Recognition: unknown
ArbGraph: Conflict-Aware Evidence Arbitration for Reliable Long-Form Retrieval-Augmented Generation
Pith reviewed 2026-05-10 04:48 UTC · model grok-4.3
The pith
ArbGraph improves factual consistency in long-form RAG by resolving conflicts among atomic claims in a graph before generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ArbGraph decomposes retrieved documents into atomic claims and organizes them into a conflict-aware evidence graph with explicit support and contradiction relations. It then applies an intensity-driven iterative arbitration mechanism that propagates credibility signals through evidence interactions to suppress unreliable and inconsistent claims before final generation, providing a coherent evidence foundation for downstream long-form RAG.
What carries the argument
The conflict-aware evidence graph with support and contradiction relations, processed via an intensity-driven iterative arbitration mechanism that propagates credibility signals to suppress inconsistent claims.
If this is right
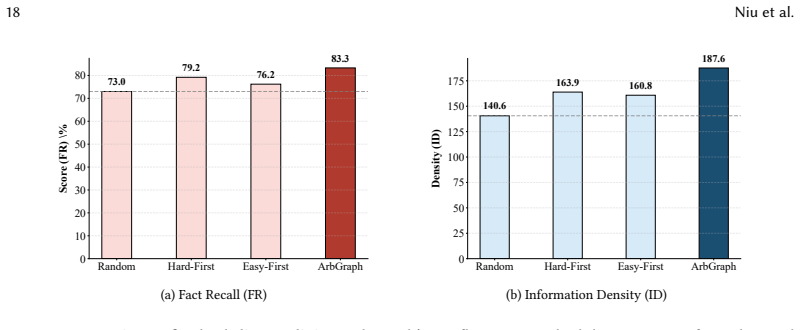
- ArbGraph improves factual recall and information density on LongFact and RAGChecker benchmarks across multiple LLM backbones.
- It reduces hallucinations and sensitivity to retrieval noise.
- Performance gains are most evident under conflicting or ambiguous evidence conditions.
- Evidence validation is separated from text generation to supply a coherent foundation for long-form outputs.
Where Pith is reading between the lines
- The same atomic-claim graph approach could be tested on multi-document summarization to check whether conflict resolution improves consistency beyond RAG.
- Adding source metadata such as dates or reliability scores to the graph edges might address temporal or authority-based inconsistencies the current model does not cover.
- If the arbitration scales efficiently, it could serve as a standard preprocessing filter in production RAG systems handling large evidence sets.
Load-bearing premise
Decomposing documents into atomic claims and modeling their support and contradiction relations in a graph resolves factual conflicts without significant information loss or introduction of new errors.
What would settle it
A controlled test on benchmarks with deliberately injected contradictions where ArbGraph shows no gain or a drop in factual accuracy compared to standard RAG would falsify the central claim.
Figures



read the original abstract
Retrieval-augmented generation (RAG) remains unreliable in long-form settings, where retrieved evidence is noisy or contradictory, making it difficult for RAG pipelines to maintain factual consistency. Existing approaches focus on retrieval expansion or verification during generation, leaving conflict resolution entangled with generation. To address this limitation, we propose ArbGraph, a framework for pre-generation evidence arbitration in long-form RAG that explicitly resolves factual conflicts. ArbGraph decomposes retrieved documents into atomic claims and organizes them into a conflict-aware evidence graph with explicit support and contradiction relations. On top of this graph, we introduce an intensity-driven iterative arbitration mechanism that propagates credibility signals through evidence interactions, enabling the system to suppress unreliable and inconsistent claims before final generation. In this way, ArbGraph separates evidence validation from text generation and provides a coherent evidence foundation for downstream long-form generation. We evaluate ArbGraph on two widely used long-form RAG benchmarks, LongFact and RAGChecker, using multiple large language model backbones. Experimental results show that ArbGraph consistently improves factual recall and information density while reducing hallucinations and sensitivity to retrieval noise. Additional analyses show that these gains are evident under conflicting or ambiguous evidence, highlighting the effectiveness of evidence-level conflict resolution for improving the reliability of long-form RAG. The implementation is publicly available at https://github.com/1212Judy/ArbGraph.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ArbGraph, a pre-generation framework for long-form RAG that decomposes retrieved documents into atomic claims, organizes them into a conflict-aware evidence graph with explicit support and contradiction relations, and applies an intensity-driven iterative arbitration mechanism to propagate credibility signals and suppress unreliable claims before generation. Experiments on LongFact and RAGChecker benchmarks with multiple LLM backbones report consistent gains in factual recall and information density alongside reductions in hallucinations and retrieval-noise sensitivity, with additional analysis under conflicting evidence.
Significance. If the central claims hold after addressing verification gaps, ArbGraph would represent a useful contribution to reliable long-form RAG by explicitly separating evidence-level conflict resolution from generation. The public code release supports reproducibility, and the focus on pre-generation arbitration addresses a practical pain point in noisy retrieval settings.
major comments (2)
- [§3 and §4] §3 (ArbGraph Framework) and §4 (Experiments): The central claim that the evidence graph plus iterative arbitration produces a cleaner claim set than raw retrieval hinges on accurate atomic claim decomposition and support/contradiction edge labeling, yet no quantitative audit (e.g., precision/recall of decomposition fidelity or edge-label accuracy on the evaluation sets) is provided. Without this, observed gains on LongFact/RAGChecker could be explained by simple filtering rather than conflict resolution.
- [§4.3] §4.3 (Analysis under conflicting evidence): The intensity-driven propagation is asserted to suppress noise without amplifying decomposition or labeling errors, but no error-propagation analysis or ablation isolating the arbitration step from baseline filtering is reported. This leaves the load-bearing assumption that the mechanism reliably corrects rather than compounds upstream errors unverified.
minor comments (2)
- [Figure 1 and §3.2] Figure 1 and §3.2: The graph construction notation (nodes as claims, edges as support/contradiction) would benefit from a concrete worked example showing how a multi-fact sentence is split and labeled.
- [§4.1] §4.1: Clarify the exact prompting templates used for claim decomposition and relation labeling, as these are implementation-critical for reproducibility.
Simulated Author's Rebuttal
Thank you for your detailed review and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our work on ArbGraph. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§3 and §4] §3 (ArbGraph Framework) and §4 (Experiments): The central claim that the evidence graph plus iterative arbitration produces a cleaner claim set than raw retrieval hinges on accurate atomic claim decomposition and support/contradiction edge labeling, yet no quantitative audit (e.g., precision/recall of decomposition fidelity or edge-label accuracy on the evaluation sets) is provided. Without this, observed gains on LongFact/RAGChecker could be explained by simple filtering rather than conflict resolution.
Authors: We agree that a quantitative audit of atomic claim decomposition fidelity and support/contradiction edge labeling accuracy would strengthen the validation of the framework components. The current manuscript emphasizes end-to-end gains in factual recall, information density, and hallucination reduction on LongFact and RAGChecker. To address the concern that gains may stem from simple filtering, we will add in revision an ablation comparing full ArbGraph against a baseline using claim decomposition followed by non-graph credibility filtering. We will also include precision/recall metrics on a sampled subset of claims via human or LLM-based judgment to quantify decomposition and labeling quality. revision: yes
-
Referee: [§4.3] §4.3 (Analysis under conflicting evidence): The intensity-driven propagation is asserted to suppress noise without amplifying decomposition or labeling errors, but no error-propagation analysis or ablation isolating the arbitration step from baseline filtering is reported. This leaves the load-bearing assumption that the mechanism reliably corrects rather than compounds upstream errors unverified.
Authors: We acknowledge that an explicit error-propagation analysis and ablation isolating iterative arbitration from baseline filtering would better verify the mechanism. Section 4.3 shows gains under conflicting evidence, but lacks a dedicated comparison. In revision, we will add an ablation with a single-pass intensity threshold variant (no iterative propagation) to demonstrate the iterative step's contribution. We will also include a sensitivity analysis discussing how the intensity-driven thresholds mitigate potential upstream errors rather than amplify them. revision: yes
Circularity Check
No circularity: ArbGraph is an empirical algorithmic framework
full rationale
The paper proposes a new pre-generation arbitration pipeline (claim decomposition into atomic units, construction of a support/contradiction graph, and intensity-driven iterative propagation) and validates it via experiments on LongFact and RAGChecker. No equations, parameter-fitting steps, or predictions appear in the provided text; the central claims rest on benchmark results rather than reducing to inputs by definition or self-citation. The method is self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Documents can be decomposed into independent atomic claims without loss of critical context.
invented entities (2)
-
Conflict-aware evidence graph
no independent evidence
-
Intensity-driven iterative arbitration mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations
2023
-
[2]
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. 2024. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 17682–17690
2024
-
[3]
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. 2024. Chain-of-verification reduces hallucination in large language models. InFindings of the association for computational linguistics: ACL 2024. 3563–3578
2024
-
[4]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitan- sky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review arXiv 2024
-
[5]
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. 2019. ELI5: Long form question answering. InProceedings of the 57th annual meeting of the association for computational linguistics. 3558–3567
2019
-
[6]
Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, et al. 2023. Rarr: Researching and revising what language models say, using language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 16477–16508
2023
-
[7]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023), 32
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [8]
-
[9]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2023. Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738(2023)
work page internal anchor Pith review arXiv 2023
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 59532–59569
2024
-
[12]
Rujun Han, Yuhao Zhang, Peng Qi, Yumo Xu, Jenyuan Wang, Lan Liu, William Yang Wang, Bonan Min, and Vittorio Castelli. 2024. Rag-qa arena: Evaluating domain robustness for long-form retrieval augmented question answering. In Proceedings of the 2024 conference on empirical methods in natural language processing. 4354–4374
2024
- [13]
-
[14]
Yukun Huang, Yixin Liu, Raghuveer Thirukovalluru, Arman Cohan, and Bhuwan Dhingra. 2024. Calibrating long-form generations from large language models. InFindings of the association for computational linguistics: EMNLP 2024. 13441–13460
2024
-
[15]
Jeongyeon Hwang, Junyoung Park, Hyejin Park, Dongwoo Kim, Sangdon Park, and Jungseul Ok. 2025. Retrieval- augmented generation with estimation of source reliability. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 34267–34291
2025
- [16]
-
[17]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F...
2020
- [18]
-
[19]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics 12 (2024), 157–173
2024
-
[20]
Shuyi Liu, Yu-Ming Shang, and Xi Zhang. 2026. Truthfulrag: Resolving factual-level conflicts in retrieval-augmented generation with knowledge graphs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 32168–32176
2026
- [21]
-
[22]
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al. 2022. Teaching language models to support answers with verified quotes.arXiv preprint arXiv:2203.11147(2022)
-
[23]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. 2021. WebGPT: Browser-Assisted Question-Answering with Human Feedback.arXiv preprint arXiv:2112.09332(2021)
work page internal anchor Pith review arXiv 2021
-
[24]
Ronak Pradeep, Nandan Thakur, Shivani Upadhyay, Daniel Campos, Nick Craswell, Ian Soboroff, Hoa Trang Dang, and Jimmy Lin. 2025. The great nugget recall: Automating fact extraction and rag evaluation with large language models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 180–190
2025
-
[25]
Yujia Qin, Zihan Cai, Dian Jin, Lan Yan, Shihao Liang, Kunlun Zhu, Yankai Lin, Xu Han, Ning Ding, Huadong Wang, et al. 2023. Webcpm: Interactive web search for chinese long-form question answering. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8968–8988
2023
-
[26]
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang
-
[27]
InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 5835–5847
2021
- [28]
-
[29]
Ruiyang Ren, Yuhao Wang, Junyi Li, Jinhao Jiang, Wayne Xin Zhao, Wenjie Wang, and Tat-Seng Chua. 2025. LLM- based Search Assistant with Holistically Guided MCTS for Intricate Information Seeking. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1098–1108
2025
-
[30]
Ruiyang Ren, Yuhao Wang, Yingqi Qu, Wayne Xin Zhao, Jing Liu, Hua Wu, Ji-Rong Wen, and Haifeng Wang. 2025. Investigating the factual knowledge boundary of large language models with retrieval augmentation. InProceedings of the 31st International Conference on Computational Linguistics. 3697–3715
2025
-
[31]
Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Cheng Jiayang, Cunxiang Wang, Shichao Sun, Huanyu Li, Zizhao Zhang, Binjie Wang, Jiarong Jiang, Tong He, Zhiguo Wang, Pengfei Liu, Yue Zhang, and Zheng Zhang. 2024. RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation. In Advances in Neural Informatio...
-
[32]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 8634–8652
2023
- [33]
-
[34]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. 2023. Plan- Bench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curr...
2023
-
[35]
Yuhao Wang, Ruiyang Ren, Yucheng Wang, Jing Liu, Xin Zhao, Hua Wu, and Haifeng Wang. 2026. Bee-rag: Balanced entropy engineering for retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 33737–33745
2026
-
[36]
Yuhao Wang, Ruiyang Ren, Yucheng Wang, Wayne Xin Zhao, Jing Liu, Hua Wu, and Haifeng Wang. 2025. Reinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation.arXiv preprint arXiv:2505.20825(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou
-
[38]
InAdvances in Neural Information Processing Systems, S
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, ACM Trans. Inf. Syst., Vol. 1, No. 1, Article . Publication date: April 2026. ArbGraph: Conflict-Aware Evidence Arbitration for Rel...
2026
-
[39]
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and Quoc V. Le. 2024. Long-form factuality in large language models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran ...
-
[40]
Zhuohan Xie, Rui Xing, Yuxia Wang, Jiahui Geng, Hasan Iqbal, Dhruv Sahnan, Iryna Gurevych, and Preslav Nakov
-
[41]
InFindings of the Association for Computational Linguistics: NAACL 2025
FIRE: fact-checking with iterative retrieval and verification. InFindings of the Association for Computational Linguistics: NAACL 2025. 2901–2914
2025
-
[42]
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. 2024. Corrective Retrieval Augmented Generation. arXiv:2401.15884
work page internal anchor Pith review arXiv 2024
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. React: Syner- gizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2023
- [45]
-
[46]
Wenhao Yu, Hongming Zhang, Xiaoman Pan, Peixin Cao, Kaixin Ma, Jian Li, Hongwei Wang, and Dong Yu. 2024. Chain-of-note: Enhancing robustness in retrieval-augmented language models. InProceedings of the 2024 conference on empirical methods in natural language processing. 14672–14685
2024
-
[47]
Zhenrui Yue, Huimin Zeng, Yimeng Lu, Lanyu Shang, Yang Zhang, and Dong Wang. 2024. Evidence-driven retrieval augmented response generation for online misinformation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 5628–5643
2024
-
[48]
Xinran Zhao, Aakanksha Naik, Jay DeYoung, Joseph Chee Chang, Jena D Hwang, Tongshuang Wu, and Varsha Kishore
- [49]
-
[50]
Yilun Zhao, Lyuhao Chen, Arman Cohan, and Chen Zhao. 2024. TaPERA: Enhancing faithfulness and interpretability in long-form table QA by content planning and execution-based reasoning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 12824–12840
2024
-
[51]
Yuqicheng Zhu, Nico Potyka, Daniel Hernández, Yuan He, Zifeng Ding, Bo Xiong, Dongzhuoran Zhou, Evgeny Kharlamov, and Steffen Staab. 2025. Argrag: Explainable retrieval augmented generation using quantitative bipolar argumentation.arXiv preprint arXiv:2508.20131(2025). ACM Trans. Inf. Syst., Vol. 1, No. 1, Article . Publication date: April 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.