Recognition: unknown
Multi-LLM Token Filtering and Routing for Sequential Recommendation
Pith reviewed 2026-05-10 04:02 UTC · model grok-4.3
The pith
Multi-LLM token filtering and routing lets sequential recommenders use embeddings directly without text inputs or backbone changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
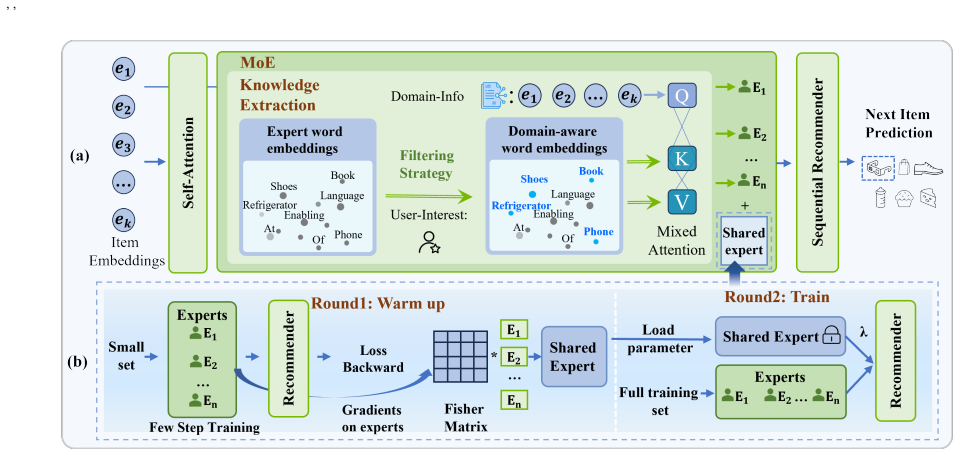
MLTFR follows an interaction-guided LLM knowledge integration paradigm, where task-relevant token embeddings are selected via user-guided token filtering to suppress noisy and irrelevant vocabulary signals. To overcome the limitations of single-LLM representations, MLTFR integrates multiple LLM token spaces through a Mixture-of-Experts architecture, with a Fisher-weighted semantic consensus expert to balance heterogeneous experts and prevent domination during training. By jointly filtering informative tokens and aggregating complementary semantic knowledge across multiple LLMs, MLTFR enables stable and effective utilization of LLM token embeddings without textual inputs or backbone modificat
What carries the argument
User-guided token filtering combined with a Fisher-weighted semantic consensus expert inside a multi-LLM Mixture-of-Experts architecture that routes and balances token embeddings.
If this is right
- Sequential recommenders obtain stable accuracy gains from LLM embeddings alone.
- Combining several LLMs supplies broader semantic coverage than any one model provides.
- No external text corpora or changes to the recommender backbone are required.
- Training stays stable because the weighted consensus expert limits domination by any single LLM.
Where Pith is reading between the lines
- The same filtering step could adapt LLM embeddings for ranking or retrieval tasks that currently rely on text alignment.
- Fisher-weighted balancing may help combine other families of pre-trained models beyond language models.
- The method could improve recommendations in cold-start settings where interaction data is limited but LLM semantics are available.
Load-bearing premise
User interaction signals can reliably identify which tokens carry useful information and Fisher-weighted routing can keep multiple LLM experts balanced without creating hidden instability or overfitting.
What would settle it
Apply MLTFR to a sequential recommendation dataset containing highly noisy or sparse user histories and measure whether accuracy gains over single-LLM and baseline methods disappear or reverse.
Figures


read the original abstract
Large language models (LLMs) have recently shown promise in recommendation by providing rich semantic knowledge. While most existing approaches rely on external textual corpora to align LLMs with recommender systems, we revisit a more fundamental yet underexplored question: Can recommendation benefit from LLM token embeddings alone without textual input? Through a systematic empirical study, we show that directly injecting token embeddings from a single LLM into sequential recommenders leads to unstable or limited gains, due to semantic misalignment, insufficient task adaptation, and the restricted coverage of individual LLMs. To address these challenges, we propose MLTFR, a Multi-LLM Token Filtering and Routing framework for corpus-free sequential recommendation. MLTFR follows an interaction-guided LLM knowledge integration paradigm, where task-relevant token embeddings are selected via user-guided token filtering to suppress noisy and irrelevant vocabulary signals. To overcome the limitations of single-LLM representations, MLTFR integrates multiple LLM token spaces through a Mixture-of-Experts architecture, with a Fisher-weighted semantic consensus expert to balance heterogeneous experts and prevent domination during training. By jointly filtering informative tokens and aggregating complementary semantic knowledge across multiple LLMs, MLTFR enables stable and effective utilization of LLM token embeddings without textual inputs or backbone modification. Extensive experiments demonstrate that MLTFR consistently outperforms state-of-the-art sequential recommendation baselines and existing alignment methods. Our code is available at: https://github.com/ccwwhhh/MLTFR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MLTFR, a Multi-LLM Token Filtering and Routing framework for corpus-free sequential recommendation. It uses interaction-guided user token filtering to select informative embeddings from multiple frozen LLMs and integrates them via a Mixture-of-Experts architecture containing a Fisher-weighted semantic consensus expert that balances heterogeneous representations and prevents single-expert domination. The central claim is that this combination yields stable performance gains over single-LLM baselines and existing alignment methods without requiring textual corpora or modifications to the recommender backbone.
Significance. If the stability and outperformance claims hold under rigorous verification, the work would be significant for sequential recommendation by showing that LLM token embeddings can be used directly and effectively in a multi-LLM setting without external text alignment. The release of code is a clear strength that supports reproducibility. The approach addresses a genuine gap in handling semantic misalignment and limited coverage of individual LLMs.
major comments (3)
- [§3.2] §3.2 (Fisher-weighted expert): the claim that the semantic consensus expert prevents domination rests on the Fisher weighting coefficients, which are listed as free parameters; without an explicit ablation that isolates their contribution from the added routing capacity, it is unclear whether observed gains derive from the proposed balancing mechanism or from increased model expressivity.
- [§4] §4 (experimental results): the abstract and results sections assert consistent outperformance and stability, yet no effect sizes, statistical significance tests, run-to-run variance, or monitoring of routing entropy/expert utilization are reported; these omissions are load-bearing for the central claim that user-guided filtering plus Fisher routing reliably suppresses noise without introducing new overfitting or instability.
- [§4.3] §4.3 (ablations): the token filtering threshold is a tunable hyperparameter whose effectiveness is demonstrated only on the same benchmarks used for tuning; an explicit sensitivity analysis across held-out splits or alternative thresholds is required to substantiate that the filtering step is not simply dataset-specific regularization.
minor comments (2)
- [§3.1] The notation distinguishing the per-LLM token selection mask from the final routed embedding could be clarified with an explicit equation in §3.1.
- [Figure 2] Figure 2 (architecture diagram) would benefit from labeling the Fisher weighting step and the consensus expert output to match the text description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Fisher-weighted expert): the claim that the semantic consensus expert prevents domination rests on the Fisher weighting coefficients, which are listed as free parameters; without an explicit ablation that isolates their contribution from the added routing capacity, it is unclear whether observed gains derive from the proposed balancing mechanism or from increased model expressivity.
Authors: We agree that isolating the contribution of the Fisher weighting is important. In the revision we will add an ablation that replaces the Fisher-derived coefficients with uniform weights (or with learned weights lacking the Fisher term) while preserving identical MoE routing capacity and expert count. The resulting performance comparison will clarify whether the balancing effect, rather than extra expressivity, accounts for the observed stability and gains. revision: yes
-
Referee: [§4] §4 (experimental results): the abstract and results sections assert consistent outperformance and stability, yet no effect sizes, statistical significance tests, run-to-run variance, or monitoring of routing entropy/expert utilization are reported; these omissions are load-bearing for the central claim that user-guided filtering plus Fisher routing reliably suppresses noise without introducing new overfitting or instability.
Authors: We accept that these quantitative indicators are necessary to substantiate the stability claims. The revised experimental section will report relative effect sizes, paired statistical significance tests (t-tests or Wilcoxon signed-rank) across runs, standard deviations over five random seeds, and additional metrics/plots for routing entropy and per-expert utilization to demonstrate that the Fisher-weighted consensus expert prevents domination and does not introduce instability. revision: yes
-
Referee: [§4.3] §4.3 (ablations): the token filtering threshold is a tunable hyperparameter whose effectiveness is demonstrated only on the same benchmarks used for tuning; an explicit sensitivity analysis across held-out splits or alternative thresholds is required to substantiate that the filtering step is not simply dataset-specific regularization.
Authors: We will add a dedicated sensitivity study in the revision. Performance will be evaluated across a grid of threshold values on held-out validation splits (distinct from the tuning folds) and reported as curves or tables. This analysis will show that the filtering step yields consistent benefits rather than acting as dataset-specific regularization. revision: yes
Circularity Check
No significant circularity; empirical method validated against external baselines
full rationale
The paper presents MLTFR as an empirical framework relying on interaction-guided token filtering and a Mixture-of-Experts routing architecture with Fisher weighting. No mathematical derivation chain, equations, or self-referential definitions are provided that reduce claimed outputs to inputs by construction. Core claims of stable utilization and outperformance are supported by experiments on standard sequential recommendation benchmarks against SOTA baselines and alignment methods, constituting independent evaluation. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked. Design choices are presented as methodological contributions tested experimentally rather than fitted predictions renamed as results. This is a standard empirical contribution with released code.
Axiom & Free-Parameter Ledger
free parameters (2)
- Fisher weighting coefficients
- Token filtering threshold
Reference graph
Works this paper leans on
-
[1]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM Conference on Recommender Systems. 299–315
2022
-
[2]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. 2024. Chatglm: A fam- ily of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793(2024)
work page internal anchor Pith review arXiv 2024
- [3]
-
[4]
B Hidasi. 2015. Session-based Recommendations with Recurrent Neural Networks. arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review arXiv 2015
- [5]
-
[6]
Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. 2024. Enhancing sequential recommendation via llm-based semantic embedding learning. InCompanion Proceedings of the ACM Web Conference 2024. 103–111
2024
-
[7]
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. 1991. Adaptive mixtures of local experts.Neural computation3, 1 (1991), 79–87
1991
-
[8]
Michael I Jordan and Robert A Jacobs. 1994. Hierarchical mixtures of experts and the EM algorithm.Neural computation6, 2 (1994), 181–214
1994
- [9]
-
[10]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[11]
Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, Vol. 1. Minneapolis, Minnesota
2019
- [12]
-
[13]
Chengxi Li, Yejing Wang, Qidong Liu, Xiangyu Zhao, Wanyu Wang, Yiqi Wang, Lixin Zou, Wenqi Fan, and Qing Li. 2023. STRec: Sparse transformer for sequential recommendations. InProceedings of the 17th ACM Conference on Recommender Systems. 101–111
2023
-
[14]
Lei Li, Yongfeng Zhang, and Li Chen. 2023. Prompt distillation for efficient llm- based recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1348–1357
2023
-
[15]
Sijia Li, Min Gao, Zongwei Wang, Yibing Bai, and Wuhan Chen. 2025. Linking Ordered and Orderless Modeling for Sequential Recommendation. InProceed- ings of the 34th ACM International Conference on Information and Knowledge Management. 1654–1664
2025
-
[16]
Zihao Li, Aixin Sun, and Chenliang Li. 2023. Diffurec: A diffusion model for sequential recommendation.ACM Transactions on Information Systems42, 3 (2023), 1–28
2023
- [17]
-
[18]
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al . 2024. Deepseek- v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434(2024)
work page internal anchor Pith review arXiv 2024
-
[19]
CanYi Liu, Wei Li, Hui Li, Rongrong Ji, et al. 2024. Beyond Inter-Item Relations: Dynamic Adaptive Mixture-of-Experts for LLM-Based Sequential Recommenda- tion.arXiv e-prints(2024), arXiv–2408
2024
-
[20]
Haibo Liu, Zhixiang Deng, Liang Wang, Jinjia Peng, and Shi Feng. 2023. Distribution-based Learnable Filters with Side Information for Sequential Recom- mendation. InProceedings of the 17th ACM Conference on Recommender Systems. 78–88
2023
-
[21]
Langming Liu, Liu Cai, Chi Zhang, Xiangyu Zhao, Jingtong Gao, Wanyu Wang, Yifu Lv, Wenqi Fan, Yiqi Wang, Ming He, et al. 2023. Linrec: Linear attention mechanism for long-term sequential recommender systems. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 289–299
2023
-
[22]
Yuli Liu, Christian Walder, Lexing Xie, and Yiqun Liu. 2024. Probabilistic Atten- tion for Sequential Recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1956–1967
2024
-
[23]
Jinliang Lu, Ziliang Pang, Min Xiao, Yaochen Zhu, Rui Xia, and Jiajun Zhang
- [24]
-
[25]
Alexander Ly, Maarten Marsman, Josine Verhagen, Raoul PPP Grasman, and Eric-Jan Wagenmakers. 2017. A tutorial on Fisher information.Journal of Mathematical Psychology80 (2017), 40–55
2017
-
[26]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of- experts. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1930–1939
2018
- [27]
-
[28]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197
2019
-
[29]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[30]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[31]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[32]
Jérémie Rappaz, Maria-Luiza Vladarean, Julian McAuley, and Michele Catasta
-
[33]
InProceedings of the Tenth ACM International Conference on Web Search and Data Mining
Bartering books to beers: A recommender system for exchange platforms. InProceedings of the Tenth ACM International Conference on Web Search and Data Mining. 505–514
-
[34]
Yankun Ren, Zhongde Chen, Xinxing Yang, Longfei Li, Cong Jiang, Lei Cheng, Bo Zhang, Linjian Mo, and Jun Zhou. 2024. Enhancing Sequential Recommenders with Augmented Knowledge from Aligned Large Language Models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 345–354
2024
-
[35]
Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factor- izing personalized markov chains for next-basket recommendation. InProceedings of the 19th international conference on World wide web. 811–820
2010
-
[36]
Yehjin Shin, Jeongwhan Choi, Hyowon Wi, and Noseong Park. 2024. An atten- tive inductive bias for sequential recommendation beyond the self-attention. In Proceedings of the AAAI conference on artificial intelligence, Vol. 38. 8984–8992
2024
-
[37]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[38]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[39]
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, and Yongfeng Zhang. 2024. Idgenrec: Llm-recsys alignment with textual id learning. InProceed- ings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 355–364
2024
-
[40]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
2018
-
[41]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Zongwei Wang, Min Gao, Wentao Li, Junliang Yu, Linxin Guo, and Hongzhi Yin
-
[43]
InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining
Efficient bi-level optimization for recommendation denoising. InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining. 2502–2511
-
[44]
Zongwei Wang, Min Gao, Xinyi Wang, Junliang Yu, Junhao Wen, and Qingyu Xiong. 2019. A minimax game for generative and discriminative sample models for recommendation. InPacific-Asia conference on knowledge discovery and data mining. Springer, 420–431
2019
-
[45]
Zongwei Wang, Min Gao, Junliang Yu, Xinyi Gao, Quoc Viet Hung Nguyen, Shazia Sadiq, and Hongzhi Yin. 2025. Id-free not risk-free: Llm-powered agents unveil risks in id-free recommender systems. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1902–1911
2025
-
[46]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259– 1273
2022
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Zhengyi Yang, Jiancan Wu, Zhicai Wang, Xiang Wang, Yancheng Yuan, and Xiangnan He. 2024. Generate what you prefer: Reshaping sequential recommen- dation via guided diffusion.Advances in Neural Information Processing Systems 36 (2024)
2024
-
[49]
Jianyang Zhai, Zi-Feng Mai, Dongyi Zheng, Chang-Dong Wang, Xiawu Zheng, Hui Li, Feidiao Yang, and Yonghong Tian. 2025. Learning Transition Patterns by Large Language Models for Sequential Recommendation. InProceedings of the 31st International Conference on Computational Linguistics. 2513–2525
2025
- [50]
-
[51]
Yang Zhang, Keqin Bao, Ming Yan, Wenjie Wang, Fuli Feng, and Xiangnan He
-
[52]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)
Text-like Encoding of Collaborative Information in Large Language Models for Recommendation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)
2024
-
[53]
Zhi Zheng, Wenshuo Chao, Zhaopeng Qiu, Hengshu Zhu, and Hui Xiong. 2024. Harnessing large language models for text-rich sequential recommendation. In Proceedings of the ACM on Web Conference 2024. 3207–3216
2024
-
[54]
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. 2022. Filter-enhanced MLP is all you need for sequential recommendation. InProceedings of the ACM web conference 2022. 2388–2399
2022
-
[55]
Richard Zhuang, Tianhao Wu, Zhaojin Wen, Andrew Li, Jiantao Jiao, and Kannan Ramchandran. 2024. EmbedLLM: Learning Compact Representations of Large Language Models.arXiv preprint arXiv:2410.02223(2024). A Complex Analysis Our MLTFR incorporates an MoE module on backbone models such as SASRec and BERT4Rec, so we focus on the complexity analysis of the MoE ...
-
[56]
The details of the data sets are shown in Table 5
after splitting. The details of the data sets are shown in Table 5. D Details of Baselines • SASRec[ 10] is a personalized recommendation model. It uses stacked unidirectional attention blocks to predict items sequen- tially. • BERT4Rec[ 34] adopts the Cloze objective, predicting a ran- domly masked item in the sequence through joint analysis of its prece...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.