Recognition: unknown
DAG-STL: A Hierarchical Framework for Zero-Shot Trajectory Planning under Signal Temporal Logic Specifications
Pith reviewed 2026-05-10 03:49 UTC · model grok-4.3
The pith
A hierarchical framework decomposes STL specifications into reachability and invariance conditions to plan trajectories without knowing robot dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
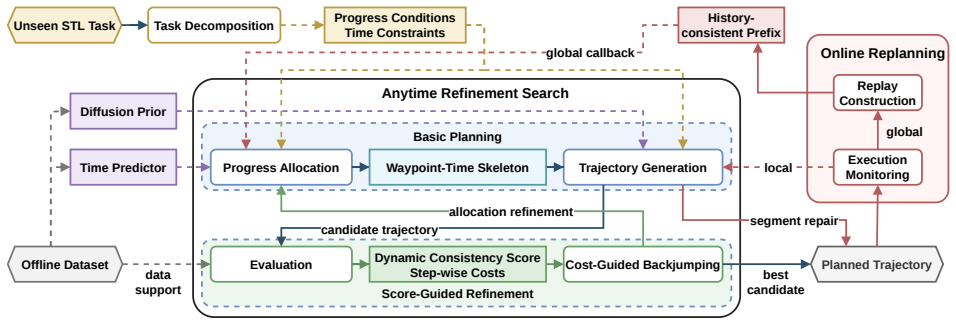
DAG-STL converts long-horizon STL planning into a decomposition-allocation-generation pipeline. An STL formula is decomposed into reachability and invariance progress conditions linked by shared timing constraints. Timed waypoints are allocated using learned reachability-time estimates from task-agnostic data. Trajectories between waypoints are synthesized by a diffusion-based generator. Additional mechanisms like a rollout-free dynamic consistency metric, anytime refinement search, and hierarchical online replanning ensure feasibility.
What carries the argument
The decomposition of STL formulas into reachability and invariance progress conditions linked by shared timing constraints, followed by waypoint allocation and diffusion generation.
If this is right
- Global planning reduces to shorter, better-supported subproblems that the diffusion generator can handle.
- Substantially better performance than direct robustness-guided diffusion on complex long-horizon STL tasks.
- Generalization across navigation tasks like Maze2D and AntMaze and manipulation in the Cube domain.
- Recovery of most tasks solvable by optimization with explicit models, but with lower computation time.
- Support for execution-time recovery through online replanning.
Where Pith is reading between the lines
- The approach suggests that logical decomposition can make offline learned generators more reliable for temporal constraints without retraining per task.
- If the timing links hold, this method could scale to even longer horizons by recursing the hierarchy.
- Extensions might include combining with model predictive control for tighter dynamic consistency.
- Testable by applying to new STL formulas not seen in training data for the estimator.
Load-bearing premise
The decomposition of an STL formula into reachability and invariance progress conditions linked by shared timing constraints remains valid and sufficient for planning when system dynamics are completely unknown and only task-agnostic trajectory data is available.
What would settle it
An experiment in the OGBench AntMaze domain where DAG-STL fails to produce any valid trajectory for a long-horizon STL specification involving multiple timed reachability and invariance phases, while a direct diffusion method guided by robustness succeeds in finding a satisfying trajectory.
Figures











read the original abstract
Signal Temporal Logic (STL) is a powerful language for specifying temporally structured robotic tasks. Planning executable trajectories under STL constraints remains difficult when system dynamics and environment structure are not analytically available. Existing methods typically either assume explicit models or learn task-specific behaviors, limiting zero-shot generalization to unseen STL tasks. In this work, we study offline STL planning under unknown dynamics using only task-agnostic trajectory data. Our central design philosophy is to separate logical reasoning from trajectory realization. We instantiate this idea in DAG-STL, a hierarchical framework that converts long-horizon STL planning into three stages. It first decomposes an STL formula into reachability and invariance progress conditions linked by shared timing constraints. It then allocates timed waypoints using learned reachability-time estimates. Finally, it synthesizes trajectories between these waypoints with a diffusion-based generator. This decomposition--allocation--generation pipeline reduces global planning to shorter, better-supported subproblems. To bridge the gap between planning-level correctness and execution-level feasibility, we further introduce a rollout-free dynamic consistency metric, an anytime refinement search procedure for improving multiple allocation hypotheses under finite budgets, and a hierarchical online replanning mechanism for execution-time recovery. Experiments in Maze2D, OGBench AntMaze, and the Cube domain show that DAG-STL substantially outperforms direct robustness-guided diffusion on complex long-horizon STL tasks and generalizes across navigation and manipulation settings. In a custom environment with an optimization-based reference, DAG-STL recovers most model-solvable tasks while retaining a clear computational advantage over direct optimization based on the explicit system model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce DAG-STL, a hierarchical framework for zero-shot trajectory planning under STL specifications with unknown dynamics using only task-agnostic data. The framework decomposes STL formulas into reachability and invariance progress conditions linked by shared timing constraints, allocates timed waypoints using learned reachability-time estimates, and synthesizes trajectories with a diffusion-based generator. It includes a rollout-free dynamic consistency metric, anytime refinement search, and hierarchical online replanning. Experiments in Maze2D, OGBench AntMaze, and Cube domain show substantial outperformance over direct robustness-guided diffusion on complex long-horizon tasks and generalization across navigation and manipulation, while recovering most model-solvable tasks with computational advantage.
Significance. If the decomposition preserves STL semantics under approximate learned timing estimates, this would be a significant contribution to data-driven robotic planning, allowing zero-shot generalization to unseen STL tasks without requiring explicit models or task-specific learning. The separation of logical reasoning from trajectory realization, combined with mechanisms for dynamic consistency and replanning, addresses key challenges in long-horizon planning. The empirical results suggest practical advantages over both diffusion and optimization baselines.
major comments (1)
- [§3 (Decomposition-Allocation-Generation Pipeline)] The claim that the decomposition of an arbitrary STL formula into reachability and invariance sub-conditions linked by shared timing constraints, combined with learned reachability-time estimates from task-agnostic trajectories, supports zero-shot planning under unknown dynamics lacks a formal argument that the resulting allocations preserve the semantics of the original formula. Errors in timing estimates can propagate through the shared constraints, potentially rendering trajectories invalid despite local diffusion success. This is load-bearing for the central zero-shot claim, as no model-based fallback is provided.
minor comments (2)
- [Abstract] The abstract asserts outperformance and generalization but does not provide quantitative metrics, error bars, or ablation details, making it challenging to fully evaluate the empirical support without the full manuscript.
- [Experiments] The description of the custom environment with optimization-based reference could benefit from more details on how the comparison is conducted to ensure fair assessment of computational advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of separating logical reasoning from trajectory realization in zero-shot STL planning. We address the major comment on the formal aspects of the decomposition below.
read point-by-point responses
-
Referee: [§3 (Decomposition-Allocation-Generation Pipeline)] The claim that the decomposition of an arbitrary STL formula into reachability and invariance sub-conditions linked by shared timing constraints, combined with learned reachability-time estimates from task-agnostic trajectories, supports zero-shot planning under unknown dynamics lacks a formal argument that the resulting allocations preserve the semantics of the original formula. Errors in timing estimates can propagate through the shared constraints, potentially rendering trajectories invalid despite local diffusion success. This is load-bearing for the central zero-shot claim, as no model-based fallback is provided.
Authors: We agree that the manuscript does not contain a formal proof establishing semantic preservation of the original STL formula under approximate learned timing estimates. The decomposition into reachability and invariance progress conditions with shared timing constraints follows standard STL decomposition principles that preserve semantics exactly when timing values are precise. The learned reachability-time estimates, obtained from task-agnostic trajectories, necessarily introduce approximation under unknown dynamics. To mitigate error propagation through the shared constraints, the framework includes a rollout-free dynamic consistency metric that evaluates allocation feasibility without full simulation, an anytime refinement search that improves allocation hypotheses under finite compute budgets, and hierarchical online replanning that enables execution-time recovery. These mechanisms are intended to maintain practical correctness even when local timing estimates are imperfect. While these safeguards do not constitute formal guarantees, the experiments show that DAG-STL solves substantially more complex long-horizon tasks than direct robustness-guided diffusion and recovers most tasks solvable by an explicit-model optimizer. We will revise the manuscript to (i) clarify in §3 that the decomposition preserves semantics exactly only under precise timings and that learned estimates are approximations, (ii) expand the discussion of how the consistency metric, refinement search, and replanning address propagation risks, and (iii) explicitly acknowledge the absence of a model-based fallback and formal semantic guarantees as current limitations, with suggested directions for future theoretical work. revision: partial
Circularity Check
No significant circularity in DAG-STL decomposition-allocation-generation pipeline
full rationale
The paper presents a methodological framework that decomposes STL formulas into reachability and invariance progress conditions as a design choice, learns reachability-time estimates from task-agnostic trajectory data, allocates waypoints, and synthesizes trajectories via diffusion. No equations or derivations are provided that reduce any prediction or result to its inputs by construction, no self-citations serve as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The central claims rest on empirical validation across Maze2D, AntMaze, and Cube domains rather than tautological reductions, rendering the approach self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2005 , publisher=
Algorithmic learning in a random world , author=. 2005 , publisher=
2005
-
[2]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Multi-agent reinforcement learning guided by signal temporal logic specifications , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
-
[3]
International conference on machine learning , pages=
Out-of-distribution detection with deep nearest neighbors , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[4]
Proceedings of the 2000 ACM SIGMOD international conference on Management of data , pages=
LOF: identifying density-based local outliers , author=. Proceedings of the 2000 ACM SIGMOD international conference on Management of data , pages=
2000
-
[5]
Proceedings of the 2000 ACM SIGMOD international conference on Management of data , pages=
Efficient algorithms for mining outliers from large data sets , author=. Proceedings of the 2000 ACM SIGMOD international conference on Management of data , pages=
2000
-
[6]
SafeDiffuser: Safe Planning with Diffusion Probabilistic Models , booktitle =
Wei Xiao and Tsun. SafeDiffuser: Safe Planning with Diffusion Probabilistic Models , booktitle =
-
[7]
arXiv preprint arXiv:2011.04950 , year=
Model-based reinforcement learning from signal temporal logic specifications , author=. arXiv preprint arXiv:2011.04950 , year=
-
[8]
Annual Review of Control, Robotics, and Autonomous Systems , volume=
Formal methods for control synthesis: An optimization perspective , author=. Annual Review of Control, Robotics, and Autonomous Systems , volume=. 2019 , publisher=
2019
-
[9]
Control Engineering Practice , volume=
Signal temporal logic synthesis under model predictive control: A low complexity approach , author=. Control Engineering Practice , volume=. 2024 , publisher=
2024
-
[10]
IEEE Conference on Control Technology and Applications , pages=
Smooth operator: Control using the smooth robustness of temporal logic , author=. IEEE Conference on Control Technology and Applications , pages=. 2017 , organization=
2017
-
[11]
Nonlinear Analysis: Hybrid Systems , volume=
STL and wSTL control synthesis: A disjunction-centric mixed-integer linear programming approach , author=. Nonlinear Analysis: Hybrid Systems , volume=. 2025 , publisher=
2025
-
[12]
IEEE Transactions on Robotics , volume=
Soft robots modeling: A structured overview , author=. IEEE Transactions on Robotics , volume=. 2023 , publisher=
2023
-
[13]
Learning for dynamics and control , pages=
Tractable reinforcement learning of signal temporal logic objectives , author=. Learning for dynamics and control , pages=. 2020 , organization=
2020
-
[14]
The International Journal of Robotics Research , volume=
Kinematic issues in 6R cuspidal robots, guidelines for path planning and deciding cuspidality , author=. The International Journal of Robotics Research , volume=. 2025 , publisher=
2025
-
[15]
IEEE Control Systems Letters , volume=
Trajectory optimization for high-dimensional nonlinear systems under STL specifications , author=. IEEE Control Systems Letters , volume=. 2020 , publisher=
2020
-
[16]
Annual Review of Control, Robotics, and Autonomous Systems , volume=
Synthesis for robots: Guarantees and feedback for robot behavior , author=. Annual Review of Control, Robotics, and Autonomous Systems , volume=. 2018 , publisher=
2018
-
[17]
2006 , publisher=
Planning algorithms , author=. 2006 , publisher=
2006
-
[18]
Conference on Robot Learning , pages=
Learning from demonstrations using signal temporal logic , author=. Conference on Robot Learning , pages=
-
[19]
IEEE Robotics and Automation Letters , volume=
Cooperative object manipulation under signal temporal logic tasks and uncertain dynamics , author=. IEEE Robotics and Automation Letters , volume=. 2022 , publisher=
2022
-
[20]
IEEE Transactions on Robotics , year=
Robust-locomotion-by-logic: Perturbation-resilient bipedal locomotion via signal temporal logic guided model predictive control , author=. IEEE Transactions on Robotics , year=
-
[21]
7th Annual Learning for Dynamics & Control Conference , pages=
STLGame: Signal Temporal Logic Games in Adversarial Multi-Agent Systems , author=. 7th Annual Learning for Dynamics & Control Conference , pages=. 2025 , organization=
2025
-
[22]
Annual Reviews in Control , volume=
Formal synthesis of controllers for safety-critical autonomous systems: Developments and challenges , author=. Annual Reviews in Control , volume=. 2024 , publisher=
2024
-
[23]
Kapoor, Parv and Mizuta, Kazuki and Kang, Eunsuk and Leung, Karen , journal=
-
[24]
IEEE Robotics and Automation Letters , volume=
Power line inspection tasks with multi-aerial robot systems via signal temporal logic specifications , author=. IEEE Robotics and Automation Letters , volume=. 2021 , publisher=
2021
-
[25]
ACM Computing Surveys , volume=
Formal specification and verification of autonomous robotic systems: A survey , author=. ACM Computing Surveys , volume=. 2019 , publisher=
2019
-
[26]
International Conference on Learning Representations , year=
OGBench: Benchmarking Offline Goal-Conditioned RL , author=. International Conference on Learning Representations , year=
-
[27]
arXiv preprint arXiv:2408.08252 , year =
Derivative-Free Guidance in Continuous and Discrete Diffusion Models with Soft Value-Based Decoding , author=. arXiv preprint arXiv:2408.08252 , year=
-
[28]
IEEE Transactions on Robotics , volume=
Continuous-time control synthesis under nested signal temporal logic specifications , author=. IEEE Transactions on Robotics , volume=. 2024 , publisher=
2024
-
[29]
European Conference on Computer Vision , pages=
Diffusion Models as Optimizers for Efficient Planning in Offline RL , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[30]
Lectures on Runtime Verification: Introductory and Advanced Topics , pages=
Specification-based monitoring of cyber-physical systems: a survey on theory, tools and applications , author=. Lectures on Runtime Verification: Introductory and Advanced Topics , pages=. 2018 , publisher=
2018
-
[31]
NASA Formal Methods Symposium , pages=
Safe Planning Through Incremental Decomposition of Signal Temporal Logic Specifications , author=. NASA Formal Methods Symposium , pages=. 2024 , organization=
2024
-
[32]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4rl: Datasets for deep data-driven reinforcement learning , author=. arXiv preprint arXiv:2004.07219 , year=
work page internal anchor Pith review arXiv 2004
-
[33]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Cobl-diffusion: Diffusion-based conditional robot planning in dynamic environments using control barrier and lyapunov functions , author=. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2024 , organization=
2024
-
[34]
Advances in Neural Information Processing Systems , volume=
Constrained synthesis with projected diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
NASA Formal Methods Symposium , pages=
Rewrite-based decomposition of signal temporal logic specifications , author=. NASA Formal Methods Symposium , pages=. 2023 , organization=
2023
-
[36]
2023 62nd IEEE Conference on Decision and Control , pages=
Model predictive control for signal temporal logic specifications with time interval decomposition , author=. 2023 62nd IEEE Conference on Decision and Control , pages=. 2023 , organization=
2023
-
[37]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[38]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[39]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Reinforcement learning and control as probabilistic inference: Tutorial and review , author=. arXiv preprint arXiv:1805.00909 , year=
work page internal anchor Pith review arXiv
-
[40]
Proceedings of the 26th annual international conference on machine learning , pages=
Robot trajectory optimization using approximate inference , author=. Proceedings of the 26th annual international conference on machine learning , pages=
-
[41]
International workshop on artificial intelligence and statistics , pages=
Planning by probabilistic inference , author=. International workshop on artificial intelligence and statistics , pages=. 2003 , organization=
2003
-
[42]
International Symposium on Formal Techniques in Real-Time and Fault-Tolerant Systems , pages=
Monitoring temporal properties of continuous signals , author=. International Symposium on Formal Techniques in Real-Time and Fault-Tolerant Systems , pages=. 2004 , organization=
2004
-
[43]
53rd Annual Allerton Conference on Communication, Control, and Computing , pages=
Robust temporal logic model predictive control , author=. 53rd Annual Allerton Conference on Communication, Control, and Computing , pages=. 2015 , organization=
2015
-
[44]
International Conference on Machine Learning , pages=
Planning with Diffusion for Flexible Behavior Synthesis , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[45]
Proceedings of the 18th International Conference on Hybrid Systems: Computation and Control , pages=
Enforcing temporal logic specifications via reinforcement learning , author=. Proceedings of the 18th International Conference on Hybrid Systems: Computation and Control , pages=
-
[46]
Proceedings of the 4th ACM SIGBED International Workshop on Design, Modeling, and Evaluation of Cyber-Physical Systems , pages=
Model predictive control from signal temporal logic specifications: A case study , author=. Proceedings of the 4th ACM SIGBED International Workshop on Design, Modeling, and Evaluation of Cyber-Physical Systems , pages=
-
[47]
IEEE Robotics and Automation Letters , volume=
Multi-agent motion planning from signal temporal logic specifications , author=. IEEE Robotics and Automation Letters , volume=. 2022 , publisher=
2022
-
[48]
IEEE Control Systems Letters , volume=
Mixed-integer programming for signal temporal logic with fewer binary variables , author=. IEEE Control Systems Letters , volume=. 2022 , publisher=
2022
-
[49]
IEEE Robotics and Automation Letters , volume=
Funnel-based reward shaping for signal temporal logic tasks in reinforcement learning , author=. IEEE Robotics and Automation Letters , volume=. 2023 , publisher=
2023
-
[50]
IEEE Control Systems Letters , year=
Tractable Reinforcement Learning for Signal Temporal Logic Tasks With Counterfactual Experience Replay , author=. IEEE Control Systems Letters , year=
-
[51]
IEEE Robotics and Automation Letters , year=
Signal temporal logic neural predictive control , author=. IEEE Robotics and Automation Letters , year=
-
[52]
arXiv preprint arXiv:2408.01923 , year=
Scalable Signal Temporal Logic Guided Reinforcement Learning via Value Function Space Optimization , author=. arXiv preprint arXiv:2408.01923 , year=
-
[53]
International Conference on Software Engineering and Formal Methods , pages=
Training agents to satisfy timed and untimed signal temporal logic specifications with reinforcement learning , author=. International Conference on Software Engineering and Formal Methods , pages=. 2022 , organization=
2022
-
[54]
IEEE International Conference on Robotics and Automation , pages=
Synthesis of temporally-robust policies for signal temporal logic tasks using reinforcement learning , author=. IEEE International Conference on Robotics and Automation , pages=. 2024 , organization=
2024
-
[55]
60th IEEE Conference on Decision and Control , pages=
Model-free reinforcement learning for optimal control of Markov decision processes under signal temporal logic specifications , author=. 60th IEEE Conference on Decision and Control , pages=. 2021 , organization=
2021
-
[56]
IEEE International Conference on Robotics and Automation , pages=
Guided conditional diffusion for controllable traffic simulation , author=. IEEE International Conference on Robotics and Automation , pages=. 2023 , organization=
2023
-
[57]
IEEE Control Systems Letters , volume=
A smooth robustness measure of signal temporal logic for symbolic control , author=. IEEE Control Systems Letters , volume=. 2020 , publisher=
2020
-
[58]
The Eleventh International Conference on Learning Representations , year=
Is Conditional Generative Modeling all you need for Decision Making? , author=. The Eleventh International Conference on Learning Representations , year=
-
[59]
IEEE Access , volume=
Deep reinforcement learning under signal temporal logic constraints using Lagrangian relaxation , author=. IEEE Access , volume=. 2022 , publisher=
2022
-
[60]
The International Journal of Robotics Research , pages=
Diffusion policy: Visuomotor policy learning via action diffusion , author=. The International Journal of Robotics Research , pages=. 2023 , publisher=
2023
-
[61]
Proceedings of the 30th International Conference on Neural Information Processing Systems , pages=
Learning to poke by poking: experiential learning of intuitive physics , author=. Proceedings of the 30th International Conference on Neural Information Processing Systems , pages=
-
[62]
The International Journal of Robotics Research , volume=
Backpropagation through signal temporal logic specifications: Infusing logical structure into gradient-based methods , author=. The International Journal of Robotics Research , volume=. 2023 , publisher=
2023
-
[63]
IEEE Control Systems Letters , year=
Decomposition-Based MPC for Uncertain Systems With Nested Signal Temporal Logic Specifications , author=. IEEE Control Systems Letters , year=
-
[64]
Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control , pages=
Structured reward functions using STL , author=. Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control , pages=
-
[65]
IEEE Control Systems Letters , volume=
Signal temporal logic task decomposition via convex optimization , author=. IEEE Control Systems Letters , volume=. 2021 , publisher=
2021
-
[66]
Proceedings of the 26th ACM International Conference on Hybrid Systems: Computation and Control , pages=
Sampling-based Approach to Robust STL Synthesis for Complex Systems under Uncertainty , author=. Proceedings of the 26th ACM International Conference on Hybrid Systems: Computation and Control , pages=
-
[67]
IEEE 55th Conference on Decision and Control , pages=
Q-learning for robust satisfaction of signal temporal logic specifications , author=. IEEE 55th Conference on Decision and Control , pages=. 2016 , organization=
2016
-
[68]
IEEE International Conference on Robotics and Automation , pages=
Stochastic robustness interval for motion planning with signal temporal logic , author=. IEEE International Conference on Robotics and Automation , pages=. 2023 , organization=
2023
-
[69]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Robust counterexample-guided optimization for planning from differentiable temporal logic , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2022 , organization=
2022
-
[70]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Adaptive planning with generative models under uncertainty , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2024 , organization=
2024
-
[71]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[72]
2024 , booktitle =
Li, Guanghe and Shan, Yixiang and Zhu, Zhengbang and Long, Ting and Zhang, Weinan , title =. 2024 , booktitle =
2024
-
[73]
Constrained Diffusers for Safe Planning and Control , author=. arXiv preprint arXiv:2506.12544 , year=
-
[74]
Journal of risk , volume=
Optimization of conditional value-at-risk , author=. Journal of risk , volume=
-
[75]
IEEE transactions on information theory , volume=
Nearest neighbor pattern classification , author=. IEEE transactions on information theory , volume=. 1967 , publisher=
1967
-
[76]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Generative Trajectory Stitching through Diffusion Composition , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[77]
IEEE Robotics and Automation Letters , volume=
Diverse controllable diffusion policy with signal temporal logic , author=. IEEE Robotics and Automation Letters , volume=. 2024 , publisher=
2024
-
[78]
IEEE Robotics and Automation Letters , year=
LTLDoG: Satisfying temporally-extended symbolic constraints for safe diffusion-based planning , author=. IEEE Robotics and Automation Letters , year=
-
[79]
2025 IEEE International Conference on Robotics and Automation , pages=
Diffusion meets options: Hierarchical generative skill composition for temporally-extended tasks , author=. 2025 IEEE International Conference on Robotics and Automation , pages=. 2025 , organization=
2025
-
[80]
Tackling the generative learning trilemma with denoising diffusion gans , author=. arXiv preprint arXiv:2112.07804 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.