Recognition: 2 theorem links
· Lean TheoremRAM: Recover Any 3D Human Motion in-the-Wild
Pith reviewed 2026-05-15 08:41 UTC · model grok-4.3
The pith
RAM recovers accurate 3D human motions from unconstrained multi-person videos by combining semantic tracking with memory-based reconstruction and prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
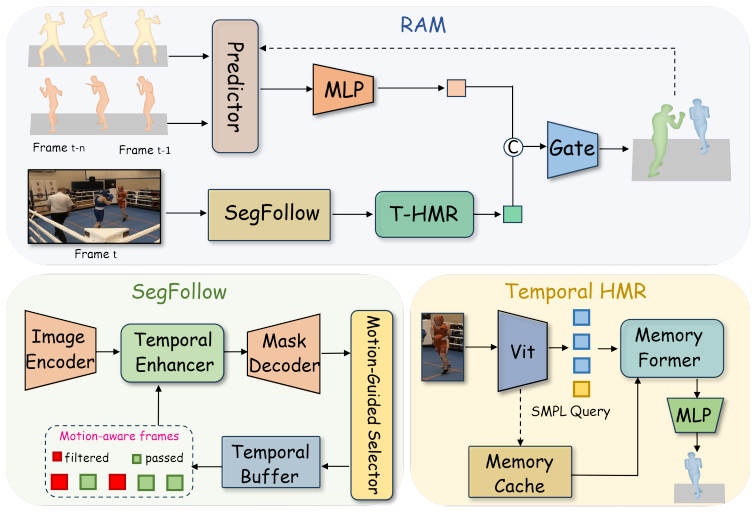
RAM achieves robust identity association under severe occlusions and dynamic interactions through a motion-aware semantic tracker with adaptive Kalman filtering. It enhances motion reconstruction with a memory-augmented Temporal HMR module that injects spatio-temporal priors for consistent and smooth estimation. A lightweight Predictor forecasts future poses to maintain continuity, while a gated combiner adaptively fuses reconstructed and predicted features. Together these components produce substantially better zero-shot tracking stability and 3D accuracy on in-the-wild multi-person benchmarks such as PoseTrack and 3DPW.
What carries the argument
The RAM pipeline, which links a motion-aware semantic tracker, a memory-augmented Temporal HMR module, a lightweight future-pose Predictor, and a gated feature combiner.
Load-bearing premise
The assumption that the four separate modules integrate without conflicts or loss of performance to produce the claimed robustness and coherence.
What would settle it
A direct comparison on PoseTrack or 3DPW in which RAM shows no improvement, or shows worse tracking stability or 3D accuracy, than the best previous method would falsify the central claim.
Figures


read the original abstract
RAM incorporates a motion-aware semantic tracker with adaptive Kalman filtering to achieve robust identity association under severe occlusions and dynamic interactions. A memory-augmented Temporal HMR module further enhances human motion reconstruction by injecting spatio-temporal priors for consistent and smooth motion estimation. Moreover, a lightweight Predictor module forecasts future poses to maintain reconstruction continuity, while a gated combiner adaptively fuses reconstructed and predicted features to ensure coherence and robustness. Experiments on in-the-wild multi-person benchmarks such as PoseTrack and 3DPW, demonstrate that RAM substantially outperforms previous state-of-the-art in both Zero-shot tracking stability and 3D accuracy, offering a generalizable paradigm for markerless 3D human motion capture in-the-wild.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RAM, a pipeline for in-the-wild 3D human motion recovery that combines a motion-aware semantic tracker with adaptive Kalman filtering for identity association under occlusion, a memory-augmented Temporal HMR module that injects spatio-temporal priors, a lightweight Predictor for future-pose forecasting, and a gated combiner that fuses reconstructed and predicted features. Experiments on PoseTrack and 3DPW are reported to show substantial gains over prior state-of-the-art in zero-shot tracking stability and 3D accuracy.
Significance. If the quantitative claims are substantiated, the work supplies a practical, modular architecture for markerless multi-person 3D capture that directly targets the failure modes of existing HMR and tracking pipelines. The explicit separation of tracking, memory-augmented reconstruction, prediction, and adaptive fusion offers a reusable template that could be adopted or extended by the community.
major comments (2)
- [Abstract] Abstract: the central claim that RAM 'substantially outperforms previous state-of-the-art' on PoseTrack and 3DPW is stated without any numerical results, error bars, ablation tables, or baseline numbers. This absence makes it impossible to assess the magnitude or statistical reliability of the reported gains.
- [Experiments] The manuscript provides no ablation or failure-case analysis demonstrating that the four modules (semantic tracker, memory-augmented Temporal HMR, Predictor, gated combiner) remain effective when combined; the integration claim therefore rests on an untested assumption.
minor comments (1)
- Notation for the gated combiner and the memory-augmented HMR is introduced without an accompanying equation or diagram, making the fusion mechanism difficult to reproduce from the text alone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to strengthen the presentation of results and validation of the proposed modules.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that RAM 'substantially outperforms previous state-of-the-art' on PoseTrack and 3DPW is stated without any numerical results, error bars, ablation tables, or baseline numbers. This absence makes it impossible to assess the magnitude or statistical reliability of the reported gains.
Authors: We agree that the abstract would be more informative with explicit quantitative support. In the revised manuscript we will add the key performance deltas (e.g., tracking MOTA and 3D MPJPE improvements on both PoseTrack and 3DPW) together with references to the corresponding tables and any reported standard deviations or error bars from the experimental section. revision: yes
-
Referee: [Experiments] The manuscript provides no ablation or failure-case analysis demonstrating that the four modules (semantic tracker, memory-augmented Temporal HMR, Predictor, gated combiner) remain effective when combined; the integration claim therefore rests on an untested assumption.
Authors: We acknowledge the absence of explicit ablations and failure-case studies. While the current experiments demonstrate end-to-end gains, we will add a dedicated ablation subsection that isolates the contribution of each module and their pairwise combinations, as well as a short qualitative analysis of representative failure cases under heavy occlusion and fast motion. These additions will be included in the revised version. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a modular pipeline (semantic tracker with adaptive Kalman filtering, memory-augmented Temporal HMR, lightweight Predictor, and gated combiner) whose integration is presented as delivering improved zero-shot tracking stability and 3D accuracy on external benchmarks PoseTrack and 3DPW. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce any central claim to its own inputs by construction. The argument remains self-contained against external data and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing Temporal HMR and Kalman-filter tracking methods provide reliable base performance that can be extended by memory and prediction modules.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RAM incorporates a motion-aware semantic tracker with adaptive Kalman filtering... memory-augmented Temporal HMR module... lightweight Predictor module... gated combiner
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on PoseTrack and 3DPW... zero-shot tracking stability and 3D accuracy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
MUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality
MUSE decouples reconstruction and semantic learning in visual tokenization via topological orthogonality, yielding SOTA generation quality and improved semantic performance over its teacher model.
-
INTENT: Invariance and Discrimination-aware Noise Mitigation for Robust Composed Image Retrieval
INTENT mitigates cross-modal correspondence noise and modality-inherent noise in composed image retrieval via FFT-based visual invariant composition and bi-objective discriminative learning.
-
HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval
HABIT improves robustness in composed image retrieval under noisy triplets by quantifying sample cleanliness via mutual information transition rates and applying dual-consistency progressive learning to retain good pa...
-
ReTrack: Evidence-Driven Dual-Stream Directional Anchor Calibration Network for Composed Video Retrieval
ReTrack calibrates directional bias in composed video features using semantic disentanglement and bidirectional evidence alignment to improve retrieval performance on CVR and CIR tasks.
-
Grounding Multi-Hop Reasoning in Structural Causal Models via Group Relative Policy Optimization
SCM-GRPO grounds multi-hop fact verification in structural causal models and applies GRPO reinforcement learning to optimize reasoning chain length, outperforming baselines on HoVer and EX-FEVER.
-
Grounding Multi-Hop Reasoning in Structural Causal Models via Group Relative Policy Optimization
The SCM-GRPO framework models multi-hop fact verification as causal inference and applies reinforcement learning to optimize reasoning depth, reporting outperformance on HoVer and EX-FEVER.
Reference graph
Works this paper leans on
-
[1]
Posetrack: A benchmark for human pose estima- tion and tracking
Mykhaylo Andriluka, Umar Iqbal, Eldar Insafutdinov, Leonid Pishchulin, Anton Milan, Juergen Gall, and Bernt Schiele. Posetrack: A benchmark for human pose estima- tion and tracking. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5167–5176, 2018
work page 2018
-
[2]
Tracking without bells and whistles
Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. InProceedings of the IEEE/CVF international conference on computer vision, pages 941–951, 2019
work page 2019
-
[3]
Simple online and realtime tracking
Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE international conference on image processing (ICIP), pages 3464–3468. Ieee, 2016
work page 2016
-
[4]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. InEuropean conference on computer vision, pages 561–578. Springer, 2016
work page 2016
-
[5]
Deep representation learning for human motion prediction and classification
Judith Butepage, Michael J Black, Danica Kragic, and Hed- vig Kjellstrom. Deep representation learning for human motion prediction and classification. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 6158–6166, 2017
work page 2017
-
[6]
Bayesian optimization for controlled image editing via llms
Chengkun Cai, Haoliang Liu, Xu Zhao, Zhongyu Jiang, Tianfang Zhang, Zongkai Wu, John Lee, Jenq-Neng Hwang, and Lei Li. Bayesian optimization for controlled image editing via llms. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[7]
The role of deductive and inductive reasoning in large language models
Chengkun Cai, Xu Zhao, Haoliang Liu, Zhongyu Jiang, Tianfang Zhang, Zongkai Wu, Jenq-Neng Hwang, and Lei Li. The role of deductive and inductive reasoning in large language models. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[8]
Pretraining on the test set is no longer all you need: A debate-driven approach to QA benchmarks
Linbo Cao and Jinman Zhao. Pretraining on the test set is no longer all you need: A debate-driven approach to QA benchmarks. InSecond Conference on Language Modeling, 2025
work page 2025
-
[9]
Deft: Detection embeddings for tracking
Mohamed Chaabane, Peter Zhang, J Ross Beveridge, and Stephen O’Hara. Deft: Detection embeddings for tracking. arXiv preprint arXiv:2102.02267, 2021
-
[10]
Yisong Chen, Yifan Gao, Sijing Yu, Chuqing Zhao, and Yang Lu. Large language models in mental health: A sys- tematic review of applications, innovations, and ethical chal- lenges.Journal of Industrial Integration and Management, 2025
work page 2025
-
[11]
Graph and temporal convolutional networks for 3d multi-person pose estimation in monocular videos
Yu Cheng, Bo Wang, Bo Yang, and Robby T Tan. Graph and temporal convolutional networks for 3d multi-person pose estimation in monocular videos. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1157– 1165, 2021
work page 2021
-
[12]
Mixformer: End-to-end tracking with iterative mixed atten- tion
Yutao Cui, Cheng Jiang, Limin Wang, and Gangshan Wu. Mixformer: End-to-end tracking with iterative mixed atten- tion. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 13608–13618, 2022
work page 2022
-
[13]
Tapir: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10061– 10072, 2023
work page 2023
-
[14]
Panocontext-former: Panoramic total scene un- derstanding with a transformer
Yuan Dong, Chuan Fang, Liefeng Bo, Zilong Dong, and Ping Tan. Panocontext-former: Panoramic total scene un- derstanding with a transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28087–28097, 2024
work page 2024
-
[15]
Bo Du, Xuekang Zhu, Xiaochen Ma, Chenfan Qu, Kai- wen Feng, Zhe Yang, Chi-Man Pun, Jian Liu, and Ji-Zhe Zhou. Forensichub: A unified benchmark & codebase for all-domain fake image detection and localization.arXiv preprint arXiv:2505.11003, 2025
-
[16]
Songcheng Du, Yang Zou, Jiaxin Li, Mingxuan Liu, Ying Li, Changjing Shang, and Qiang Shen. Pansharpening for thin-cloud contaminated remote sensing images: a unified framework and benchmark dataset. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3696– 3704, 2026
work page 2026
-
[17]
Songcheng Du, Yang Zou, Zixu Wang, Xingyuan Li, Ying Li, Changjing Shang, and Qiang Shen. Unsupervised hyper- spectral image super-resolution via self-supervised modality decoupling.International Journal of Computer Vision, 134: 152, 2026
work page 2026
-
[18]
Humans in 4d: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023
work page 2023
-
[19]
Flex: extrinsic parameters-free multi-view 3d human motion reconstruction
Brian Gordon, Sigal Raab, Guy Azov, Raja Giryes, and Daniel Cohen-Or. Flex: extrinsic parameters-free multi-view 3d human motion reconstruction. InEuropean Conference on Computer Vision, pages 176–196. Springer, 2022
work page 2022
-
[20]
Mocount: Motion-based repetitive ac- tion counting
Ruocheng Gu, Sen Jia, Yule Ma, Jinqin Zhong, Jenq-Neng Hwang, and Lei Li. Mocount: Motion-based repetitive ac- tion counting. InProceedings of the 33rd ACM International Conference on Multimedia, pages 9026–9034, 2025
work page 2025
-
[21]
Yunchuan Guan, Yu Liu, Ke Zhou, Zhiqi Shen, Serge Be- longie, Jenq-Neng Hwang, and Lei Li. Learning to learn weight generation via local consistency diffusion.arXiv preprint arXiv:2502.01117, 2025. Accepted to CVPR 2026
-
[22]
Xin Han et al. A survey of weight space learning: Under- standing, representation, and generation.arXiv preprint arXiv:2603.10090, 2026. Comprehensive survey covering Mc-Di-like methods
-
[23]
Markus Hiller, Krista A Ehinger, and Tom Drummond. Per- ceiving longer sequences with bi-directional cross-attention transformers.Advances in Neural Information Processing Systems, 37:94097–94129, 2024
work page 2024
-
[24]
Self-supervised 3d mesh reconstruction from single images
Tao Hu, Liwei Wang, Xiaogang Xu, Shu Liu, and Jiaya Jia. Self-supervised 3d mesh reconstruction from single images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6002–6011, 2021
work page 2021
-
[25]
Yuelyu Ji, Wuwei Lan, and Patrick NG. Mrag-suite: A di- agnostic evaluation platform for visual retrieval-augmented generation.arXiv preprint arXiv:2509.24253, 2025
-
[26]
Yuelyu Ji, Zhuochun Li, Rui Meng, and Daqing He. Reason- to-rank: Distilling direct and comparative reasoning from large language models for document reranking. InProceed- ings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, page 2320–2329, New York, NY , USA, 2025. Association for Computing Machinery
work page 2025
-
[27]
Sadhu, Zhuochun Li, Xizhi Wu, Shyam Visweswaran, and Yanshan Wang
Yuelyu Ji, Wenhe Ma, Sonish Sivarajkumar, Hang Zhang, Eugene M. Sadhu, Zhuochun Li, Xizhi Wu, Shyam Visweswaran, and Yanshan Wang. Mitigating the risk of health inequity exacerbated by large language models.npj Digital Medicine, 8(1):246, 2025
work page 2025
-
[28]
Yuelyu Ji, Zhuochun Li, Rui Meng, and Daqing He. Retrieval–reasoning processes for multi-hop question an- swering: A four-axis design framework and empirical trends. arXiv preprint arXiv:2601.00536, 2026
-
[29]
Adaptive masking enhances visual grounding.arXiv preprint arXiv:2410.03161, 2024
Sen Jia and Lei Li. Adaptive masking enhances visual grounding.arXiv preprint arXiv:2410.03161, 2024
-
[30]
Multiply: Reconstruction of multiple people from monocular video in the wild
Zeren Jiang, Chen Guo, Manuel Kaufmann, Tianjian Jiang, Julien Valentin, Otmar Hilliges, and Jie Song. Multiply: Reconstruction of multiple people from monocular video in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 109–118, 2024
work page 2024
-
[31]
Back to optimization: Diffusion-based zero-shot 3d human pose estimation
Zhongyu Jiang, Zhuoran Zhou, Lei Li, Wenhao Chai, Cheng- Yen Yang, and Jenq-Neng Hwang. Back to optimization: Diffusion-based zero-shot 3d human pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision (WACV), 2024
work page 2024
-
[32]
Unihpr: Unified human pose representation via singular value contrastive learning
Zhongyu Jiang, Wenhao Chai, Lei Li, Zhuoran Zhou, Cheng- Yen Yang, and Jenq-Neng Hwang. Unihpr: Unified human pose representation via singular value contrastive learning. arXiv preprint arXiv:2510.19078, 2025
-
[33]
A new approach to linear filtering and prediction problems
Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. 1960
work page 1960
-
[34]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7122–7131, 2018
work page 2018
-
[35]
Lp-detr: Layer-wise progressive relation for object detection
Zhengjian Kang, Ye Zhang, Xiaoyu Deng, Xintao Li, and Yongzhe Zhang. Lp-detr: Layer-wise progressive relation for object detection. InInternational Conference on Intelligent Computing, pages 144–156. Springer, 2025
work page 2025
-
[36]
Multi- person physics-based pose estimation for combat sports
Hossein Feizollah Zadeh Khoiee, David Labbe, Thomas Romeas, Jocelyn Faubert, and Sheldon Andrews. Multi- person physics-based pose estimation for combat sports. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5832–5841, 2025
work page 2025
-
[37]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 4015–4026, 2023
work page 2023
-
[38]
Pare: Part attention regressor for 3d human body estimation
Muhammed Kocabas, Chun-Hao P Huang, Otmar Hilliges, and Michael J Black. Pare: Part attention regressor for 3d human body estimation. InProceedings of the IEEE/CVF international conference on computer vision, pages 11127– 11137, 2021
work page 2021
-
[39]
Learning to reconstruct 3d human pose and shape via model-fitting in the loop
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. InProceedings of the IEEE/CVF international conference on computer vision, pages 2252–2261, 2019
work page 2019
-
[40]
Harold W Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97, 1955
work page 1955
-
[41]
Mocap everyone everywhere: Lightweight motion capture with smartwatches and a head- mounted camera
Jiye Lee and Hanbyul Joo. Mocap everyone everywhere: Lightweight motion capture with smartwatches and a head- mounted camera. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 1091–1100, 2024
work page 2024
-
[42]
Hao Li, Ju Dai, Xin Zhao, Feng Zhou, Junjun Pan, and Lei Li. Wav2sem: Plug-and-play audio semantic decou- pling for 3d speech-driven facial animation.arXiv preprint arXiv:2505.23290, 2025
-
[43]
Hao Li, Ju Dai, Feng Zhou, Kaida Ning, Lei Li, and Junjun Pan. Au-blendshape for fine-grained stylized 3d facial ex- pression manipulation.arXiv preprint arXiv:2507.12001, 2025
-
[44]
Lei Li, Tianfang Zhang, Zhongfeng Kang, and Xikun Jiang. Mask-fpan: Semi-supervised face parsing in the wild with de-occlusion and uv gan.arXiv preprint arXiv:2212.09098, 2022
-
[45]
Chatmotion: A multimodal multi-agent for human motion analysis.arXiv preprint arXiv:2502.18180, 2025
Lei Li, Sen Jia, Jianhao Wang, Zhaochong An, Jiaang Li, Jenq-Neng Hwang, and Serge Belongie. Chatmotion: A multimodal multi-agent for human motion analysis.arXiv preprint arXiv:2502.18180, 2025
-
[46]
Human Motion Instruction Tuning
Lei Li, Sen Jia, Jianhao Wang, Zhongyu Jiang, Feng Zhou, Ju Dai, Tianfang Zhang, Zongkai Wu, and Jenq-Neng Hwang. Human Motion Instruction Tuning. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[47]
Multiple human mo- tion understanding
Lei Li, Sen Jia, and Jenq-Neng Hwang. Multiple human mo- tion understanding. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6297–6305, 2026
work page 2026
-
[48]
Time3d: End-to-end joint monocu- lar 3d object detection and tracking for autonomous driving
Peixuan Li and Jieyu Jin. Time3d: End-to-end joint monocu- lar 3d object detection and tracking for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3885–3894, 2022
work page 2022
-
[49]
Yuqi Li, Kai Li, Xin Yin, Zhifei Yang, Junhao Dong, Zeyu Dong, Chuanguang Yang, Yingli Tian, and Yao Lu. Sep- prune: Structured pruning for efficient deep speech separa- tion.arXiv preprint arXiv:2505.12079, 2025
-
[50]
Frequency-aligned knowledge distillation for lightweight spatiotemporal forecasting
Yuqi Li, Chuanguang Yang, Hansheng Zeng, Zeyu Dong, Zhulin An, Yongjun Xu, Yingli Tian, and Hao Wu. Frequency-aligned knowledge distillation for lightweight spatiotemporal forecasting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7262– 7272, 2025
work page 2025
-
[51]
A comprehensive survey of interaction techniques in 3d scene generation.Authorea Preprints, 2026
Yuqi Li, Siwei Meng, Chuanguang Yang, Weilun Feng, Jun- ming Liu, Zhulin An, Yikai Wang, and Yingli Tian. A comprehensive survey of interaction techniques in 3d scene generation.Authorea Preprints, 2026
work page 2026
-
[52]
Cliff: Carrying location information in full frames into human pose and shape estimation
Zhihao Li, Jianzhuang Liu, Zhensong Zhang, Songcen Xu, and Youliang Yan. Cliff: Carrying location information in full frames into human pose and shape estimation. In European Conference on Computer Vision, pages 590–606. Springer, 2022
work page 2022
-
[53]
Jiacheng Liang, Yuhui Wang, Changjiang Li, Rongyi Zhu, Tanqiu Jiang, Neil Gong, and Ting Wang. Graphrag under fire, 2025
work page 2025
-
[54]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[55]
Discovering what you can control: Interventional boundary discovery for reinforcement learning, 2026
Jiaxin Liu. Discovering what you can control: Interventional boundary discovery for reinforcement learning, 2026
work page 2026
-
[56]
Jiaxin Liu and Zhaolu Kang. Reasonact: Progressive training for fine-grained video reasoning in small models.Proceed- ings of the AAAI Conference on Artificial Intelligence, 40 (9):7188–7196, 2026
work page 2026
-
[57]
Graph canvas for controllable 3d scene generation.arXiv preprint arXiv:2412.00091, 2024
Libin Liu, Shen Chen, Sen Jia, Jingzhe Shi, Zhongyu Jiang, Can Jin, Wu Zongkai, Jenq-Neng Hwang, and Lei Li. Graph canvas for controllable 3d scene generation.arXiv preprint arXiv:2412.00091, 2024
-
[58]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
work page 2023
-
[59]
Towards generalizable and interpretable motion predic- tion: A deep variational bayes approach
Juanwu Lu, Wei Zhan, Masayoshi Tomizuka, and Yeping Hu. Towards generalizable and interpretable motion predic- tion: A deep variational bayes approach. InInternational Conference on Artificial Intelligence and Statistics, pages 4717–4725. PMLR, 2024
work page 2024
-
[60]
Diffmot: A real-time diffusion-based multiple object tracker with non-linear prediction
Weiyi Lv, Yuhang Huang, Ning Zhang, Ruei-Sung Lin, Mei Han, and Dan Zeng. Diffmot: A real-time diffusion-based multiple object tracker with non-linear prediction. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19321–19330, 2024
work page 2024
-
[61]
Hongxu Ma, Guanshuo Wang, Fufu Yu, Qiong Jia, and Shouhong Ding. MS-DETR: Towards effective video mo- ment retrieval and highlight detection by joint motion- semantic learning. InProceedings of the 33rd ACM In- ternational Conference on Multimedia (ACM MM), pages 4514–4523, 2025. Oral Presentation
work page 2025
-
[62]
Fine-grained zero-shot ob- ject detection
Hongxu Ma, Chenbo Zhang, Lu Zhang, Jiaogen Zhou, Ji- hong Guan, and Shuigeng Zhou. Fine-grained zero-shot ob- ject detection. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM), pages 4504–4513,
-
[63]
GoR: A unified and extensible generative framework for ordinal regression
Hongxu Ma, Han Zhou, Kai Tian, Xuefeng Zhang, Chunjie Chen, Han Li, Jihong Guan, and Shuigeng Zhou. GoR: A unified and extensible generative framework for ordinal regression. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026. ICLR 2026
work page 2026
-
[64]
Xiaochen Ma, Xuekang Zhu, Lei Su, Bo Du, Zhuohang Jiang, Bingkui Tong, Zeyu Lei, Xinyu Yang, Chi-Man Pun, Jiancheng Lv, et al. Imdl-benco: A comprehensive bench- mark and codebase for image manipulation detection & localization.Advances in Neural Information Processing Systems, 37:134591–134613, 2025
work page 2025
-
[65]
3d human pose estimation from a single image via distance matrix regression
Francesc Moreno-Noguer. 3d human pose estimation from a single image via distance matrix regression. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2823–2832, 2017
work page 2017
-
[66]
Comotion: Concurrent multi- person 3d motion.arXiv preprint arXiv:2504.12186, 2025
Alejandro Newell, Peiyun Hu, Lahav Lipson, Stephan R Richter, and Vladlen Koltun. Comotion: Concurrent multi- person 3d motion.arXiv preprint arXiv:2504.12186, 2025
-
[67]
Towards robust and smooth 3d multi-person pose estimation from monocular videos in the wild
Sungchan Park, Eunyi You, Inhoe Lee, and Joonseok Lee. Towards robust and smooth 3d multi-person pose estimation from monocular videos in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14772–14782, 2023
work page 2023
-
[68]
Motiontrack: Learning robust short- term and long-term motions for multi-object tracking
Zheng Qin, Sanping Zhou, Le Wang, Jinghai Duan, Gang Hua, and Wei Tang. Motiontrack: Learning robust short- term and long-term motions for multi-object tracking. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 17939–17948, 2023
work page 2023
-
[69]
Tracking people by pre- dicting 3d appearance, location and pose
Jathushan Rajasegaran, Georgios Pavlakos, Angjoo Kanazawa, and Jitendra Malik. Tracking people by pre- dicting 3d appearance, location and pose. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2740–2749, 2022
work page 2022
-
[70]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Global-to-local modeling for video-based 3d human pose and shape estimation
Xiaolong Shen, Zongxin Yang, Xiaohan Wang, Jianxin Ma, Chang Zhou, and Yi Yang. Global-to-local modeling for video-based 3d human pose and shape estimation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8887–8896, 2023
work page 2023
-
[72]
Scaling law for time series forecasting
Jingzhe Shi, Qinwei Ma, Huan Ma, and Lei Li. Scaling law for time series forecasting. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2024
work page 2024
-
[73]
Jingzhe Shi, Qinwei Ma, Hongyi Liu, Hang Zhao, Jeng- Neng Hwang, and Lei Li. Explaining context length scaling and bounds for language models.arXiv preprint arXiv:2502.01481, 2025
-
[74]
Medal s: Spatio-textual prompt model for medical segmentation
Pengcheng Shi, Jiawei Chen, Jiaqi Liu, Xinglin Zhang, Tao Chen, and Lei Li. Medal s: Spatio-textual prompt model for medical segmentation. InCVPR 2025: Foundation Models for 3D Biomedical Image Segmentation
work page 2025
-
[75]
Diffusion-based neural network weights generation.arXiv preprint arXiv:2402.18153, 2024
Bedionita Soro, Nicol `o Andreis, et al. Diffusion-based neural network weights generation.arXiv preprint arXiv:2402.18153, 2024. ICLR 2025
-
[76]
Multiphys: Multi-person physics-aware 3d motion estimation
Nicolas Ugrinovic, Boxiao Pan, Georgios Pavlakos, De- spoina Paschalidou, Bokui Shen, Jordi Sanchez-Riera, Francesc Moreno-Noguer, and Leonidas Guibas. Multiphys: Multi-person physics-aware 3d motion estimation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2331–2340, 2024
work page 2024
-
[77]
Recovering accurate 3d human pose in the wild using imus and a moving camera
Timo von Marcard, Roberto Henschel, Michael Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering accurate 3d human pose in the wild using imus and a moving camera. In European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[78]
Reasoning or retrieval? a study of answer attribution on large reasoning models, 2025
Yuhui Wang, Changjiang Li, Guangke Chen, Jiacheng Liang, and Ting Wang. Reasoning or retrieval? a study of answer attribution on large reasoning models, 2025
work page 2025
-
[79]
Self-destructive language model, 2025
Yuhui Wang, Rongyi Zhu, and Ting Wang. Self-destructive language model, 2025
work page 2025
-
[80]
Simple online and realtime tracking with a deep association metric
Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. In2017 IEEE international conference on image processing (ICIP), pages 3645–3649. IEEE, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.