Recognition: unknown
From Program Slices to Causal Clarity: Evaluating Faithful, Actionable LLM-Generated Failure Explanations via Context Partitioning and LLM-as-a-Judge
Pith reviewed 2026-05-10 04:27 UTC · model grok-4.3
The pith
Varying the composition of debugging context causally changes the quality of LLM-generated failure explanations, with targeted artifacts yielding better causal and actionable insights than large undifferentiated contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
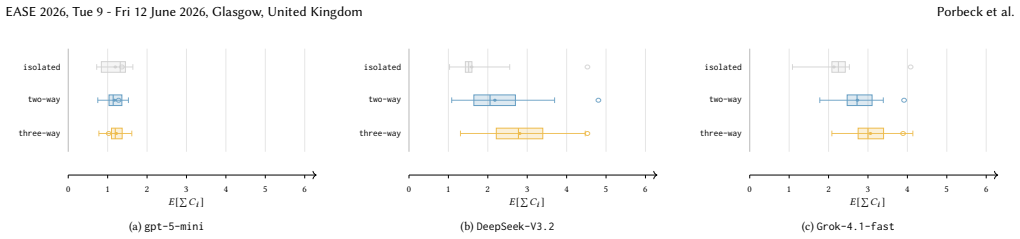
The central claim is that explanation quality is causally affected by context composition. Evidence-rich, failure-specific artifacts improve causal and action-oriented quality, whereas overly large contexts tend to yield vague explanations. Higher explanation-score quartiles are associated with higher downstream repair pass rates and, for some models, with fixes that are closer to the reference minimal fixes. In contrast, low-score quartiles can even underperform the no-explanation baseline.
What carries the argument
Systematic context partitioning into 93 configurations on real bugs, evaluated with an LLM-as-a-judge on six criteria for faithful and actionable explanations.
If this is right
- Evidence-rich, failure-specific artifacts improve causal and action-oriented quality of explanations.
- Overly large contexts tend to yield vague explanations.
- Higher explanation-score quartiles are associated with higher downstream repair pass rates.
- For some models, higher-quality explanations produce fixes closer to the reference minimal fixes.
- Low-score explanations can underperform the no-explanation baseline in repair tasks.
Where Pith is reading between the lines
- Debugging tools could benefit from automated selection of minimal, targeted context rather than full code dumps.
- The partitioning and LLM-judge method could extend to assessing explanations in related tasks like test generation or code review.
- If context effects generalize, then systems might incorporate dynamic context filtering to optimize for explanation quality before repair attempts.
Load-bearing premise
The six evaluation criteria and LLM-as-a-judge scores faithfully reflect true causal and actionable quality, and the 93 context configurations plus chosen real bugs are representative enough to support general claims about context effects.
What would settle it
A replication on a new set of bugs where varying context compositions produces no significant difference in explanation quality scores or no correlation with repair pass rates would falsify the central claim.
Figures




read the original abstract
Large language model (LLM)-based debugging systems can generate failure explanations, but these explanations may be incomplete or incorrect. Misleading explanations are harmful for downstream tasks (e.g., bug triage, bug fixing). We investigate how explanation quality is affected by various LLM context configurations. Existing work predominantly treats LLM-generated failure explanations as an ad hoc by-product of debugging or repair workflows, using generic prompting over undifferentiated artifacts such as code, tests, and error messages rather than targeting explanations as a first-class output with dedicated quality assessment. Consequently, existing approaches provide limited support for assessing whether these explanations capture the underlying fault-error-failure mechanism and for actionable next steps, and most techniques instead prioritize task success (e.g., patch correctness or review quality) over the explicit causal explanation quality. We systematically vary the debugging information to study how distinct context compositions affect the quality of LLM-generated failure explanations. Across 93 context configurations on real bugs and three economically viable models (gpt-5-mini, DeepSeek-V3.2, and Grok-4.1-fast), we evaluate explanations with six criteria and validate the LLM-as-a-judge scores against human ratings in a user study. Our results indicate that explanation quality is causally affected by context composition. Evidence-rich, failure-specific artifacts improve causal and action-oriented quality, whereas overly large contexts tend to yield vague explanations. Higher explanation-score quartiles are associated with higher downstream repair pass rates and, for some models, with fixes that are closer to the reference minimal fixes. In contrast, low-score quartiles can even underperform the no-explanation baseline. Reproduction package is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that systematically varying LLM context configurations (93 total) across three models on real bugs shows that explanation quality—assessed via six criteria using an LLM-as-a-judge and validated in a human study—is causally affected by context composition. Evidence-rich, failure-specific artifacts improve causal and action-oriented quality, while overly large contexts produce vague explanations. Higher explanation-score quartiles correlate with higher downstream repair pass rates and, for some models, fixes closer to reference minimal fixes; low-score explanations can underperform a no-explanation baseline.
Significance. If the results hold after addressing evaluation validity, the work provides useful empirical guidance for context design in LLM-based debugging tools, moving beyond ad-hoc prompting by treating explanations as a first-class output and linking quality directly to repair outcomes. Credit is due for the use of real bugs, multiple economically viable models, human validation of the judge, and the publicly available reproduction package, which supports reproducibility and verification.
major comments (3)
- [§4 (Evaluation Methodology)] §4 (Evaluation Methodology): The LLM-as-a-judge setup risks a measurement confound. If the judge prompt includes the full debugging context (or a superset of the artifacts supplied to the generator), larger contexts give the judge more reference material against which to detect vagueness or incompleteness. This could systematically depress scores for large-context explanations independently of any intrinsic defect, undermining the central causal claim that context composition directly affects explanation quality. The human validation study mitigates this only if it replicates the exact judge prompt and context exposure; the manuscript does not confirm this.
- [§3 (Methodology)] §3 (Methodology): Details on the precise partitioning rules used to create the 93 context configurations, the exclusion criteria for bugs and artifacts, and the rationale for selecting those specific configurations are insufficient. Without these, it is difficult to verify whether the observed effects on causal/actionable quality are robust to post-hoc design choices or generalizable beyond the chosen real bugs.
- [§5 (Results)] §5 (Results): The reported associations between explanation-score quartiles and repair pass rates (and proximity to minimal fixes) lack explicit statistical controls for potential confounders such as bug complexity, model-specific behavior, or multiple-comparison corrections across 93 configurations. This weakens the strength of the downstream-utility claims.
minor comments (1)
- [Abstract and §1] The abstract and introduction could more explicitly state the number of distinct bugs used and the exact definition of the six evaluation criteria to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to improve methodological transparency, address potential evaluation confounds, and strengthen the statistical presentation of results. Our point-by-point responses to the major comments are below.
read point-by-point responses
-
Referee: [§4 (Evaluation Methodology)] §4 (Evaluation Methodology): The LLM-as-a-judge setup risks a measurement confound. If the judge prompt includes the full debugging context (or a superset of the artifacts supplied to the generator), larger contexts give the judge more reference material against which to detect vagueness or incompleteness. This could systematically depress scores for large-context explanations independently of any intrinsic defect, undermining the central causal claim that context composition directly affects explanation quality. The human validation study mitigates this only if it replicates the exact judge prompt and context exposure; the manuscript does not confirm this.
Authors: We acknowledge the validity of this potential measurement confound. Our judge prompt evaluates the six criteria using a standardized, minimal reference set (primarily the bug report and targeted code elements for causality and actionability checks) rather than the full generator context. The human validation study used the identical prompt and the same reference materials. We will revise §4 to explicitly document the judge prompt, the exact context supplied to the judge, and confirm the matching exposure in the human study, allowing readers to evaluate the risk directly. revision: yes
-
Referee: [§3 (Methodology)] §3 (Methodology): Details on the precise partitioning rules used to create the 93 context configurations, the exclusion criteria for bugs and artifacts, and the rationale for selecting those specific configurations are insufficient. Without these, it is difficult to verify whether the observed effects on causal/actionable quality are robust to post-hoc design choices or generalizable beyond the chosen real bugs.
Authors: We agree that these details require expansion for full reproducibility and to demonstrate robustness. The 93 configurations arise from systematic combinations of failure-specific artifacts (static/dynamic slices, failing tests, error messages, and stack traces) at varying granularities. Exclusion criteria removed bugs without available ground-truth minimal patches or unparsable artifacts. We will add a dedicated subsection in the revised §3 describing the partitioning algorithm, complete exclusion rules, and the design rationale (to span minimal failure-specific to maximal undifferentiated contexts). revision: yes
-
Referee: [§5 (Results)] §5 (Results): The reported associations between explanation-score quartiles and repair pass rates (and proximity to minimal fixes) lack explicit statistical controls for potential confounders such as bug complexity, model-specific behavior, or multiple-comparison corrections across 93 configurations. This weakens the strength of the downstream-utility claims.
Authors: The §5 analysis is primarily descriptive and exploratory, using quartile trends to illustrate associations that hold consistently across models. We did not apply formal multiple-comparison corrections or full multivariate modeling in the main text. In the revision we will add supplementary regression analyses in §5 that control for bug complexity (proxied by LOC and number of failing tests) and include model as a fixed effect, together with an explicit statement on the exploratory framing and absence of correction across the configuration space. revision: partial
Circularity Check
No significant circularity: empirical evaluation on real bugs with external validation
full rationale
The paper reports an empirical study that systematically varies 93 context configurations on real bugs, generates explanations from three LLMs, scores them via six criteria using LLM-as-a-judge, validates those scores against a human user study, and correlates quartiles with downstream repair pass rates and minimal-fix distances. No mathematical derivation chain, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described methodology. Central claims rest on direct experimental measurements and external human ratings rather than reducing to quantities defined by the study's own inputs or prior author work. The study is therefore self-contained against its stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can produce explanations whose quality can be meaningfully scored on causal and actionability criteria
- domain assumption Human ratings constitute a reliable ground truth for validating automated explanation scores
Reference graph
Works this paper leans on
-
[1]
Fannar Steinn Aðalsteinsson, Björn Borgar Magnússon, Mislav Milicevic, Adam Nirving Davidsson, and Chih-Hong Cheng. 2025. Rethinking code re- view workflows with llm assistance: An empirical study. In2025 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). IEEE, 488–497
2025
- [2]
-
[3]
Chenxin An, Jun Zhang, Ming Zhong, Lei Li, Shansan Gong, Yao Luo, Jingjing Xu, and Lingpeng Kong. 2025. Why Does the Effective Context Length of LLMs Fall Short?. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=eoln5WgrPx
2025
-
[4]
Algirdas Avizienis, J-C Laprie, Brian Randell, and Carl Landwehr. 2004. Basic concepts and taxonomy of dependable and secure computing.IEEE transactions on dependable and secure computing1, 1 (2004), 11–33
2004
-
[5]
2026.DeepSeek-V3.2
DeepSeek-AI. 2026.DeepSeek-V3.2. https://huggingface.co/deepseek-ai/ DeepSeek-V3.2 Hugging Face model card
2026
-
[6]
Roosta, and Peyman Passban
Bryan Guan, Mehdi Rezagholizadeh, Tanya G. Roosta, and Peyman Passban
-
[7]
InFirst International KDD Workshop on Prompt Optimization, 2025
The Order Effect: Investigating Prompt Sensitivity to Input Order in LLMs. InFirst International KDD Workshop on Prompt Optimization, 2025. https: //openreview.net/forum?id=QcYyYvrPNU
2025
-
[8]
Halstead
Maurice H. Halstead. 1977.Elements of Software Science. Elsevier North-Holland, New York, NY
1977
-
[9]
Junda He, Jieke Shi, Terry Yue Zhuo, Christoph Treude, Jiamou Sun, Zhenchang Xing, Xiaoning Du, and David Lo. 2026. LLM-as-a-Judge for Software Engineering: Literature Review, Vision, and the Road Ahead.ACM Transactions on Software Engineering and Methodology(2026)
2026
-
[10]
Elenberg
Tyler Holloway and Ethan R. Elenberg. 2024. On the Role of Context Granular- ity in LLM-Driven Program Repair. InMachine Learning for Systems Workshop (NeurIPS ’24 Workshop). NeurIPS Foundation, Vancouver, BC, Canada, 8 pages. https://neurips.cc/virtual/2024/103609 Workshop paper
2024
-
[11]
Defects4j: a database of existing faults to enable controlled testing studies for java programs,
René Just, Darioush Jalali, Laura Inozemtseva, Michael D. Ernst, Reid Holmes, and Gordon Fraser. 2014. Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs. InProceedings of the 23rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2014). ACM, 312–315. doi:10.1145/2610384.2628055
-
[12]
Peter Kincaid, Robert P
J. Peter Kincaid, Robert P. Fishburne, Richard L. Rogers, and Brad S. Chissom. 1975.Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel. Technical Report Research Branch Report 8-75. Naval Technical Training Command. https: //stars.library.ucf.edu/istlibrary/56/
1975
-
[13]
Lucas Layman, Madeline Diep, Meiyappan Nagappan, Janice Singer, Robert Deline, and Gina Venolia. 2013. Debugging revisited: Toward understanding the debugging needs of contemporary software developers. In2013 ACM/IEEE international symposium on empirical software engineering and measurement. IEEE, 383–392
2013
-
[14]
Levenshtein
Vladimir I. Levenshtein. 1966. Binary Codes Capable of Correcting Deletions, Insertions and Reversals.Soviet Physics Doklady10, 8 (1966), 707–710
1966
- [15]
-
[16]
Available: https://doi.org/10.1162/tacl a 00449
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing. 2511–2522
2023
-
[18]
Junyi Lu, Xiaojia Li, Zihan Hua, Lei Yu, Shiqi Cheng, Li Yang, Fengjun Zhang, and Chun Zuo. 2025. Deepcrceval: Revisiting the evaluation of code review comment generation. InInternational Conference on Fundamental Approaches to Software Engineering. Springer, 43–64
2025
-
[19]
Luca Mariotto, Christian Medeiros Adriano, Daniel Burgstahler, René Eichhorn, and Holger Giese. 2025. From Assessment to Enhancement of Pull Requests at Scale: Aligning Code Reviews with Developer Competencies Using Large Language Models. To appear
2025
-
[20]
Christian Medeiros Adriano. 2022. Microtasking software failure resolution: early results.ACM SIGSOFT Software Engineering Notes44, 1 (2022), 36–39
2022
-
[21]
automatic patch generation learned from human-written patches
Martin Monperrus. 2014. A critical review of “automatic patch generation learned from human-written patches”: essay on the problem statement and the evaluation of automatic software repair. InProceedings of the 36th International Conference on Software Engineering (ICSE ’14). ACM, 234–242. doi:10.1145/2568225.2568324
-
[22]
2026.openai/gpt-5-mini
OpenRouter. 2026.openai/gpt-5-mini. https://openrouter.ai/openai/gpt-5-mini Model route page
2026
-
[23]
2026.x-ai/grok-4.1-fast
OpenRouter. 2026.x-ai/grok-4.1-fast. https://openrouter.ai/x-ai/grok-4.1-fast Model route page
2026
-
[24]
2026.From Program Slices to Causal Clarity: Evaluating Faithful, Actionable LLM-Generated Failure Explanations via Context Partitioning and LLM- as-a-Judge
Julius Porbeck. 2026.From Program Slices to Causal Clarity: Evaluating Faithful, Actionable LLM-Generated Failure Explanations via Context Partitioning and LLM- as-a-Judge. Master’s thesis. Hasso Plattner Institute
2026
-
[25]
Zichao Qi, Fan Long, Sara Achour, and Martin Rinard. 2015. An Analysis of Patch Plausibility and Correctness for Generate-And-Validate Patch Generation Systems. (02 2015). doi:10.1145/2771783.2771791
-
[26]
Stefano Rando, Luca Romani, Alessio Sampieri, Luca Franco, John Yang, Yuta Kyuragi, Fabio Galasso, and Tatsunori Hashimoto. 2025. LongCodeBench: Evalu- ating Coding LLMs at 1M Context Windows. InSecond Conference on Language Modeling. https://openreview.net/forum?id=GFPoM8Ylp8
2025
- [27]
-
[28]
Ezekiel Soremekun, Lukas Kirschner, Marcel Böhme, and Andreas Zeller. 2021. Locating faults with program slicing: an empirical analysis.Empirical Software Engineering26, 3 (2021), 51
2021
-
[29]
J.M. Voas and K.W. Miller. 1995. Software testability: the new verification.IEEE Software12, 3 (1995), 17–28. doi:10.1109/52.382180
-
[30]
Xindi Wang, Mahsa Salmani, Parsa Omidi, Xiangyu Ren, Mehdi Rezagholizadeh, and Armaghan Eshaghi. 2024. Beyond the limits: a survey of techniques to extend the context length in large language models. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 8299–8307
2024
-
[31]
Ratnadira Widyasari, Jia Wei Ang, Truong Giang Nguyen, Neil Sharma, and David Lo. 2024. Demystifying faulty code: Step-by-step reasoning for explainable fault localization. In2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 568–579
2024
-
[32]
James Woodward. 1989. The Causal Mechanical Model of Explanation.Philoso- phy of Science56, 2 (1989), 345–363. https://conservancy.umn.edu/bitstreams/ f470d3c2-57fc-4764-8c0a-88c8747acc36/download Review of Wesley C. Salmon, Scientific Explanation and the Causal Structure of the World
1989
- [33]
-
[34]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.