Recognition: unknown
Committed SAE-Feature Traces for Audited-Session Substitution Detection in Hosted LLMs
Pith reviewed 2026-05-10 04:47 UTC · model grok-4.3
The pith
A Merkle-tree commitment to per-position sparse-autoencoder feature traces lets verifiers detect silent model substitution in hosted LLMs even when the provider knows the audit rules in advance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By forcing the provider to commit to sparse-autoencoder feature traces before any opening request, the protocol creates a session-wide record that a verifier can check for joint consistency at random positions, rejecting substitution even against protocol-aware attackers.
What carries the argument
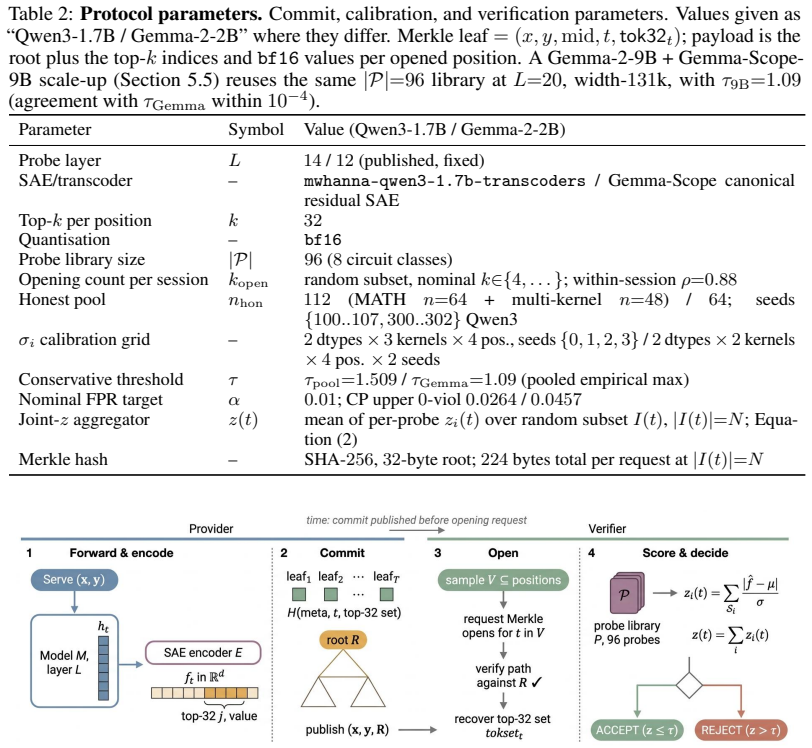
The commit-open protocol that uses a Merkle tree to bind the provider to per-position sparse-autoencoder (SAE) feature-trace sketches at a fixed probe layer, scored by a public named-circuit probe library and a fixed-threshold joint-consistency z-score rule.
If this is right
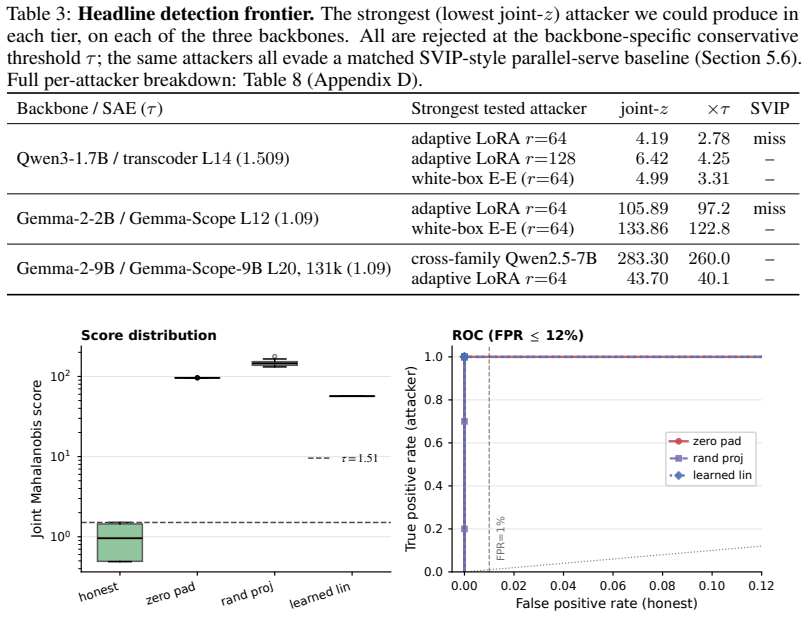
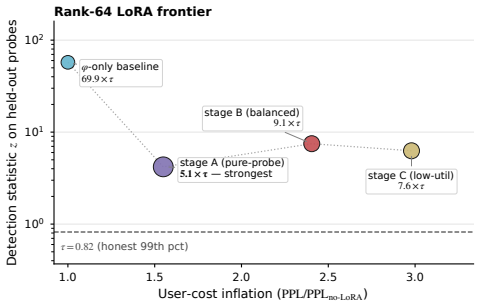
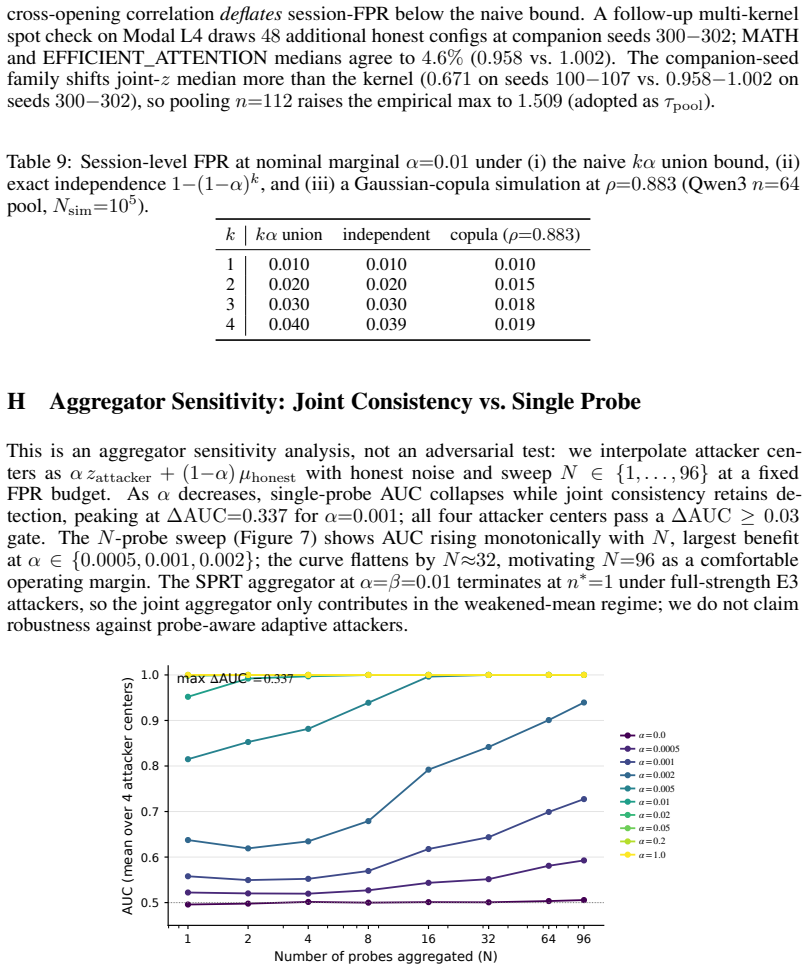
- All seventeen tested attackers spanning same-family lifts, cross-family substitutes, and rank-128 adaptive LoRA are rejected at one shared scale-stable threshold.
- The identical attackers evade a matched SVIP-style parallel-serve baseline.
- A white-box end-to-end attack that backpropagates through the frozen SAE encoder does not close the detection margin.
- A feature-forgery attacker that never runs the honest model is bounded in closed form by an intrinsic-dimension argument.
- The commitment step adds no more than 2.1 percent to forward-only wall-clock time at batch size 32.
Where Pith is reading between the lines
- Widespread use would require providers to publish their probe libraries in advance so independent parties can perform audits.
- The same commitment structure could apply to other detectable deviations such as safety-filter bypasses if distinctive feature traces for those behaviors exist.
- Periodic updates to the probe library may be needed as new model families appear, otherwise the distinctiveness assumption could weaken over time.
Load-bearing premise
That a public probe library calibrated across backends produces feature traces distinctive enough between different models that the fixed z-score rule still works when the provider knows the protocol ahead of time.
What would settle it
Finding a substitute model or fine-tune that produces outputs a user would accept as coming from the advertised model yet still matches the committed SAE traces closely enough to pass the joint-consistency z-score test at the published threshold.
Figures









read the original abstract
Hosted-LLM providers have a silent-substitution incentive: advertise a stronger model while serving cheaper replies. Probe-after-return schemes such as SVIP leave a parallel-serve side-channel, since a dishonest provider can route the verifier's probe to the advertised model while serving ordinary users from a substitute. We propose a commit-open protocol that closes this gap. Before any opening request, the provider commits via a Merkle tree to a per-position sparse-autoencoder (SAE) feature-trace sketch of its served output at a published probe layer. A verifier opens random positions, scores them against a public named-circuit probe library calibrated with cross-backend noise, and decides with a fixed-threshold joint-consistency z-score rule. We instantiate the protocol on three backbones -- Qwen3-1.7B, Gemma-2-2B, and a 4.5x scale-up to Gemma-2-9B with a 131k-feature SAE. Of 17 attackers spanning same-family lifts, cross-family substitutes, and rank-<=128 adaptive LoRA, all are rejected at a shared, scale-stable threshold; the same attackers all evade a matched SVIP-style parallel-serve baseline. A white-box end-to-end attack that backpropagates through the frozen SAE encoder does not close the margin, and a feature-forgery attacker that never runs M_hon is bounded in closed form by an intrinsic-dimension argument. Commitment adds <=2.1% to forward-only wall-clock at batch 32.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a commit-open protocol to detect silent model substitution by hosted LLM providers. Providers commit via Merkle tree to per-position SAE feature-trace sketches of outputs at a published probe layer before any verifier opening. Verifiers open random positions, score traces against a public named-circuit probe library (calibrated on cross-backend noise), and apply a fixed-threshold joint-consistency z-score rule. Experiments on Qwen3-1.7B, Gemma-2-2B, and a 4.5x Gemma-2-9B scale-up with 131k-feature SAE show all 17 tested attackers (same-family lifts, cross-family substitutes, rank-≤128 adaptive LoRA) rejected at one shared scale-stable threshold; the same attackers evade a matched SVIP-style parallel-serve baseline. A white-box end-to-end attack backpropagating through the frozen SAE encoder fails to close the margin, while a feature-forgery attacker never running the honest model is bounded in closed form by an intrinsic-dimension argument. Commitment overhead is ≤2.1% at batch 32.
Significance. If the empirical and theoretical results hold, the work supplies a concrete, low-overhead mechanism for auditing hosted LLMs that closes the parallel-serve side-channel left by probe-after-return schemes. The combination of cryptographic commitment, SAE feature traces, and a public probe library is a novel contribution to the model-auditing literature. Explicit credit is due for testing a diverse attacker suite, including adaptive LoRA and white-box gradient attacks, plus the closed-form intrinsic-dimension bound on forgery. These elements would strengthen practical trust in commercial LLM services if the calibration independence and statistical robustness concerns are resolved.
major comments (3)
- [Abstract] Abstract: the central empirical claim that 'all 17 attackers are rejected at a shared, scale-stable threshold' is presented without error bars, the exact numerical threshold, details on how the probe library was constructed, or statistical justification for the z-score rule. This is load-bearing for the paper's main result.
- [Protocol description and §4 (experiments)] Protocol and experimental sections: the detection rule relies on an empirically calibrated noise model and public probe library, yet no demonstration is given that the library construction and calibration are independent of the 17 test attackers or the specific backbones used. This raises a circularity risk for the fixed-threshold rule against protocol-aware adversaries.
- [Attacker evaluation] Attacker evaluation: while the white-box backprop attack through the frozen SAE and the intrinsic-dimension bound on feature forgery are reported, the manuscript does not quantify the margin by which these attacks fail or show that the bound remains non-vacuous once the provider knows the exact opening distribution and z-score rule in advance.
minor comments (2)
- [Abstract and results] The abstract and results would benefit from a table listing the exact 17 attackers, their categories, and the per-attacker z-scores or distances to threshold.
- [Notation] Notation for the 'per-position SAE-feature-trace sketch' and the joint-consistency z-score should be defined once in a dedicated notation subsection rather than introduced piecemeal.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and will revise the manuscript to incorporate the requested details, clarifications, and additional analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that 'all 17 attackers are rejected at a shared, scale-stable threshold' is presented without error bars, the exact numerical threshold, details on how the probe library was constructed, or statistical justification for the z-score rule. This is load-bearing for the paper's main result.
Authors: We agree that the abstract would benefit from greater specificity on these load-bearing elements. In revision we will state the exact shared threshold value, include error bars derived from the repeated experimental runs, briefly describe the probe library construction from the public named-circuit set, and point to the statistical justification of the joint-consistency z-score rule (which appears in §3). These additions will be kept concise while making the central claim fully transparent. revision: yes
-
Referee: [Protocol description and §4 (experiments)] Protocol and experimental sections: the detection rule relies on an empirically calibrated noise model and public probe library, yet no demonstration is given that the library construction and calibration are independent of the 17 test attackers or the specific backbones used. This raises a circularity risk for the fixed-threshold rule against protocol-aware adversaries.
Authors: The calibration uses cross-backend noise collected from a diverse set of models and the probe library is built from fixed, publicly documented named circuits; neither step incorporates the 17 evaluation attackers. To remove any ambiguity we will add an explicit independence check in the revised §4: we re-calibrate the noise model while deliberately excluding the test backbones and attackers, then verify that the same fixed threshold continues to separate all 17 attackers. This directly demonstrates that the rule is not circular with respect to the reported evaluation set. revision: yes
-
Referee: [Attacker evaluation] Attacker evaluation: while the white-box backprop attack through the frozen SAE and the intrinsic-dimension bound on feature forgery are reported, the manuscript does not quantify the margin by which these attacks fail or show that the bound remains non-vacuous once the provider knows the exact opening distribution and z-score rule in advance.
Authors: We will expand the attacker-evaluation subsection to report the precise margins: the z-score gap between the white-box back-propagation attack and the detection threshold, and the numerical probability bound obtained from the intrinsic-dimension argument. We will also add a short analysis showing that the forgery bound remains non-vacuous even under full knowledge of the opening-position distribution and the z-score rule, because the bound is derived from the SAE feature-space dimensionality and the sparsity constraint rather than from the specific opening schedule. revision: yes
Circularity Check
No significant circularity in protocol derivation or empirical claims
full rationale
The paper presents a commit-open protocol whose core steps (Merkle commitment to SAE feature-trace sketches, random-position opening, and fixed-threshold z-score decision) are defined independently of the test outcomes. Empirical results on 17 attackers are reported as validation rather than as a derivation that reduces to fitted parameters or self-citations by construction. The public probe library and cross-backend noise calibration are described as external inputs, with no equations or claims showing that the rejection threshold or distinctiveness argument collapses to the input data or prior self-work. The intrinsic-dimension bound on feature-forgery is presented as a closed-form argument separate from the fitted elements. This is the normal case of a self-contained protocol paper whose central claims do not reduce to their own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- joint-consistency z-score threshold
- probe-library calibration parameters
axioms (1)
- domain assumption SAE features extracted at the published probe layer remain distinctive across model families and scales even after cross-backend noise.
invented entities (1)
-
per-position SAE-feature-trace sketch
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LegoSNARK: Modular design and compo- sition of succinct zero-knowledge proofs
Matteo Campanelli, Dario Fiore, and Anaïs Querol. LegoSNARK: Modular design and compo- sition of succinct zero-knowledge proofs. InProceedings of the 2019 ACM SIGSAC Confer- ence on Computer and Communications Security (CCS), pages 2075–2092. ACM, 2019. doi: 10.1145/3319535.3339820
-
[2]
Kornaropoulos, and Giuseppe Ateniese
Dario Pasquini, Evgenios M. Kornaropoulos, and Giuseppe Ateniese. LLMmap: Fingerprinting for large language models. In34th USENIX Security Symposium, pages 299–318. USENIX Association, 2025
2025
-
[3]
Jiashu Xu, Fei Wang, Mingyu Derek Ma, Pang Wei Koh, Chaowei Xiao, and Muhao Chen. Instructional fingerprinting of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), pages 3277–3306. Association for Computational Linguistics, 2024. doi: 10.18653/V1/2024. NA...
-
[4]
SVIP: Towards Verifiable Inference of Open-source Large Language Models
Yifan Sun, Yuhang Li, Yue Zhang, Yuchen Jin, and Huan Zhang. SVIP: Towards verifiable inference of open-source large language models.CoRR, abs/2410.22307, 2024. doi: 10.48550/ ARXIV .2410.22307
-
[5]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR). OpenReview.net, 2022
2022
-
[6]
TOPLOC: A locality sensitive hashing scheme for trustless verifiable inference
Jack Min Ong, Matthew Di Ferrante, Aaron Pazdera, Ryan Garner, Sami Jaghouar, Manveer Basra, Max Ryabinin, and Johannes Hagemann. TOPLOC: A locality sensitive hashing scheme for trustless verifiable inference. InInternational Conference on Machine Learning (ICML). PMLR / OpenReview.net, 2025. 11
2025
-
[7]
Compact proofs of model performance via mechanistic interpretability
Jason Gross, Rajashree Agrawal, Thomas Kwa, Euan Ong, Chun Hei Yip, Alex Gibson, Soufiane Noubir, and Lawrence Chan. Compact proofs of model performance via mechanistic interpretability. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[8]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In International Conference on Learning Representations (ICLR). OpenReview.net, 2023
2023
-
[9]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
work page internal anchor Pith review arXiv 2022
-
[10]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and Ch...
2023
-
[11]
Daniel Freeman, Theodore R
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosema...
2024
-
[12]
SAELens: Training and analyzing sparse autoencoders, 2024
Joseph Bloom, Curt Tigges, Anthony Duong, and David Chanin. SAELens: Training and analyzing sparse autoencoders, 2024. Software package, https://github.com/jbloomAus/ SAELens
2024
-
[13]
Transcoders find interpretable LLM feature circuits
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable LLM feature circuits. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[14]
Proofs of useful work
Marshall Ball, Alon Rosen, Manuel Sabin, and Prashant Nalini Vasudevan. Proofs of useful work. Cryptology ePrint Archive, Paper 2017/203, 2017. URL https://eprint.iacr.org/ 2017/203
2017
-
[15]
Intel TDX demystified: A top-down approach.ACM Computing Surveys, 56(9):238:1–238:33, 2024
Pau-Chen Cheng, Wojciech Ozga, Enriquillo Valdez, Salman Ahmed, Zhongshu Gu, Hani Jamjoom, Hubertus Franke, and James Bottomley. Intel TDX demystified: A top-down approach.ACM Computing Surveys, 56(9):238:1–238:33, 2024. doi: 10.1145/3652597
-
[17]
Design and implementation of a TCG-based integrity measurement architecture
Reiner Sailer, Xiaolan Zhang, Trent Jaeger, and Leendert van Doorn. Design and implementation of a TCG-based integrity measurement architecture. In13th USENIX Security Symposium, pages 223–238. USENIX Association, 2004
2004
-
[18]
Crosby and Dan S
Scott A. Crosby and Dan S. Wallach. Efficient data structures for tamper-evident logging. In 18th USENIX Security Symposium, pages 317–334. USENIX Association, 2009
2009
-
[19]
Certificate transparency
Ben Laurie, Adam Langley, and Emilia Käsper. Certificate transparency. RFC 6962, IETF, 2013
2013
-
[20]
Heng Jin, Chaoyu Zhang, Hexuan Yu, Shanghao Shi, Ning Zhang, Y . Thomas Hou, and Wenjing Lou. Trusting what you cannot see: Auditable fine-tuning and inference for proprietary AI. CoRR, abs/2603.07466, 2026. 12
-
[21]
Hasan Akgul, Daniel Borg, Arta Berisha, Amina Rahimova, Andrej Novak, and Mila Petrov. Verifiable fine-tuning for LLMs: Zero-knowledge training proofs bound to data provenance and policy.CoRR, abs/2510.16830, 2025
-
[22]
Ralph C. Merkle. A digital signature based on a conventional encryption function. In Carl Pomerance, editor,Advances in Cryptology - CRYPTO ’87, Lecture Notes in Computer Science, pages 369–378. Springer, 1987. doi: 10.1007/3-540-48184-2\_32
-
[23]
Sequential tests of statistical hypotheses.Annals of Mathematical Statistics, 16 (2):117–186, 1945
Abraham Wald. Sequential tests of statistical hypotheses.Annals of Mathematical Statistics, 16 (2):117–186, 1945
1945
-
[24]
A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
1979
-
[30]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800GB dataset of diverse text for language modeling.CoRR, abs/2101.00027, 2021
work page internal anchor Pith review arXiv 2021
-
[31]
On the generalised distance in statistics.Proceedings of the National Institute of Sciences of India, 2(1):49–55, 1936
Prasanta Chandra Mahalanobis. On the generalised distance in statistics.Proceedings of the National Institute of Sciences of India, 2(1):49–55, 1936
1936
-
[32]
C. J. Clopper and E. S. Pearson. The use of confidence or fiducial limits illustrated in the case of the binomial.Biometrika, 26(4):404–413, 1934. doi: 10.1093/biomet/26.4.404
-
[33]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca D. Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2.CoRR, abs/2408.05147, 2024. doi: 10.48550/ARXIV .2408.05147. 14 A Threat Model Table 6 defines the adversary we consider. Every...
work page internal anchor Pith review doi:10.48550/arxiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.