Recognition: unknown
Distributional Off-Policy Evaluation with Deep Quantile Process Regression
Pith reviewed 2026-05-10 04:07 UTC · model grok-4.3
The pith
A quantile-based method estimates the full return distribution in off-policy evaluation using the same number of samples needed for the expected value alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
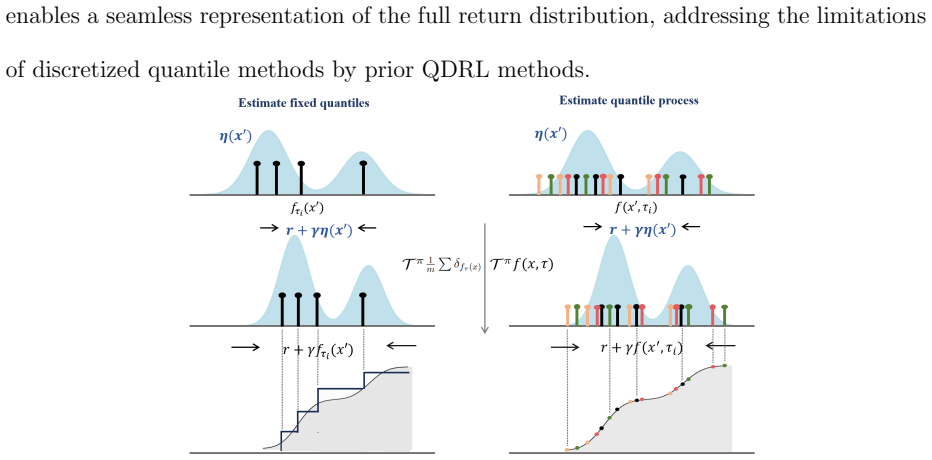
The paper presents DQPOPE which applies deep quantile process regression to off-policy evaluation, extending from discrete to continuous quantile functions, and establishes sample complexity bounds that allow estimating the full return distribution with the sample size sufficient for estimating a single policy value under conventional approaches.
What carries the argument
Deep quantile process regression for modeling continuous quantile functions of the return distribution in Markov decision processes.
If this is right
- DQPOPE enables estimation of risk-sensitive metrics like value-at-risk from the same data.
- Policy selection can incorporate distributional information for more robust choices.
- The theoretical bounds support using deep networks without losing statistical efficiency.
- Practical implementations can achieve better performance in environments with high variance returns.
Where Pith is reading between the lines
- If the method scales well, it could be integrated into existing RL libraries to improve evaluation modules.
- Further work might explore combining this with other distributional RL techniques like distributional Bellman operators.
- Applications in high-stakes domains such as healthcare or finance could benefit from full distribution estimates.
Load-bearing premise
The assumptions on the Markov decision process and the function approximation allow the deep quantile process to converge to the true continuous quantile function at the claimed rates.
What would settle it
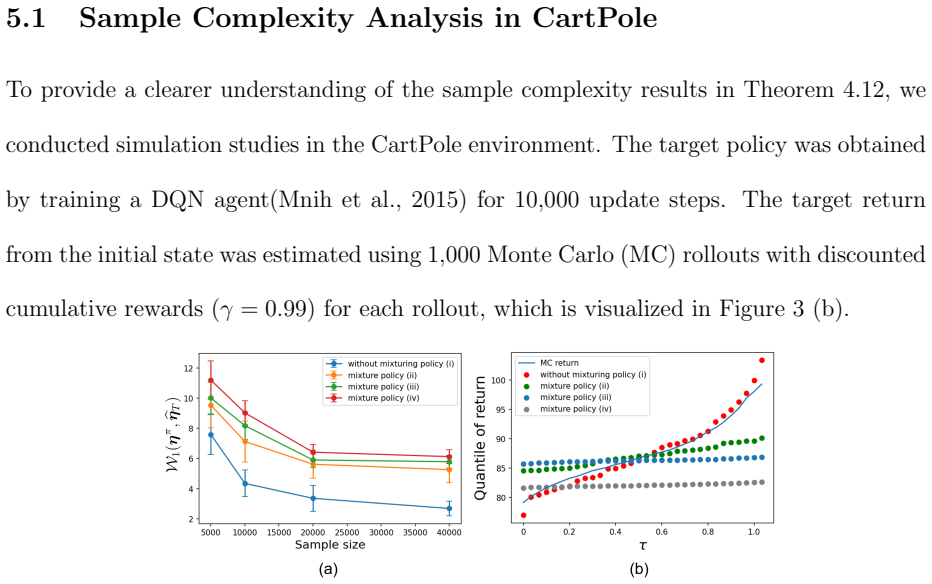
Running DQPOPE and standard OPE on a simple MDP with known return distribution and checking if the sample size needed for accurate distribution estimates matches that for the mean, or if the estimated quantiles deviate significantly from ground truth.
Figures











read the original abstract
This paper investigates the off-policy evaluation (OPE) problem from a distributional perspective. Rather than focusing solely on the expectation of the total return, as in most existing OPE methods, we aim to estimate the entire return distribution. To this end, we introduce a quantile-based approach for OPE using deep quantile process regression, presenting a novel algorithm called Deep Quantile Process regression-based Off-Policy Evaluation (DQPOPE). We provide new theoretical insights into the deep quantile process regression technique, extending existing approaches that estimate discrete quantiles to estimate a continuous quantile function. A key contribution of our work is the rigorous sample complexity analysis for distributional OPE with deep neural networks, bridging theoretical analysis with practical algorithmic implementations. We show that DQPOPE achieves statistical advantages by estimating the full return distribution using the same sample size required to estimate a single policy value using conventional methods. Empirical studies further show that DQPOPE provides significantly more precise and robust policy value estimates than standard methods, thereby enhancing the practical applicability and effectiveness of distributional reinforcement learning approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DQPOPE, a distributional off-policy evaluation algorithm based on deep quantile process regression. It extends discrete quantile estimation to continuous quantile functions and provides sample complexity bounds claiming that the full return distribution can be estimated with the same number of samples required for conventional mean-based OPE. Empirical results are presented showing improved precision and robustness over standard methods.
Significance. If the uniform convergence rates for the continuous quantile process hold under the stated MDP and function approximation assumptions, the result would strengthen the theoretical foundation for distributional OPE by showing no asymptotic sample penalty for estimating the full distribution versus the mean. This could influence practical algorithm design in RL by enabling richer distributional information at conventional OPE costs.
major comments (2)
- [§4 (sample complexity analysis)] The central sample complexity claim (abstract and §4) that full distributional estimation requires only the sample size for scalar mean estimation rests on uniform control of the quantile process error over τ ∈ [0,1]. The analysis must explicitly derive or cite the chaining/empirical process bound that prevents covering-number growth with the quantile index set from introducing extra log(1/ε) or discretization factors; without this, the stated bound reduces to a pointwise or grid-based result that does not support the 'same sample size' advantage.
- [§3.2 / Theorem on continuous quantile regression] Theorem establishing the extension from discrete to continuous quantile process regression (likely §3.2 or 4.1) assumes the deep network approximation error remains controlled uniformly in τ. The proof sketch should clarify whether the Lipschitz or smoothness assumptions on the quantile function are sufficient to absorb the sup-norm without additional sample overhead, as standard DNN covering numbers scale with the effective dimension of the quantile index.
minor comments (2)
- [§2 / §3] Notation for the quantile process (e.g., definition of the continuous τ-indexed estimator) should be introduced earlier and used consistently to avoid ambiguity between discrete-grid and continuous-function versions.
- [§5] Empirical section would benefit from explicit reporting of the number of independent runs and confidence intervals on the reported precision/robustness gains to allow direct comparison with baseline OPE methods.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable feedback. We are pleased that the significance of our work is recognized. We address the major comments below and plan to incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§4 (sample complexity analysis)] The central sample complexity claim (abstract and §4) that full distributional estimation requires only the sample size for scalar mean estimation rests on uniform control of the quantile process error over τ ∈ [0,1]. The analysis must explicitly derive or cite the chaining/empirical process bound that prevents covering-number growth with the quantile index set from introducing extra log(1/ε) or discretization factors; without this, the stated bound reduces to a pointwise or grid-based result that does not support the 'same sample size' advantage.
Authors: We agree that an explicit treatment of the uniform convergence over the quantile index is essential to substantiate the sample complexity claim. In our analysis in Section 4, we utilize standard results from empirical process theory for quantile processes, including chaining bounds that account for the continuity in τ. The Lipschitz assumption on the quantile function ensures that the covering number for the index set [0,1] contributes only a constant factor, not additional logarithmic terms in the sample complexity. To address the concern directly, we will revise the manuscript to include a self-contained derivation of the relevant chaining bound in an appendix, citing the appropriate empirical process literature (e.g., van der Vaart and Wellner) to make the absence of extra factors transparent. This revision will strengthen the presentation without altering the core result. revision: yes
-
Referee: [§3.2 / Theorem on continuous quantile regression] Theorem establishing the extension from discrete to continuous quantile process regression (likely §3.2 or 4.1) assumes the deep network approximation error remains controlled uniformly in τ. The proof sketch should clarify whether the Lipschitz or smoothness assumptions on the quantile function are sufficient to absorb the sup-norm without additional sample overhead, as standard DNN covering numbers scale with the effective dimension of the quantile index.
Authors: The theorem in Section 3.2 extends discrete quantile estimation by modeling the quantile function as a continuous process in τ. The uniform control of the approximation error is achieved by leveraging the assumed smoothness (Lipschitz continuity in τ) of the target quantile function, which allows discretization of [0,1] with a grid size that does not depend on the error tolerance ε in a way that increases sample complexity. The deep neural network is trained to approximate the joint function over state and τ, and the covering number analysis incorporates the τ dimension but remains bounded due to the process structure. We will expand the proof sketch in the revision to explicitly show the steps where the sup-norm is bounded without incurring additional overhead, including how the effective dimension is handled. This clarification will be added to ensure the uniform bound is rigorously justified. revision: yes
Circularity Check
No circularity: derivation chain self-contained under stated assumptions
full rationale
The paper introduces DQPOPE via deep quantile process regression as a novel extension from discrete to continuous quantile functions, with a claimed rigorous sample-complexity analysis for distributional OPE. The central statistical-advantage claim (full return distribution at same n as scalar mean) is presented as following from new theoretical insights and standard MDP/function-approximation assumptions rather than reducing to fitted parameters, self-definitions, or unverified self-citations. No quoted steps exhibit self-definitional equivalence, renaming of known results, or load-bearing self-citation chains that collapse the derivation to its inputs by construction. The analysis is therefore treated as independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Annals of Applied Statistics , volume=
A Bayesian decision framework for optimizing sequential combination antiretroviral therapy in people with HIV , author=. The Annals of Applied Statistics , volume=. 2023 , publisher=
2023
-
[2]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[3]
The Annals of Probability , volume=
Concentration inequalities using the entropy method , author=. The Annals of Probability , volume=. 2003 , publisher=
2003
-
[4]
The Annals of Statistics , volume=
LOCAL RADEMACHER COMPLEXITIES , author=. The Annals of Statistics , volume=
-
[5]
International Conference on Machine Learning , pages=
Risk bounds and rademacher complexity in batch reinforcement learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[6]
Journal of Machine Learning Research , volume=
Towards a unified analysis of random fourier features , author=. Journal of Machine Learning Research , volume=. 2021 , publisher=
2021
-
[7]
2008 , publisher=
Support vector machines , author=. 2008 , publisher=
2008
-
[8]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[9]
2019 , publisher=
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
2019
-
[10]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[11]
International Conference on Machine Learning , pages =
Statistics and samples in distributional reinforcement learning , author =. International Conference on Machine Learning , pages =. 2019 , organization=
2019
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Distributional Reinforcement Learning via Moment Matching , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Distributional Reinforcement Learning With Quantile Regression , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[14]
International Conference on Machine Learning , pages=
Implicit Quantile Networks for Distributional Reinforcement Learning , author=. International Conference on Machine Learning , pages=
-
[15]
Advances in Neural Information Processing Systems , pages=
Fully parameterized quantile function for distributional reinforcement learning , author=. Advances in Neural Information Processing Systems , pages=
-
[16]
Nature , volume=
Human-level control through deep reinforcement learning , author=. Nature , volume=. 2015 , publisher=
2015
-
[17]
International Conference on Machine Learning , pages=
A Distributional Perspective on Reinforcement Learning , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[18]
International Conference on Machine Learning , pages=
Distributional Reinforcement Learning for Efficient Exploration , author=. International Conference on Machine Learning , pages=
-
[19]
International Conference on Artificial Intelligence and Statistics , pages=
A distributional analysis of sampling-based reinforcement learning algorithms , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[20]
Revue de l'Institut international de Statistique , pages=
Moments and cumulants in the specification of distributions , author=. Revue de l'Institut international de Statistique , pages=. 1938 , publisher=
1938
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A comparative analysis of expected and distributional reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
International Conference on Artificial Intelligence and Statistics , pages=
An analysis of categorical distributional reinforcement learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2018 , organization=
2018
-
[23]
International Conference on Learning Representations , year=
Distributional Reinforcement Learning with Monotonic Splines , author=. International Conference on Learning Representations , year=
-
[24]
International Conference on Machine Learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[25]
International Conference on Machine Learning , pages=
Controlling overestimation bias with truncated mixture of continuous distributional quantile critics , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[26]
International Conference on Machine Learning , pages=
Addressing function approximation error in actor-critic methods , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[27]
International Conference on Machine Learning , pages=
Averaged-dqn: Variance reduction and stabilization for deep reinforcement learning , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[28]
arXiv preprint arXiv:2004.14547 , year=
DSAC: distributional soft actor critic for risk-sensitive reinforcement learning , author=. arXiv preprint arXiv:2004.14547 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Deep exploration via bootstrapped DQN , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:1706.01502 , year=
Ucb exploration via q-ensembles , author=. arXiv preprint arXiv:1706.01502 , year=
-
[31]
Openai gym , author=. arXiv preprint arXiv:1606.01540 , year=
work page internal anchor Pith review arXiv
-
[32]
Advances in Neural Information Processing Systems , volume=
Non-crossing quantile regression for distributional reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
International Joint Conference on Artificial Intelligence , pages=
Non-decreasing Quantile Function Network with Efficient Exploration for Distributional Reinforcement Learning , author=. International Joint Conference on Artificial Intelligence , pages=
-
[34]
International Conference on Machine Learning , pages=
Count-based exploration with neural density models , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[35]
Econometrica: Journal of the Econometric Society , pages=
Asymmetric least squares estimation and testing , author=. Econometrica: Journal of the Econometric Society , pages=. 1987 , publisher=
1987
-
[36]
Science , volume=
Dynamic programming , author=. Science , volume=. 1966 , publisher=
1966
-
[37]
PhD thesis , year=
Learning from delayed rewards , author=. PhD thesis , year=
-
[38]
Machine Learning , year=
Learning to Predict by the Methods of Temporal Differences , author=. Machine Learning , year=
-
[39]
Quantile regression , author=
-
[40]
Stochastic Processes and their Applications , volume=
A fixed point theorem for distributions , author=. Stochastic Processes and their Applications , volume=. 1992 , publisher=
1992
-
[41]
Distributional Reinforcement Learning , author=
-
[42]
2009 , publisher=
Optimal transport: old and new , author=. 2009 , publisher=
2009
-
[43]
Journal of Applied Probability , volume=
The variance of discounted Markov decision processes , author=. Journal of Applied Probability , volume=. 1982 , publisher=
1982
-
[44]
, author=
Variance Reduction Techniques for Gradient Estimates in Reinforcement Learning. , author=. Journal of Machine Learning Research , volume=
-
[45]
An analysis of random design linear regression
An analysis of random design linear regression , author=. arXiv preprint arXiv:1106.2363 , year=
-
[46]
arXiv preprint arXiv:2302.06799 , year=
Quantiled conditional variance, skewness, and kurtosis by Cornish-Fisher expansion , author=. arXiv preprint arXiv:2302.06799 , year=
-
[47]
Journal of Machine Learning Research , year=
An Analysis of Quantile Temporal-Difference Learning , author=. Journal of Machine Learning Research , year=
-
[48]
International Conference on Machine Learning , year=
Distributional Offline Policy Evaluation with Predictive Error Guarantees , author=. International Conference on Machine Learning , year=
-
[49]
Reinforcement Learning: An Introduction , author=
-
[50]
Machine Learning , volume=
Learning near-optimal policies with Bellman-residual minimization based fitted policy iteration and a single sample path , author=. Machine Learning , volume=. 2008 , publisher=
2008
-
[51]
Advances in neural information processing systems , volume=
Fitted Q-iteration in continuous action-space MDPs , author=. Advances in neural information processing systems , volume=
-
[52]
, author=
Finite-Time Bounds for Fitted Value Iteration. , author=. Journal of Machine Learning Research , volume=
-
[53]
International Conference on Machine Learning , pages=
Information-theoretic considerations in batch reinforcement learning , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[54]
Advances in Neural Information Processing Systems , volume=
Bellman-consistent pessimism for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Conference on Uncertainty in Artificial Intelligence , pages=
Q* approximation schemes for batch reinforcement learning: A theoretical comparison , author=. Conference on Uncertainty in Artificial Intelligence , pages=. 2020 , organization=
2020
-
[56]
Journal of Machine Learning Research , volume=
Nonparametric Estimation of Non-Crossing Quantile Regression Process with Deep ReQU Neural Networks , author=. Journal of Machine Learning Research , volume=
-
[57]
arXiv preprint arXiv:2305.00608 , year=
Differentiable Neural Networks with RePU Activation: with Applications to Score Estimation and Isotonic Regression , author=. arXiv preprint arXiv:2305.00608 , year=
-
[58]
Advances in Neural Information Processing Systems , volume=
Conservative offline distributional reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
International Conference on Learning Representations , year=
Offline reinforcement learning with implicit q-learning , author=. International Conference on Learning Representations , year=
-
[61]
, author=
l_1 -penalized quantile regression in high dimensional sparse models. , author=. The Annals of Statistics , pages=. 2011 , publisher=
2011
-
[62]
arXiv preprint arXiv:2104.06708 , year=
Deep nonparametric regression on approximately low-dimensional manifolds , author=. arXiv preprint arXiv:2104.06708 , year=
-
[63]
2004 , publisher=
Fractal geometry: mathematical foundations and applications , author=. 2004 , publisher=
2004
-
[64]
arXiv preprint arXiv:2202.11461 , year=
Exponential tail local Rademacher complexity risk bounds without the Bernstein condition , author=. arXiv preprint arXiv:2202.11461 , year=
-
[65]
International Conference on Machine Learning , pages=
Fast excess risk rates via offset Rademacher complexity , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[66]
Biometrika , volume=
Risk bounds for quantile trend filtering , author=. Biometrika , volume=. 2022 , publisher=
2022
-
[67]
Advances in Neural Information Processing Systems , volume=
Imagenet classification with deep convolutional neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Econometrica , volume=
Deep neural networks for estimation and inference , author=. Econometrica , volume=. 2021 , publisher=
2021
-
[69]
2009 , publisher=
Neural Network Learning: Theoretical Foundations , author=. 2009 , publisher=
2009
-
[70]
Bartlett and Nick Harvey and Christopher Liaw and Abbas Mehrabian , title =
Peter L. Bartlett and Nick Harvey and Christopher Liaw and Abbas Mehrabian , title =. Journal of Machine Learning Research , year =
-
[71]
arXiv preprint arXiv:1903.05858 , year=
Better approximations of high dimensional smooth functions by deep neural networks with rectified power units , author=. arXiv preprint arXiv:1903.05858 , year=
-
[72]
arXiv preprint arXiv:1911.05467 , year=
ChebNet: Efficient and stable constructions of deep neural networks with rectified power units using chebyshev approximations , author=. arXiv preprint arXiv:1911.05467 , year=
-
[73]
Transactions on Machine Learning Research , year=
On Sample Complexity of Offline Reinforcement Learning with Deep ReLU Networks in Besov Spaces , author=. Transactions on Machine Learning Research , year=
-
[74]
Learning for dynamics and control , pages=
A theoretical analysis of deep Q-learning , author=. Learning for dynamics and control , pages=. 2020 , organization=
2020
-
[75]
Journal of Machine Learning Research , volume=
Quantile regression with ReLU Networks: Estimators and minimax rates , author=. Journal of Machine Learning Research , volume=. 2022 , publisher=
2022
-
[76]
Advances in Neural Information Processing Systems , volume=
Error propagation for approximate policy and value iteration , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
Journal of Machine Learning Research , volume=
Regularized policy iteration with nonparametric function spaces , author=. Journal of Machine Learning Research , volume=. 2016 , publisher=
2016
-
[78]
Adaptivity of deep Re
Taiji Suzuki , booktitle=. Adaptivity of deep Re
-
[79]
The Annals of Statistics , volume=
Deep nonparametric regression on approximately low-dimensional manifolds , author=. The Annals of Statistics , volume=
-
[80]
Journal of Nonparametric Statistics , volume =
Xuming He and Peide Shi , title =. Journal of Nonparametric Statistics , volume =. 1994 , publisher =
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.