Recognition: unknown
On the Importance and Evaluation of Narrativity in Natural Language AI Explanations
Pith reviewed 2026-05-10 05:17 UTC · model grok-4.3
The pith
Explanations for AI predictions become more understandable when written as narratives with continuous flow, cause-effect links, fluent phrasing, and varied wording instead of static feature lists.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Explanations for machine learning model behaviour should be presented as narratives rather than static lists of feature importances. Narratives support human understanding through four defining properties: continuous structure, cause-effect mechanisms, linguistic fluency, and lexical diversity. Standard token-probability or frequency-based NLP metrics cannot capture these properties and can be matched by non-explanatory text. Seven new automatic metrics are therefore defined to quantify narrative quality along the four dimensions, and benchmarking on six datasets shows they separate descriptive from narrative explanations more effectively than prior metrics. A set of problem-agnostic rulesis
What carries the argument
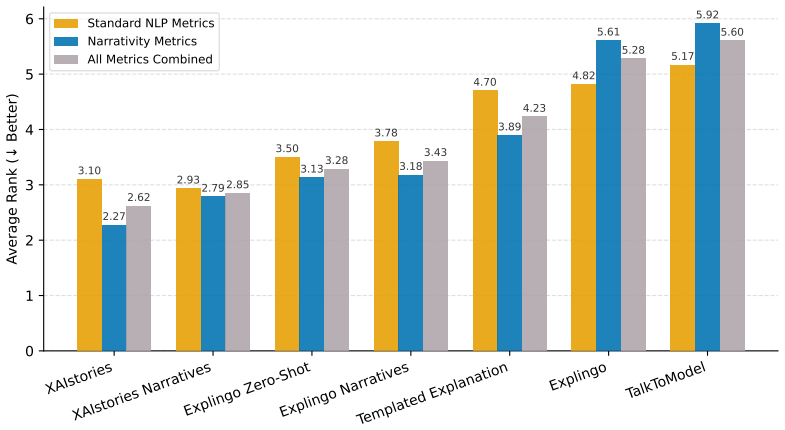
The four narrative properties (continuous structure, cause-effect mechanisms, linguistic fluency, and lexical diversity) together with the seven proposed automatic metrics that quantify each property in generated XAI text.
If this is right
- Current explanation generation methods can be evaluated and ranked more reliably by how well they meet the four narrative properties.
- Standard NLP metrics based on token probability are unsuitable for assessing explanatory quality because they accept empty text.
- Following the proposed generation rules produces explanations that exhibit stronger continuous structure, causal links, fluency, and lexical diversity.
- Benchmark results on six datasets establish a baseline for comparing future narrative explanation systems against existing ones.
Where Pith is reading between the lines
- Narrative XAI outputs could reduce misinterpretation of model decisions in domains where users must act on the explanation.
- The metrics might be extended to score explanations produced by large language models that were not part of the original benchmarks.
- Adopting narrative rules could make regulatory requirements for AI transparency easier to meet in practice.
Load-bearing premise
The four properties taken from social sciences and linguistics are the main drivers of human understanding for AI explanations, and the new metrics measure them without direct validation against human comprehension studies.
What would settle it
A controlled study in which people achieve equal or higher accuracy at predicting model behaviour from non-narrative feature lists or from text lacking one of the four properties, compared with full narrative explanations, or where the seven new metrics show no correlation with human ratings of explanation usefulness.
Figures





read the original abstract
Explainable AI (XAI) aims to make the behaviour of machine learning models interpretable, yet many explanation methods remain difficult to understand. The integration of Natural Language Generation into XAI aims to deliver explanations in textual form, making them more accessible to practitioners. Current approaches, however, largely yield static lists of feature importances. Although such explanations indicate what influences the prediction, they do not explain why the prediction occurs. In this study, we draw on insights from social sciences and linguistics, and argue that XAI explanations should be presented in the form of narratives. Narrative explanations support human understanding through four defining properties: continuous structure, cause-effect mechanisms, linguistic fluency, and lexical diversity. We show that standard Natural Language Processing (NLP) metrics based solely on token probability or word frequency fail to capture these properties and can be matched or exceeded by tautological text that conveys no explanatory content. To address this issue, we propose seven automatic metrics that quantify the narrative quality of explanations along the four identified dimensions. We benchmark current state-of-the-art explanation generation methods on six datasets and show that the proposed metrics separate descriptive from narrative explanations more reliably than standard NLP metrics. Finally, to further advance the field, we propose a set of problem-agnostic XAI Narrative generation rules for producing natural language XAI explanations, so that the resulting XAI Narratives exhibit stronger narrative properties and align with the findings from the linguistic and social science literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that XAI explanations should be presented as narratives rather than static feature lists, drawing on four properties from social sciences and linguistics (continuous structure, cause-effect mechanisms, linguistic fluency, and lexical diversity) to support human understanding. It demonstrates that standard token-probability and word-frequency NLP metrics can be matched or exceeded by tautological text with no explanatory value, proposes seven automatic metrics to quantify the four narrative dimensions, benchmarks these metrics on six datasets against state-of-the-art explanation generators to show improved separation of narrative from descriptive text, and offers a set of problem-agnostic generation rules intended to produce explanations with stronger narrative properties.
Significance. If the proposed metrics prove to correlate with human comprehension outcomes, the work could supply a practical evaluation framework and generation guidelines that move XAI beyond feature-importance lists toward more usable textual explanations. The tautological-text counter-example usefully exposes a concrete limitation of probability-based baselines. The benchmarking results on six datasets provide initial evidence that the new metrics discriminate better than prior approaches, which is a methodological contribution even if downstream human validation is still required.
major comments (2)
- [Abstract and §4] Abstract and §4 (Benchmarking): The claim that the four narrative properties are primary drivers of human understanding for XAI explanations rests on citations to external literature but is not tested with any human-subject experiments (comprehension tests, trust ratings, or decision-quality measures) comparing high- versus low-narrative explanations. The reported benchmarking only establishes that the metrics separate narrative from descriptive text more reliably than baselines; it does not establish that higher scores on the metrics predict improved human outcomes.
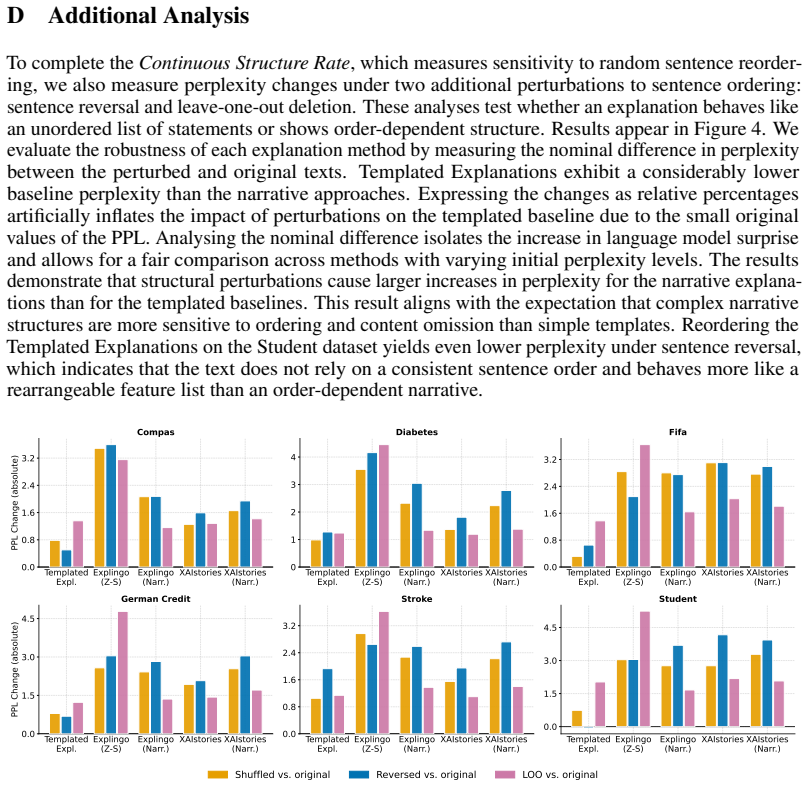
- [§3] §3 (Metric definitions): The seven automatic metrics are introduced without derivation details, formal definitions, or error analysis. No sensitivity studies (e.g., robustness to explanation length, domain shift, or lexical variation) are reported, which is load-bearing for the assertion that these metrics reliably quantify the four narrative properties across the six datasets.
minor comments (2)
- [Generation rules section] The generation rules in the final section would be easier to apply if accompanied by a short pseudocode or checklist format.
- A table summarizing the seven metrics, their formulas, and the narrative dimension each targets would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the scope and presentation of our contributions. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4] The claim that the four narrative properties are primary drivers of human understanding for XAI explanations rests on citations to external literature but is not tested with any human-subject experiments (comprehension tests, trust ratings, or decision-quality measures) comparing high- versus low-narrative explanations. The reported benchmarking only establishes that the metrics separate narrative from descriptive text more reliably than baselines; it does not establish that higher scores on the metrics predict improved human outcomes.
Authors: We agree that the manuscript motivates the four properties via citations to social science and linguistics literature rather than new human-subject studies, and that the benchmarking in §4 demonstrates improved separation of narrative from descriptive text (including via the tautological counter-example) without directly validating correlation to human comprehension outcomes. The paper does not claim such predictive validity for human results. In revision we will (i) update the abstract and §4 to explicitly qualify the claims as literature-grounded and (ii) add a limitations paragraph stating that direct human validation of the metrics remains future work. This is a partial revision because no new experiments are added. revision: partial
-
Referee: [§3] The seven automatic metrics are introduced without derivation details, formal definitions, or error analysis. No sensitivity studies (e.g., robustness to explanation length, domain shift, or lexical variation) are reported, which is load-bearing for the assertion that these metrics reliably quantify the four narrative properties across the six datasets.
Authors: We accept that §3 would be strengthened by additional formalization. In the revised version we will expand the section to supply (a) explicit mathematical definitions for each metric, (b) brief derivation notes linking each metric to its target narrative property, and (c) a new error-analysis subsection that includes sensitivity checks on explanation length, domain shift, and lexical variation performed on the existing six datasets. These additions address the referee’s concern without altering the core results. revision: yes
Circularity Check
No circularity: claims grounded in external literature with independent metrics and benchmarks
full rationale
The paper draws its four narrative properties (continuous structure, cause-effect mechanisms, linguistic fluency, lexical diversity) from cited social-science and linguistics sources rather than defining them in terms of its own outputs or metrics. It then proposes seven new automatic metrics and generation rules as original contributions, benchmarks them against standard NLP baselines on six external datasets, and demonstrates separation of narrative vs. descriptive text without any self-referential fitting, parameter renaming as prediction, or load-bearing self-citation chains. The derivation chain remains self-contained against external benchmarks and does not reduce any core claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Narrative explanations support human understanding through continuous structure, cause-effect mechanisms, linguistic fluency, and lexical diversity.
Reference graph
Works this paper leans on
-
[1]
Explanation in artificial intelligence: Insights from the social sciences.Artificial intelligence, 267:1–38, 2019
Tim Miller. Explanation in artificial intelligence: Insights from the social sciences.Artificial intelligence, 267:1–38, 2019
2019
-
[2]
David Martens, James Hinns, Camille Dams, Mark Vergouwen, and Theodoros Evgeniou. Tell me a story! Narrative-driven XAI with Large Language Models.Decision Support Systems, 191:114402, 2025. ISSN 0167-9236. doi: https://doi.org/10.1016/j.dss.2025.114402. URL https://www.sciencedirect.com/science/article/pii/S016792362500003X
-
[3]
Tim Miller, Piers Howe, and Liz Sonenberg. Explainable ai: Beware of inmates running the asylum or: How i learnt to stop worrying and love the social and behavioural sciences.arXiv preprint arXiv:1712.00547, 2017
-
[4]
Using narratives and storytelling to communicate science with nonexpert audiences.Proceedings of the national academy of sciences, 111(supplement_4):13614–13620, 2014
Michael F Dahlstrom. Using narratives and storytelling to communicate science with nonexpert audiences.Proceedings of the national academy of sciences, 111(supplement_4):13614–13620, 2014
2014
-
[5]
GraphXAIN: Narratives to Explain Graph Neural Networks
Mateusz Cedro and David Martens. GraphXAIN: Narratives to Explain Graph Neural Networks. InExplainable Artificial Intelligence, pages 91–114. Springer Nature Switzerland, 2025. ISBN 978-3-032-08327-2
2025
-
[6]
Explingo: Explaining ai predictions using large language models
Alexandra Zytek, Sara Pido, Sarah Alnegheimish, Laure Berti-Equille, and Kalyan Veera- machaneni. Explingo: Explaining ai predictions using large language models. In2024 IEEE International Conference on Big Data (BigData), pages 1197–1208. IEEE, 2024
2024
-
[7]
Explaining machine learning models with interactive natural language conversations using talktomodel.Nature Machine Intelligence, 5(8):873–883, 2023
Dylan Slack, Satyapriya Krishna, Himabindu Lakkaraju, and Sameer Singh. Explaining machine learning models with interactive natural language conversations using talktomodel.Nature Machine Intelligence, 5(8):873–883, 2023
2023
-
[8]
Explanation and scientific understanding.the Journal of Philosophy, 71(1): 5–19, 1974
Michael Friedman. Explanation and scientific understanding.the Journal of Philosophy, 71(1): 5–19, 1974
1974
-
[9]
A theoretical framework for narrative explanation in science.Science education, 89(4): 535–563, 2005
Stephen P Norris, Sandra M Guilbert, Martha L Smith, Shahram Hakimelahi, and Linda M Phillips. A theoretical framework for narrative explanation in science.Science education, 89(4): 535–563, 2005
2005
-
[10]
Harvard university press, 1986
Jerome S Bruner.Actual minds, possible worlds. Harvard university press, 1986
1986
-
[11]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017
2017
-
[12]
Why should I trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "Why should I trust you?" Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016
2016
-
[13]
Explaining data-driven document classifications.MIS quarterly, 38(1):73–100, 2014
David Martens and Foster Provost. Explaining data-driven document classifications.MIS quarterly, 38(1):73–100, 2014
2014
-
[14]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps.arXiv preprint arXiv:1312.6034, 2013. 21
work page Pith review arXiv 2013
-
[15]
R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient- based localization. In2017 IEEE International Conference on Computer Vision (ICCV), pages 618–626, 2017. doi: 10.1109/ICCV.2017.74
-
[16]
Gnnexplainer: Generating explanations for graph neural networks.Advances in neural information processing systems, 32, 2019
Zhitao Ying, Dylan Bourgeois, Jiaxuan You, Marinka Zitnik, and Jure Leskovec. Gnnexplainer: Generating explanations for graph neural networks.Advances in neural information processing systems, 32, 2019
2019
-
[17]
A survey on xai and natural language explanations.Information Processing & Management, 60 (1):103111, 2023
Erik Cambria, Lorenzo Malandri, Fabio Mercorio, Mario Mezzanzanica, and Navid Nobani. A survey on xai and natural language explanations.Information Processing & Management, 60 (1):103111, 2023
2023
-
[18]
A generative model for category text generation.Information Sciences, 450:301–315, 2018
Yang Li, Quan Pan, Suhang Wang, Tao Yang, and Erik Cambria. A generative model for category text generation.Information Sciences, 450:301–315, 2018. ISSN 0020-0255. doi: https://doi.org/10.1016/j.ins.2018.03.050. URL https://www.sciencedirect.com/scie nce/article/pii/S0020025518302366
-
[19]
Graphnarrator: Generating textual explanations for graph neural networks
Bo Pan, Zhen Xiong, Guanchen Wu, Zheng Zhang, Yifei Zhang, Yuntong Hu, and Liang Zhao. Graphnarrator: Generating textual explanations for graph neural networks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23–42, 2025
2025
-
[20]
Zero-shot natural language explanations
Fawaz Sammani and Nikos Deligiannis. Zero-shot natural language explanations. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://open review.net/forum?id=X6VVK8pIzZ
2025
-
[21]
An agentic approach to generating XAI-Narratives.arXiv preprint arXiv:2603.20003, 2026
Yifan He and David Martens. An agentic approach to generating XAI-Narratives.arXiv preprint arXiv:2603.20003, 2026
-
[22]
FLamE: Few-shot learning from nat- ural language explanations
Yangqiaoyu Zhou, Yiming Zhang, and Chenhao Tan. FLamE: Few-shot learning from nat- ural language explanations. InProceedings of the 61st Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 6743–6763. Associa- tion for Computational Linguistics, 2023. doi: 10.18653/v1/2023.acl-long.372. URL https://aclanthology....
-
[23]
Towards harnessing natural language genera- tion to explain black-box models
Ettore Mariotti, Jose M Alonso, and Albert Gatt. Towards harnessing natural language genera- tion to explain black-box models. In2nd Workshop on interactive natural language technology for explainable artificial intelligence, pages 22–27, 2020
2020
-
[24]
Perplexity—a measure of the difficulty of speech recognition tasks.The Journal of the Acoustical Society of America, 62(S1): S63–S63, 1977
Fred Jelinek, Robert L Mercer, Lalit R Bahl, and James K Baker. Perplexity—a measure of the difficulty of speech recognition tasks.The Journal of the Acoustical Society of America, 62(S1): S63–S63, 1977
1977
-
[25]
How good is my story? towards quantitative metrics for evaluating LLM-generated XAI narratives,
Timour Ichmoukhamedov, James Hinns, and David Martens. How good is my story? To- wards quantitative metrics for evaluating LLM-generated XAI narratives.arXiv preprint arXiv:2412.10220, 2024
-
[26]
Nasim Shirvani-Mahdavi and Chengkai Li. Rule2text: A framework for generating and evaluat- ing natural language explanations of knowledge graph rules.arXiv preprint arXiv:2508.10971, 2025
-
[27]
Perplexity from plm is unreliable for evaluating text quality.arXiv preprint arXiv:2210.05892,
Yequan Wang, Jiawen Deng, Aixin Sun, and Xuying Meng. Perplexity from plm is unreliable for evaluating text quality.arXiv preprint arXiv:2210.05892, 2022
-
[28]
Hashimoto, Hugh Zhang, and Percy Liang
Tatsunori B. Hashimoto, Hugh Zhang, and Percy Liang. Unifying human and statistical evaluation for natural language generation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1689–1701, Minneapolis, Minnesota,
2019
-
[29]
Association for Computational Linguistics. doi: 10.18653/v1/N19-1169
-
[30]
Arun Tejasvi Chaganty, Stephen Mussman, and Percy Liang. The price of debiasing automatic metrics in natural language evaluation.arXiv preprint arXiv:1807.02202, 2018. 22
-
[31]
Perplexity cannot always tell right from wrong.arXiv preprint arXiv:2601.22950, 2026
Petar Veliˇckovi´c, Federico Barbero, Christos Perivolaropoulos, Simon Osindero, and Razvan Pascanu. Perplexity cannot always tell right from wrong.arXiv preprint arXiv:2601.22950, 2026
-
[32]
What is wrong with perplexity for long-context language modeling?arXiv preprint arXiv:2410.23771,
Lizhe Fang, Yifei Wang, Zhaoyang Liu, Chenheng Zhang, Stefanie Jegelka, Jinyang Gao, Bolin Ding, and Yisen Wang. What is wrong with perplexity for long-context language modeling? arXiv preprint arXiv:2410.23771, 2024
-
[33]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[34]
Meteor: An automatic metric for mt evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005
2005
-
[35]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
2004
-
[36]
Bleurt: Learning robust metrics for text generation
Thibault Sellam, Dipanjan Das, and Ankur Parikh. Bleurt: Learning robust metrics for text generation. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 7881–7892, 2020
2020
-
[37]
Language model evaluation beyond perplexity
Clara Meister and Ryan Cotterell. Language model evaluation beyond perplexity. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5328–5339. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021....
-
[38]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[39]
Sule Tekkesinoglu and Lars Kunze. From feature importance to natural language explanations using llms with rag.arXiv preprint arXiv:2407.20990, 2024
-
[40]
Coh-metrix: Analysis of text on cohesion and language.Behavior research methods, instruments, & comput- ers, 36(2):193–202, 2004
Arthur C Graesser, Danielle S McNamara, Max M Louwerse, and Zhiqiang Cai. Coh-metrix: Analysis of text on cohesion and language.Behavior research methods, instruments, & comput- ers, 36(2):193–202, 2004
2004
-
[41]
Recollection versus imagination: Exploring human memory and cognition via neural language models
Maarten Sap, Eric Horvitz, Yejin Choi, Noah A Smith, and James Pennebaker. Recollection versus imagination: Exploring human memory and cognition via neural language models. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 1970–1978, 2020
1970
-
[42]
Arthur C. Graesser and Danielle S. McNamara. Computational analyses of multilevel discourse comprehension.Topics in Cognitive Science, 3(2):371–398, 2011. doi: https://doi.org/10.1111/ j.1756-8765.2010.01081.x. URL https://onlinelibrary.wiley.com/doi/abs/10.111 1/j.1756-8765.2010.01081.x
-
[43]
Gandomi, Fang Chen, and Andreas Holzinger
Jianlong Zhou, Amir H. Gandomi, Fang Chen, and Andreas Holzinger. Evaluating the quality of machine learning explanations: A survey on methods and metrics.Electronics, 10(5), 2021. ISSN 2079-9292. doi: 10.3390/electronics10050593. URL https://www.mdpi.com/207 9-9292/10/5/593
-
[44]
Scientific explanation and the causal structure of the world
Wesley C Salmon. Scientific explanation and the causal structure of the world. 1984
1984
-
[45]
Four decades of scientific explanation.[part 3] the second decade (1958-67): Manifest destiny–expansion and conflict
Wesley C Salmon. Four decades of scientific explanation.[part 3] the second decade (1958-67): Manifest destiny–expansion and conflict. 1989
1958
-
[46]
Connectives and narrative text: The role of continuity.Memory & Cognition, 25(2):227–236, 1997
John D Murray. Connectives and narrative text: The role of continuity.Memory & Cognition, 25(2):227–236, 1997. 23
1997
-
[47]
Coh-metrix: Providing multilevel analyses of text characteristics.Educational researcher, 40(5):223–234, 2011
Arthur C Graesser, Danielle S McNamara, and Jonna M Kulikowich. Coh-metrix: Providing multilevel analyses of text characteristics.Educational researcher, 40(5):223–234, 2011
2011
-
[48]
Deictic shift theory and the poetics of involvement in narrative
Mary Galbraith. Deictic shift theory and the poetics of involvement in narrative. InDeixis in narrative, pages 19–59. Psychology Press, 1995
1995
-
[49]
Updating a situation model: a memory-based text processing view.Journal of Experimental Psychology: Learning, Memory, and Cognition, 24(5):1200, 1998
Edward J O’Brien, Michelle L Rizzella, Jason E Albrecht, and Jennifer G Halleran. Updating a situation model: a memory-based text processing view.Journal of Experimental Psychology: Learning, Memory, and Cognition, 24(5):1200, 1998
1998
-
[50]
Discovering explanations.Explanation and cognition, pages 21–59, 2000
Herbert A Simon. Discovering explanations.Explanation and cognition, pages 21–59, 2000
2000
-
[51]
Studies in the logic of explanation.Philosophy of science, 15(2):135–175, 1948
Carl G Hempel and Paul Oppenheim. Studies in the logic of explanation.Philosophy of science, 15(2):135–175, 1948
1948
-
[52]
The relative ease of writing narrative text
Ronald T Kellogg et al. The relative ease of writing narrative text. 1991
1991
-
[53]
Examining the reading difficulty of secondary students with learning disabilities: Expository versus narrative text.Remedial and Special Education, 23(1): 31–41, 2002
Laura M Saenz and Lynn S Fuchs. Examining the reading difficulty of secondary students with learning disabilities: Expository versus narrative text.Remedial and Special Education, 23(1): 31–41, 2002
2002
-
[54]
Expository text
Charles A Weaver III and Walter Kintsch. Expository text. 1991
1991
-
[55]
Prediction and entropy of printed english.Bell system technical journal, 30 (1):50–64, 1951
Claude E Shannon. Prediction and entropy of printed english.Bell system technical journal, 30 (1):50–64, 1951
1951
-
[56]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review arXiv 1904
-
[57]
Constructing a lexicon of english discourse connectives
Debopam Das, Tatjana Scheffler, Peter Bourgonje, and Manfred Stede. Constructing a lexicon of english discourse connectives. InProceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, pages 360–365, 2018
2018
-
[58]
Marco Valentino and André Freitas. Scientific explanation and natural language: A unified epistemological-linguistic perspective for explainable ai.arXiv preprint arXiv:2205.01809, 2022
-
[59]
On the nature of explanation: An epistemological-linguistic perspective for explanation-based natural language inference.Philosophy & Technology, 37(3): 88, 2024
Marco Valentino and André Freitas. On the nature of explanation: An epistemological-linguistic perspective for explanation-based natural language inference.Philosophy & Technology, 37(3): 88, 2024
2024
-
[60]
Explanatory unification.Philosophy of Science, 48(4):507–531, 1981
Philip Kitcher. Explanatory unification.Philosophy of Science, 48(4):507–531, 1981. ISSN 00318248, 1539767X. URLhttp://www.jstor.org/stable/186834
1981
-
[61]
Free press New York, 1965
Carl G Hempel et al.Aspects of scientific explanation, volume 965. Free press New York, 1965
1965
-
[62]
Penn discourse treebank version 3.0.LDC2019T05, 2019
Rashmi Prasad, Bonnie Webber, Alan Lee, and Aravind Joshi. Penn discourse treebank version 3.0.LDC2019T05, 2019
2019
-
[63]
Improving neural language models with a continuous cache.arXiv preprint arXiv:1612.04426, 2016
Edouard Grave, Armand Joulin, and Nicolas Usunier. Improving neural language models with a continuous cache.arXiv preprint arXiv:1612.04426, 2016
-
[64]
Factuality enhanced language models for open-ended text generation
Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale N Fung, Mohammad Shoeybi, and Bryan Catanzaro. Factuality enhanced language models for open-ended text generation. In Advances in Neural Information Processing Systems, volume 35, pages 34586–34599. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper /2022/file/df438ca...
2022
-
[65]
A diversity- promoting objective function for neural conversation models
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and William B Dolan. A diversity- promoting objective function for neural conversation models. InProceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 110–119, 2016. 24
2016
-
[66]
Understanding the dilemma of explainable artificial intelligence: a proposal for a ritual dialog framework.Humanities and Social Sciences Communications, 11 (1):1–9, 2024
Aorigele Bao and Yi Zeng. Understanding the dilemma of explainable artificial intelligence: a proposal for a ritual dialog framework.Humanities and Social Sciences Communications, 11 (1):1–9, 2024
2024
-
[67]
Random forests.Machine learning, 45(1):5–32, 2001
Leo Breiman. Random forests.Machine learning, 45(1):5–32, 2001
2001
-
[68]
Towards unifying evaluation of counterfactual explanations: Leveraging large language models for human-centric assessments
Marharyta Domnich, Julius Välja, Rasmus Moorits Veski, Giacomo Magnifico, Kadi Tulver, Eduard Barbu, and Raul Vicente. Towards unifying evaluation of counterfactual explanations: Leveraging large language models for human-centric assessments. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 16308–16316, 2025
2025
-
[69]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
2006
-
[72]
Alexey Tikhonov, Igor Samenko, and Ivan P. Yamshchikov. StoryDB: Broad multi-language narrative dataset. In Yang Gao, Steffen Eger, Wei Zhao, Piyawat Lertvittayakumjorn, and Marina Fomicheva, editors,Proceedings of the 2nd Workshop on Evaluation and Comparison of NLP Systems, pages 32–39, Punta Cana, Dominican Republic, November 2021. Association for Comp...
-
[73]
Start the explanation immediately
-
[74]
Limit the entire answer to exactly {sentence_limit} sentences
-
[75]
Only mention the top {num_feat} most important features in the narrative
-
[76]
The goal is to have a narrative/story
Do not use tables or lists, or simply rattle through the features and/or nodes one by one. The goal is to have a narrative/story. **Content related rules**:
-
[77]
Be clear about what the model actually predicted for the {target_instance}
-
[78]
Make sure to clearly establish this the first time you refer to a feature
Discuss how the features contributed to final prediction. Make sure to clearly establish this the first time you refer to a feature
-
[79]
Consider the feature importance, feature values, and averages when referencing their relative importance
-
[80]
The reader should be able to tell what the order of importance of the features is based on their feature importance value
Begin the discussion of features by presenting those with the highest absolute feature importance values first. The reader should be able to tell what the order of importance of the features is based on their feature importance value
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.