Recognition: unknown
AQPIM: Breaking the PIM Capacity Wall for LLMs with In-Memory Activation Quantization
Pith reviewed 2026-05-10 04:05 UTC · model grok-4.3
The pith
By running product quantization inside memory, AQPIM compresses LLM activations enough to fit within PIM hardware limits and enables direct computation on the compact form.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
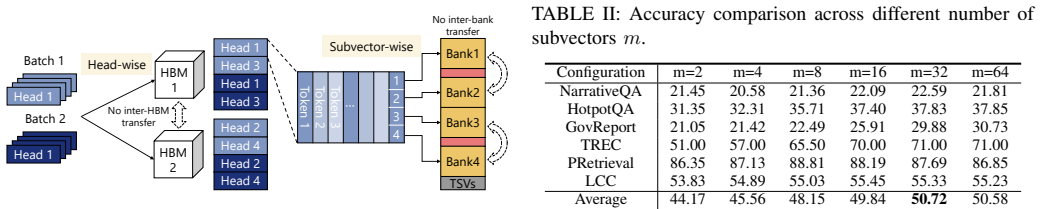
AQPIM is a PIM-aware activation quantization framework based on product quantization that performs the clustering and indexing steps entirely inside memory, introduces algorithmic adjustments to keep accuracy acceptable for LLMs, and thereby shrinks the activation footprint while allowing attention to operate directly on the compressed representations.
What carries the argument
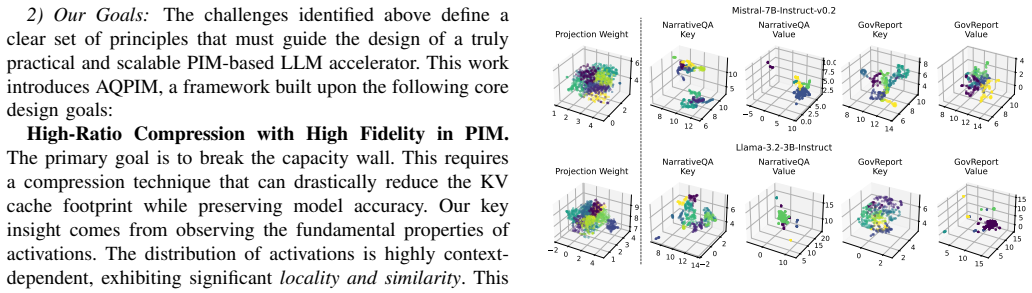
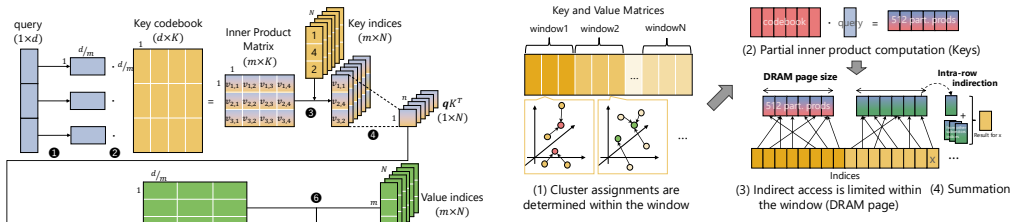
Product quantization executed in-memory on activation vectors, where learned codebooks replace each vector with a short index so that approximate inner products can be computed without restoring the original values.
If this is right
- GPU-CPU communication that currently accounts for 90 to 98.5 percent of decoding latency drops sharply.
- Overall inference reaches 3.4 times the speed of prior state-of-the-art PIM methods for the same models.
- Larger KV caches fit inside fixed PIM memory capacity, supporting longer context lengths.
- Attention operations execute directly on the compressed indices, avoiding full decompression overhead.
Where Pith is reading between the lines
- The same in-memory compression pattern could be reused for other memory-capacity-limited PIM workloads such as large graph analytics.
- PIM chip designers may add dedicated codebook lookup units as a standard on-die feature rather than leaving quantization to software.
- Pairing AQPIM-style quantization with sparsity patterns that preserve data locality could produce further efficiency gains beyond what either technique achieves alone.
Load-bearing premise
The accuracy loss from clustering-based product quantization on LLM activations stays small enough when the whole process runs inside memory that downstream model quality does not degrade noticeably.
What would settle it
Measure end-to-end accuracy of a standard LLM on a benchmark such as MMLU after replacing all activations with AQPIM-quantized versions and observe whether the score falls more than 1-2 percent below the full-precision baseline, or profile actual data-transfer volume and find no reduction in the claimed 90-98.5 percent range.
Figures











read the original abstract
Processing-in-Memory (PIM) architectures offer a promising solution to the memory bottlenecks in data-intensive machine learning, yet often overlook the growing challenge of activation memory footprint. Conventional PIM approaches struggle with massive KV cache sizes generated in long-context scenarios by Transformer-based models, frequently exceeding PIM's limited memory capacity, while techniques like sparse attention can conflict with PIM's need for data locality. Existing PIM approaches and quantization methods are often insufficient or poorly suited for leveraging the unique characteristics of activations. This work identifies an opportunity for PIM-specialized activation quantization to enhance bandwidth and compute efficiency. We explore clustering-based vector quantization approaches, which align well with activation characteristics and PIM's internal bandwidth capabilities. Building on this, we introduce AQPIM, a novel PIM-aware activation quantization framework based on Product Quantization (PQ), optimizing it for modern Large Language Models (LLMs). By performing quantization directly within memory, AQPIM leverages PIM's high internal bandwidth and enables direct computation on compressed data, significantly reducing both memory footprint and computational overhead for attention computation. AQPIM addresses PQ's accuracy challenges by introducing several algorithmic optimizations. Evaluations demonstrate that AQPIM achieves significant performance improvements, drastically reducing of GPU-CPU communication that can account for 90$\sim$98.5\% of decoding latency, together with 3.4$\times$ speedup over a SOTA PIM approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce AQPIM, a PIM-aware activation quantization framework based on Product Quantization (PQ) optimized for LLMs. By performing quantization and computation directly in memory, it reduces activation memory footprint, enables direct computation on compressed data, and minimizes GPU-CPU communication (claimed to account for 90-98.5% of decoding latency), achieving a 3.4× speedup over a state-of-the-art PIM approach.
Significance. If the quantization maintains acceptable model quality, this could meaningfully advance PIM architectures for long-context LLM inference by addressing activation capacity limits that exceed PIM memory and conflict with data locality requirements. The in-memory focus leverages PIM's internal bandwidth advantages and could inform hardware-software co-design for efficient inference.
major comments (2)
- The abstract reports performance gains and latency reductions from evaluations but provides no details on accuracy metrics, baselines, error bars, or data selection. This leaves the central empirical claim only partially supported without further evidence.
- The assumption that clustering-based product quantization (with unspecified algorithmic optimizations) produces activation representations whose error does not materially degrade attention or generation quality is not validated. Activations in long-context Transformers exhibit heavy-tailed distributions and high sensitivity in the attention softmax; without quantitative results on perplexity impact or quality loss, the reported communication reduction and speedup cannot be assessed for practical utility.
minor comments (1)
- The abstract contains a grammatical error in 'drastically reducing of GPU-CPU communication' which should be corrected to 'drastically reducing GPU-CPU communication'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the presentation of our empirical results and the validation of AQPIM's quantization effects. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The abstract reports performance gains and latency reductions from evaluations but provides no details on accuracy metrics, baselines, error bars, or data selection. This leaves the central empirical claim only partially supported without further evidence.
Authors: We agree that the abstract would be strengthened by including these details. In the revised version, we will expand the abstract to reference the accuracy metrics (perplexity and generation quality), the specific baselines and models evaluated, the use of multiple runs with reported standard deviations, and the datasets/context lengths used. The main text already contains the full evaluation setup and results; the abstract revision will ensure the central claims are better supported at a glance. revision: yes
-
Referee: The assumption that clustering-based product quantization (with unspecified algorithmic optimizations) produces activation representations whose error does not materially degrade attention or generation quality is not validated. Activations in long-context Transformers exhibit heavy-tailed distributions and high sensitivity in the attention softmax; without quantitative results on perplexity impact or quality loss, the reported communication reduction and speedup cannot be assessed for practical utility.
Authors: We acknowledge the need for explicit validation given the characteristics of LLM activations. Section 5 of the manuscript already reports perplexity results across LLaMA and other models for varying context lengths, showing limited degradation, along with the algorithmic optimizations in Section 4 that target attention computation. To directly address concerns about heavy-tailed distributions and softmax sensitivity, we will add a new subsection with quantitative analysis of attention score distributions and quality loss metrics in the revision. revision: partial
Circularity Check
No circularity in derivation or claims
full rationale
The paper introduces AQPIM as a PIM-aware framework that applies product quantization to LLM activations with unspecified algorithmic optimizations to address accuracy. All load-bearing claims (90-98.5% communication reduction, 3.4× speedup) are presented as outcomes of experimental evaluation on hardware and models rather than quantities derived from equations, fitted parameters, or self-citations within the work. No self-definitional steps, fitted-input predictions, or uniqueness theorems appear; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PIM hardware provides sufficiently high internal bandwidth and supports the operations needed for in-memory quantization and computation on compressed activations.
Reference graph
Works this paper leans on
-
[1]
Keyformer: Kv cache reduction through key tokens selection for efficient generative inference,
M. Adnan, A. Arunkumar, G. Jain, P. Nair, I. Soloveychik, and P. Ka- math, “Keyformer: Kv cache reduction through key tokens selection for efficient generative inference,”Proceedings of Machine Learning and Systems, vol. 6, pp. 114–127, 2024
2024
-
[2]
LongBench: A bilingual, multitask benchmark for long context understanding,
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y . Dong, J. Tang, and J. Li, “LongBench: A bilingual, multitask benchmark for long context understanding,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bang...
2024
-
[3]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long- document transformer,”arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[4]
Scaling transformer to 1m tokens and beyond with rmt.arXiv preprint arXiv:2304.11062, 2023
A. Bulatov, Y . Kuratov, Y . Kapushev, and M. S. Burtsev, “Scaling transformer to 1m tokens and beyond with rmt,” 2024. [Online]. Available: https://arxiv.org/abs/2304.11062
-
[5]
W. Chen, X. Ma, X. Wang, and W. W. Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,(2022),”arXiv preprint arXiv:2211.12588, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,
Y .-H. Chen, T.-J. Yang, J. Emer, and V . Sze, “Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,”IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9, no. 2, pp. 292–308, 2019
2019
-
[7]
Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory,
P. Chi, S. Li, C. Xu, T. Zhang, J. Zhao, Y . Liu, Y . Wang, and Y . Xie, “Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory,”ACM SIGARCH Computer Architecture News, vol. 44, no. 3, pp. 27–39, 2016
2016
-
[8]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, and I. Sutskever, “Generating long sequences with sparse transformers,”arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review arXiv 1904
-
[9]
Asap7: A 7-nm finfet predictive process design kit,
L. T. Clark, V . Vashishtha, L. Shifren, A. Gujja, S. Sinha, B. Cline, C. Ramamurthy, and G. Yeric, “Asap7: A 7-nm finfet predictive process design kit,”Microelectronics Journal, vol. 53, pp. 105–115, 2016. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S002626921630026X
2016
-
[10]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” in Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 16 344–16 359. [Online]. Available: https://proceedings.neuri...
2022
-
[11]
SKVQ: Sliding-window key and value cache quantization for large language models,
H. Duanmu, Z. Yuan, X. Li, J. Duan, X. ZHANG, and D. Lin, “SKVQ: Sliding-window key and value cache quantization for large language models,” inFirst Conference on Language Modeling, 2024. [Online]. Available: https://openreview.net/forum?id=nI6JyFSnyV
2024
-
[12]
Neural cache: Bit-serial in-cache acceleration of deep neural networks,
C. Eckert, X. Wang, J. Wang, A. Subramaniyan, R. Iyer, D. Sylvester, D. Blaaauw, and R. Das, “Neural cache: Bit-serial in-cache acceleration of deep neural networks,” in2018 ACM/IEEE 45Th annual international symposium on computer architecture (ISCA). IEEE, 2018, pp. 383–396
2018
-
[13]
Mvc: Enabling fully coherent multi-data-views through the memory hierarchy with processing in memory,
D. Fujiki, “Mvc: Enabling fully coherent multi-data-views through the memory hierarchy with processing in memory,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, 2023, pp. 800–814
2023
-
[14]
Duality cache for data parallel acceleration,
D. Fujiki, S. Mahlke, and R. Das, “Duality cache for data parallel acceleration,” inProceedings of the 46th International Symposium on Computer Architecture, 2019, pp. 397–410
2019
-
[15]
Fujiki, X
D. Fujiki, X. Wang, A. Subramaniyan, and R. Das,In-/near-memory Computing. Springer, 2021
2021
-
[16]
Pal: Program-aided language models,
L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y . Yang, J. Callan, and G. Neubig, “Pal: Program-aided language models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 10 764–10 799
2023
-
[17]
A survey of quantization methods for efficient neural network infer- ence,
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network infer- ence,” inLow-power computer vision. Chapman and Hall/CRC, 2022, pp. 291–326
2022
-
[18]
ToRA: A tool-integrated reasoning agent for mathe- matical problem solving,
Z. Gou, Z. Shao, Y . Gong, yelong shen, Y . Yang, M. Huang, N. Duan, and W. Chen, “ToRA: A tool-integrated reasoning agent for mathe- matical problem solving,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[19]
The llama 3 herd of models,
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Ma...
-
[20]
[Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Ramulator2.0,
S. R. Group, “Ramulator2.0,” 2023, https://github.com/CMU-SAFARI/ ramulator2
2023
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects,
M. U. Hadi, R. Qureshi, A. Shah, M. Irfan, A. Zafar, M. B. Shaikh, N. Akhtar, J. Wu, S. Mirjaliliet al., “Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects,”Authorea Preprints, vol. 1, pp. 1–26, 2023
2023
-
[24]
Zipcache: Accurate and efficient KV cache quantization with salient token identification,
Y . He, L. Zhang, W. Wu, J. Liu, H. Zhou, and B. Zhuang, “Zipcache: Accurate and efficient KV cache quantization with salient token identification,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=5t4ZAkPiJs
2024
-
[25]
Neupims: Npu-pim heterogeneous acceleration for batched llm inferencing,
G. Heo, S. Lee, J. Cho, H. Choi, S. Lee, H. Ham, G. Kim, D. Mahajan, and J. Park, “Neupims: Npu-pim heterogeneous acceleration for batched llm inferencing,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS ’24. New York, NY , USA: Association for Computin...
-
[26]
Squeezed attention: Accelerating long context length llm inference,
C. Hooper, S. Kim, H. Mohammadzadeh, M. Maheswaran, S. Zhao, J. Paik, M. W. Mahoney, K. Keutzer, and A. Gholami, “Squeezed attention: Accelerating long context length llm inference,” 2025. [Online]. Available: https://arxiv.org/abs/2411.09688
-
[27]
Kvquant: Towards 10 million context length llm inference with kv cache quantization,
C. Hooper, S. Kim, H. Mohammadzadeh, M. W. Mahoney, Y . S. Shao, K. Keutzer, and A. Gholami, “Kvquant: Towards 10 million context length llm inference with kv cache quantization,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2...
2024
-
[28]
M-ant: Efficient low-bit group quantization for llms via mathematically adaptive numerical type,
W. Hu, H. Zhang, C. Guo, Y . Feng, R. Guan, Z. Hua, Z. Liu, Y . Guan, M. Guo, and J. Leng, “M-ant: Efficient low-bit group quantization for llms via mathematically adaptive numerical type,”arXiv preprint arXiv:2502.18755, 2025
-
[29]
Efficient attentions for long document summarization,
L. Huang, S. Cao, N. Parulian, H. Ji, and L. Wang, “Efficient attentions for long document summarization,” inProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Cha...
2021
-
[30]
Available: https://aclanthology.org/2021.naacl-main.112/
[Online]. Available: https://aclanthology.org/2021.naacl-main.112/
2021
-
[31]
Energy and AI – analysis
IEA. Energy and AI – analysis. [Online]. Available: https://www.iea. org/reports/energy-and-ai
-
[32]
Intel xeon platinum 8480+ processor,
Intel, “Intel xeon platinum 8480+ processor,” 2023, https: //www.intel.com/content/www/us/en/products/sku/231746/intel-xeon- platinum-8480-processor-105m-cache-2-00-ghz/specifications.html
2023
-
[33]
High bandwidth memory dram (hbm3),
JEDEC, “High bandwidth memory dram (hbm3),” 2022
2022
-
[34]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention,
H. Jiang, Y . Li, C. Zhang, Q. Wu, X. Luo, S. Ahn, Z. Han, A. Abdi, D. Li, C.-Y . Linet al., “Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention,”Advances in Neural Information Processing Systems, vol. 37, pp. 52 481–52 515, 2024
2024
-
[36]
Product quantization for nearest neighbor search,
H. Jégou, M. Douze, and C. Schmid, “Product quantization for nearest neighbor search,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 1, pp. 117–128, 2011
2011
-
[37]
Aquabolt-xl: Samsung hbm2-pim with in- memory processing for ml accelerators and beyond,
J. H. Kim, S.-h. Kang, S. Lee, H. Kim, W. Song, Y . Ro, S. Lee, D. Wang, H. Shin, B. Phuahet al., “Aquabolt-xl: Samsung hbm2-pim with in- memory processing for ml accelerators and beyond,” in2021 IEEE Hot Chips 33 Symposium (HCS). IEEE, 2021, pp. 1–26
2021
-
[38]
Ramulator: A fast and extensible dram simulator,
Y . Kim, W. Yang, and O. Mutlu, “Ramulator: A fast and extensible dram simulator,”IEEE Comput. Archit. Lett., vol. 15, no. 1, p. 45–49, Jan
-
[39]
Available: https://doi.org/10.1109/LCA.2015.2414456
[Online]. Available: https://doi.org/10.1109/LCA.2015.2414456
-
[40]
The NarrativeQA reading comprehension challenge,
T. Ko ˇciský, J. Schwarz, P. Blunsom, C. Dyer, K. M. Hermann, G. Melis, and E. Grefenstette, “The NarrativeQA reading comprehension challenge,”Transactions of the Association for Computational Linguistics, vol. 6, pp. 317–328, 2018. [Online]. Available: https://aclanthology.org/Q18-1023/
2018
-
[41]
Hardware architecture and software stack for pim based on commercial dram technology: Industrial product,
S. Lee, S.-h. Kang, J. Lee, H. Kim, E. Lee, S. Seo, H. Yoon, S. Lee, K. Lim, H. Shinet al., “Hardware architecture and software stack for pim based on commercial dram technology: Industrial product,” in 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 43–56
2021
-
[42]
Hardware architecture and software stack for pim based on commercial dram technology : Industrial product,
S. Lee, S.-h. Kang, J. Lee, H. Kim, E. Lee, S. Seo, H. Yoon, S. Lee, K. Lim, H. Shin, J. Kim, O. Seongil, A. Iyer, D. Wang, K. Sohn, and N. S. Kim, “Hardware architecture and software stack for pim based on commercial dram technology : Industrial product,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021, pp. 43–56
2021
-
[43]
SnapKV: LLM knows what you are looking for before generation,
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen, “SnapKV: LLM knows what you are looking for before generation,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=poE54GOq2l
2024
-
[44]
Duquant: Distributing outliers via dual transformation makes stronger quantized LLMs,
H. Lin, H. Xu, Y . Wu, J. Cui, Y . Zhang, L. Mou, L. Song, Z. Sun, and Y . Wei, “Duquant: Distributing outliers via dual transformation makes stronger quantized LLMs,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=mp8u2Pcmqz
2024
-
[45]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving
Y . Lin*, H. Tang*, S. Yang*, Z. Zhang, G. Xiao, C. Gan, and S. Han, “Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,”arXiv preprint arXiv:2405.04532, 2024
-
[46]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval, December 2024
D. Liu, M. Chen, B. Lu, H. Jiang, Z. Han, Q. Zhang, Q. Chen, C. Zhang, B. Ding, K. Zhanget al., “Retrievalattention: Accelerating long-context llm inference via vector retrieval,”arXiv preprint arXiv:2409.10516, 2024
-
[48]
G. Liu, C. Li, J. Zhao, C. Zhang, and M. Guo, “Clusterkv: Manipulating llm kv cache in semantic space for recallable compression,” 2024. [Online]. Available: https://arxiv.org/abs/2412.03213
-
[49]
S2ta: Exploiting structured sparsity for energy-efficient mobile cnn acceleration,
Z.-G. Liu, P. N. Whatmough, Y . Zhu, and M. Mattina, “S2ta: Exploiting structured sparsity for energy-efficient mobile cnn acceleration,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2022, pp. 573–586
2022
-
[50]
Kivi: a tuning-free asymmetric 2bit quantization for kv cache,
Z. Liu, J. Yuan, H. Jin, S. H. Zhong, Z. Xu, V . Braverman, B. Chen, and X. Hu, “Kivi: a tuning-free asymmetric 2bit quantization for kv cache,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[51]
Ramulator 2.0: A modern, modular, and extensible dram simulator,
H. Luo, Y . C. Tu ˘grul, F. N. Bostancı, A. Olgun, A. G. Ya ˘glıkçı, and O. Mutlu, “Ramulator 2.0: A modern, modular, and extensible dram simulator,”IEEE Comput. Archit. Lett., vol. 23, no. 1, p. 112–116, Jan
-
[52]
Nisa Bostancı, Ataberk Olgun, A
[Online]. Available: https://doi.org/10.1109/LCA.2023.3333759
-
[53]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,” 2020. [Online]. Available: https://arxiv.org/abs/1802.03426
work page internal anchor Pith review arXiv 2020
-
[54]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” inInternational Conference on Learning Representations, 2017. [Online]. Available: https://openreview.net/ forum?id=Byj72udxe
2017
-
[55]
Nvidia h100 tensor core gpu,
NVIDIA, “Nvidia h100 tensor core gpu,” 2024, https://arc.net/l/quote/ btwhvenw
2024
-
[56]
OpenAI, “Models,” 2024, https://platform.openai.com/docs/models/gpt- 4o
2024
-
[57]
Transformers are multi-state RNNs , 2024
M. Oren, M. Hassid, N. Yarden, Y . Adi, and R. Schwartz, “Transformers are multi-state rnns,”arXiv preprint arXiv:2401.06104, 2024
-
[58]
Scnn: An accelerator for compressed-sparse convolutional neural networks,
A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. Venkatesan, B. Khailany, J. Emer, S. W. Keckler, and W. J. Dally, “Scnn: An accelerator for compressed-sparse convolutional neural networks,”ACM SIGARCH computer architecture news, vol. 45, no. 2, pp. 27–40, 2017
2017
-
[59]
attacc_simulator,
J. Park and J. Choi, “attacc_simulator,” 2024, https://github.com/scale- snu/attacc_simulator
2024
-
[60]
Attacc! unleashing the power of pim for batched transformer- based generative model inference,
J. Park, J. Choi, K. Kyung, M. J. Kim, Y . Kwon, N. S. Kim, and J. H. Ahn, “Attacc! unleashing the power of pim for batched transformer- based generative model inference,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’24. New York, NY , USA: Associati...
-
[61]
Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,
A. Shafiee, A. Nag, N. Muralimanohar, R. Balasubramonian, J. P. Stra- chan, M. Hu, R. S. Williams, and V . Srikumar, “Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,” ACM SIGARCH Computer Architecture News, vol. 44, no. 3, pp. 14–26, 2016
2016
-
[62]
Omniquant: Omnidirectionally calibrated quantization for large language models,
W. Shao, M. Chen, Z. Zhang, P. Xu, L. Zhao, Z. Li, K. Zhang, P. Gao, Y . Qiao, and P. Luo, “Omniquant: Omnidirectionally calibrated quantization for large language models,” inICLR, 2024. [Online]. Available: https://openreview.net/forum?id=8Wuvhh0LYW
2024
-
[63]
FlexGen: High-throughput generative inference of large language models with a single GPU,
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, P. Liang, C. Re, I. Stoica, and C. Zhang, “FlexGen: High-throughput generative inference of large language models with a single GPU,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhard...
2023
-
[64]
Sze, Y .-H
V . Sze, Y .-H. Chen, T.-J. Yang, and J. S. Emer,Efficient processing of deep neural networks. Springer, 2020
2020
-
[65]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wang, S. Mariooryad, Y . Ding, X. Geng, F. Alcober, R. Frostig, M. Omernick, L. Walker, C. Paduraru, C. Sorokin, A. Tacchetti, C. Gaffney, S. Daruki, O. Sercinoglu, Z. Gleicher, J. Love, P. V oigtlaender, R. Jain, G. Surita, K. Mohamed, R. Blevins, J. Ahn, T...
work page internal anchor Pith review arXiv 2024
-
[66]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[67]
Memorizing transformers,
Y . Wu, M. N. Rabe, D. Hutchins, and C. Szegedy, “Memorizing transformers,” inInternational Conference on Learning Representations,
-
[68]
Available: https://openreview.net/forum?id=TrjbxzRcnf-
[Online]. Available: https://openreview.net/forum?id=TrjbxzRcnf-
-
[69]
Smoothquant: accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: accurate and efficient post-training quantization for large language models,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023
2023
-
[70]
Efficient streaming language models with attention sinks,
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=NG7sS51zVF
2024
-
[71]
Online product quantization,
D. Xu, I. W. Tsang, and Y . Zhang, “Online product quantization,”IEEE Transactions on Knowledge and Data Engineering, vol. 30, no. 11, pp. 2185–2198, 2018
2018
-
[72]
Native sparse attention: Hardware-aligned and natively trainable sparse attention
J. Yuan, H. Gao, D. Dai, J. Luo, L. Zhao, Z. Zhang, Z. Xie, Y . X. Wei, L. Wang, Z. Xiao, Y . Wang, C. Ruan, M. Zhang, W. Liang, and W. Zeng, “Native sparse attention: Hardware-aligned and natively trainable sparse attention,” 2025. [Online]. Available: https://arxiv.org/abs/2502.11089
-
[73]
Gobo: Quan- tizing attention-based nlp models for low latency and energy efficient inference,
A. H. Zadeh, I. Edo, O. M. Awad, and A. Moshovos, “Gobo: Quan- tizing attention-based nlp models for low latency and energy efficient inference,” in2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020, pp. 811–824
2020
-
[74]
Thermometer: profile-guided btb replacement for data center applications,
A. H. Zadeh, M. Mahmoud, A. Abdelhadi, and A. Moshovos, “Mokey: enabling narrow fixed-point inference for out-of-the-box floating-point transformer models,” inProceedings of the 49th Annual International Symposium on Computer Architecture, ser. ISCA ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 888–901. [Online]. Available: https:...
-
[75]
Big bird: Transformers for longer sequences,
M. Zaheer, G. Guruganesh, K. A. Dubey, J. Ainslie, C. Alberti, S. Ontanon, P. Pham, A. Ravula, Q. Wang, L. Yanget al., “Big bird: Transformers for longer sequences,”Advances in neural information processing systems, vol. 33, pp. 17 283–17 297, 2020
2020
- [76]
-
[77]
Pqcache: Product quantization-based kvcache for long context llm inference,
H. Zhang, X. Ji, Y . Chen, F. Fu, X. Miao, X. Nie, W. Chen, and B. Cui, “Pqcache: Product quantization-based kvcache for long context llm inference,” 2024. [Online]. Available: https://arxiv.org/abs/2407.12820
-
[78]
Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization,
T. Zhang, J. Yi, Z. Xu, and A. Shrivastava, “Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 3304–3331. [Online]. Avail...
2024
-
[79]
H2o: Heavy-hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. Re, C. Barrett, Z. Wang, and B. Chen, “H2o: Heavy-hitter oracle for efficient generative inference of large language models,” inThirty-seventh Conference on Neural Information Processing Systems, 2023. [Online]. Available: https: //openreview.net/forum?id=RkRrPp7GKO
2023
-
[80]
Atom: Low-bit quantization for efficient and accurate llm serving,
Y . Zhao, C.-Y . Lin, K. Zhu, Z. Ye, L. Chen, S. Zheng, L. Ceze, A. Krishnamurthy, T. Chen, and B. Kasikci, “Atom: Low-bit quantization for efficient and accurate llm serving,”Proceedings of Machine Learning and Systems, vol. 6, pp. 196–209, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.