Recognition: unknown
Negative Advantage Is a Double-Edged Sword: Calibrating Advantage in GRPO for Deep Search
Pith reviewed 2026-05-10 04:10 UTC · model grok-4.3
The pith
CalibAdv resolves reward mismatches in GRPO for deep search by calibrating advantages with intermediate step correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
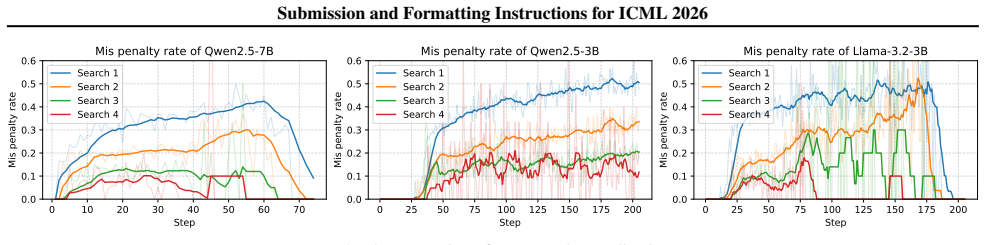
CalibAdv leverages the correctness of intermediate steps to downscale excessive negative advantages at a fine-grained level. It then rebalances positive and negative advantages in the answer component. This addresses the mismatch between step correctness and reward signals as well as the imbalance in advantages that causes training instability in GRPO for deep search tasks.
What carries the argument
CalibAdv, the advantage calibration technique that adjusts GRPO signals using intermediate step correctness to mitigate negative advantage problems.
If this is right
- Improved performance on question-answering tasks across seven benchmarks and three models.
- Greater training stability preventing natural language degradation or catastrophic collapse.
- More effective learning from multi-turn search interactions due to fine-grained advantage adjustments.
- Rebalanced advantages in answer components enhance overall policy optimization.
Where Pith is reading between the lines
- This calibration strategy could be adapted to other policy optimization algorithms facing similar sparse reward issues in agent training.
- Automating step correctness judgments reliably might open paths to scaling deep search without extra human oversight.
- Potential improvements in real-world agent reliability if the method generalizes beyond the tested benchmarks.
Load-bearing premise
Intermediate step correctness can be accurately and automatically determined without introducing biases or needing costly extra supervision.
What would settle it
A test where automatic judgments of intermediate step correctness are replaced with random or incorrect labels, checking if CalibAdv still outperforms baseline GRPO or instead harms performance.
Figures





read the original abstract
Deep search agents can autonomously initiate multi-turn interactions with search engines, thereby exhibiting strong question-answering capabilities. Such performance critically relies on Group Relative Policy Optimization (GRPO) as its core training algorithm. However, GRPO still faces several challenges in deep search settings. First, there exists a substantial mismatch between the correctness of intermediate steps and the reward signal, causing numerous correct intermediate steps to be incorrectly penalized when the final answer is wrong. Second, training is highly unstable, often resulting in degradation of natural language ability or even catastrophic training collapse. Our analysis attributes these issues to coarse-grained advantage assignment and an imbalance between positive and negative advantages. To address these problems, we propose CalibAdv, an advantage calibration method specifically designed for deep search tasks. Specifically, CalibAdv leverages the correctness of intermediate steps to downscale excessive negative advantages at a fine-grained level. It then rebalances positive and negative advantages in the answer component. Extensive experiments across three models and seven benchmarks demonstrate that CalibAdv improves both model performance and training stability. Our code is available at https://github.com/wujwyi/CalibAdv.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that GRPO for deep search agents suffers from a mismatch between intermediate step correctness and final-answer rewards (penalizing correct steps when the answer is wrong) plus training instability from coarse advantage assignment and positive/negative imbalance. It proposes CalibAdv, which downscales excessive negative advantages using per-step correctness labels at fine granularity and rebalances advantages in the answer component. Experiments across three models and seven benchmarks report gains in both performance and training stability.
Significance. If reproducible, CalibAdv offers a targeted fix for a practical pain point in RL for multi-turn search agents, where final-reward sparsity is acute. The multi-model, multi-benchmark evaluation and public code release are strengths that would make the result useful to the community if the core calibration procedure can be validated.
major comments (2)
- Abstract and §3 (CalibAdv description): The method for obtaining per-step correctness labels is never specified (rule-based, model-based, or oracle). Since CalibAdv's central operation is to downscale negative advantages using these labels, the absence of a reproducible procedure makes the claimed gains impossible to verify or replicate and is load-bearing for the entire contribution.
- §4 (Experiments): No ablation isolates the contribution of the step-correctness calibration from the rebalancing step or from any implicit supervision used to generate the labels. Without this, it is unclear whether the reported stability and accuracy improvements stem from the proposed mechanism or from an unreported source of additional signal.
minor comments (2)
- The paper should clarify how the 'answer component' is segmented from the search trajectory for the rebalancing step.
- Table and figure captions could more explicitly state the exact GRPO baseline variant and reward formulation used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us identify areas for improvement in clarity and experimental rigor. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract and §3 (CalibAdv description): The method for obtaining per-step correctness labels is never specified (rule-based, model-based, or oracle). Since CalibAdv's central operation is to downscale negative advantages using these labels, the absence of a reproducible procedure makes the claimed gains impossible to verify or replicate and is load-bearing for the entire contribution.
Authors: We agree that the original manuscript did not specify the procedure for obtaining per-step correctness labels with sufficient detail. In the revised version, we have added an explicit description in Section 3.1: labels are generated via a rule-based method that verifies whether each intermediate step contains facts or reasoning consistent with the ground-truth answer, using string matching against search results and logical entailment checks. No external models or oracles are used. We have also updated the abstract and included pseudocode plus implementation details in the released code to ensure full reproducibility. revision: yes
-
Referee: §4 (Experiments): No ablation isolates the contribution of the step-correctness calibration from the rebalancing step or from any implicit supervision used to generate the labels. Without this, it is unclear whether the reported stability and accuracy improvements stem from the proposed mechanism or from an unreported source of additional signal.
Authors: We acknowledge the value of isolating the components. The original experiments focused on the combined effect of CalibAdv, but we have now added dedicated ablations in the revised Section 4.3. These show that the step-correctness calibration is the main driver for mitigating excessive negative advantages, with rebalancing providing additional stability gains. As clarified in the updated Section 3, the labels rely solely on the rule-based procedure with no additional implicit supervision, confirming that the reported gains arise from the proposed calibration. revision: yes
Circularity Check
No circularity: empirical calibration method is self-contained
full rationale
The paper presents CalibAdv as a practical adjustment to GRPO that downscales negative advantages using per-step correctness labels and rebalances advantages in the answer component. This is motivated by observed mismatches between intermediate correctness and final rewards, with performance gains shown via experiments across models and benchmarks. No equations, derivations, or self-citations are provided that reduce the proposed calibration back to fitted inputs, self-defined quantities, or prior author results by construction. The method is introduced as an empirical fix rather than a first-principles result, making the derivation chain independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zerosearch: Incentivize the search capability of llms without searching, 2025
Hao Sun and Zile Qiao and Jiayan Guo and Xuanbo Fan and Yingyan Hou and Yong Jiang and Pengjun Xie and Yan Zhang and Fei Huang and Jingren Zhou , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.04588 , eprinttype =. 2505.04588 , timestamp =
-
[2]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song and Jinhao Jiang and Yingqian Min and Jie Chen and Zhipeng Chen and Wayne Xin Zhao and Lei Fang and Ji. R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2503.05592 , eprinttype =. 2503.05592 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2503.05592 2025
-
[3]
2025 , eprint=
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
Defeating the Training-Inference Mismatch via FP16 , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
On GRPO Collapse in Search-R1: The Lazy Likelihood-Displacement Death Spiral , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Deep Research: A Systematic Survey , author=. 2025 , eprint=
2025
-
[9]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
StepSearch: Igniting LLMs Search Ability via Step-Wise Proximal Policy Optimization , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
CriticSearch: Fine-Grained Credit Assignment for Search Agents via a Retrospective Critic , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
Repurposing Synthetic Data for Fine-grained Search Agent Supervision , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[15]
2020 , eprint=
Dense Passage Retrieval for Open-Domain Question Answering , author=. 2020 , eprint=
2020
-
[16]
2018 , eprint=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. 2018 , eprint=
2018
-
[17]
2020 , eprint=
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps , author=. 2020 , eprint=
2020
-
[18]
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[19]
2017 , eprint=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. 2017 , eprint=
2017
-
[20]
2023 , eprint=
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author=. 2023 , eprint=
2023
-
[21]
2022 , eprint=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. 2022 , eprint=
2022
-
[22]
2023 , eprint=
Measuring and Narrowing the Compositionality Gap in Language Models , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.