Recognition: unknown
PARM: Pipeline-Adapted Reward Model
Pith reviewed 2026-05-10 05:12 UTC · model grok-4.3
The pith
A reward model trained on full pipeline outcomes aligns rewards with multi-stage LLM results using direct preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
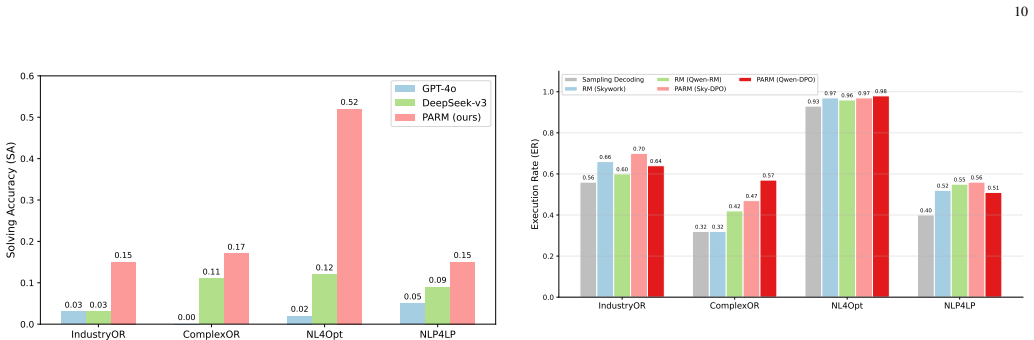
By collecting preference pairs from the outcomes of the entire pipeline rather than from single-stage generations, PARM produces reward signals that more reliably improve the quality and consistency of two-stage formulation-to-code pipelines on combinatorial optimization problems.
What carries the argument
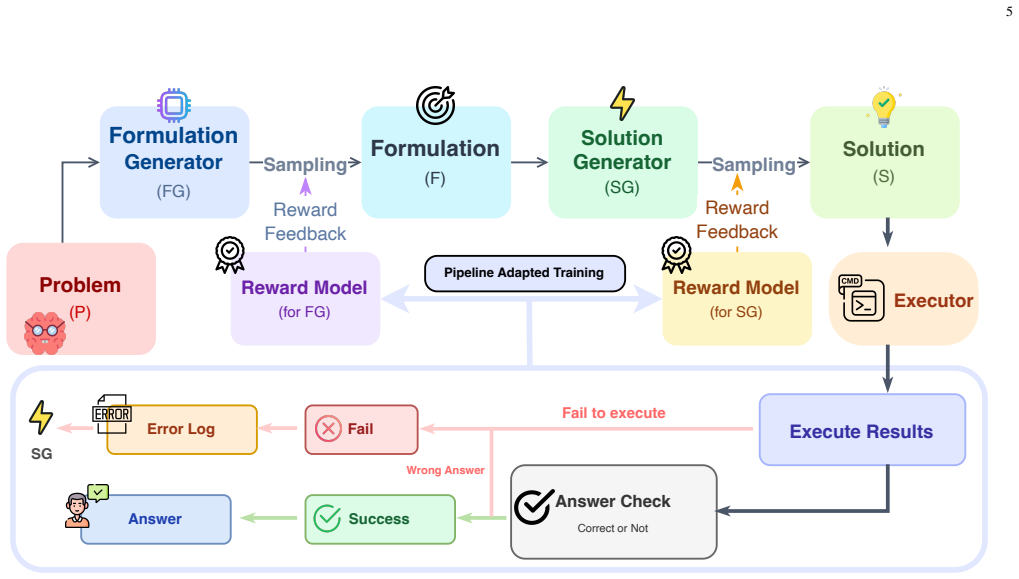
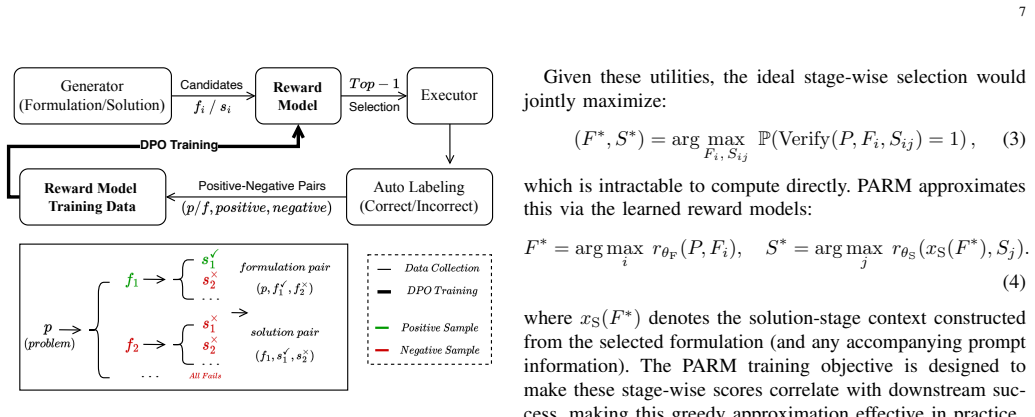
Pipeline-Adapted Reward Model (PARM) trained via direct preference optimization on data whose labels come from full pipeline execution feedback instead of isolated step judgments.
If this is right
- Raises execution rate and solving accuracy on four public combinatorial optimization benchmarks relative to standard reward models and sampling baselines.
- Increases stability of the generated pipeline outputs across multiple runs.
- Shows measurable transfer in a supplementary GSM8K experiment outside the original domain.
- Supplies a concrete way to incorporate downstream execution signals into reward training for chained LLM reasoning.
Where Pith is reading between the lines
- The same execution-feedback loop could be tried on pipelines that include planning, tool calls, or verification stages.
- Execution outcomes might replace some human preference data when scaling reward models to longer reasoning chains.
- End-to-end consistency checks could become a standard diagnostic when building reward models for any multi-step LLM workflow.
Load-bearing premise
The rewards learned from one fixed two-stage pipeline and four benchmarks will continue to improve results when the pipeline or the problem set changes.
What would settle it
Training PARM on the described data and then testing it on a three-stage pipeline or on non-optimization tasks where the gains in execution rate and accuracy disappear would show the central claim does not hold.
Figures




read the original abstract
Reward models (RMs) are central to aligning large language models (LLMs) with human preferences, powering RLHF and advanced decoding strategies. While most prior work focuses on single-step generation, real-world applications increasingly adopt multi-stage LLM pipelines, where effective reward guidance remains underexplored. We investigate this through code generation for combinatorial optimization, constructing a pipeline that integrates reward models into both formulation and solution stages. We identify a critical challenge: inconsistency between reward model predictions and actual pipeline execution outcomes. To address this, we propose the Pipeline-Adapted Reward Model (PARM), which leverages pipeline-specific data and direct preference optimization to align rewards with downstream feedback. We instantiate PARM as a two-stage pipeline (formulation -> code generation) and evaluate it on four public optimization benchmarks, measuring execution rate and solving accuracy against baselines and sampling methods. A supplementary cross-domain experiment on GSM8K assesses transferability. Results demonstrate that PARM consistently improves pipeline output quality and stability, providing new insights into reward modeling for multi-stage LLM reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Pipeline-Adapted Reward Model (PARM) to address inconsistencies between reward model predictions and downstream execution outcomes in multi-stage LLM pipelines. It constructs a two-stage formulation-to-code pipeline for combinatorial optimization, trains the reward model on pipeline-specific data via direct preference optimization (DPO), and evaluates execution rate and solving accuracy on four public benchmarks plus a GSM8K transfer test, claiming consistent improvements in output quality and stability over baselines.
Significance. If the empirical results hold with proper controls, the work is significant for extending reward modeling beyond single-step generation to multi-stage pipelines, an increasingly common setting in LLM applications. The pipeline-specific DPO adaptation is a practical approach that could generalize to other reasoning chains, and the cross-domain transfer experiment provides a useful initial check on broader applicability.
major comments (2)
- [Evaluation section] Evaluation section: the experiments are restricted to a single fixed two-stage (formulation → code) pipeline on four combinatorial optimization benchmarks plus one GSM8K test. No ablations vary pipeline depth, stage ordering, domain structure, or benchmark distributions, so it is unclear whether gains stem from genuine adaptation or from fitting to the tested interaction; this directly limits support for the claim of new insights into reward modeling for multi-stage LLM reasoning in general.
- [Results and method sections] Results and method sections: the abstract and high-level description report improvements without visible quantitative tables, error bars, or ablation details on the pipeline data construction and DPO objective; if these are present in the full manuscript they must be explicitly tied to the consistency claim, otherwise the soundness of the central empirical result cannot be assessed.
minor comments (2)
- Add a clear diagram of the two-stage pipeline and where the adapted reward model is applied at each stage to improve readability.
- Ensure all metric definitions (execution rate, solving accuracy) are stated with precise formulas or pseudocode in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, with clarifications on the existing results and planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the experiments are restricted to a single fixed two-stage (formulation → code) pipeline on four combinatorial optimization benchmarks plus one GSM8K test. No ablations vary pipeline depth, stage ordering, domain structure, or benchmark distributions, so it is unclear whether gains stem from genuine adaptation or from fitting to the tested interaction; this directly limits support for the claim of new insights into reward modeling for multi-stage LLM reasoning in general.
Authors: We acknowledge that the evaluation is confined to one representative two-stage pipeline (formulation to code generation) across the four optimization benchmarks and the GSM8K transfer test. This design choice enables a focused, reproducible demonstration of how pipeline-specific data and DPO can resolve reward-execution inconsistencies in a practical multi-stage setting. The core method—generating preferences from downstream pipeline outcomes and optimizing the reward model accordingly—is formulated to be applicable beyond this specific configuration. In the revised manuscript, we will add an expanded limitations and future work subsection that discusses extensions to varying pipeline depths, stage orderings, and other domains, while explicitly noting the current scope as a boundary on generalizability claims. The GSM8K results already provide initial cross-domain evidence supporting broader applicability. revision: partial
-
Referee: [Results and method sections] Results and method sections: the abstract and high-level description report improvements without visible quantitative tables, error bars, or ablation details on the pipeline data construction and DPO objective; if these are present in the full manuscript they must be explicitly tied to the consistency claim, otherwise the soundness of the central empirical result cannot be assessed.
Authors: The full manuscript presents the quantitative results in Section 4 (Experiments), including tables of execution rates and solving accuracies on the four benchmarks with standard deviations across multiple runs, plus ablation studies on pipeline data construction and the DPO objective in Section 3 and the appendix. These are directly linked to the consistency claim by quantifying how PARM reduces the gap between reward predictions and actual pipeline success (e.g., higher execution rates indicate better alignment with downstream outcomes). To improve clarity, we will insert explicit forward references from the abstract and introduction to these tables and ablations in the revised version. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical proposal for PARM using pipeline-specific data and DPO training to align rewards with downstream execution feedback in a two-stage formulation-to-code pipeline. No mathematical derivations, equations, or first-principles predictions are presented that reduce to the inputs by construction. Claims of improved quality and stability rest on benchmark evaluations (execution rate, solving accuracy) rather than tautological definitions or self-referential fits. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The work is self-contained as standard ML experimentation without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[2]
Reft: Reasoning with reinforced fine-tuning
T. Q. Luong, X. Zhang, Z. Jie, P. Sun, X. Jin, and H. Li, “Reft: Reasoning with reinforced fine-tuning,”arXiv preprint arXiv:2401.08967, 2024
-
[3]
WebGPT: Browser-assisted question-answering with human feedback
R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V . Kosaraju, W. Saunderset al., “Webgpt: Browser- assisted question-answering with human feedback,”arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review arXiv 2021
-
[4]
Learning to summarize with human feedback,
N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. V oss, A. Rad- ford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,”Advances in Neural Information Processing Systems, vol. 33, pp. 3008–3021, 2020
2020
-
[5]
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Y . Wu, M. Schuster, Z. Chen, Q. V . Le, M. Norouzi, W. Macherey, M. Krikun, Y . Cao, Q. Gao, K. Machereyet al., “Google’s neural machine translation system: Bridging the gap between human and machine translation,”arXiv preprint arXiv:1609.08144, 2016
work page internal anchor Pith review arXiv 2016
-
[6]
Correcting length bias in neural machine translation
K. Murray and D. Chiang, “Correcting length bias in neural machine translation,”arXiv preprint arXiv:1808.10006, 2018
-
[7]
Rest-mcts*: Llm self-training via process reward guided tree search
D. Zhang, S. Zhoubian, Y . Yue, Y . Dong, and J. Tang, “Rest-mcts*: Llm self-training via process reward guided tree search,”arXiv preprint arXiv:2406.03816, 2024
-
[8]
Pal: Program-aided language models,
L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y . Yang, J. Callan, and G. Neubig, “Pal: Program-aided language models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 10 764–10 799
2023
-
[9]
Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification,
A. Zhou, K. Wang, Z. Lu, W. Shi, S. Luo, Z. Qin, S. Lu, A. Jia, L. Song, M. Zhanet al., “Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification,” inThe Twelfth International Conference on Learning Representations
-
[10]
Orlm: Training large language models for optimization modeling,
Z. Tang, C. Huang, X. Zheng, S. Hu, Z. Wang, D. Ge, and B. Wang, “Orlm: Training large language models for optimization modeling,” arXiv preprint arXiv:2405.17743, 2024
-
[11]
C. Jiang, X. Shu, H. Qian, X. Lu, J. Zhou, A. Zhou, and Y . Yu, “Llmopt: Learning to define and solve general optimization problems from scratch,”arXiv preprint arXiv:2410.13213, 2024
-
[12]
Chain-of-experts: When llms meet complex operations research problems,
Z. Xiao, D. Zhang, Y . Wu, L. Xu, Y . J. Wang, X. Han, X. Fu, T. Zhong, J. Zeng, M. Songet al., “Chain-of-experts: When llms meet complex operations research problems,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[13]
Knowledge matters: Importance of prior information for optimization,
C ¸ . G¨ulc ¸ehre and Y . Bengio, “Knowledge matters: Importance of prior information for optimization,”The Journal of Machine Learning Re- search, vol. 17, no. 1, pp. 226–257, 2016
2016
-
[14]
Limits of end-to-end learning,
T. Glasmachers, “Limits of end-to-end learning,” inAsian conference on machine learning. PMLR, 2017, pp. 17–32
2017
-
[15]
Assessing satnet’s ability to solve the symbol grounding problem,
O. Chang, L. Flokas, H. Lipson, and M. Spranger, “Assessing satnet’s ability to solve the symbol grounding problem,”Advances in Neural Information Processing Systems, vol. 33, pp. 1428–1439, 2020
2020
-
[16]
Sub-task decomposition enables learning in sequence to sequence tasks,
N. Wies, Y . Levine, and A. Shashua, “Sub-task decomposition enables learning in sequence to sequence tasks,”arXiv preprint arXiv:2204.02892, 2022
-
[17]
Generated knowledge prompting for commonsense reasoning
J. Liu, A. Liu, X. Lu, S. Welleck, P. West, R. L. Bras, Y . Choi, and H. Hajishirzi, “Generated knowledge prompting for commonsense reasoning,”arXiv preprint arXiv:2110.08387, 2021
-
[18]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
C.-M. Chan, W. Chen, Y . Su, J. Yu, W. Xue, S. Zhang, J. Fu, and Z. Liu, “Chateval: Towards better llm-based evaluators through multi- agent debate,”arXiv preprint arXiv:2308.07201, 2023
work page internal anchor Pith review arXiv 2023
-
[19]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y . Li, “Api-bank: A comprehensive benchmark for tool-augmented llms,”arXiv preprint arXiv:2304.08244, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
Automated resource orchestration for large-scale heterogeneous applications,
Q. Liang, L. Xiao, and M. Hu, “Automated resource orchestration for large-scale heterogeneous applications,” in2025 IEEE 11th International Conference on High Performance and Smart Computing (HPSC). IEEE Computer Society, 2025, pp. 108–113
2025
-
[21]
X. Wen, J. Lou, Y . Lu, H. Lin, X. Yu, X. Lu, B. He, X. Han, D. Zhang, and L. Sun, “Rethinking reward model evaluation: Are we barking up the wrong tree?”arXiv preprint arXiv:2410.05584, 2024
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Technical report: Enhancing llm reasoning with reward-guided tree search
J. Jiang, Z. Chen, Y . Min, J. Chen, X. Cheng, J. Wang, Y . Tang, H. Sun, J. Deng, W. X. Zhaoet al., “Enhancing llm reasoning with reward- guided tree search,”arXiv preprint arXiv:2411.11694, 2024
-
[24]
Rewarding progress: Scaling automated process verifiers for llm reasoning,
A. Setlur, C. Nagpal, A. Fisch, X. Geng, J. Eisenstein, R. Agarwal, A. Agarwal, J. Berant, and A. Kumar, “Rewarding progress: Scaling automated process verifiers for llm reasoning,” inThe Thirteenth Inter- national Conference on Learning Representations, 2025
2025
-
[25]
Versaprm: Multi-domain process reward model via synthetic reasoning data,
T. Zeng, S. Zhang, S. Wu, C. Classen, D. Chae, E. Ewer, M. Lee, H. Kim, W. Kang, J. Kundeet al., “Versaprm: Multi-domain process reward model via synthetic reasoning data,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 74 197–74 239
2025
-
[26]
Dynamic and generalizable process reward modeling,
Z. Yin, Q. Sun, Z. Zeng, Q. Cheng, X. Qiu, and X.-J. Huang, “Dynamic and generalizable process reward modeling,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 4203–4233
2025
-
[27]
Theoretical guarantees on the best-of-n alignment policy,
A. Beirami, A. Agarwal, J. Berant, A. D’Amour, J. Eisenstein, C. Nag- pal, and A. T. Suresh, “Theoretical guarantees on the best-of-n alignment policy,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 3580–3602
2025
-
[28]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[29]
Pre- train, prompt, and predict: A systematic survey of prompting methods in natural language processing,
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre- train, prompt, and predict: A systematic survey of prompting methods in natural language processing,”ACM Computing Surveys, vol. 55, no. 9, pp. 1–35, 2023
2023
-
[30]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[31]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Nl4opt competition: Formulating optimization problems based on their natural language descriptions,
R. Ramamonjison, T. Yu, R. Li, H. Li, G. Carenini, B. Ghaddar, S. He, M. Mostajabdaveh, A. Banitalebi-Dehkordi, Z. Zhouet al., “Nl4opt competition: Formulating optimization problems based on their natural language descriptions,” inNeurIPS 2022 Competition Track. PMLR, 2023, pp. 189–203
2022
-
[33]
arXiv preprint arXiv:2503.10009 , year=
B. Zhang, P. Luo, G. Yang, B.-H. Soong, and C. Yuen, “Or-llm-agent: Automating modeling and solving of operations research optimization problems with reasoning llm,”arXiv preprint arXiv:2503.10009, 2025
-
[34]
Alphaopt: Formulating optimization programs with self-improving llm experience library,
M. Kong, A. Qu, X. Guo, W. Ouyang, C. Jiang, H. Zheng, Y . Ma, D. Zhuang, Y . Tang, J. Liet al., “Alphaopt: Formulating optimization programs with self-improving llm experience library,” inNeurIPS Work- shop on GPU-Accelerated and Scalable Optimization, 2025. 16
2025
-
[35]
Cafa: Coding as auto- formulation can boost large language models in solving linear program- ming problem,
H. Deng, B. Zheng, Y . Jiang, and T. H. Tran, “Cafa: Coding as auto- formulation can boost large language models in solving linear program- ming problem,” inThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, 2024
2024
-
[36]
OptimAI: Optimization from natural language using llm-powered ai agents,
R. Thind, Y . Sun, L. Liang, and H. Yang, “OptimAI: Optimization from natural language using llm-powered ai agents,”arXiv preprint arXiv:2504.16918, 2025
-
[37]
Augmenting operations research with auto- formulation of optimization models from problem descriptions,
Ramamonjison et al, “Augmenting operations research with auto- formulation of optimization models from problem descriptions,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track. Abu Dhabi, UAE: Association for Computational Linguistics, Dec. 2022, pp. 29–62. [Online]. Available: https://aclanthology.o...
2022
-
[38]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[39]
Optimus: Scalable opti- mization modeling with (mi) lp solvers and large language models,
A. AhmadiTeshnizi, W. Gao, and M. Udell, “Optimus: Scalable opti- mization modeling with (mi) lp solvers and large language models,” in Forty-first International Conference on Machine Learning
-
[40]
MAMO: A mathematical modeling benchmark with solvers.arXiv preprint arXiv:2405.13144, 2024
X. Huang, Q. Shen, Y . Hu, A. Gao, and B. Wang, “Mamo: a mathematical modeling benchmark with solvers,”arXiv preprint arXiv:2405.13144, 2024
-
[41]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Lin, K. Lu, M. Xue, R. Lin, T. Liu, X. Ren, and Z. Zhang, “Qwen2.5-math technical report: Toward mathematical expert model via self-improvement,”arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review arXiv 2024
-
[42]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Danget al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review arXiv 2024
-
[43]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Liet al., “Deepseek-coder: when the large language model meets programming–the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review arXiv 2024
-
[45]
Skywork-o1 open series,
S. o1 Team, “Skywork-o1 open series,” https://huggingface.co/Skywork, November 2024. [Online]. Available: https://huggingface.co/Skywork
2024
-
[46]
arXiv preprint arXiv:2501.07301 , year=
Z. Zhang, C. Zheng, Y . Wu, B. Zhang, R. Lin, B. Yu, D. Liu, J. Zhou, and J. Lin, “The lessons of developing process reward models in mathematical reasoning,”arXiv preprint arXiv:2501.07301, 2025
-
[47]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024. VII. BIOGRAPHYSECTION Xingyu Fanreceived the B.Sc. degree in software engineering from University of Electronic Science and Technology of China in 2022. Since 2022, he has been working toward the ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
According to Google Scholar, his publications have been cited over 60,000 times, with an H-index of 117
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.