Recognition: unknown
Soft Label Pruning and Quantization for Large-Scale Dataset Distillation
Pith reviewed 2026-05-10 05:40 UTC · model grok-4.3
The pith
Pruning and quantizing soft labels during dataset distillation cuts their storage by 78x on ImageNet-1K while raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
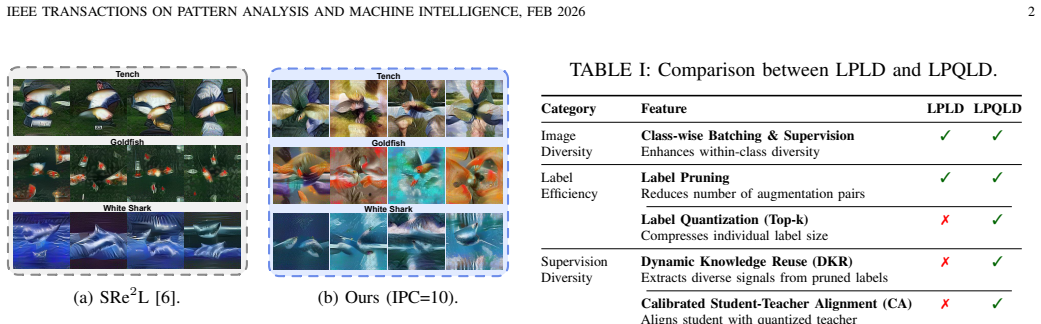
The paper establishes that label pruning with dynamic knowledge reuse and label quantization with calibrated student-teacher alignment, combined with class-wise batching and batch-normalization supervision during synthesis, simultaneously raise image diversity and supervision diversity. This allows soft-label storage to shrink by 78 times on ImageNet-1K and 500 times on ImageNet-21K while accuracy rises by as much as 7.2 percent and 2.8 percent, respectively, and the gains hold across different network architectures and distillation algorithms.
What carries the argument
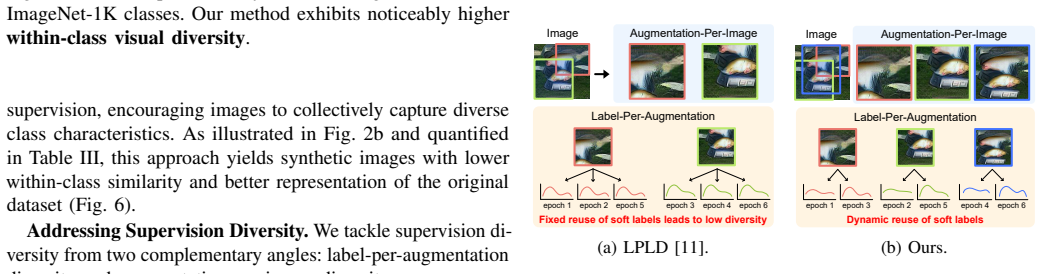
Label Pruning with Dynamic Knowledge Reuse together with Label Quantization with Calibrated Student-Teacher Alignment, which improve label-per-augmentation diversity and augmentation-per-image diversity while preserving alignment between student and teacher models.
If this is right
- Distilled datasets can be stored at much higher compression ratios without the usual accuracy penalty.
- Training on the distilled data requires fewer augmentation passes because the synthetic images already vary more within each class.
- The same pruning and quantization steps can be added to existing distillation pipelines without changing their core synthesis loop.
- Supervision remains effective even when the number of soft labels per image is reduced by orders of magnitude.
- The approach scales to ImageNet-21K where label storage had been an even larger barrier.
Where Pith is reading between the lines
- Similar pruning-quantization logic could be applied to other auxiliary data structures that grow with dataset size, such as feature banks or attention maps.
- The diversity gains might allow distilled datasets to support longer training schedules or larger batch sizes than before.
- If the calibration step generalizes, the same alignment technique could be reused when distilling into models with different output dimensions.
- Testing on non-ImageNet domains would show whether the class-wise batching rule needs domain-specific tuning.
Load-bearing premise
That adding class-wise batching, batch-normalization supervision, and the specific pruning and quantization rules will reliably raise diversity without creating new biases or lowering supervision quality across architectures and distillation methods.
What would settle it
Running the full pipeline on ImageNet-1K with a held-out distillation method and architecture and finding that the compressed soft labels produce lower accuracy than the original uncompressed labels at the same image count.
Figures












read the original abstract
Large-scale dataset distillation requires storing auxiliary soft labels that can be 30-40x larger on ImageNet-1K and 200x larger on ImageNet-21K than the condensed images, undermining the goal of dataset compression. We identify two fundamental issues necessitating such extensive labels: (1) insufficient image diversity, where high within-class similarity in synthetic images requires extensive augmentation, and (2) insufficient supervision diversity, where limited variety in supervisory signals during training leads to performance degradation at high compression rates. To address these challenges, we propose Label Pruning and Quantization for Large-scale Distillation (LPQLD). We enhance image diversity via class-wise batching and batch-normalization supervision during synthesis. For supervision diversity, we introduce Label Pruning with Dynamic Knowledge Reuse to improve label-per-augmentation diversity, and Label Quantization with Calibrated Student-Teacher Alignment to improve augmentation-per-image diversity. Our approach reduces soft label storage by 78x on ImageNet-1K and 500x on ImageNet-21K while improving accuracy by up to 7.2% and 2.8%, respectively. Extensive experiments validate the superiority of LPQLD across different network architectures and dataset distillation methods. Code is available at https://github.com/he-y/soft-label-pruning-quantization-for-dataset-distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Label Pruning and Quantization for Large-scale Distillation (LPQLD) to mitigate the high storage cost of soft labels in large-scale dataset distillation. It identifies insufficient image diversity and supervision diversity as core issues and addresses them via class-wise batching plus batch-norm supervision during synthesis, dynamic knowledge reuse for label pruning, and calibrated student-teacher alignment for quantization. The central empirical claims are 78x and 500x reductions in soft-label storage on ImageNet-1K and ImageNet-21K, respectively, accompanied by accuracy gains of up to 7.2% and 2.8%, with validation across multiple architectures and distillation baselines. Code is released.
Significance. If the storage reductions and accuracy improvements prove robust, the work would meaningfully advance practical dataset distillation for large-scale vision datasets by removing a major auxiliary-data bottleneck. The public code release is a clear strength that supports reproducibility. The approach is algorithmic and empirical rather than deriving parameter-free guarantees, so its impact hinges on the reliability of the reported gains across realistic deployment settings.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): accuracy improvements (up to 7.2% and 2.8%) are stated without error bars, standard deviations, or the number of independent runs, which is load-bearing for any claim that the method “improves accuracy.”
- [§3.2] §3.2 (Batch-Normalization Supervision): the synthesis-time BN supervision implicitly assumes downstream students also rely on batch statistics; this assumption is not tested on LayerNorm- or attention-only architectures, raising the risk that reported gains are partly an artifact of the ResNet-style models used in the experiments.
- [§4.3] §4.3 (Ablations) and free-parameter list: the pruning threshold, reuse schedule, quantization bit-width, and alignment calibration are free parameters, yet no systematic sensitivity analysis or data-exclusion protocol is provided; without these, it is unclear whether the diversity improvements are general or the result of post-hoc tuning on the reported splits.
minor comments (2)
- [§3] Notation for the dynamic reuse schedule and calibrated alignment loss could be introduced earlier and used consistently in the method diagrams.
- [Figures] Figure captions should explicitly state the compression ratio and student architecture for each bar group to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, agreeing where revisions are warranted and providing clarifications where the manuscript already supports the claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): accuracy improvements (up to 7.2% and 2.8%) are stated without error bars, standard deviations, or the number of independent runs, which is load-bearing for any claim that the method “improves accuracy.”
Authors: We agree that statistical reporting is necessary to substantiate accuracy claims. In the revised manuscript we will report mean accuracy and standard deviation over at least three independent runs with different random seeds for all main results, and add error bars to the relevant tables and figures in §4 as well as the abstract summary. revision: yes
-
Referee: [§3.2] §3.2 (Batch-Normalization Supervision): the synthesis-time BN supervision implicitly assumes downstream students also rely on batch statistics; this assumption is not tested on LayerNorm- or attention-only architectures, raising the risk that reported gains are partly an artifact of the ResNet-style models used in the experiments.
Authors: The BN supervision is applied only during dataset synthesis to increase image diversity and is independent of the student architecture used at distillation time. Our experiments already include multiple architectures beyond basic ResNet (as stated in §4), and the pruning/quantization components are architecture-agnostic. We will add an explicit discussion of this scope and include results on one LayerNorm-based model in the revision to further demonstrate generality. revision: partial
-
Referee: [§4.3] §4.3 (Ablations) and free-parameter list: the pruning threshold, reuse schedule, quantization bit-width, and alignment calibration are free parameters, yet no systematic sensitivity analysis or data-exclusion protocol is provided; without these, it is unclear whether the diversity improvements are general or the result of post-hoc tuning on the reported splits.
Authors: Parameter values were chosen via a held-out validation set distinct from the reported test splits, with the chosen values documented in the supplementary material. We acknowledge that a systematic sensitivity study would strengthen the presentation. In the revised §4.3 we will add plots showing performance across ranges of each free parameter, confirming that the reported gains remain stable within reasonable operating regions. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper is an algorithmic proposal that identifies two issues in large-scale dataset distillation (insufficient image and supervision diversity) and introduces LPQLD with concrete techniques: class-wise batching plus BN supervision for image diversity, plus label pruning with dynamic knowledge reuse and label quantization with calibrated alignment for supervision diversity. These are presented as engineering solutions whose value is demonstrated via empirical storage reductions (78x/500x) and accuracy gains (up to 7.2%/2.8%) across architectures and distillation methods. No equations, fitted parameters, or self-citations are shown that reduce the reported gains to quantities defined inside the same derivation; the central claims rest on external experimental validation rather than a closed mathematical loop. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- pruning threshold and reuse schedule
- quantization bit-width and alignment calibration
axioms (1)
- domain assumption Soft labels from a teacher model provide richer supervision than hard labels during distillation training
Reference graph
Works this paper leans on
-
[1]
Dataset distillation.arXiv preprint arXiv:1811.10959, 2018
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A Efros. Dataset distillation.arXiv preprint arXiv:1811.10959, 2018
-
[2]
Cafe: Learning to condense dataset by aligning features
Kai Wang, Bo Zhao, Xiangyu Peng, Zheng Zhu, Shuo Yang, Shuo Wang, Guan Huang, Hakan Bilen, Xinchao Wang, and Yang You. Cafe: Learning to condense dataset by aligning features. InProc. IEEE Conf. Comput. Vis. Pattern Recog., pages 12196–12205, 2022
2022
-
[3]
Efros, and Jun-Yan Zhu
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A. Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. InProc. IEEE Conf. Comput. Vis. Pattern Recog., 2022
2022
-
[4]
Dataset condensation with gradient matching
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching. InProc. Int. Conf. Learn. Represent., 2021
2021
-
[5]
Dataset condensation with distribution matching
Bo Zhao and Hakan Bilen. Dataset condensation with distribution matching. InProc. IEEE Winter Conf. Appl. Comput. Vis., pages 6514– 6523, 2023
2023
-
[6]
Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective
Zeyuan Yin, Eric Xing, and Zhiqiang Shen. Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective. InProc. Adv. Neural Inform. Process. Syst., 2023
2023
-
[7]
Dataset distillation via curriculum data synthesis in large data era.Transactions on Machine Learning Research, 2024
Zeyuan Yin and Zhiqiang Shen. Dataset distillation via curriculum data synthesis in large data era.Transactions on Machine Learning Research, 2024
2024
-
[8]
On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm
Peng Sun, Bei Shi, Daiwei Yu, and Tao Lin. On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm. InProc. IEEE Conf. Comput. Vis. Pattern Recog., 2024. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, FEB 2026 12
2024
-
[9]
Generalized large-scale data condensation via various backbone and statistical matching
Shitong Shao, Zeyuan Yin, Muxin Zhou, Xindong Zhang, and Zhiqiang Shen. Generalized large-scale data condensation via various backbone and statistical matching. InProc. IEEE Conf. Comput. Vis. Pattern Recog., 2024
2024
-
[10]
Self- supervised dataset distillation: A good compression is all you need
Muxin Zhou, Zeyuan Yin, Shitong Shao, and Zhiqiang Shen. Self- supervised dataset distillation: A good compression is all you need. arXiv preprint arXiv:2404.07976, 2024
-
[11]
Are large-scale soft labels necessary for large-scale dataset distillation? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
Lingao Xiao and Yang He. Are large-scale soft labels necessary for large-scale dataset distillation? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[12]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProc. IEEE Conf. Comput. Vis. Pattern Recog., pages 248–255. Ieee, 2009
2009
-
[13]
Dataset condensation via efficient synthetic-data parameterization
Jang-Hyun Kim, Jinuk Kim, Seong Joon Oh, Sangdoo Yun, Hwanjun Song, Joonhyun Jeong, Jung-Woo Ha, and Hyun Oh Song. Dataset condensation via efficient synthetic-data parameterization. InProc. Int. Conf. Mach. Learn., 2022
2022
-
[14]
Scaling up dataset distillation to imagenet-1k with constant memory
Justin Cui, Ruochen Wang, Si Si, and Cho-Jui Hsieh. Scaling up dataset distillation to imagenet-1k with constant memory. InProc. Int. Conf. Mach. Learn., pages 6565–6590. PMLR, 2023
2023
-
[15]
Diversity-driven synthesis: Enhancing dataset distillation through directed weight adjustment
Jiawei Du, Xin Zhang, Juncheng Hu, Wenxin Huang, and Joey Tianyi Zhou. Diversity-driven synthesis: Enhancing dataset distillation through directed weight adjustment. InProc. Adv. Neural Inform. Process. Syst., 2024
2024
-
[16]
Going beyond feature similarity: Effective dataset distillation based on class-aware conditional mutual information
Xinhao Zhong, Bin Chen, Hao Fang, Xulin Gu, Shu-Tao Xia, and EN- HUI Y ANG. Going beyond feature similarity: Effective dataset distillation based on class-aware conditional mutual information. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Understanding dataset distillation via spectral filtering.arXiv preprint arXiv:2503.01212, 2025
Deyu Bo, Songhua Liu, and Xinchao Wang. Understanding dataset distillation via spectral filtering.arXiv preprint arXiv:2503.01212, 2025
-
[18]
Dataset distillation via committee voting.arXiv preprint arXiv:2501.07575, 2025
Jiacheng Cui, Zhaoyi Li, Xiaochen Ma, Xinyue Bi, Yaxin Luo, and Zhiqiang Shen. Dataset distillation via committee voting.arXiv preprint arXiv:2501.07575, 2025
-
[19]
The augmented image prior: Distilling 1000 classes by extrapolating from a single image
Yuki M Asano and Aaqib Saeed. The augmented image prior: Distilling 1000 classes by extrapolating from a single image. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[20]
Delt: A simple diversity-driven earlylate training for dataset distillation, 2024
Zhiqiang Shen, Ammar Sherif, Zeyuan Yin, and Shitong Shao. Delt: A simple diversity-driven earlylate training for dataset distillation, 2024
2024
-
[21]
Dataset distillation via the wasserstein metric
Haoyang Liu, Yijiang Li, Tiancheng Xing, Vibhu Dalal, Luwei Li, Jingrui He, and Haohan Wang. Dataset distillation via the wasserstein metric. InProc. Int. Conf. Comput. Vis., pages 1205–1215, 2025
2025
-
[22]
You only condense once: Two rules for pruning condensed datasets
Yang He, Lingao Xiao, and Joey Tianyi Zhou. You only condense once: Two rules for pruning condensed datasets. InProc. Adv. Neural Inform. Process. Syst., 2024
2024
-
[23]
Large scale dataset distillation with domain shift
Noel Loo, Alaa Maalouf, Ramin Hasani, Mathias Lechner, Alexander Amini, and Daniela Rus. Large scale dataset distillation with domain shift. InProc. Int. Conf. Mach. Learn., 2024
2024
-
[24]
Emphasizing discriminative features for dataset distillation in complex scenarios
Kai Wang, Zekai Li, Zhi-Qi Cheng, Samir Khaki, Ahmad Sajedi, Ramakr- ishna Vedantam, Konstantinos N Plataniotis, Alexander Hauptmann, and Yang You. Emphasizing discriminative features for dataset distillation in complex scenarios. InProc. IEEE Conf. Comput. Vis. Pattern Recog., pages 30451–30461, 2025
2025
-
[25]
Dˆ 4: Dataset distillation via disentangled diffusion model
Duo Su, Junjie Hou, Weizhi Gao, Yingjie Tian, and Bowen Tang. Dˆ 4: Dataset distillation via disentangled diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5809–5818, 2024
2024
-
[26]
Generative dataset distillation: Balancing global structure and local details
Longzhen Li, Guang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. Generative dataset distillation: Balancing global structure and local details. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7664–7671, 2024
2024
-
[27]
Influence-guided diffusion for dataset distillation
Mingyang Chen, Jiawei Du, Bo Huang, Yi Wang, Xiaobo Zhang, and Wei Wang. Influence-guided diffusion for dataset distillation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Breaking class barriers: Efficient dataset distillation via inter-class feature compensator
Xin Zhang, Jiawei Du, Ping Liu, and Joey Tianyi Zhou. Breaking class barriers: Efficient dataset distillation via inter-class feature compensator. InProc. Int. Conf. Learn. Represent., 2025
2025
-
[29]
Rethinking large-scale dataset compression: Shifting focus from labels to images
Lingao Xiao, Songhua Liu, Yang He, and Xinchao Wang. Rethinking large-scale dataset compression: Shifting focus from labels to images. arXiv preprint arXiv:2502.06434, 2025
-
[30]
A label is worth a thousand images in dataset distillation
Tian Qin, Zhiwei Deng, and David Alvarez-Melis. A label is worth a thousand images in dataset distillation. InProc. Adv. Neural Inform. Process. Syst., 2024
2024
-
[31]
Ferkd: Surgical label adaptation for efficient distillation
Zhiqiang Shen. Ferkd: Surgical label adaptation for efficient distillation. InProc. Int. Conf. Comput. Vis., pages 1666–1675, 2023
2023
-
[32]
Label- augmented dataset distillation
Seoungyoon Kang, Youngsun Lim, and Hyunjung Shim. Label- augmented dataset distillation. InProc. IEEE Winter Conf. Appl. Comput. Vis., pages 1457–1466, 2025
2025
-
[33]
Teddy: Efficient large-scale dataset distillation via taylor-approximated matching
Ruonan Yu, Songhua Liu, Jingwen Ye, and Xinchao Wang. Teddy: Efficient large-scale dataset distillation via taylor-approximated matching. InProc. Eur. Conf. Comput. Vis., pages 1–17. Springer, 2025
2025
-
[34]
A fast knowledge distillation framework for visual recognition
Zhiqiang Shen and Eric Xing. A fast knowledge distillation framework for visual recognition. InProc. Eur. Conf. Comput. Vis., pages 673–690, 2022
2022
-
[35]
Dreaming to distill: Data-free knowledge transfer via deepinversion
Hongxu Yin, Pavlo Molchanov, Jose M Alvarez, Zhizhong Li, Arun Mallya, Derek Hoiem, Niraj K Jha, and Jan Kautz. Dreaming to distill: Data-free knowledge transfer via deepinversion. InProc. IEEE Conf. Comput. Vis. Pattern Recog., pages 8715–8724, 2020
2020
-
[36]
M3d: Dataset condensation by minimizing maximum mean discrepancy
Hansong Zhang, Shikun Li, Pengju Wang, Dan Zeng, and Shiming Ge. M3d: Dataset condensation by minimizing maximum mean discrepancy. InProc. AAAI Conf. Artif. Intell., pages 9314–9322, 2024
2024
-
[37]
Distributional dataset distillation with subtask decomposition
Tian Qin, Zhiwei Deng, and David Alvarez-Melis. Distributional dataset distillation with subtask decomposition. InICLR 2024 Workshop on Navigating and Addressing Data Problems for Foundation Models, 2024
2024
-
[38]
Multisize dataset condensation
Yang He, Lingao Xiao, Joey Tianyi Zhou, and Ivor Tsang. Multisize dataset condensation. InProc. Int. Conf. Learn. Represent., 2024
2024
-
[39]
Annealing knowledge distillation
Aref Jafari, Mehdi Rezagholizadeh, Pranav Sharma, and Ali Ghodsi. Annealing knowledge distillation. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2493–2504, 2021
2021
-
[40]
An overview of statistical learning theory.IEEE transactions on neural networks, 10(5):988–999, 1999
Vladimir N Vapnik. An overview of statistical learning theory.IEEE transactions on neural networks, 10(5):988–999, 1999
1999
-
[41]
Improved knowledge distillation via teacher assistant
Seyed Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Nir Levine, Akihiro Matsukawa, and Hassan Ghasemzadeh. Improved knowledge distillation via teacher assistant. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 5191–5198, 2020
2020
-
[42]
Unifying distillation and privileged information
David Lopez-Paz, Léon Bottou, Bernhard Schölkopf, and Vladimir Vapnik. Unifying distillation and privileged information. InProc. Int. Conf. Learn. Represent., 2016
2016
-
[43]
Imagenet-21k pretraining for the masses
Tal Ridnik, Emanuel Ben-Baruch, Asaf Noy, and Lihi Zelnik-Manor. Imagenet-21k pretraining for the masses. InNeurIPS Benchmarks Track (Round 1), 2021
2021
-
[44]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProc. IEEE Conf. Comput. Vis. Pattern Recog., pages 770–778, 2016
2016
-
[45]
Randaugment: Practical automated data augmentation with a reduced search space
Ekin Dogus Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. 2020 ieee. InCVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 3008–3017, 2019
2020
-
[46]
Pytorch image models
Ross Wightman. Pytorch image models. https://github.com/rwightman/ pytorch-image-models, 2019
2019
-
[47]
Efficient dataset distillation via minimax diffusion
Jianyang Gu, Saeed Vahidian, Vyacheslav Kungurtsev, Haonan Wang, Wei Jiang, Yang You, and Yiran Chen. Efficient dataset distillation via minimax diffusion. InProc. IEEE Conf. Comput. Vis. Pattern Recog., 2024
2024
-
[48]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InProc. Int. Conf. Mach. Learn., pages 6105–6114. PMLR, 2019
2019
-
[49]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. InProc. IEEE Conf. Comput. Vis. Pattern Recog., pages 4510–4520, 2018
2018
-
[50]
Swin transformer v2: Scaling up capacity and resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12009– 12019, 2022
2022
-
[51]
Improved Regularization of Convolutional Neural Networks with Cutout
Terrance DeVries and Graham W Taylor. Improved regularization of con- volutional neural networks with cutout.arXiv preprint arXiv:1708.04552, 2017
work page internal anchor Pith review arXiv 2017
-
[52]
Distilling the knowledge in data pruning.arXiv preprint arXiv:2403.07854, 2024
Emanuel Ben-Baruch, Adam Botach, Igor Kviatkovsky, Manoj Aggarwal, and Gérard Medioni. Distilling the knowledge in data pruning.arXiv preprint arXiv:2403.07854, 2024. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, FEB 2026 13 APPENDIXA THEORETICALMOTIVATION FORLOWSTUDENTTEMPERATURE A. Optimal Logit-Temperature Relationship Let P be the qu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.