably enables adaptation to modification discrepancies.
What would settle it
An experiment that injects controlled noise known to break the correlation between mutual information transition rate and true semantic alignment, then checks whether HABIT's performance advantage over baselines disappears.
Figures




read the original abstract
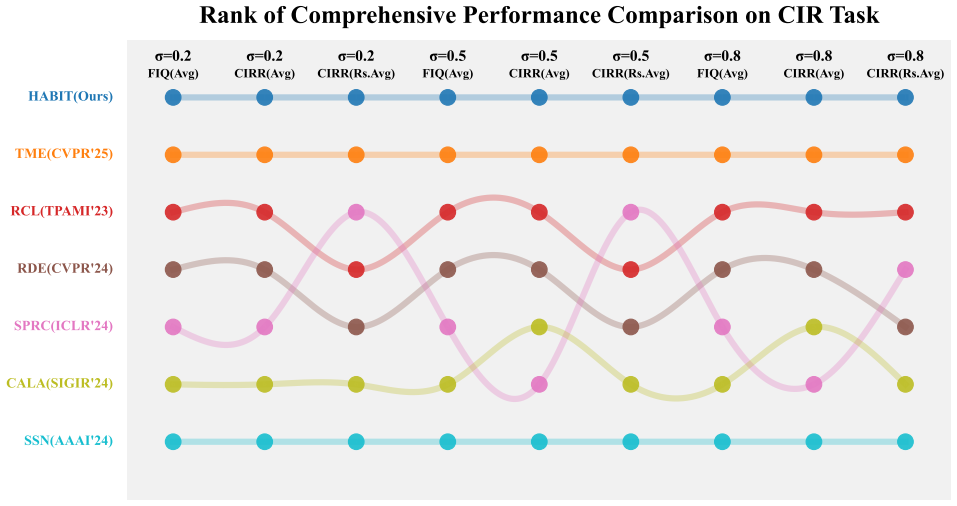
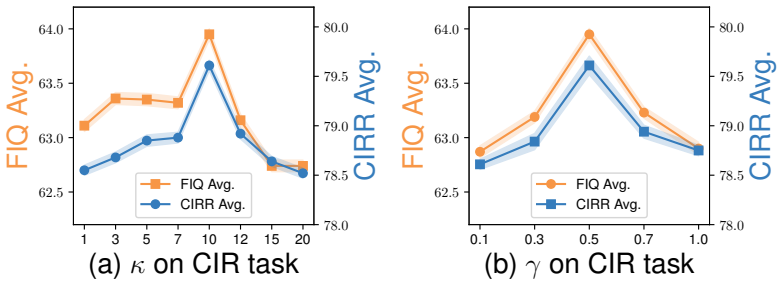
Composed Image Retrieval (CIR) is a flexible image retrieval paradigm that enables users to accurately locate the target image through a multimodal query composed of a reference image and modification text. Although this task has demonstrated promising applications in personalized search and recommendation systems, it encounters a severe challenge in practical scenarios known as the Noise Triplet Correspondence (NTC) problem. This issue primarily arises from the high cost and subjectivity involved in annotating triplet data. To address this problem, we identify two central challenges: the precise estimation of composed semantic discrepancy and the insufficient progressive adaptation to modification discrepancy. To tackle these challenges, we propose a cHrono-synergiA roBust progressIve learning framework for composed image reTrieval (HABIT), which consists of two core modules. First, the Mutual Knowledge Estimation Module quantifies sample cleanliness by calculating the Transition Rate of mutual information between the composed feature and the target image, thereby effectively identifying clean samples that align with the intended modification semantics. Second, the Dual-consistency Progressive Learning Module introduces a collaborative mechanism between the historical and current models, simulating human habit formation to retain good habits and calibrate bad habits, ultimately enabling robust learning under the presence of NTC. Extensive experiments conducted on two standard CIR datasets demonstrate that HABIT significantly outperforms most methods under various noise ratios, exhibiting superior robustness and retrieval performance. Codes are available at https://github.com/Lee-zixu/HABIT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HABIT, a chrono-synergia robust progressive learning framework for Composed Image Retrieval (CIR) under the Noise Triplet Correspondence (NTC) problem. It consists of a Mutual Knowledge Estimation Module that quantifies sample cleanliness via the Transition Rate of mutual information between composed features and target images, and a Dual-consistency Progressive Learning Module that employs collaboration between historical and current models to simulate habit formation for retaining good adaptations and calibrating discrepancies. Experiments on two standard CIR datasets are reported to show that HABIT significantly outperforms most methods across various noise ratios, with claims of superior robustness and retrieval performance.
Significance. If the central empirical claims hold after addressing the validation gaps, the work would offer a practically relevant advance for CIR systems, where NTC arises frequently from costly and subjective triplet annotations. The progressive collaboration mechanism provides a conceptually distinct approach to robust learning, and the public code release aids reproducibility. The result would strengthen noise-robust multimodal retrieval if the mutual-information estimator is shown to isolate modification-aligned samples rather than incidental embedding properties.
major comments (2)
- [Mutual Knowledge Estimation Module] Mutual Knowledge Estimation Module: the claim that the Transition Rate of mutual information precisely estimates sample cleanliness aligned with intended modification semantics lacks supporting evidence such as correlation analysis against held-out clean labels or controls for confounding factors (e.g., image complexity or embedding norm). Without this, the separation of clean versus noisy triplets under NTC remains unverified.
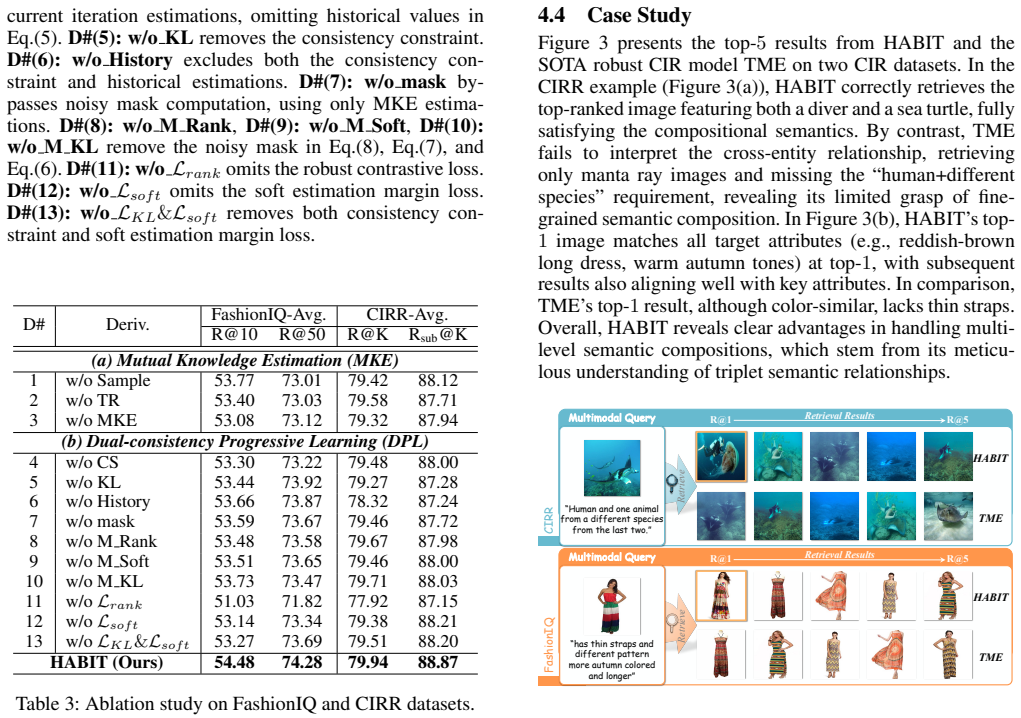
- [Experiments] Experiments: the reported outperformance at high noise ratios is not accompanied by an ablation that isolates the contribution of the Mutual Knowledge Estimation Module from the Dual-consistency Progressive Learning Module. It is therefore unclear whether the gains derive from the mutual-information estimator or from the progressive collaboration alone.
minor comments (2)
- [Abstract] The abstract states the method outperforms 'most methods' but provides no quantitative metrics, dataset names, or baseline list; adding these would improve immediate readability.
- [Method] Notation for the Transition Rate and mutual-information quantities should be defined explicitly with equations in the method section to avoid ambiguity in the estimation procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Mutual Knowledge Estimation Module] Mutual Knowledge Estimation Module: the claim that the Transition Rate of mutual information precisely estimates sample cleanliness aligned with intended modification semantics lacks supporting evidence such as correlation analysis against held-out clean labels or controls for confounding factors (e.g., image complexity or embedding norm). Without this, the separation of clean versus noisy triplets under NTC remains unverified.
Authors: We agree that direct supporting evidence for the Mutual Knowledge Estimation Module would strengthen the manuscript. While the end-to-end results under varying noise ratios provide indirect validation, we will add a dedicated analysis in the revision: correlation coefficients between the estimated transition rates and held-out clean labels on a controlled subset, along with controls for potential confounders such as image complexity (measured via entropy) and embedding norms. This will verify that the module isolates modification-aligned semantics. revision: yes
-
Referee: [Experiments] Experiments: the reported outperformance at high noise ratios is not accompanied by an ablation that isolates the contribution of the Mutual Knowledge Estimation Module from the Dual-consistency Progressive Learning Module. It is therefore unclear whether the gains derive from the mutual-information estimator or from the progressive collaboration alone.
Authors: We acknowledge this gap in the experimental design. The current results demonstrate the full framework's robustness, but to isolate contributions we will include new ablation studies in the revised manuscript. These will compare: (1) a baseline with only Dual-consistency Progressive Learning, (2) the Mutual Knowledge Estimation Module applied to a standard progressive learner, and (3) the full HABIT model. This will clarify the individual and synergistic effects, particularly at high noise ratios. revision: yes
Circularity Check
No significant circularity; framework is empirically defined and externally validated
full rationale
The paper defines two modules to address NTC: Mutual Knowledge Estimation via Transition Rate of mutual information between composed feature and target image, plus Dual-consistency Progressive Learning between historical and current models. These are introduced as novel components without any derivation chain, equations, or self-citations that reduce the claimed robustness or predictions back to fitted inputs or prior self-work by construction. Performance is shown via experiments on standard CIR datasets under varying noise ratios, providing independent empirical content. This matches the reader's assessment of no evident circular reasoning and qualifies as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Transition Rate of mutual information between the composed feature and the target image accurately quantifies sample cleanliness for composed semantic discrepancy.
- ad hoc to paper A collaborative mechanism between historical and current models can simulate human habit formation to retain good habits and calibrate bad habits for robust learning under NTC.
Reference graph
Works this paper leans on
-
[1]
Wen, H.; Song, X.; Yin, J.; Wu, J.; Guan, W.; and Nie, L
-
[2]
Self-Training Boosted Multi-Factor Matching Net- work for Composed Image Retrieval.IEEE TPAMI
-
[3]
Xu, X.; Liu, Y .; Khan, S.; Khan, F.; Zuo, W.; Goh, R. S. M.; Feng, C.-M.; et al. 2024. Sentence-level Prompts Benefit Composed Image Retrieval. InICLR
2024
-
[4]
Chen, Z.; Hu, Y .; Fu, Z.; Li, Z.; Huang, J.; Huang, Q.; and Wei, Y . 2026. INTENT: Invariance and Discrimination- aware Noise Mitigation for Robust Composed Image Re- trieval. InAAAI, volume 40, 20463–20471
2026
-
[5]
Hu, Y .; Li, Z.; Chen, Z.; Huang, Q.; Fu, Z.; Xu, M.; and Nie, L. 2026. REFINE: Composed Video Retrieval via Shared and Differential Semantics Enhancement.ACM ToMM
2026
-
[6]
Li, Z.; Hu, Y .; Chen, Z.; Huang, Q.; Qiu, G.; Fu, Z.; and Liu, M. 2026. ReTrack: Evidence-Driven Dual-Stream Di- rectional Anchor Calibration Network for Composed Video Retrieval. InAAAI, volume 40, 23373–23381
2026
-
[7]
Liu, F.; Cheng, Z.; Zhu, L.; Gao, Z.; and Nie, L. 2021. Interest-aware message-passing GCN for recommendation. InACM WWW, 1296–1305
2021
-
[8]
Yang, X.; Liu, D.; Zhang, H.; Luo, Y .; Wang, C.; and Zhang, J. 2024. Decomposing Semantic Shifts for Composed Image Retrieval. InAAAI, volume 38, 6576–6584
2024
-
[9]
Jiang, X.; Wang, Y .; Li, M.; Wu, Y .; Hu, B.; and Qian, X
-
[10]
InACM SIGIR, 2177– 2187
Cala: Complementary association learning for aug- menting comoposed image retrieval. InACM SIGIR, 2177– 2187
-
[11]
Cheng, Z.; Lai, L.; Liu, Y .; Cheng, K.; and Qi, X. 2026. En- hancing Financial Report Question-Answering: A Retrieval- Augmented Generation System with Reranking Analysis. arXiv preprint arXiv:2603.16877
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Pu, R.; Qin, Y .; Song, X.; Peng, D.; Ren, Z.; and Sun, Y
-
[13]
SHE: Streaming-media Hashing Retrieval. InICML
- [14]
- [15]
-
[16]
Chen, K.; Fang, P.; and Xue, H. 2025. DePro: Domain Ensemble using Decoupled Prompts for Universal Cross- Domain Retrieval. InSIGIR, SIGIR ’25, 958–967
2025
-
[17]
Chen, K.; Fang, P.; and Xue, H. 2025. Multi-Modal Inter- active Agent Layer for Few-Shot Universal Cross-Domain Retrieval and Beyond. InNeurIPS
2025
-
[18]
Wang, Y .; Fu, T.; Xu, Y .; Ma, Z.; Xu, H.; Du, B.; Lu, Y .; Gao, H.; Wu, J.; and Chen, J. 2024. TWIN-GPT: digital twins for clinical trials via large language model.ACM ToMM
2024
- [19]
-
[20]
Jia, S.; Zhu, N.; Zhong, J.; Zhou, J.; Zhang, H.; Hwang, J.- N.; and Li, L. 2026. RAM: Recover Any 3D Human Motion in-the-Wild. arXiv:2603.19929
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Li, L.; Jia, S.; Wang, J.; Jiang, Z.; Zhou, F.; Dai, J.; Zhang, T.; Wu, Z.; and Hwang, J.-N. 2025. Human Motion Instruc- tion Tuning. InCVPR
2025
-
[22]
Li, L.; Jia, S.; and Hwang, J.-N. 2026. Multiple Human Motion Understanding. InAAAI, volume 40, 6297–6305
2026
- [23]
-
[24]
Qiu, X.; Wu, X.; Lin, Y .; Guo, C.; Hu, J.; and Yang, B. 2025. DUET: Dual Clustering Enhanced Multivariate Time Series Forecasting. InSIGKDD, 1185–1196
2025
-
[25]
Zhao, Z. 2024. Balf: Simple and efficient blur aware local feature detector. InWACV, 3362–3372
2024
-
[26]
Zhang, F.; Gu, Z.; and Wang, H. 2026. Decoding with struc- tured awareness: integrating directional, frequency-spatial, and structural attention for medical image segmentation. In AAAI, volume 40, 12421–12429
2026
-
[27]
Liu, J.; Zhuo, D.; Feng, Z.; Zhu, S.; Peng, C.; Liu, Z.; and Wang, H. 2024. Dvlo: Deep visual-lidar odometry with local-to-global feature fusion and bi-directional structure alignment. InECCV, 475–493. Springer
2024
- [28]
-
[29]
Yuan, H.; Li, X.; Dai, J.; You, X.; Sun, Y .; and Ren, Z. 2025. Deep Streaming View Clustering. InICML
2025
-
[30]
Lu, S.; Liu, Y .; and Kong, A. W.-K. 2023. Tf-icon: Diffusion-based training-free cross-domain image compo- sition. InICCV, 2294–2305
2023
-
[31]
Zhou, S.; Cao, Y .; Nie, J.; Fu, Y .; Zhao, Z.; Lu, X.; and Wang, S. 2026. Comptrack: Information bottleneck-guided low-rank dynamic token compression for point cloud track- ing. InAAAI, volume 40, 13773–13781
2026
- [32]
-
[33]
Lan, Y .; Xu, S.; Su, C.; Ye, R.; Peng, D.; and Sun, Y . 2025. Multi-view Hashing Classification. InACM MM, 2122– 2130
2025
-
[34]
Yu, Z.; IDRIS, M. Y . I.; Wang, P.; and Qureshi, R. 2025. CoTextor: Training-Free Modular Multilingual Text Editing via Layered Disentanglement and Depth-Aware Fusion. In NeurIPS
2025
-
[35]
Liao, B.; Zhao, Z.; Li, H.; Zhou, Y .; Zeng, Y .; Li, H.; and Liu, P. 2025. Convex Relaxation for Robust Vanishing Point Estimation in Manhattan World. InCVPR, 15823–15832
2025
-
[36]
S.; Sheng, Z.; and Yang, B
Qiu, X.; Hu, J.; Zhou, L.; Wu, X.; Du, J.; Zhang, B.; Guo, C.; Zhou, A.; Jensen, C. S.; Sheng, Z.; and Yang, B. 2024. TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods. InVLDB, 2363–2377
2024
- [37]
-
[38]
Duan, S.; Wu, W.; Hu, P.; Ren, Z.; Peng, D.; and Sun, Y
-
[39]
CoPINN: Cognitive physics-informed neural net- works. InICML
-
[40]
Zhou, S.; Nie, J.; Zhao, Z.; Cao, Y .; and Lu, X. 2025. Focus- track: One-stage focus-and-suppress framework for 3d point cloud object tracking. InACM MM, 7366–7375
2025
-
[41]
Xie, Z.; Wang, C.; Wang, Y .; Cai, S.; Wang, S.; and Jin, T
-
[42]
InEMNLP, 5259–5270
Chat-driven text generation and interaction for person retrieval. InEMNLP, 5259–5270
-
[43]
Liu, P. 2024. Unsupervised corrupt data detection for text training.ESWA, 248: 123335
2024
- [44]
-
[45]
Gu, R.; Jia, S.; Ma, Y .; Zhong, J.; Hwang, J.-N.; and Li, L
-
[46]
InACM MM, 9026–9034
MoCount: Motion-Based Repetitive Action Counting. InACM MM, 9026–9034
- [47]
- [48]
- [49]
-
[50]
Liu, P.; Yang, J.; Wang, L.; Wang, S.; Hao, Y .; and Bai, H
-
[51]
InCIKM, 4099–4104
Retrieval-Based Unsupervised Noisy Label Detection on Text Data. InCIKM, 4099–4104
- [52]
-
[53]
Yang, Q.; Lv, P.; Li, Y .; Zhang, S.; Chen, Y .; Chen, Z.; Li, Z.; and Hu, Y . 2026. ERASE: Bypassing Collaborative Detec- tion of AI Counterfeit Via Comprehensive Artifacts Elimi- nation.IEEE TDSC, 1–18
2026
-
[54]
T.; Peng, X.; and Hu, P
Li, S.; He, C.; Liu, X.; Zhou, J. T.; Peng, X.; and Hu, P. 2025. Learning with Noisy Triplet Correspondence for Composed Image Retrieval. InCVPR, 19628–19637
2025
-
[55]
Liu, M.; Wang, X.; Nie, L.; He, X.; Chen, B.; and Chua, T.-S. 2018. Attentive moment retrieval in videos. InACM SIGIR, 15–24
2018
-
[56]
Hu, Y .; Liu, M.; Su, X.; Gao, Z.; and Nie, L. 2021. Video moment localization via deep cross-modal hashing.IEEE TIP, 30: 4667–4677
2021
-
[57]
Liu, M.; Wang, X.; Nie, L.; Tian, Q.; Chen, B.; and Chua, T.-S. 2018. Cross-modal moment localization in videos. In ACM MM, 843–851
2018
-
[58]
Hu, Y .; Wang, K.; Liu, M.; Tang, H.; and Nie, L. 2023. Se- mantic collaborative learning for cross-modal moment lo- calization.ACM TOIS, 42(2): 1–26
2023
-
[59]
Liu, F.; Liu, Y .; Chen, H.; Cheng, Z.; Nie, L.; and Kankan- halli, M. 2025. Understanding Before Recommendation: Se- mantic Aspect-Aware Review Exploitation via Large Lan- guage Models.ACM TOIS, 43(2)
2025
-
[60]
Liu, P.; Wang, X.; Cui, Z.; and Ye, W. 2025. Queries Are Not Alone: Clustering Text Embeddings for Video Search. InSIGIR, 874–883
2025
-
[61]
Wen, H.; Zhang, X.; Song, X.; Wei, Y .; and Nie, L. 2023. Target-guided composed image retrieval. InACM MM, 915– 923
2023
-
[62]
Li, Z.; Chen, Z.; Wen, H.; Fu, Z.; Hu, Y .; and Guan, W
-
[63]
ENCODER: Entity Mining and Modification Relation Binding for Composed Image Retrieval. InAAAI
-
[64]
Chen, Z.; Hu, Y .; Li, Z.; Fu, Z.; Wen, H.; and Guan, W
-
[65]
InACM MM, 6143–6152
HUD: Hierarchical Uncertainty-Aware Disambigua- tion Network for Composed Video Retrieval. InACM MM, 6143–6152. ACM
-
[66]
Chen, Z.; Hu, Y .; Li, Z.; Fu, Z.; Song, X.; and Nie, L
-
[67]
InACM MM, 6113–6122
OFFSET: Segmentation-based Focus Shift Revision for Composed Image Retrieval. InACM MM, 6113–6122. ACM
-
[68]
Mu, C.; Yang, E.; and Deng, C. 2025. Meta-Guided Adap- tive Weight Learner for Noisy Correspondence. InACM SIGIR, 968–978
2025
-
[69]
Zha, Q.; Liu, X.; Cheung, Y .-m.; Peng, S.-J.; Xu, X.; and Wang, N. 2025. UCPM: Uncertainty-Guided Cross-Modal Retrieval with Partially Mismatched Pairs.IEEE TIP
2025
-
[70]
Wu, H.; Gao, Y .; Guo, X.; Al-Halah, Z.; Rennie, S.; Grau- man, K.; and Feris, R. 2021. Fashion iq: A new dataset to- wards retrieving images by natural language feedback. In CVPR, 11307–11317
2021
-
[71]
Guo, X.; Wu, H.; Cheng, Y .; Rennie, S.; Tesauro, G.; and Feris, R. S. 2018. Dialog-based Interactive Image Retrieval. InNeurIPS, 676–686. MIT Press
2018
-
[72]
P.; Yu, J.; and Yang, W
Song, Z.; Luo, R.; Ma, L.; Tang, Y .; Chen, Y .-P. P.; Yu, J.; and Yang, W. 2025. Temporal Coherent Object Flow for Multi-Object Tracking. InAAAI, volume 39, 6978–6986
2025
-
[73]
Zhou, S.; Yuan, Z.; Yang, D.; Hu, X.; Qian, J.; and Zhao, Z
-
[74]
InCVPR, 27336–27345
Pillarhist: A quantization-aware pillar feature encoder based on height-aware histogram. InCVPR, 27336–27345
-
[75]
Liu, J.; Wang, G.; Ye, W.; Jiang, C.; Han, J.; Liu, Z.; Zhang, G.; Du, D.; and Wang, H. 2024. DifFlow3D: Toward Ro- bust Uncertainty-Aware Scene Flow Estimation with Itera- tive Diffusion-Based Refinement. InCVPR, 15109–15119
2024
-
[76]
Liu, J.; Ye, W.; Wang, G.; Jiang, C.; Pan, L.; Han, J.; Liu, Z.; Zhang, G.; and Wang, H. 2025. DifFlow3D: Hierarchi- cal Diffusion Models for Uncertainty-Aware 3D Scene Flow Estimation.IEEE TPAMI
2025
-
[77]
Jiang, K.; Dong, H.; Kang, Z.; Zhu, Z.; and Song, G. 2026. FoE: Forest of Errors Makes the First Solution the Best in Large Reasoning Models. arXiv:2604.02967
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [78]
-
[79]
P.; and Yang, W
Song, Z.; Luo, R.; Yu, J.; Chen, Y .-P. P.; and Yang, W. 2023. Compact transformer tracker with correlative masked mod- eling. InAAAI, volume 37, 2321–2329
2023
-
[80]
Yu, Z.; Idris, M. Y . I.; and Wang, P. 2025. Visualizing Our Changing Earth: A Creative AI Framework for Democratiz- ing Environmental Storytelling Through Satellite Imagery. InNeurIPS
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.