Recognition: unknown
A Control Architecture for Training-Free Memory Use
Pith reviewed 2026-05-10 04:12 UTC · model grok-4.3
The pith
A control architecture decides when to apply and trust prompt-injected memory, yielding gains on arithmetic reasoning without any model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
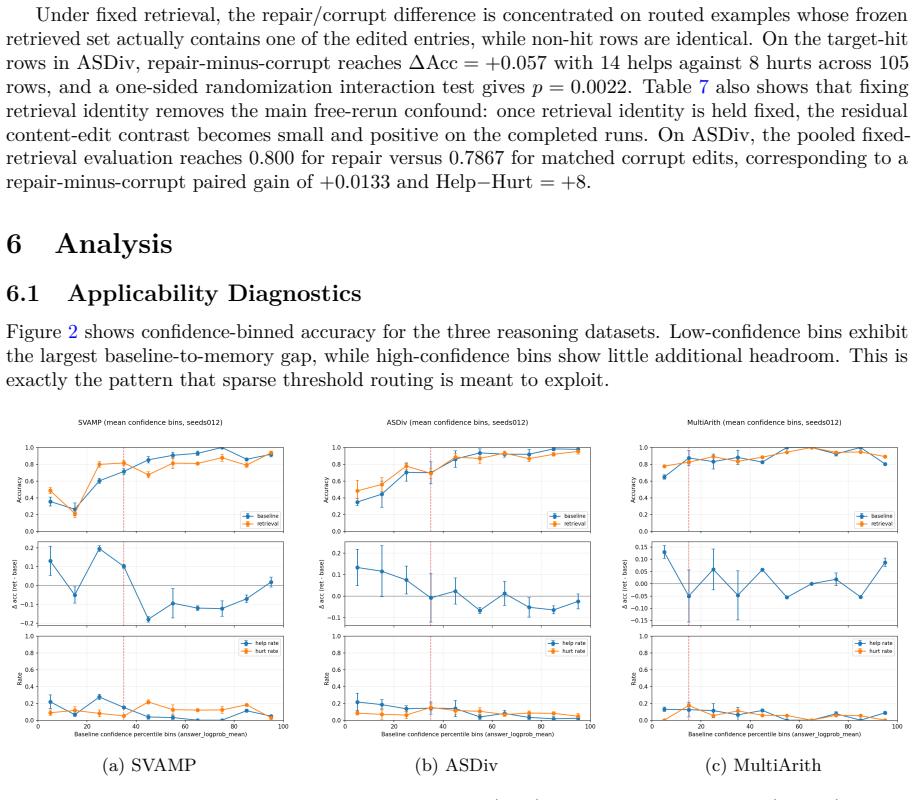
The paper claims that applicability control—implemented through uncertainty-based routing to decide when a memory-assisted second pass is warranted, confidence-based selective acceptance to decide when to keep that output, selection across rule and exemplar memory banks, and evidence-based governance to update the bank over time—produces measurable gains on arithmetic benchmarks under locked training-free and compute-matched conditions. Specifically, the architecture raises SVAMP by 7.0 points and ASDiv by 7.67 points over baseline, with the gains driven by the control layer: confidence scores separate helpful from harmful rule-bank interventions, and under fixed retrieval the repair-versus-
What carries the argument
The applicability control architecture, which uses uncertainty routing to trigger a second pass, confidence scoring to accept or reject its result, bank selection between rule and exemplar memories, and evidence-based governance to maintain the bank.
If this is right
- Confidence scoring isolates the cases where rule-bank interventions improve versus corrupt the answer.
- Evidence-based governance keeps the memory bank useful across successive uses without retraining.
- The same control stack produces positive though smaller effects on QA and agent benchmarks.
- The directional benefit appears on a second model checkpoint for the main arithmetic tasks.
Where Pith is reading between the lines
- The same separation of control from raw retrieval could be tested on non-arithmetic reasoning where harmful memory items are more frequent.
- Targeted editing of only the entries that appear in retrieved sets might amplify the observed localization of gains.
- Without the governance step, repeated use of the memory bank could accumulate errors that eventually outweigh the initial benefits.
- The approach suggests a general template for safe memory augmentation in any fixed model where retrieval risk must be managed.
Load-bearing premise
That uncertainty estimates and confidence scores can reliably identify when a memory intervention will help rather than harm the final answer.
What would settle it
An ablation that removes the routing, selective-acceptance, and governance components while keeping identical memory exposure and compute budget, then measures whether the arithmetic benchmark gains disappear or reverse.
Figures

read the original abstract
Prompt-injected memory can improve reasoning without updating model weights, but it also creates a control problem: retrieved content helps only when it is applied in the right state. We study this problem in a strict training-free setting and formulate it as applicability control: when to trigger a memory-assisted second pass, when to trust it, and how to maintain the memory bank over time. Our method combines uncertainty-based routing, confidence-based selective acceptance, bank selection across rule and exemplar memory, and evidence-based governance of the memory bank over time. Under a locked training-free protocol with compute-matched controls, it improves two core arithmetic benchmarks by +7.0 points on SVAMP and +7.67 points on ASDiv over baseline. The same architecture also transfers to QA and agent benchmarks with smaller positive effects and shows the same positive direction on a second checkpoint for the main arithmetic tasks. On arithmetic, the main empirical pattern is that the control architecture, rather than raw memory exposure, drives the improvements on SVAMP and ASDiv. Mechanistically, confidence separates helpful from harmful rule-bank interventions, and under fixed retrieval the repair-versus-corrupt difference localizes to rows whose retrieved set actually contains the edited entries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a control architecture for training-free memory use in LLMs to address when and how to apply prompt-injected memory for reasoning. It combines uncertainty-based routing to trigger a memory-assisted second pass, confidence-based selective acceptance, bank selection across rule and exemplar memory, and evidence-based governance to maintain the memory bank. In a locked training-free protocol with compute-matched controls, the method reports gains of +7.0 points on SVAMP and +7.67 points on ASDiv over baseline, with the central claim that the control architecture (rather than raw memory exposure) drives these improvements. Positive but smaller effects are shown on QA and agent benchmarks, with consistency on a second model checkpoint for arithmetic tasks. Mechanistically, confidence is said to separate helpful from harmful rule-bank interventions, with differences localizing to edited entries.
Significance. If the results and causal attribution hold under the locked protocol, this could be a meaningful contribution to retrieval-augmented generation and in-context learning by providing a training-free mechanism to control memory interventions. The use of compute-matched controls and cross-checkpoint consistency strengthens the empirical case for applicability control on arithmetic reasoning. It offers a practical path to leverage memory banks without fine-tuning while mitigating risks of harmful content.
major comments (2)
- [Abstract] Abstract: The central claim that 'the control architecture, rather than raw memory exposure, drives the improvements' on SVAMP and ASDiv rests on uncertainty-based routing and confidence-based selective acceptance correctly identifying beneficial interventions. However, the reported evidence is post-hoc (localization to rows with edited entries and confidence separating helpful/harmful cases); no controlled ablation is described that disables the uncertainty routing while holding retrieval, memory content, and compute fixed to test whether gains disappear. This is load-bearing for attributing the +7.0 / +7.67 point gains to the control components.
- [Results] Results (or equivalent experimental section): The abstract reports concrete benchmark gains under a locked protocol but provides no details on exact baselines, statistical significance testing, ablation studies isolating each control component, or data exclusion rules. These omissions leave the robustness of the reported improvements and the claim that differences localize to edited entries only partially supported.
minor comments (2)
- [Method] The abstract and method description could clarify the precise definitions and implementation details of 'uncertainty-based routing' and 'evidence-based governance' to aid reproducibility, as these are central to the architecture but described at a high level.
- [Experiments] Figure or table captions (if present in experimental results) should explicitly state the compute-matched baseline and whether memory exposure is held constant across conditions to make the 'control vs. raw exposure' comparison transparent.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We address the major comments point by point below, agreeing where the manuscript requires strengthening and outlining specific revisions to improve empirical rigor and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the control architecture, rather than raw memory exposure, drives the improvements' on SVAMP and ASDiv rests on uncertainty-based routing and confidence-based selective acceptance correctly identifying beneficial interventions. However, the reported evidence is post-hoc (localization to rows with edited entries and confidence separating helpful/harmful cases); no controlled ablation is described that disables the uncertainty routing while holding retrieval, memory content, and compute fixed to test whether gains disappear. This is load-bearing for attributing the +7.0 / +7.67 point gains to the control components.
Authors: We agree that a controlled ablation disabling uncertainty-based routing while holding retrieval, memory content, and compute fixed would provide stronger causal evidence for attributing the gains to the control architecture. The manuscript currently supports the claim via post-hoc analyses showing that, under fixed retrieval, repair-versus-corrupt differences localize to rows containing edited entries and that confidence separates helpful from harmful rule-bank interventions. To directly address this, we will add a new ablation in the revised manuscript that removes the uncertainty routing component (triggering memory-assisted passes unconditionally) and reports the resulting performance on SVAMP and ASDiv under otherwise identical conditions. This will test whether the +7.0 / +7.67 point gains diminish without the routing mechanism. revision: yes
-
Referee: [Results] Results (or equivalent experimental section): The abstract reports concrete benchmark gains under a locked protocol but provides no details on exact baselines, statistical significance testing, ablation studies isolating each control component, or data exclusion rules. These omissions leave the robustness of the reported improvements and the claim that differences localize to edited entries only partially supported.
Authors: We thank the referee for highlighting these omissions and agree that greater experimental detail is needed to support robustness. In the revised manuscript, we will expand the experimental section to include: (1) precise specifications of all baselines and how compute-matched controls were enforced in the locked training-free protocol; (2) statistical significance testing (e.g., paired t-tests or bootstrap confidence intervals) for the reported gains on SVAMP and ASDiv; (3) additional ablation studies that isolate the individual contributions of uncertainty routing, confidence-based selective acceptance, bank selection, and evidence-based governance; and (4) explicit clarification of any data exclusion or filtering rules applied to the benchmarks. These changes will better substantiate the localization claim and overall improvements. revision: yes
Circularity Check
No significant circularity; empirical claims with no derivations or self-referential reductions.
full rationale
The paper reports benchmark improvements (+7.0 on SVAMP, +7.67 on ASDiv) under a locked training-free protocol with compute-matched controls. No equations, derivations, fitted parameters, or mathematical claims appear in the provided text. The central claim—that the control architecture (uncertainty routing, confidence acceptance, evidence governance) rather than raw memory drives gains—is presented as an empirical pattern localized to edited entries, not as a reduction to self-defined quantities or self-citations. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are invoked for any derivation. The analysis remains self-contained against external benchmarks and does not reduce any prediction to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avi Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In International Conference on Learning Representations (ICLR), 2024
2024
-
[2]
Finite-time analysis of the multiarmed bandit problem
Peter Auer, Nicol\`o Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47 0 (2--3): 0 235--256, 2002
2002
-
[3]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[4]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In International Conference on Machine Learning (ICML), 2017
2017
-
[5]
REALM : Retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM : Retrieval-augmented language model pre-training. In International Conference on Machine Learning (ICML), 2020
2020
-
[6]
Probability inequalities for sums of bounded random variables
Wassily Hoeffding. Probability inequalities for sums of bounded random variables. Journal of the American Statistical Association, 58 0 (301): 0 13--30, 1963
1963
-
[7]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[8]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DaSilva, Eli Elhage, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[9]
Selective question answering under domain shift
Amita Kamath, Robin Jia, and Percy Liang. Selective question answering under domain shift. In Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[10]
Joshi, Hanna Mober, et al
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Mober, et al. Dspy: Compiling declarative language model calls into self-improving pipelines. In International Conference on Learning Representations (ICLR), 2024
2024
-
[11]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In International Conference on Learning Representations (ICLR), 2023
2023
-
[12]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[13]
Teaching models to express their uncertainty in words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. Transactions on Machine Learning Research, 2022
2022
-
[14]
Clin: A continually learning language agent for rapid task adaptation and generalization
Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Peter Jansen, Oyvind Tafjord, Niket Tandon, Li Zhang, Chris Callison-Burch, and Peter Clark. CLIN : A continually learning language agent for rapid task adaptation and generalization. arXiv preprint arXiv:2310.10134, 2023
-
[15]
A diverse corpus for evaluating and developing english math word problem solvers
Shen-yun Miao, Chao-Chun Liang, and Keh-Yih Su. A diverse corpus for evaluating and developing english math word problem solvers. In Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[16]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir Patil, Kevin Lin, Sarah Zhao, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
O'Brien, Carrie J
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In ACM Symposium on User Interface Software and Technology (UIST), 2023
2023
-
[18]
Are NLP models really able to solve simple math word problems? In Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2021
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2021. SVAMP benchmark
2021
-
[19]
John C. Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In Advances in Large Margin Classifiers. MIT Press, 1999
1999
-
[20]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2015
2015
-
[21]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[22]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023 a
work page internal anchor Pith review arXiv 2023
-
[23]
Scienceworld: Is your agent smarter than a 5th grader? In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022
Ruoyao Wang, Peter Jansen, Marc-Alexandre C\^ot\'e, and Prithviraj Ammanabrolu. Scienceworld: Is your agent smarter than a 5th grader? In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022
2022
-
[24]
Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. International Conference on Learning Representations (ICLR), 2023 b
2023
-
[25]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. In International Conference on Learning Representations (ICLR), 2024
2024
-
[26]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review arXiv 2024
-
[27]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Wang, Bowen Zheng, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. arXiv preprint arXiv:2309.03409, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Webshop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[30]
Seakr: Self-aware knowledge retrieval for adaptive retrieval augmented generation
Zijun Yao, Weijian Qi, Liangming Pan, Shulin Cao, Linmei Hu, Weichuan Liu, Lei Hou, and Juanzi Li. Seakr: Self-aware knowledge retrieval for adaptive retrieval augmented generation. In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[31]
Expel: LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: LLM agents are experiential learners. Proceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[32]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. In International Conference on Learning Representations (ICLR), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.