Recognition: unknown
Towards Disentangled Preference Optimization Dynamics: Suppress the Loser, Preserve the Winner
Pith reviewed 2026-05-10 04:56 UTC · model grok-4.3
The pith
Preference optimization can suppress rejected responses without harming chosen ones by satisfying the disentanglement band condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
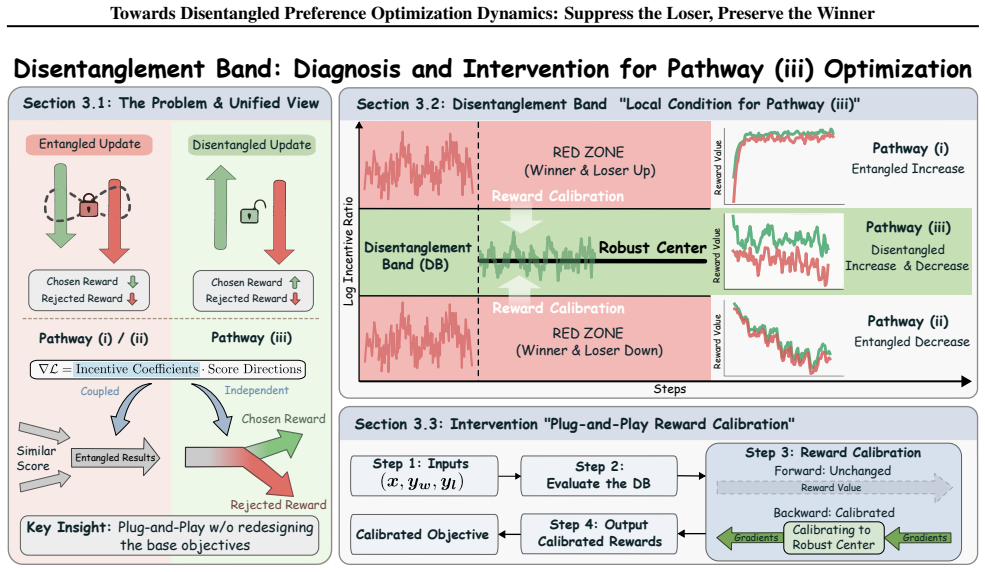
The incentive-score decomposition unifies preference optimization by demonstrating that objectives share identical local update directions and differ solely in scalar weights. Analysis of the resulting dynamics in chosen and rejected likelihoods identifies the disentanglement band, a testable condition ensuring training suppresses the rejected response while preserving the chosen one, possibly after an initial phase. Reward calibration is introduced to adaptively rebalance updates and satisfy this band.
What carries the argument
The disentanglement band (DB), a condition on the relative changes in likelihoods of chosen and rejected responses that is derived from the incentive-score decomposition.
If this is right
- Reward calibration applies to existing preference optimization objectives without redesigning the base loss.
- Training follows dynamics that decrease rejected-response likelihood while maintaining or increasing chosen-response likelihood.
- Improved downstream performance occurs across multiple alignment settings when the band condition is met.
Where Pith is reading between the lines
- The decomposition framework could simplify direct comparisons of alignment methods that were previously analyzed in isolation.
- Extending the band condition beyond current objectives might stabilize training in related reinforcement learning from human feedback setups.
- Tracking whether the band holds during training could provide an early diagnostic for whether alignment is proceeding as intended.
Load-bearing premise
Different preference optimization objectives share the same local update directions and differ only in scalar weights.
What would settle it
A new or existing preference optimization objective whose update directions do not match the shared structure, or an experiment where reward calibration fails to satisfy the disentanglement band and yields no performance gain.
Figures










read the original abstract
Preference optimization is widely used to align large language models (LLMs) with human preferences. However, many margin-based methods also suppress the chosen response when they try to suppress the rejected one, and there is no general way to prevent this across different objectives. We address this issue with a unified incentive-score decomposition of preference optimization, revealing that different objectives share the same local update directions and differ only in their scalar weights. This decomposition provides a common framework for analyzing objectives that were previously studied in separate settings. Building on this decomposition, by analyzing the dynamics of the chosen/rejected likelihoods, we identify the disentanglement band (DB), a simple, testable condition that tells us when training can follow the desired path: suppress the loser while preserving the winner, possibly after an early stage. Using the DB, we propose reward calibration (RC), a plug-and-play method that adaptively rebalances the updates for chosen and rejected responses to satisfy the DB, without redesigning the base objective. Empirical results show that RC leads to more disentangled dynamics, with better downstream performance observed across several settings. Our code is available at https://github.com/IceyWuu/DisentangledPreferenceOptimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that preference optimization objectives admit a unified incentive-score decomposition under which different methods share identical local update directions and differ only by scalar weights. Analyzing the resulting chosen/rejected likelihood dynamics yields the disentanglement band (DB) condition that characterizes when training suppresses the rejected response while preserving the chosen one (possibly after an initial phase). The authors introduce reward calibration (RC), a plug-and-play reweighting procedure that adaptively enforces the DB without altering the base objective, and report improved disentanglement and downstream performance across several empirical settings.
Significance. If the shared-direction property holds and the DB condition is shown to be non-circular, the work supplies a common analytic lens for margin-based preference methods that were previously treated separately. The RC method is attractive because it is objective-agnostic and code is released, which would allow immediate adoption and further testing. The empirical gains, if robust, would indicate that enforcing the DB improves alignment stability.
major comments (2)
- [§3 (unified incentive-score decomposition)] The central claim rests on the assertion that all considered objectives share identical local update directions (differing only in scalar weights). This must be shown explicitly for the full set of objectives studied; if higher-order terms or non-margin losses produce non-collinear gradients, the DB condition ceases to be well-defined and RC cannot be guaranteed to enforce the desired dynamics.
- [§4 (DB derivation and dynamics)] The DB condition is derived from the dynamics analysis under the decomposition. The manuscript must clarify whether the band boundaries and any scalar weights are obtained parameter-free from the derivation or are selected to match observed trajectories; the latter would render the DB a post-hoc description rather than a predictive criterion.
minor comments (2)
- [Abstract and §4] The abstract states that the desired path is followed 'possibly after an early stage'; the main text should state the precise conditions under which the early-stage exception occurs and provide a concrete example.
- [§5 (experiments)] Empirical tables would benefit from reporting the number of random seeds and statistical significance tests for the claimed performance improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below, providing clarifications on the derivations while preserving the manuscript's analytic scope.
read point-by-point responses
-
Referee: [§3 (unified incentive-score decomposition)] The central claim rests on the assertion that all considered objectives share identical local update directions (differing only in scalar weights). This must be shown explicitly for the full set of objectives studied; if higher-order terms or non-margin losses produce non-collinear gradients, the DB condition ceases to be well-defined and RC cannot be guaranteed to enforce the desired dynamics.
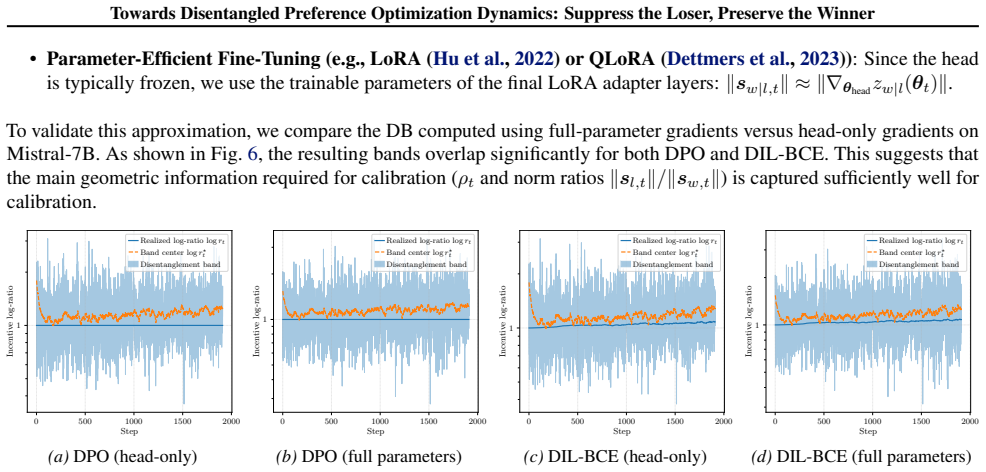
Authors: In §3 and Appendix A we derive the incentive-score decomposition explicitly for every objective studied (DPO, IPO, SimPO, KTO, and the others listed). Each derivation begins from the respective loss and shows that the resulting gradient with respect to the policy logits is identical in direction and differs only by a positive scalar multiplier. The analysis is strictly first-order and local; we make no claim about higher-order terms or non-margin losses, which lie outside the paper's stated focus on margin-based methods. We will add one clarifying sentence in §3 to restate this scope and the collinearity result. revision: partial
-
Referee: [§4 (DB derivation and dynamics)] The DB condition is derived from the dynamics analysis under the decomposition. The manuscript must clarify whether the band boundaries and any scalar weights are obtained parameter-free from the derivation or are selected to match observed trajectories; the latter would render the DB a post-hoc description rather than a predictive criterion.
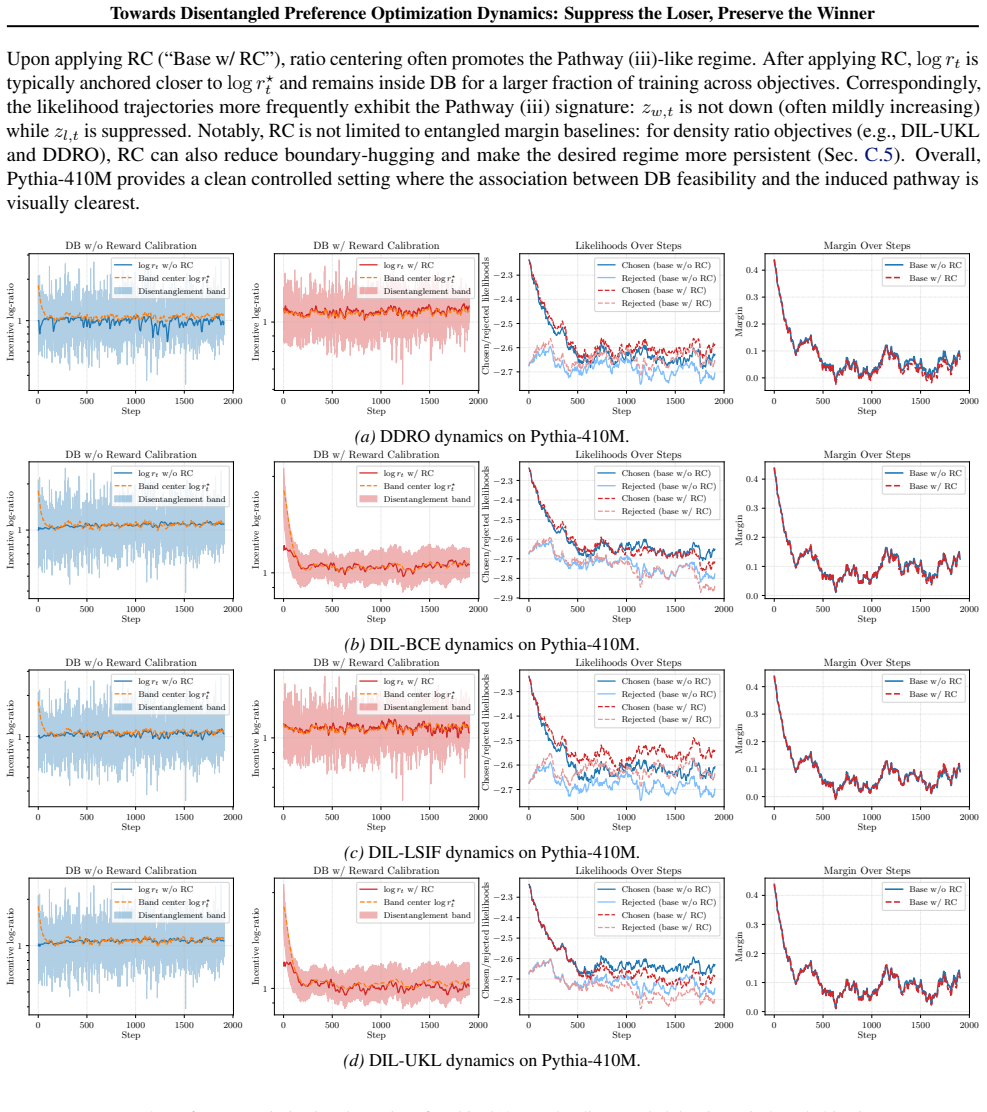
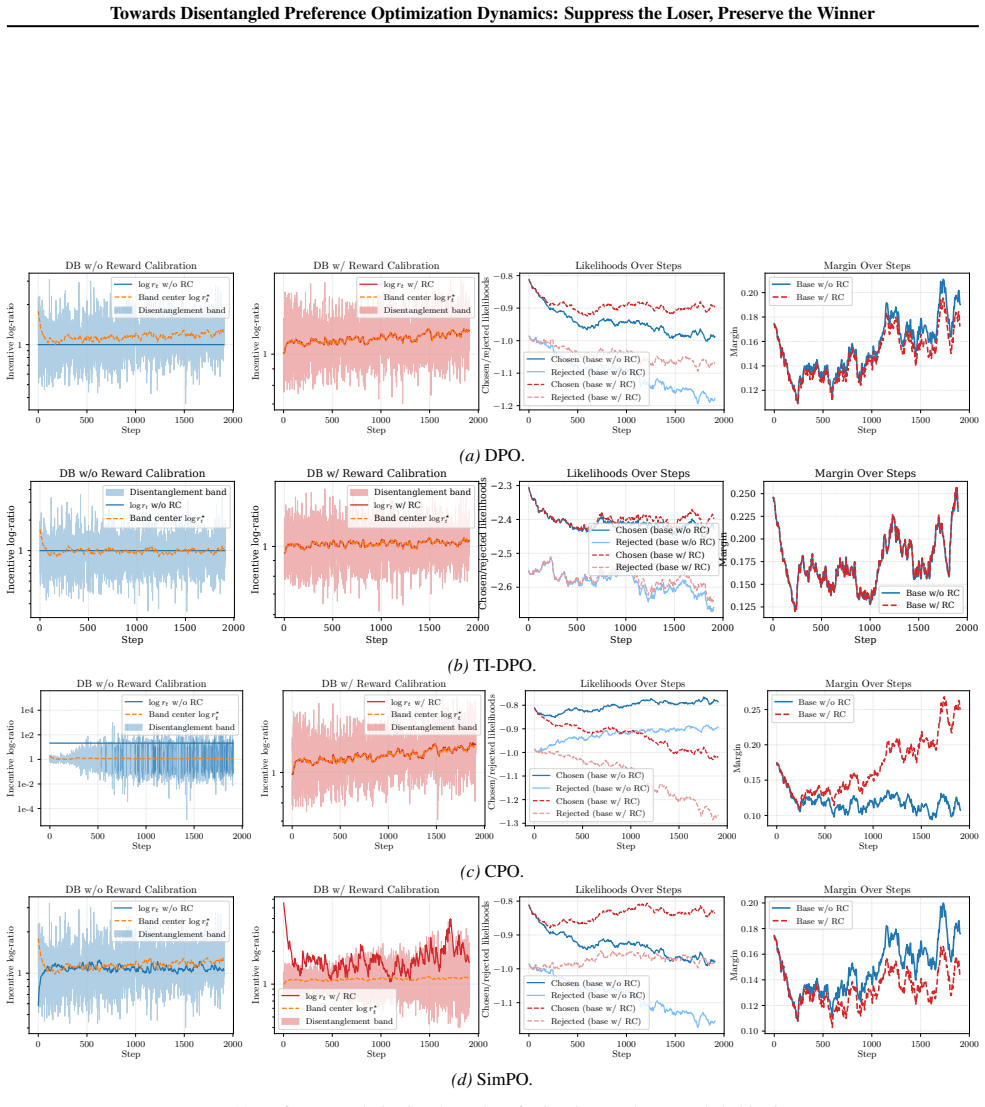
Authors: The DB boundaries are obtained parameter-free by analyzing the sign of the chosen and rejected likelihood derivatives under the incentive decomposition; the critical points are solved directly from the analytic expressions without reference to any empirical trajectories. The scalar weights are exactly those supplied by the §3 decomposition. We will expand the derivation in §4 and Appendix B to display the algebraic steps that yield the band limits, thereby making the parameter-free character explicit. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper first presents a unified incentive-score decomposition derived directly from the gradient structure of margin-based preference objectives, showing shared local update directions differing only by scalars. From this, the disentanglement band (DB) is obtained via explicit analysis of chosen/rejected likelihood dynamics. Reward calibration (RC) is then defined as an adaptive reweighting that enforces the DB condition. No load-bearing step reduces by construction to a fitted parameter, self-citation, or ansatz smuggled from prior work; the core claims rest on independent algebraic manipulation and are evaluated empirically across settings. The shared-direction property is shown rather than presupposed without derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different preference optimization objectives share the same local update directions and differ only in scalar weights.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=Oty1LQrnFc. Beeching, E., Fourrier, C., Habib, N., Han, S., Lam- bert, N., Rajani, N., Sanseviero, O., Tunstall, L., and Wolf, T. Open llm leaderboard (2023- 2024). https://huggingface.co/spaces/ open-llm-leaderboard-old/open_llm_ leaderboard, 2023. Biderman, S., Schoelkopf, H., Anthony, Q., Bradley, H., O’Brien, K., H...
-
[2]
org/CorpusID:244478113
URL https://api.semanticscholar. org/CorpusID:244478113. Chowdhury, S. R., Kini, A., and Natarajan, N. Provably robust DPO: Aligning language models with noisy feed- back. InInternational Conference on Machine Learning,
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
URL https://openreview.net/forum? id=yhpDKSw7yA. Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, volume 30, 2017. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have s...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
URL https://openreview.net/forum? id=OUIFPHEgJU. Dubois, Y ., Galambosi, B., Liang, P., and Hashimoto, T. B. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024. Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L., and Madry, A. Implementation matters in deep policy gradi...
work page internal anchor Pith review arXiv 2024
-
[5]
URL https://proceedings.mlr.press/ v202/gao23h.html. Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Le Noac’h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., and Zou, A. The language mod...
-
[6]
Measuring Mathematical Problem Solving With the MATH Dataset
URL https://api.semanticscholar. org/CorpusID:58068920. Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset, 2021. URLhttps://arxiv.org/abs/2103.03874. Higuchi, R. and Suzuki, T. Direct density ratio optimization: A statistically consistent app...
work page internal anchor Pith review arXiv 2021
-
[7]
Li, J., Chen, W., Liu, Y ., Yang, J., Zeng, D., and Zhou, Z
URL https://openreview.net/forum? id=Iytf59QZzl. Li, J., Chen, W., Liu, Y ., Yang, J., Zeng, D., and Zhou, Z. Neural ordinary differential equation networks for fintech applications using internet of things.IEEE Internet of Things Journal, 2024a. Li, J., Chen, W., Liu, Y ., Yang, J., Zhou, Z., and Zeng, D. Integrating ordinary differential equations with ...
-
[8]
URL https://openreview.net/forum? id=3Tzcot1LKb. Munos, R., Valko, M., Calandriello, D., Azar, M. G., Row- land, M., Guo, Z. D., Tang, Y ., Geist, M., Mesnard, T., Fiegel, C., Michi, A., Selvi, M., Girgin, S., Momchev, N., Bachem, O., Mankowitz, D. J., Precup, D., and Piot, B. Nash learning from human feedback. InInternational Conference on Machine Learni...
-
[9]
Razin, N., Malladi, S., Bhaskar, A., Chen, D., Arora, S., and Hanin, B
URL https://openreview.net/forum? id=HPuSIXJaa9. Razin, N., Malladi, S., Bhaskar, A., Chen, D., Arora, S., and Hanin, B. Unintentional unalignment: Likeli- hood displacement in direct preference optimization. In International Conference on Learning Representations,
-
[10]
URL https://openreview.net/forum? id=uaMSBJDnRv. Ren, Y . and Sutherland, D. J. Learning dynamics of LLM finetuning. InInternational Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=tPNHOoZFl9. Rhodes, B., Xu, K., and Gutmann, M. U. Telescoping density-ratio estimation. InAdvances in Neural Informa- tion Processing System...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
org/CorpusID:44112860
URL https://api.semanticscholar. org/CorpusID:44112860. 12 Towards Disentangled Preference Optimization Dynamics: Suppress the Loser, Preserve the Winner Sugiyama, M., Suzuki, T., and Kanamori, T. Density- ratio matching under the bregman divergence: a uni- fied framework of density-ratio estimation.Annals of the Institute of Statistical Mathematics, 64:1...
-
[12]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
URL https://api.semanticscholar. org/CorpusID:46615544. Suzgun, M., Scales, N., Sch ¨arli, N., Gehrmann, S., Tay, Y ., Chung, H. W., Chowdhery, A., Le, Q. V ., Chi, E. H., Zhou, D., and Wei, J. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv, 2022. Tang, Y ., Guo, Z. D., Zheng, Z., Calandriello, D., Munos, R., Rowland, M., Ri...
work page internal anchor Pith review arXiv 2022
-
[13]
URL https://openreview.net/forum? id=cMEnMVvMw9. Yang, Q. A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Xia, T., Ren, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
org/CorpusID:274859421
URL https://api.semanticscholar. org/CorpusID:274859421. Yu, H., Klami, A., Hyvarinen, A., Korba, A., and Chehab, O. Density ratio estimation with conditional probability paths. InInternational Conference on Machine Learning,
-
[15]
Yuan, H., Yuan, Z., Tan, C., Wang, W., Huang, S., and Huang, F
URL https://openreview.net/forum? id=Gn2izAiYzZ. Yuan, H., Yuan, Z., Tan, C., Wang, W., Huang, S., and Huang, F. RRHF: Rank responses to align language models with human feedback. InAdvances in Neural Information Processing Systems, 2023. URL https: //openreview.net/forum?id=EdIGMCHk4l. Yuan, H., Zeng, Y ., Wu, Y ., Wang, H., Wang, M., and Leqi, L. A comm...
2023
-
[16]
Zeng, Y ., Liu, G., Ma, W., Yang, N., Zhang, H., and Wang, J
URL https://openreview.net/forum? id=YaBiGjuDiC. Zeng, Y ., Liu, G., Ma, W., Yang, N., Zhang, H., and Wang, J. Token-level direct preference optimiza- tion. InInternational Conference on Machine Learning,
-
[17]
Semantic-Aware Logical Reasoning via a Semiotic Framework
URL https://openreview.net/forum? id=1RZKuvqYCR. Zhang, Y ., Zhang, X., Sheng, J., Li, W., Yu, J., Chen, Y .- P. P., Yang, W., and Song, Z. Semantic-aware logical reasoning via a semiotic framework, 2026. URL https: //arxiv.org/abs/2509.24765. Zhao, Y ., Joshi, R., Liu, T., Khalman, M., Saleh, M., and Liu, P. J. Slic-hf: Sequence likelihood calibration wi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.