Recognition: unknown
Long-Text-to-Image Generation via Compositional Prompt Decomposition
Pith reviewed 2026-05-10 04:17 UTC · model grok-4.3
The pith
PRISM allows pre-trained text-to-image models to generate images from long descriptive paragraphs by decomposing prompts into components and merging their noise predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRISM demonstrates that long prompts can be processed by pre-trained T2I models through a compositional pipeline: a lightweight module extracts constituent representations, the model computes separate noise predictions for each, and energy-based conjunction merges them into a single denoising step, yielding images that capture intricate details without retraining or fidelity loss.
What carries the argument
The PRISM pipeline of lightweight constituent extraction followed by independent noise predictions merged via energy-based conjunction.
Load-bearing premise
Independent noise predictions for each prompt component can be merged via energy-based conjunction without introducing inconsistencies or losing global scene coherence.
What would settle it
Generate an image from a long prompt that describes multiple interacting objects with conflicting spatial or attribute details and check whether the output shows all elements combined coherently or exhibits mismatches and omissions.
Figures










read the original abstract
While modern text-to-image (T2I) models excel at generating images from intricate prompts, they struggle to capture the key details when the inputs are descriptive paragraphs. This limitation stems from the prevalence of concise captions that shape their training distributions. Existing methods attempt to bridge this gap by either fine-tuning T2I models on long prompts, which generalizes poorly to longer lengths; or by projecting the oversize inputs into normal-prompt space and compromising fidelity. We propose Prompt Refraction for Intricate Scene Modeling (PRISM), a compositional approach that enables pre-trained T2I models to process long sequence inputs. PRISM uses a lightweight module to extract constituent representations from the long prompts. The T2I model makes independent noise predictions for each component, and their outputs are merged into a single denoising step using energy-based conjunction. We evaluate PRISM across a wide range of model architectures, showing comparable performances to models fine-tuned on the same training data. Furthermore, PRISM demonstrates superior generalization, outperforming baseline models by 7.4% on prompts over 500 tokens in a challenging public benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a compositional method for long-text-to-image generation. It uses a lightweight module to extract constituent representations from long prompts, runs a frozen pre-trained T2I model to obtain independent noise predictions for each component, and merges these into a single denoising step via energy-based conjunction. The central claims are that this achieves performance comparable to models fine-tuned on the same data while demonstrating superior generalization, outperforming baselines by 7.4% on prompts over 500 tokens in a public benchmark.
Significance. If the energy-based merging can be shown to preserve global scene coherence without introducing contradictions on shared variables, the approach would be significant as a training-free way to extend existing T2I models to complex, long-form prompts, addressing a core limitation of short-caption training distributions and offering better generalization than fine-tuning.
major comments (3)
- [§3.2] §3.2 (energy-based conjunction): No derivation or analysis is provided showing that the operator is closed under the diffusion process or approximates the joint posterior over the full prompt; independent per-component predictions can conflict on shared attributes such as lighting, scale, or background, which directly undermines the claim that the method produces coherent images for interacting scene elements.
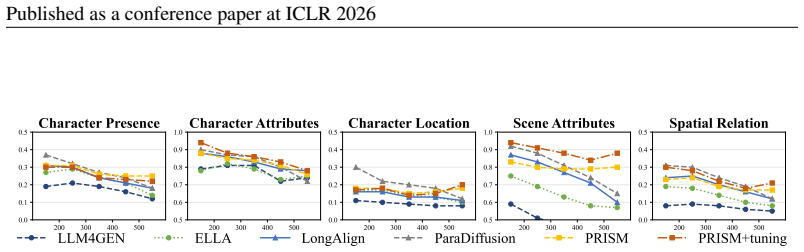
- [§4] §4 (quantitative evaluation): The headline 7.4% gain on >500-token prompts and the 'comparable performance' claim are reported without error bars, number of runs, precise benchmark definition, or controls for prompt length distribution, making it impossible to assess whether the generalization result is robust or load-bearing.
- [§3.1] §3.1 (constituent extraction): The assumption that the lightweight module accurately decomposes the prompt without error propagation into the merging step is not supported by ablations or failure-case analysis, yet it is required for the independent noise predictions to remain valid inputs to the conjunction operator.
minor comments (2)
- [Abstract] The abstract states results 'across a wide range of model architectures' but does not name them; adding the specific backbones (e.g., Stable Diffusion v1.5, SDXL) would improve clarity.
- [§3.2] Notation for the energy function in the conjunction step could be defined more explicitly (e.g., explicit form of E and how it is computed from the per-component scores).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (energy-based conjunction): No derivation or analysis is provided showing that the operator is closed under the diffusion process or approximates the joint posterior over the full prompt; independent per-component predictions can conflict on shared attributes such as lighting, scale, or background, which directly undermines the claim that the method produces coherent images for interacting scene elements.
Authors: We agree that the current manuscript does not include a formal derivation establishing closure under the diffusion process or an exact approximation to the joint posterior. The energy-based conjunction is implemented as a minimization over an additive energy function derived from the per-component noise predictions, which empirically favors consistent values on shared attributes. To strengthen this section, we will add a new subsection in §3.2 providing a brief analysis of the operator's properties, including its relation to the joint score and discussion of potential conflicts, supported by additional qualitative examples and quantitative coherence metrics on shared scene elements. revision: yes
-
Referee: [§4] §4 (quantitative evaluation): The headline 7.4% gain on >500-token prompts and the 'comparable performance' claim are reported without error bars, number of runs, precise benchmark definition, or controls for prompt length distribution, making it impossible to assess whether the generalization result is robust or load-bearing.
Authors: The referee correctly identifies that the reported results lack statistical rigor. The 7.4% improvement was obtained from a single evaluation pass on the public benchmark. In the revised manuscript we will re-evaluate all methods over five independent runs, report means and standard deviations, provide the exact benchmark construction details, and include controls that stratify results by prompt-length bins to confirm the generalization advantage is not an artifact of distribution shift. revision: yes
-
Referee: [§3.1] §3.1 (constituent extraction): The assumption that the lightweight module accurately decomposes the prompt without error propagation into the merging step is not supported by ablations or failure-case analysis, yet it is required for the independent noise predictions to remain valid inputs to the conjunction operator.
Authors: We recognize that the manuscript currently provides limited validation of the decomposition module. We will augment §3.1 and the experiments section with new ablations that quantify decomposition accuracy (via human and automatic metrics) and measure downstream impact on image quality when decomposition errors are introduced. We will also add a dedicated failure-case analysis illustrating cases of error propagation and how the conjunction step partially mitigates them. revision: yes
Circularity Check
No significant circularity detected in PRISM derivation
full rationale
The paper's core derivation introduces a compositional pipeline: a lightweight extraction module decomposes long prompts into constituents, a frozen pre-trained T2I model produces independent noise predictions per constituent, and an energy-based conjunction merges them into one denoising step. Performance claims (comparable to fine-tuned models, +7.4% on >500-token prompts) rest on empirical evaluation against public benchmarks rather than any algebraic reduction of outputs to inputs. No equations or self-citations are presented that would make the generalization result equivalent to fitted parameters or prior author results by construction; the conjunction operator and extraction module are treated as independent mechanisms whose validity is assessed externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.01103 , year=
Compositional generative modeling: A single model is not all you need , author=. arXiv preprint arXiv:2402.01103 , year=
-
[2]
International conference on machine learning , pages=
Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[3]
European conference on computer vision , pages=
Compositional visual generation with composable diffusion models , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[4]
2025 , school=
Learning Generalizable Systems by Learning Composable Energy Landscapes , author=. 2025 , school=
2025
-
[5]
Planning with Diffusion for Flexible Behavior Synthesis
Planning with diffusion for flexible behavior synthesis , author=. arXiv preprint arXiv:2205.09991 , year=
work page internal anchor Pith review arXiv
-
[6]
arXiv preprint arXiv:2306.01872 , year=
Probabilistic adaptation of text-to-video models , author=. arXiv preprint arXiv:2306.01872 , year=
-
[7]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Unsupervised compositional concepts discovery with text-to-image generative models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[8]
Advances in Neural Information Processing Systems , volume=
Unsupervised learning of compositional energy concepts , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:2406.19298 , year=
Compositional image decomposition with diffusion models , author=. arXiv preprint arXiv:2406.19298 , year=
-
[10]
arXiv preprint arXiv:2506.08894 , year=
Product of Experts for Visual Generation , author=. arXiv preprint arXiv:2506.08894 , year=
-
[11]
The Twelfth International Conference on Learning Representations , year=
Probabilistic adaptation of black-box text-to-video models , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
Multidiffusion: Fusing diffusion paths for controlled image generation,
Multidiffusion: Fusing diffusion paths for controlled image generation.(2023) , author=. URL https://arxiv. org/abs/2302.08113 , year=
-
[13]
arXiv preprint arXiv:2503.01145 , year=
Coind: Enabling logical compositions in diffusion models , author=. arXiv preprint arXiv:2503.01145 , year=
-
[14]
arXiv preprint arXiv:2502.04549 , year=
Mechanisms of projective composition of diffusion models , author=. arXiv preprint arXiv:2502.04549 , year=
-
[15]
Advances in neural information processing systems , volume=
Implicit generation and modeling with energy based models , author=. Advances in neural information processing systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Compositional visual generation with energy based models , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[18]
arXiv preprint arXiv:2309.00966 , year=
Compositional diffusion-based continuous constraint solvers , author=. arXiv preprint arXiv:2309.00966 , year=
-
[19]
Compositional risk minimization , author=. arXiv preprint arXiv:2410.06303 , year=
-
[20]
Advances in neural information processing systems , volume=
Compositional sculpting of iterative generative processes , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[22]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[23]
International conference on machine learning , pages=
Improved denoising diffusion probabilistic models , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[24]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[25]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow straight and fast: Learning to generate and transfer data with rectified flow , author=. arXiv preprint arXiv:2209.03003 , year=
work page internal anchor Pith review arXiv
-
[26]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Hierarchical text-conditional image generation with clip latents , author=. arXiv preprint arXiv:2204.06125 , volume=
work page internal anchor Pith review arXiv
-
[29]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[30]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[31]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=
FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=. arXiv e-prints , pages=
-
[33]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[34]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Sdxl: Improving latent diffusion models for high-resolution image synthesis , author=. arXiv preprint arXiv:2307.01952 , year=
work page internal anchor Pith review arXiv
-
[35]
Computer Science
Improving image generation with better captions , author=. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf , volume=
-
[36]
2025 , howpublished=
OpenAI , title=. 2025 , howpublished=
2025
-
[37]
2025 , howpublished=
Google , title=. 2025 , howpublished=
2025
-
[38]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[39]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[40]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Ella: Equip diffusion models with llm for enhanced semantic alignment , author=. arXiv preprint arXiv:2403.05135 , year=
work page internal anchor Pith review arXiv
-
[42]
Longalign: A recipe for long context alignment of large language models , author=. arXiv preprint arXiv:2401.18058 , year=
-
[43]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Llm4gen: Leveraging semantic representation of llms for text-to-image generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[44]
International Journal of Computer Vision , pages=
Paragraph-to-image generation with information-enriched diffusion model , author=. International Journal of Computer Vision , pages=. 2025 , publisher=
2025
-
[45]
European Conference on Computer Vision , pages=
An empirical study and analysis of text-to-image generation using large language model-powered textual representation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[46]
European Conference on Computer Vision , pages=
Bridging different language models and generative vision models for text-to-image generation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[47]
arXiv preprint arXiv:2505.16915 , year=
DetailMaster: Can Your Text-to-Image Model Handle Long Prompts? , author=. arXiv preprint arXiv:2505.16915 , year=
-
[48]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Clipscore: A reference-free evaluation metric for image captioning , author=. arXiv preprint arXiv:2104.08718 , year=
work page internal anchor Pith review arXiv
-
[49]
European Conference on Computer Vision , pages=
Evaluating text-to-visual generation with image-to-text generation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[50]
Hpsv3: Towards wide-spectrum human preference score
HPSv3: Towards Wide-Spectrum Human Preference Score , author=. arXiv preprint arXiv:2508.03789 , year=
-
[51]
Advances in neural information processing systems , volume=
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. Advances in neural information processing systems , volume=
-
[52]
Advances in Neural Information Processing Systems , volume=
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[54]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[55]
Advances in neural information processing systems , volume=
Pick-a-pic: An open dataset of user preferences for text-to-image generation , author=. Advances in neural information processing systems , volume=
-
[56]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Human preference score: Better aligning text-to-image models with human preference , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[57]
Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400,
Directly fine-tuning diffusion models on differentiable rewards , author=. arXiv preprint arXiv:2309.17400 , year=
-
[58]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[59]
Qwen-image technical report , author=. arXiv preprint arXiv:2508.02324 , year=
work page internal anchor Pith review arXiv
-
[60]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[62]
European Conference on Computer Vision , pages=
Sharegpt4v: Improving large multi-modal models with better captions , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[63]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.