Recognition: unknown
Depth Registers Unlock W4A4 on SwiGLU: A Reader/Generator Decomposition
Pith reviewed 2026-05-10 04:57 UTC · model grok-4.3
The pith
Depth registers with a hinge loss control residual reader magnitudes in SwiGLU, unlocking W4A4 quantization performance while leaving the w2 bilinear generator as the dominant error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
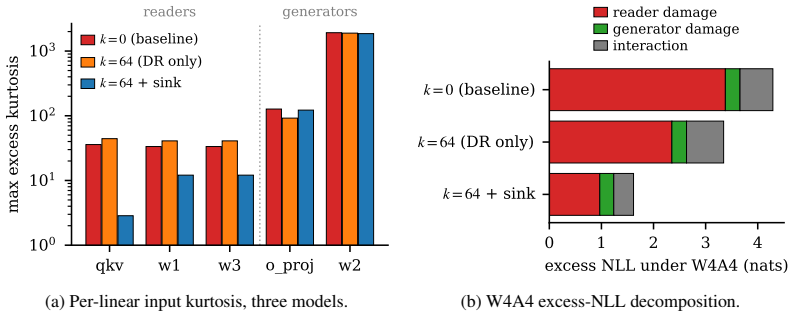
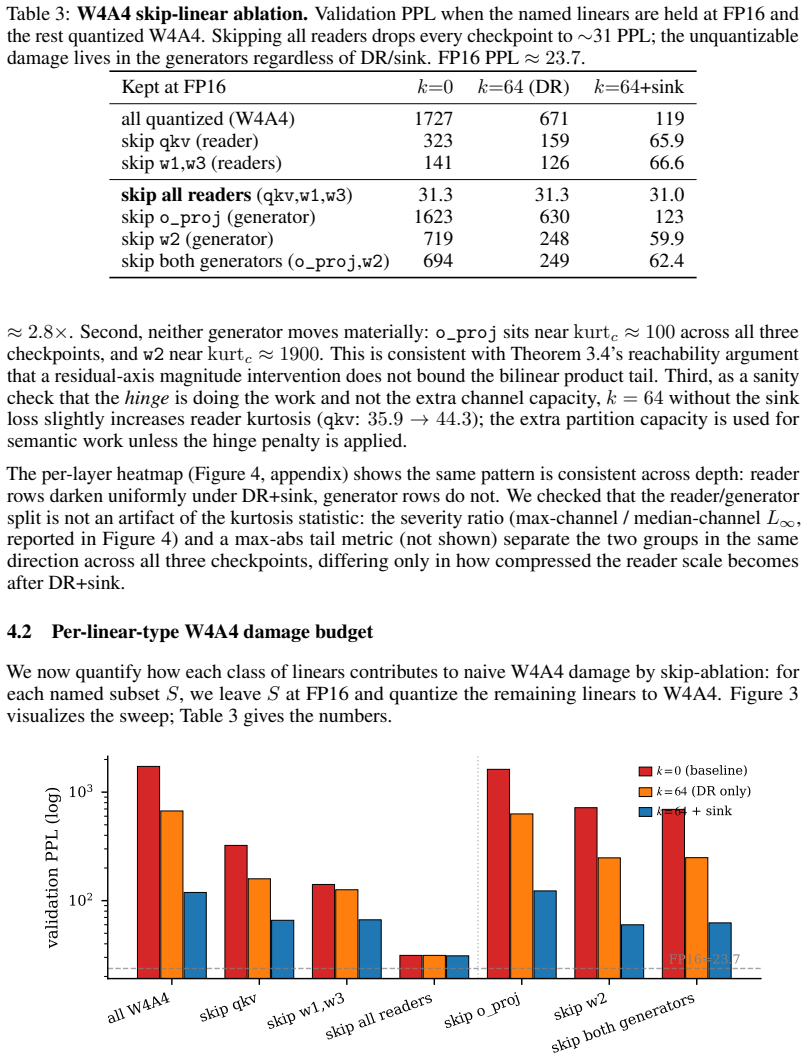
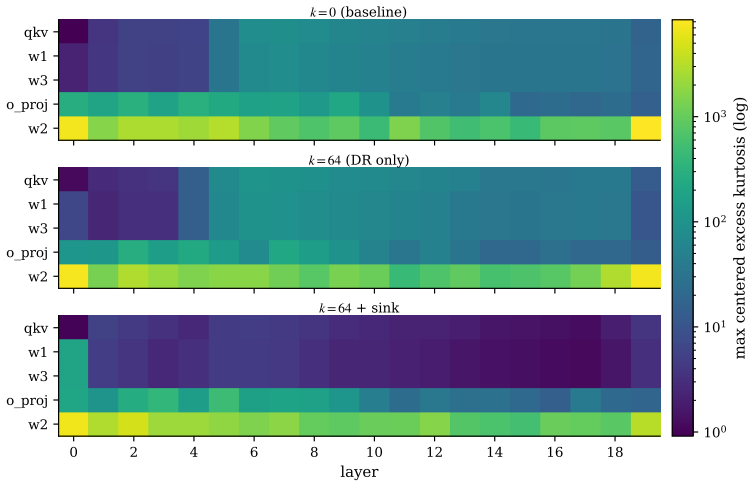
Elementary norm arguments show residual-axis magnitude control bounds readers tightly but leaves w2's bilinear input bounded only by the trivial product of factor bounds. Empirically, DR+sink collapses reader kurtosis while leaving generators essentially unchanged, and the reader-rescued W4A4 residue is flat at ~0.28 nats across three matched checkpoints with Delta-remove(w2) dominating.
What carries the argument
Depth Registers with register-magnitude hinge loss (DR+sink) applied to residual-axis readers (qkv, w1, w3) versus block-internal generators (o_proj, w2) in SwiGLU blocks.
If this is right
- DR+sink reduces W4A4 validation perplexity by a factor of about 14 at matched FP16 performance.
- Combining DR+sink with SmoothQuant further reduces perplexity to 39.9.
- Per-Linear QuaRot nearly matches DR+sink on the reader axis as a post-hoc method.
- Full QuaRot with value Hadamard and w2-input rotation fails to close the remaining gap, confirming that orthogonal rotation cannot bound the bilinear SwiGLU tail.
Where Pith is reading between the lines
- Similar magnitude control techniques could be applied to other activation quantization problems in transformer variants with residual paths.
- The flat residue suggests that w2-specific quantization strategies, such as input-aware scaling, might close the remaining FP16 gap.
- The reader-generator split may generalize to other feed-forward architectures beyond SwiGLU.
Load-bearing premise
The partition into residual-axis readers and block-internal generators, together with the hinge loss, isolates the reader effect without confounding generator behavior, though the experiments do not fully separate the two.
What would settle it
An experiment that quantizes only the readers versus only w2 after DR+sink training and checks whether the flat 0.28 nats residue and kurtosis collapse persist independently for the readers alone.
Figures


read the original abstract
We study post-training W4A4 quantization in a controlled 300M-parameter SwiGLU decoder-only language model trained on 5B tokens of FineWeb-Edu, and ask which input-activation sites dominate the error. Naive round-to-nearest W4A4 collapses validation perplexity from FP16 23.6 to 1727. A simple residual-axis training-time intervention -- Depth Registers with a register-magnitude hinge loss (DR+sink) -- reduces this to 119 (about 14x) at matched FP16 PPL and matched zero-shot capacity, and composes with SmoothQuant to 39.9 PPL. The residual ~2 PPL gap to FP16 is the diagnostic core. We decompose W4A4 damage by input-activation site: the five trainable linears in a SwiGLU block split into residual-axis readers (qkv, w1, w3) and block-internal generators (o_proj, w2). Elementary norm arguments show residual-axis magnitude control bounds readers tightly but leaves w2's bilinear input bounded only by the trivial product of factor bounds; empirically, DR+sink collapses reader kurtosis while leaving generators essentially unchanged, and the reader-rescued W4A4 residue is flat at ~0.28 nats across three matched checkpoints with Delta-remove(w2) dominating. We present DR+sink as a training-time probe rather than a deployment proposal: a post-hoc alternative (Per-Linear QuaRot) nearly matches it on the reader axis. Full QuaRot -- adding online per-head value Hadamard plus online w2-input rotation -- does not close the gap either, directly testing the prediction that orthogonal rotation cannot bound the bilinear SwiGLU tail. Claims are specific to our 300M, 5B-token, single-seed setting, and our experiments do not isolate the partition from the hinge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies post-training W4A4 quantization on a 300M SwiGLU decoder-only LM trained on 5B FineWeb-Edu tokens. Naive W4A4 raises validation PPL from 23.6 to 1727; a training-time Depth Registers + register-magnitude hinge (DR+sink) reduces it to 119 at matched FP16 PPL, and composes with SmoothQuant to 39.9. The central claim decomposes the residual ~2 PPL gap by site: residual-axis readers (qkv, w1, w3) are tightly bounded by magnitude control while the block-internal generator w2 is only bounded by the product of its factors; DR+sink collapses reader kurtosis, leaves generators unchanged, and leaves a flat ~0.28 nats residue whose dominant term is Delta-remove(w2). Full QuaRot fails to close the gap, consistent with the bilinear-tail prediction. All claims are scoped to the single 300M, single-seed, 5B-token setting, and the paper states that experiments do not isolate the reader/generator partition from the hinge.
Significance. If the decomposition is robust, the work supplies a concrete diagnostic for why SwiGLU W4A4 error concentrates on the w2 bilinear input and shows that residual-axis magnitude control recovers most of the damage. The matched-checkpoint PPL numbers, kurtosis measurements, and direct Delta-remove(w2) observations are strengths; the failure of full QuaRot supplies a falsifiable test of the norm argument. The single-model scale and explicit non-isolation of hinge from partition, however, keep the result exploratory rather than definitive for larger models or deployment.
major comments (2)
- [Abstract] Abstract: the paper states that 'our experiments do not isolate the partition from the hinge.' Because DR+sink is a training-time intervention applied before the post-hoc reader/generator split and quantization-error measurements, any hinge-induced shift in generator activation statistics or error propagation directly confounds the claim that Delta-remove(w2) dominance is an inherent property of the bilinear SwiGLU tail rather than an artifact of the hinge. This is load-bearing for the central attribution of the flat ~0.28 nats residue.
- [Abstract and experimental sections] The central empirical claim (flat ~0.28 nats residue with w2 dominance across three matched checkpoints) rests on a single 300M model and single seed. No ablation varies model scale, data volume, or random seed while keeping the DR+sink hinge fixed, so it is unclear whether the reader kurtosis collapse and w2 dominance generalize or are specific to this training run.
minor comments (2)
- [Abstract] The abstract reports 'about 14x' improvement; an exact ratio (1727/119) should be stated for precision.
- [Main text] Notation for 'Delta-remove(w2)' and the exact definition of the reader/generator partition should be introduced with an equation or table in the main text rather than only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We respond to each major comment below, maintaining the scoped nature of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the paper states that 'our experiments do not isolate the partition from the hinge.' Because DR+sink is a training-time intervention applied before the post-hoc reader/generator split and quantization-error measurements, any hinge-induced shift in generator activation statistics or error propagation directly confounds the claim that Delta-remove(w2) dominance is an inherent property of the bilinear SwiGLU tail rather than an artifact of the hinge. This is load-bearing for the central attribution of the flat ~0.28 nats residue.
Authors: We agree that the training-time application of DR+sink precludes fully isolating the reader/generator partition from any effects of the hinge. Our manuscript already states this limitation explicitly. Kurtosis measurements in the paper show generators remain essentially unchanged under DR+sink, and the observed w2 dominance holds within this trained model. We will revise the abstract to further emphasize that the attribution applies specifically under DR+sink training. revision: partial
-
Referee: [Abstract and experimental sections] The central empirical claim (flat ~0.28 nats residue with w2 dominance across three matched checkpoints) rests on a single 300M model and single seed. No ablation varies model scale, data volume, or random seed while keeping the DR+sink hinge fixed, so it is unclear whether the reader kurtosis collapse and w2 dominance generalize or are specific to this training run.
Authors: We acknowledge that results are from a single 300M model, single seed, and fixed 5B-token training run. The three matched checkpoints offer internal consistency for the reported residue and dominance, but we make no claims of generalization. All statements in the manuscript are already scoped to this specific setting. revision: no
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's load-bearing steps are (1) elementary norm arguments bounding residual-axis readers (qkv, w1, w3) versus the product-bound bilinear input to w2, presented as first-principles analysis, and (2) direct empirical observations of kurtosis collapse, unchanged generator statistics, and flat ~0.28 nats residue with Delta-remove(w2) dominance across matched checkpoints. These do not reduce by construction to the DR+sink hinge parameters or to any fitted input renamed as prediction. The paper explicitly states its experiments do not isolate the partition from the hinge, which is an experimental-design caveat rather than a self-definitional loop. No self-citations, uniqueness theorems, or ansatzes appear in the provided text. The central claims remain independent of the intervention by the paper's own equations and measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Residual-axis magnitude control bounds reader activations but only trivially bounds the product input to w2.
invented entities (1)
-
Depth Registers
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information...
2024
-
[2]
URL http://papers.nips.cc/paper_files/ paper/2024/hash/b5b939436789f76f08b9d0da5e81af7c-Abstract-Conference.html. Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang R...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski
URL http://papers.nips.cc/paper_files/paper/2023/hash/ edbcb7583fd8921dad78adecfe06a99b-Abstract-Conference.html. Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2023
-
[5]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
URL https://openreview.net/ forum?id=2dnO3LLiJ1. Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale.CoRR, abs/2208.07339,
work page internal anchor Pith review arXiv
-
[7]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
doi: 10.48550/ ARXIV .2210.17323. URLhttps://doi.org/10.48550/arXiv.2210.17323. Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas ...
work page internal anchor Pith review doi:10.48550/arxiv.2210.17323
-
[9]
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Kr- ishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort
URL https://proceedings.mlsys.org/paper_files/paper/2024/hash/ 42a452cbafa9dd64e9ba4aa95cc1ef21-Abstract-Conference.html. Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Kr- ishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: LLM quantization with learned rotations. InThe Thirteenth Internatio...
2024
-
[10]
Guilherme Penedo, Hynek Kydlícek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin A
URL https://openreview.net/forum?id=ogO6DGE6FZ. Guilherme Penedo, Hynek Kydlícek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin A. Raffel, Leandro von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomcz...
2024
-
[11]
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo
URLhttp://papers.nips.cc/paper_ files/paper/2024/hash/370df50ccfdf8bde18f8f9c2d9151bda-Abstract-Datasets_ and_Benchmarks_Track.html. Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models.International Confere...
2024
-
[13]
GLU Variants Improve Transformer
URL https: //arxiv.org/abs/2002.05202. Mingjie Sun, Xinlei Chen, J. Zico Kolter, and Zhuang Liu. Massive activations in large language models.CoRR, abs/2402.17762,
work page internal anchor Pith review arXiv 2002
-
[15]
LLaMA: Open and Efficient Foundation Language Models
URLhttps://proceedings.mlr. press/v267/sun25l.html. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.CoRR, abs/2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
LLaMA: Open and Efficient Foundation Language Models
doi: 10.48550/ARXIV .2302.13971. URL https://doi. org/10.48550/arXiv.2302.13971. Guangxuan Xiao, Ji Lin, Mickaël Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, e...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[17]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis
URLhttps://proceedings.mlr.press/v202/xiao23c.html. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[18]
URLhttps://doi.org/10.3390/fi17040185
doi: 10.3390/FI17040185. URLhttps://doi.org/10.3390/fi17040185. Zhihang Yuan, Lin Niu, Jiawei Liu, Wenyu Liu, Xinggang Wang, Yuzhang Shang, Guangyu Sun, Qiang Wu, Jiaxiang Wu, and Bingzhe Wu. RPTQ: Reorder-based post-training quantization for large language models.arXiv preprint arXiv:2304.01089,
-
[19]
Total trainable parameters:302M
11 A Implementation details Architecture.All three models share: 20 decoder layers, d= 1024 model dimension, 16 attention heads (head dimension 64), SwiGLU MLP with inner dimension 2752 (parameter budget matched across configurations), RoPE positional embeddings, tied token-embedding / output head, vocabulary size50,304. Total trainable parameters:302M. T...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.