Recognition: unknown
JudgeMeNot: Personalizing Large Language Models to Emulate Judicial Reasoning in Hebrew
Pith reviewed 2026-05-10 04:08 UTC · model grok-4.3
The pith
A pipeline using synthetic data from court rulings lets language models emulate specific judges' reasoning in Hebrew.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
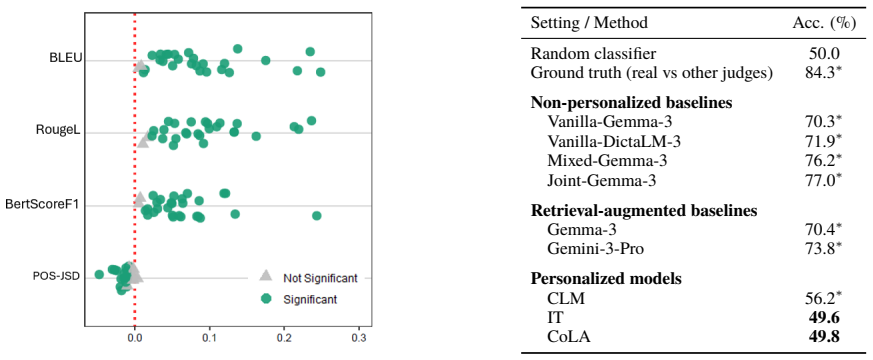
The central claim is that Causal Language Modeling followed by synthetically generated instruction-tuning significantly outperforms all other baselines, providing significant improvements across lexical, stylistic, and semantic similarity. Notably, our model-generated outputs are indistinguishable from the reasoning of human judges.
What carries the argument
The synthetic-organic supervision pipeline that transforms raw judicial decisions into instruction-tuning data for parameter-efficient fine-tuning.
If this is right
- The method delivers higher similarity to individual judges than existing personalization techniques on three tasks.
- Outputs match human reasoning so closely that they cannot be reliably distinguished.
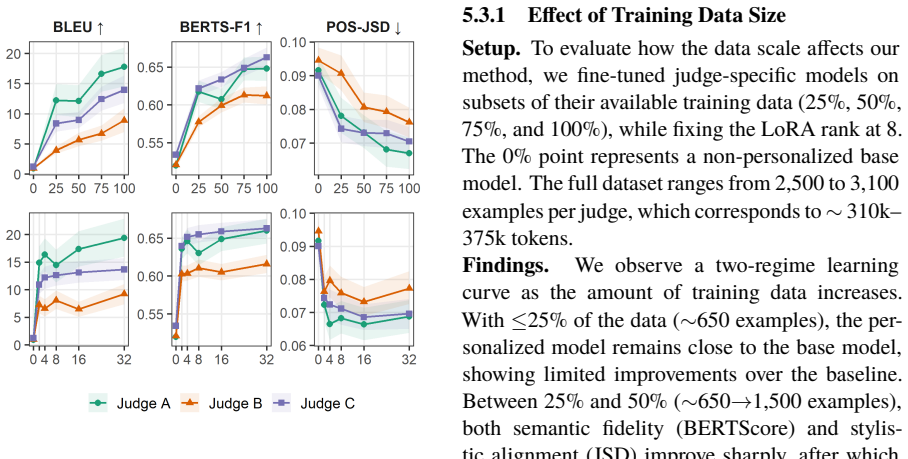
- Personalization succeeds even with limited training resources in languages like Hebrew.
- The two-stage process of causal modeling then synthetic instruction tuning drives the gains.
Where Pith is reading between the lines
- The same synthetic generation step could help personalize models for other experts who produce consistent but individual reasoning, such as physicians or financial analysts.
- Future tests on entirely new cases could show whether the tuned models preserve a judge's preferences beyond the training examples.
- Using synthetic data may lower privacy risks by reducing the need to expose full personal decision histories during training.
Load-bearing premise
Synthetically generated instruction data from judicial decisions accurately captures each judge's individual reasoning style and details without introducing biases or artifacts that distort the similarity measures.
What would settle it
A blind evaluation in which independent raters cannot distinguish the model's outputs from actual human judge decisions at rates above chance, or where lexical, stylistic, and semantic similarity scores show no advantage over standard personalization baselines.
Figures

read the original abstract
Despite significant advances in large language models, personalizing them for individual decision-makers remains an open problem. Here, we introduce a synthetic-organic supervision pipeline that transforms raw judicial decisions into instruction-tuning data, enabling parameter-efficient fine-tuning of personalized models for individual judges in low-resource settings. We compare our approach to state-of-the-art personalization techniques across three different tasks and settings. The results show that Causal Language Modeling followed by synthetically generated instruction-tuning significantly outperforms all other baselines, providing significant improvements across lexical, stylistic, and semantic similarity. Notably, our model-generated outputs are indistinguishable from the reasoning of human judges, highlighting the viability of efficient personalization, even in low-resource settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JudgeMeNot, a synthetic-organic supervision pipeline that converts raw judicial decisions into instruction-tuning data for parameter-efficient fine-tuning of personalized LLMs to emulate individual Hebrew judges' reasoning. It compares Causal Language Modeling followed by synthetically generated instruction-tuning against state-of-the-art personalization techniques across three tasks and settings, claiming significant outperformance on lexical, stylistic, and semantic similarity metrics, with model outputs described as indistinguishable from human judges' reasoning.
Significance. If the results hold under detailed scrutiny, the work would offer a practical advance in low-resource personalized language modeling for high-stakes domains like judicial reasoning. The pipeline's use of synthetic data derived from real decisions provides an efficient path to capturing individual nuances without extensive manual annotation, with potential applicability to other specialized decision-making contexts in under-resourced languages.
major comments (3)
- [Abstract] Abstract: The central claims of outperformance and indistinguishability from human judges are stated without any information on datasets (e.g., number of decisions or judges), specific similarity metrics, baselines, statistical significance testing, or the human evaluation protocol used to establish indistinguishability. These details are load-bearing for verifying the headline result that the approach 'significantly outperforms all other baselines' and produces outputs 'indistinguishable' from human judges.
- [Evaluation] The manuscript provides no ablations, human validation of synthetic examples, or controls to test whether the synthetically generated instruction data preserves individual judicial nuances or instead introduces artifacts from the generator LLM (especially relevant in low-resource Hebrew). Without such checks, improvements on automatic similarity metrics may not demonstrate faithful emulation of judicial reasoning.
- [Methods] Methods: The transformation process from raw judicial decisions to instruction-tuning data is described at a high level but lacks concrete details on prompting strategies, data filtering, or how individual judge-specific patterns are isolated and preserved, hindering assessment of reproducibility and bias risks.
minor comments (1)
- [Abstract] The abstract introduces the term 'synthetic-organic supervision pipeline' without a brief definition or pointer to related hybrid supervision literature, which would aid reader comprehension.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and commit to revisions that enhance clarity, rigor, and reproducibility without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of outperformance and indistinguishability from human judges are stated without any information on datasets (e.g., number of decisions or judges), specific similarity metrics, baselines, statistical significance testing, or the human evaluation protocol used to establish indistinguishability. These details are load-bearing for verifying the headline result that the approach 'significantly outperforms all other baselines' and produces outputs 'indistinguishable' from human judges.
Authors: We agree that the abstract would be strengthened by incorporating these specifics. In the revised manuscript, we will expand the abstract to report the dataset composition (number of decisions and judges), enumerate the lexical, stylistic, and semantic similarity metrics, identify the baselines, reference the statistical significance testing performed, and outline the human evaluation protocol used to assess indistinguishability from human judges' reasoning. revision: yes
-
Referee: [Evaluation] The manuscript provides no ablations, human validation of synthetic examples, or controls to test whether the synthetically generated instruction data preserves individual judicial nuances or instead introduces artifacts from the generator LLM (especially relevant in low-resource Hebrew). Without such checks, improvements on automatic similarity metrics may not demonstrate faithful emulation of judicial reasoning.
Authors: We acknowledge that additional validation would further substantiate the pipeline's fidelity. The submitted manuscript emphasized end-to-end task performance, but we will incorporate ablations isolating the synthetic instruction-tuning component, a human validation study on sampled synthetic examples to verify preservation of judge-specific nuances, and controls comparing synthetic outputs against original decisions to assess potential generator artifacts in the Hebrew setting. revision: yes
-
Referee: [Methods] Methods: The transformation process from raw judicial decisions to instruction-tuning data is described at a high level but lacks concrete details on prompting strategies, data filtering, or how individual judge-specific patterns are isolated and preserved, hindering assessment of reproducibility and bias risks.
Authors: We concur that greater methodological detail is necessary for reproducibility. The revised Methods section will include the exact prompting templates used for converting decisions to instruction data, the filtering criteria applied, and the specific techniques for isolating and retaining individual judge patterns. We will also add discussion of bias risks and corresponding safeguards. revision: yes
Circularity Check
No circularity: empirical results rest on external human similarity metrics
full rationale
The paper describes an empirical pipeline that converts raw judicial decisions into synthetic instruction data for fine-tuning, then evaluates the resulting models via independent lexical, stylistic, and semantic similarity metrics against held-out human judge outputs. No equations, fitted parameters, or derivations are presented that reduce the reported performance gains to the inputs by construction. The central claim of outperforming baselines and producing indistinguishable outputs is supported by comparative experiments rather than self-referential fitting or self-citation chains. Evaluation relies on external benchmarks, satisfying the criteria for a self-contained, non-circular result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Raw judicial decisions contain sufficient signal to train models that emulate individual reasoning styles
- domain assumption Parameter-efficient fine-tuning can achieve high fidelity personalization in low-resource settings
Reference graph
Works this paper leans on
-
[1]
Political Analysis, 32(1):115– 132
Relatio: Text semantics capture political and economic narratives. Political Analysis, 32(1):115– 132. J Elliott Casal and Matt Kessler. 2023. Can linguists distinguish between chatgpt/ai and human writing?: A study of research ethics and academic publish- ing. Research Methods in Applied Linguistics , 2(3):100068. Shu Chen, Xinyan Guan, Y aojie Lu, Hongy...
2023
-
[2]
In Proceedings of the 5th International Con- ference on Natural Language Processing for Digital Humanities, pages 20–32, Albuquerque, USA
Analyzing large language models’ pastiche ability: a case study on a 20th century Romanian au- thor. In Proceedings of the 5th International Con- ference on Natural Language Processing for Digital Humanities, pages 20–32, Albuquerque, USA. Asso- ciation for Computational Linguistics. Lee Epstein, William M Landes, and Richard A Posner
-
[3]
harvard uni- versity press
The behavior of federal judges: a theoretical and empirical study of rational choice . harvard uni- versity press. Deva Kumar Gajulamandyam, Sainath Veerla, Y asaman Emami, Kichang Lee, Yuanting Li, Jinthy Swetha Mamillapalli, and Simon Shim
-
[4]
In 2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC), pages 00484–00490
Domain specific finetuning of llms using peft techniques. In 2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC), pages 00484–00490. IEEE. Google DeepMind. 2025. Gemini 3 pro model card. Model card. https://storage.googleapis. com/deepmind-media/Model-Cards/ Gemini-3-Pro-Model-Card.pdf . Neel Guha, Julian Nyarko, Daniel Ho, Ch...
2025
-
[5]
International Conference on Machine Learning, pages 2790–2799
Parameter-efficient transfer learning for nlp. International Conference on Machine Learning, pages 2790–2799. Edward J Hu, Y elong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3. Jie Huang and Kevin Chen-Chuan Chang. 2023. To- wards r...
2022
-
[6]
Journal of the American Society for informa- tion Science and Technology, 60(1):9–26
Computational methods in authorship attribu- tion. Journal of the American Society for informa- tion Science and Technology, 60(1):9–26. Kalpesh Krishna, John Wieting, and Mohit Iyyer. 2020. Reformulating unsupervised style transfer as para- phrase generation. In Proceedings of the 2020 Con- ference on Empirical Methods in Natural Language Processing (EMN...
2020
-
[7]
Chatharuhi: Reviving anime character in reality via large language model
Chatharuhi: Reviving anime character in reality via large language model. arXiv preprint arXiv:2308.09597. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[8]
In The Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. In The Twelfth Inter- national Conference on Learning Representations . Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[9]
In The Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. In The Twelfth Inter- national Conference on Learning Representations . Xinyue Liu, Harshita Diddee, and Daphne Ippolito
-
[10]
In Proceedings of the 17th International Natural Language Generation Conference , pages 412–426, Tokyo, Japan
Customizing large language model gen- eration style using parameter-efficient finetuning . In Proceedings of the 17th International Natural Language Generation Conference , pages 412–426, Tokyo, Japan. Association for Computational Lin- guistics. Gianluca Moro, Leonardo David Matteo Magnani, and Luca Ragazzi. 2026. Legal lay summarization: exploring method...
2026
-
[11]
Perplm: Personalized fine-tuning of pre- trained language models via writer-specific interme- diate learning and prompts . arXiv. Jeiyoon Park, Chanjun Park, and Heuiseok Lim. 2025. CharacterGPT: A persona reconstruction framework for role-playing agents. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Democratizing large lan- guage models via personalized parameter-efficient fine-tuning
Character-LLM: A trainable agent for role- playing. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 13153–13187, Singapore. Association for Computational Linguistics. Shaltiel Shmidman, Avi Shmidman, Amir DN Cohen, and Moshe Koppel. 2025. Dicta-LM 3.0: Advancing The Frontier of Hebrew Sovereign LLMs. Tech...
-
[13]
Reasoning Sentence Extraction We process each verdict with a chain-of-thought prompt to identify sentences that express the judge’s legal reasoning
-
[14]
Judicial Reasoning ValidationWe pass the extracted flagged sentences to a separate validator prompt that confirms they indeed contain judicial reasoning; sentences that fail validation are removed
-
[15]
Question Generation Based on the extracted reasoning sentences, we generate questions whose an- swers refer to the reasoning sentences
-
[16]
The exact prompts used in each stage of the workflow are provided in Section A.7
Validation We then verify that the questions match the answers; if validation fails twice, the pair is discarded. The exact prompts used in each stage of the workflow are provided in Section A.7. A.6 Qualitative Error Analysis Below we present representative question–answer pairs comparing the outputs of the Base model, CLM, and CoLA on identical inputs. ...
-
[17]
Language — Output questions in Hebrew
-
[18]
Style — Prefer״כיצד״,״מהו״,״מדוע״ to open questions; avoid rhetoric
-
[19]
Scope — Use only the Answer (and optional Context to disambiguate names)
-
[20]
### Reasoning Steps
Punctuation — Standard Hebrew punctuation; never the character ‘ -’. ### Reasoning Steps
-
[21]
Identify its pivotal legal point (rule, fact pattern, mitigation, etc.)
-
[22]
Reformulate that pivot into an interrogative sentence that elicits the Answer verbatim or in tight paraphrase
-
[23]
### Output Format Return exactly one line per Answer, numbered 1
Verify the question is answerable solely from the Answer. ### Output Format Return exactly one line per Answer, numbered 1. 2. … Example: 1 2 Return only the numbered list—nothing else. Step 4: QA Validation Model: GPT-4o-mini אתהבודק-איכותקפדן.השאלהוהתשובהחייבותלהתאיםבזיקהמלאה:האםהתשובהעונהבמדויקעלהשאלהענה אךורקב-״
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.