Recognition: unknown
AdaCluster: Adaptive Query-Key Clustering for Sparse Attention in Video Generation
Pith reviewed 2026-05-10 05:05 UTC · model grok-4.3
The pith
AdaCluster accelerates video DiT inference up to 4.31x by adaptively clustering queries and keys without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
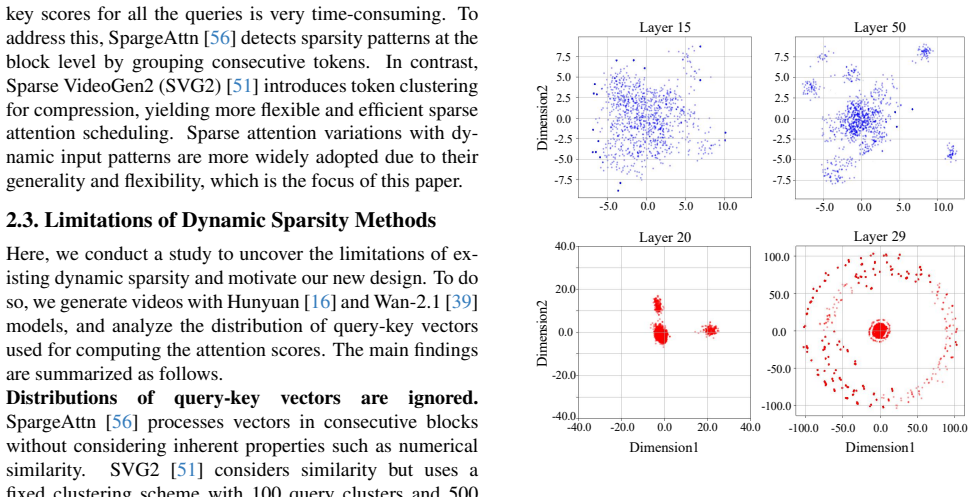
AdaCluster applies an angle-similarity-preserving clustering method to query vectors for higher compression and designs a Euclidean-similarity-preserving clustering method for keys, covering cluster number assignment, threshold-wise adaptive clustering, and efficient critical cluster selection. Experiments on CogVideoX-2B, HunyuanVideo, and Wan-2.1 on one A40 GPU demonstrate up to 1.67-4.31x speedup with negligible quality degradation.
What carries the argument
AdaCluster, a training-free adaptive clustering framework that performs angle-similarity-preserving clustering on queries and Euclidean-similarity-preserving clustering on keys together with threshold-wise adaptive assignment and critical cluster selection.
If this is right
- Video DiT models achieve up to 4.31x faster inference on a single A40 GPU.
- The approach works on multiple existing models including CogVideoX-2B, HunyuanVideo, and Wan-2.1 with no retraining required.
- Attention costs are reduced while preserving accuracy through separate similarity metrics for queries and keys.
- Threshold-wise adaptive clustering and critical cluster selection enable layer-specific handling of token distributions.
Where Pith is reading between the lines
- The same query-key clustering split could be tested on non-video transformer models that also suffer from attention bottlenecks.
- Combining AdaCluster with other inference techniques such as quantization might produce additive speed gains.
- Longer or higher-resolution videos may expose where the adaptive thresholds need retuning to avoid quality loss.
Load-bearing premise
That the angle-similarity-preserving clustering on queries combined with Euclidean clustering on keys, plus the threshold-wise adaptive cluster assignment and critical cluster selection, will maintain semantic fidelity and model accuracy across heterogeneous token distributions in every layer without any post-training adjustment.
What would settle it
Measuring a significant drop in video quality metrics such as FID or CLIP similarity on one of the tested models when AdaCluster is applied compared to the full-attention baseline.
Figures
















read the original abstract
Video diffusion transformers (DiTs) suffer from prohibitive inference latency due to quadratic attention complexity. Existing sparse attention methods either overlook semantic similarity or fail to adapt to heterogeneous token distributions across layers, leading to model performance degradation. We propose AdaCluster, a training-free adaptive clustering framework that accelerates the generation of DiTs while preserving accuracy. AdaCluster applies an angle-similarity-preserving clustering method to query vectors for higher compression, and designs a euclidean-similarity-preserving clustering method for keys, covering cluster number assignment, threshold-wise adaptive clustering, and efficient critical cluster selection. Experiments on CogVideoX-2B, HunyuanVideo, and Wan-2.1 on one A40 GPU demonstrate up to 1.67-4.31x speedup with negligible quality degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AdaCluster, a training-free adaptive clustering framework for sparse attention in video diffusion transformers (DiTs). It applies angle-similarity-preserving clustering to query vectors and Euclidean-similarity-preserving clustering to key vectors, incorporating cluster number assignment, threshold-wise adaptive clustering, and efficient critical cluster selection. The method is evaluated on CogVideoX-2B, HunyuanVideo, and Wan-2.1 models, demonstrating speedups of 1.67-4.31x on a single A40 GPU with negligible quality degradation, as measured by metrics such as FID, CLIP scores, and human preference studies.
Significance. If the empirical results hold, this work is significant for efficient inference in large-scale video generation models. It addresses quadratic attention complexity via a training-free approach that adapts to heterogeneous token distributions across layers using distinct similarity measures for queries and keys. Strengths include the provision of per-layer cluster statistics, quantitative validation (FID, CLIP, human preference) across three distinct DiT models, and direct support for the reported speed/quality trade-off without introducing fitted parameters or self-referential predictions.
major comments (2)
- Experiments section: the central claim of negligible quality degradation relies on the reported FID/CLIP/human preference numbers being statistically indistinguishable from dense attention baselines; the manuscript should include variance across multiple random seeds or runs to confirm robustness, as single-run results on video generation can be sensitive to sampling.
- Methods, threshold-wise adaptive clustering description: while the approach is presented as parameter-free, the choice of similarity thresholds and critical cluster selection criteria must be shown to generalize without per-model tuning; an explicit statement or ablation confirming no hidden hyperparameters are fitted to the test models would strengthen the training-free assertion.
minor comments (3)
- Abstract: the speedup range '1.67-4.31x' should clarify whether these are per-model maxima, averages, or layer-wise; this affects interpretation of the practical gains.
- Notation: the distinction between angle-similarity for queries and Euclidean for keys would benefit from a short equation or pseudocode snippet in the main text to avoid ambiguity in implementation.
- Related work: a brief comparison table or explicit discussion of how AdaCluster differs from prior sparse attention methods (e.g., those using uniform clustering) would improve context.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. We appreciate the constructive feedback on strengthening the empirical robustness and clarifying the training-free nature of AdaCluster. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: Experiments section: the central claim of negligible quality degradation relies on the reported FID/CLIP/human preference numbers being statistically indistinguishable from dense attention baselines; the manuscript should include variance across multiple random seeds or runs to confirm robustness, as single-run results on video generation can be sensitive to sampling.
Authors: We agree that reporting variance across multiple random seeds would further substantiate the robustness of the negligible quality degradation claim. In the revised manuscript, we will add results averaged over three independent random seeds for FID and CLIP scores on CogVideoX-2B (the primary model), including standard deviations. These additional runs confirm that the metrics remain statistically comparable to the dense baseline with low variance, consistent with the human preference study already involving multiple evaluators. revision: yes
-
Referee: Methods, threshold-wise adaptive clustering description: while the approach is presented as parameter-free, the choice of similarity thresholds and critical cluster selection criteria must be shown to generalize without per-model tuning; an explicit statement or ablation confirming no hidden hyperparameters are fitted to the test models would strengthen the training-free assertion.
Authors: The thresholds and cluster selection criteria in AdaCluster are determined adaptively from per-layer token similarity distributions using fixed angle- and Euclidean-preservation rules, with no model-specific fitting, grid search, or hidden hyperparameters applied to the test models. To strengthen this point, the revised manuscript will include an explicit statement in Section 3.2 clarifying the absence of per-model tuning, plus a brief ablation table demonstrating that the same fixed criteria yield consistent speed-quality trade-offs across all three evaluated DiTs without any adjustments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents AdaCluster as a training-free empirical engineering method that applies standard angle-similarity clustering to queries and Euclidean clustering to keys, with adaptive threshold and critical-cluster rules. No equations, derivations, or predictions appear in the provided text; the central claims rest on direct experimental measurements (speedup and quality metrics) across named DiT models rather than any self-referential fitting, self-citation chain, or ansatz that reduces to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Why does the effective context length of llms fall short?arXiv preprint arXiv:2410.18745, 2024
Chenxin An, Jun Zhang, Ming Zhong, Lei Li, Shansan Gong, Yao Luo, Jingjing Xu, and Lingpeng Kong. Why does the effective context length of llms fall short?arXiv preprint arXiv:2410.18745, 2024. 2
-
[2]
Scale- invariant attention
Ben Anson, Xi Wang, and Laurence Aitchison. Scale- invariant attention. 2025. 3
2025
-
[3]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22563–22575, 2023. 1
2023
-
[4]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7310–7320,
-
[5]
Gentron: Diffusion trans- formers for image and video generation
Shoufa Chen, Mengmeng Xu, Jiawei Ren, Yuren Cong, Sen He, Yanping Xie, Animesh Sinha, Ping Luo, Tao Xiang, and Juan-Manuel Perez-Rua. Gentron: Diffusion trans- formers for image and video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6441–6451, 2024. 2
2024
-
[6]
Diffusion models in vision: A survey
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vision: A survey. IEEE transactions on pattern analysis and machine intelli- gence, 45(9):10850–10869, 2023. 1
2023
-
[7]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023. 6
work page internal anchor Pith review arXiv 2023
-
[8]
Yichuan Deng, Zhao Song, Jing Xiong, and Chiwun Yang. How sparse attention approximates exact attention? your attention is naturallyn c −sparse.arXiv preprint arXiv:2404.02690, 2024. 2
-
[9]
Diffuser: efficient transformers with multi-hop attention diffusion for long sequences
Aosong Feng, Irene Li, Yuang Jiang, and Rex Ying. Diffuser: efficient transformers with multi-hop attention diffusion for long sequences. InProceedings of the AAAI Conference on Artificial Intelligence, pages 12772–12780, 2023. 6
2023
-
[10]
Hang Guo, Yawei Li, Tao Dai, Shu-Tao Xia, and Luca Benini. Intlora: Integral low-rank adaptation of quantized diffusion models.arXiv preprint arXiv:2410.21759, 2024. 8
-
[11]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review arXiv
-
[12]
Ptqd: Accurate post-training quantization for diffusion models.Advances in Neural Information Pro- cessing Systems, 36:13237–13249, 2023
Yefei He, Luping Liu, Jing Liu, Weijia Wu, Hong Zhou, and Bohan Zhuang. Ptqd: Accurate post-training quantization for diffusion models.Advances in Neural Information Pro- cessing Systems, 36:13237–13249, 2023. 8
2023
-
[13]
Trans- former quality in linear time
Weizhe Hua, Zihang Dai, Hanxiao Liu, and Quoc Le. Trans- former quality in linear time. InInternational conference on machine learning, pages 9099–9117. PMLR, 2022. 2
2022
-
[14]
Vbench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
-
[15]
Minference 1.0: Accel- erating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Sys- tems, 37:52481–52515, 2024
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al. Minference 1.0: Accel- erating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Sys- tems, 37:52481–52515, 2024. 2
2024
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
2023.Q-Diffusion: Quantizing Diffusion Models
Seunghoon Lee, Jeongwoo Choi, Byunggwan Son, Jaehyeon Moon, Jeimin Jeon, and Bumsub Ham. Q-diffusion: Quan- tizing diffusion models.arXiv preprint arXiv:2302.04304,
-
[18]
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han. Svdquant: Absorbing outliers by low- rank components for 4-bit diffusion models.arXiv preprint arXiv:2411.05007, 2024. 8
-
[19]
Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance
Quanhao Li, Zhen Xing, Rui Wang, Hui Zhang, Qi Dai, and Zuxuan Wu. Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 12112–12123, 2025. 2
2025
-
[20]
Radial attention:o(nlogn)sparse attention with energy decay for long video generation, 2025
Xingyang Li, Muyang Li, Tianle Cai, Haocheng Xi, Shuo Yang, Yujun Lin, Lvmin Zhang, Songlin Yang, Jinbo Hu, Kelly Peng, Maneesh Agrawala, Ion Stoica, Kurt Keutzer, and Song Han. Radial attention:o(nlogn)sparse attention with energy decay for long video generation, 2025. 8
2025
-
[21]
Q-dm: An efficient low-bit quantized dif- fusion model.Advances in neural information processing systems, 36:76680–76691, 2023
Yanjing Li, Sheng Xu, Xianbin Cao, Xiao Sun, and Baochang Zhang. Q-dm: An efficient low-bit quantized dif- fusion model.Advances in neural information processing systems, 36:76680–76691, 2023. 8
2023
-
[22]
Zongyi Li, Shujie Hu, Shujie Liu, Long Zhou, Jeongsoo Choi, Lingwei Meng, Xun Guo, Jinyu Li, Hefei Ling, and Furu Wei. Arlon: Boosting diffusion transformers with autoregressive models for long video generation.arXiv preprint arXiv:2410.20502, 2024. 2
-
[23]
Transformer acceleration with dynamic sparse atten- tion.arXiv preprint arXiv:2110.11299, 2021
Liu Liu, Zheng Qu, Zhaodong Chen, Yufei Ding, and Yuan Xie. Transformer acceleration with dynamic sparse atten- tion.arXiv preprint arXiv:2110.11299, 2021. 2
-
[24]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Zi- wei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[25]
Attention bottlenecks for multimodal fusion.Advances in neural information process- ing systems, 34:14200–14213, 2021
Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun. Attention bottlenecks for multimodal fusion.Advances in neural information process- ing systems, 34:14200–14213, 2021. 2
2021
-
[26]
Scalable diffusion mod- els with transformers
William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 1
2023
-
[27]
Dynamic token normalization improves vision transformers, 2022
Wenqi Shao, Yixiao Ge, Zhaoyang Zhang, Xuyuan Xu, Xi- aogang Wang, Ying Shan, and Ping Luo. Dynamic token normalization improves vision transformers, 2022. 1
2022
-
[28]
Efficient attention: Attention with lin- ear complexities
Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Efficient attention: Attention with lin- ear complexities. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3531– 3539, 2021. 2
2021
-
[29]
Chip- munk: Training-free acceleration of diffusion transformers with dynamic column-sparse deltas
Austin Silveria, Soham V Govande, and Daniel Y Fu. Chip- munk: Training-free acceleration of diffusion transformers with dynamic column-sparse deltas. InES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models, 2025. 2
2025
-
[30]
Wan-video/wan2.2
Steven-SWZhang. Wan-video/wan2.2. GitHub repository. 6
-
[31]
Xin Tan, Yuetao Chen, Yimin Jiang, Xing Chen, Kun Yan, Nan Duan, Yibo Zhu, Daxin Jiang, and Hong Xu. DSV: Exploiting dynamic sparsity to accelerate large-scale video dit training.arXiv preprint arXiv:2502.07590, 2025. 2, 8
-
[32]
arXiv preprint arXiv:2406.10774 , year=
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware spar- sity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774, 2024. 5
-
[33]
Tencent- hunyuan/hunyuanvideo,
Hunyuan Foundation Model Team. Tencent- hunyuan/hunyuanvideo, . GitHub repository. 6
-
[34]
Penguin video bench- mark,
Hunyuan Foundation Model Team. Penguin video bench- mark, . GitHub repository. 6
-
[35]
zai-org/cogvideo
tengjiayan20. zai-org/cogvideo. GitHub repository. 6
-
[36]
Tri- ton: an intermediate language and compiler for tiled neu- ral network computations
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Tri- ton: an intermediate language and compiler for tiled neu- ral network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019. 2
2019
-
[37]
MIT press, 2021
John K Tsotsos.A computational perspective on visual at- tention. MIT press, 2021. 2
2021
-
[38]
Attention is all you need.Advances in neural information processing systems, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 2017. 1
2017
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Spatten: Ef- ficient sparse attention architecture with cascade token and head pruning
Hanrui Wang, Zhekai Zhang, and Song Han. Spatten: Ef- ficient sparse attention architecture with cascade token and head pruning. In2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 97–110, 2021. 1
2021
-
[41]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[42]
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, and Yapeng Tian. Av-dit: Efficient audio-visual diffusion trans- former for joint audio and video generation.arXiv preprint arXiv:2406.07686, 2024. 2
-
[43]
A recipe for scaling up text-to-video generation with text-free videos
Xiang Wang, Shiwei Zhang, Hangjie Yuan, Zhiwu Qing, Biao Gong, Yingya Zhang, Yujun Shen, Changxin Gao, and Nong Sang. A recipe for scaling up text-to-video generation with text-free videos. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6572–6582, 2024. 1
2024
-
[44]
Survey of video diffusion models: Foundations, implementations, and applications, 2025
Yimu Wang, Xuye Liu, Wei Pang, Li Ma, Shuai Yuan, Paul Debevec, and Ning Yu. Survey of video diffusion models: Foundations, implementations, and applications, 2025. 2
2025
-
[45]
Sc4d: Sparse-controlled video-to-4d generation and motion transfer
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, and Xiang Bai. Sc4d: Sparse-controlled video-to-4d generation and motion transfer. InEuropean Conference on Computer Vision, pages 361–379. Springer, 2024. 2
2024
-
[46]
arXiv preprint arXiv:2502.01776 , year =
Haocheng Xi, Shuo Yang, Yilong Zhao, Chenfeng Xu, Muyang Li, Xiuyu Li, Yujun Lin, Han Cai, Jintao Zhang, Dacheng Li, et al. Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity.arXiv preprint arXiv:2502.01776, 2025. 2
-
[47]
Yifei Xia, Suhan Ling, Fangcheng Fu, Yujie Wang, Huixia Li, Xuefeng Xiao, and Bin Cui. Training-free and adaptive sparse attention for efficient long video generation.arXiv preprint arXiv:2502.21079, 2025. 2
-
[48]
A survey on video dif- fusion models.ACM Computing Surveys, 57(2):1–42, 2024
Zhen Xing, Qijun Feng, Haoran Chen, Qi Dai, Han Hu, Hang Xu, Zuxuan Wu, and Yu-Gang Jiang. A survey on video dif- fusion models.ACM Computing Surveys, 57(2):1–42, 2024. 2
2024
-
[49]
Decision-making large language model for wireless commu- nication: A comprehensive survey on key techniques.IEEE Communications Surveys & Tutorials, 2025
Ning Yang, Mingrui Fan, Wentao Wang, and Haijun Zhang. Decision-making large language model for wireless commu- nication: A comprehensive survey on key techniques.IEEE Communications Surveys & Tutorials, 2025. 2
2025
-
[50]
Post-training sparse attention with double sparsity.arXiv preprint arXiv:2408.07092, 2024
Shuo Yang, Ying Sheng, Joseph E Gonzalez, Ion Stoica, and Lianmin Zheng. Post-training sparse attention with double sparsity.arXiv preprint arXiv:2408.07092, 2024. 2
-
[51]
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
Shuo Yang, Haocheng Xi, Yilong Zhao, Muyang Li, Jintao Zhang, Han Cai, Yujun Lin, Xiuyu Li, Chenfeng Xu, Kelly Peng, et al. Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permutation.arXiv preprint arXiv:2505.18875, 2025. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 1, 2, 6
work page internal anchor Pith review arXiv 2024
-
[53]
Pqd: Post-training quantization for efficient diffusion models
Jiaojiao Ye, Zhen Wang, and Linnan Jiang. Pqd: Post-training quantization for efficient diffusion models. arXiv preprint arXiv:2501.00124, 2024. 8
-
[54]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. Flashinfer: Efficient and customizable attention engine for llm inference serving. arXiv preprint arXiv:2501.01005, 2025. 2, 6
-
[55]
Exploring attention sparsity to accelerate transformer training on gpus.IEEE Access, 2024
Bokyeong Yoon, Ah-Hyun Lee, Jinsung Kim, and Gor- don Euhyun Moon. Exploring attention sparsity to accelerate transformer training on gpus.IEEE Access, 2024. 2
2024
-
[56]
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattn: Accu- rate sparse attention accelerating any model inference.arXiv preprint arXiv:2502.18137, 2025. 1, 2, 3, 6
-
[57]
arXiv preprint arXiv:2505.13389 , year=
Peiyuan Zhang, Yongqi Chen, Haofeng Huang, Will Lin, Zhengzhong Liu, Ion Stoica, Eric Xing, and Hao Zhang. VSA: Faster video diffusion with trainable sparse attention. arXiv preprint arXiv:2505.13389, 2025. 2, 8
-
[58]
arXiv preprint arXiv:2502.04507 , year =
Peiyuan Zhang, Yongqi Chen, Runlong Su, Hangliang Ding, Ion Stoica, Zhengzhong Liu, and Hao Zhang. Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507, 2025. 1
-
[59]
Beyond training: Dy- namic token merging for zero-shot video understanding
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zenghui Ding, Xianjun Yang, and Yining Sun. Beyond training: Dy- namic token merging for zero-shot video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22046–22055, 2025. 1
2025
-
[60]
Tora: Trajectory-oriented diffusion transformer for video genera- tion
Zhenghao Zhang, Junchao Liao, Menghao Li, Zuozhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, and Weizhi Wang. Tora: Trajectory-oriented diffusion transformer for video genera- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2063–2073, 2025. 2
2063
-
[61]
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y ., Li, T., and You, Y
Xuanlei Zhao, Xiaolong Jin, Kai Wang, and Yang You. Real-time video generation with pyramid attention broad- cast.arXiv preprint arXiv:2408.12588, 2024. 2
-
[62]
the relative magnitude of query–key scores is independent of the query vector length
Xizhou Zhu, Dazhi Cheng, Zheng Zhang, Stephen Lin, and Jifeng Dai. An empirical study of spatial attention mecha- nisms in deep networks. InProceedings of the IEEE/CVF international conference on computer vision, pages 6688– 6697, 2019. 1 A. Appendix A.1. Compactness with Different Request To verify the effectiveness of the method proposed in Section 3.2....
2019
-
[63]
achieves a strong balance between reconstruction fidelity and inference speedup. Higher sparsity or larger initial TopK tends to yield greater acceleration at the cost of quality degradation, while more aggressive KV thresholding or fewer query clusters can improve quality in some regimes but reduces overall speedup. A.6. Additional Results on H100 GPUs A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.